 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Scaling in Diffusion LLMs via Hidden Semi-Autoregressive Experts
Oct 06, 2025



Diffusion-based large language models (dLLMs) are trained flexibly to model extreme dependence in the data distribution; however, how to best utilize this information at inference time remains an open problem. In this work, we uncover an interesting property of these models: dLLMs trained on textual data implicitly learn a mixture of semi-autoregressive experts, where different generation orders reveal different specialized behaviors. We show that committing to any single, fixed inference time schedule, a common practice, collapses performance by failing to leverage this latent ensemble. To address this, we introduce HEX (Hidden semiautoregressive EXperts for test-time scaling), a training-free inference method that ensembles across heterogeneous block schedules. By doing a majority vote over diverse block-sized generation paths, HEX robustly avoids failure modes associated with any single fixed schedule. On reasoning benchmarks such as GSM8K, it boosts accuracy by up to 3.56X (from 24.72% to 88.10%), outperforming top-K margin inference and specialized fine-tuned methods like GRPO, without additional training. HEX even yields significant gains on MATH benchmark from 16.40% to 40.00%, scientific reasoning on ARC-C from 54.18% to 87.80%, and TruthfulQA from 28.36% to 57.46%. Our results establish a new paradigm for test-time scaling in diffusion-based LLMs (dLLMs), revealing that the sequence in which masking is performed plays a critical role in determining performance during inference.
MIRA: Towards Mitigating Reward Hacking in Inference-Time Alignment of T2I Diffusion Models
Oct 02, 2025Diffusion models excel at generating images conditioned on text prompts, but the resulting images often do not satisfy user-specific criteria measured by scalar rewards such as Aesthetic Scores. This alignment typically requires fine-tuning, which is computationally demanding. Recently, inference-time alignment via noise optimization has emerged as an efficient alternative, modifying initial input noise to steer the diffusion denoising process towards generating high-reward images. However, this approach suffers from reward hacking, where the model produces images that score highly, yet deviate significantly from the original prompt. We show that noise-space regularization is insufficient and that preventing reward hacking requires an explicit image-space constraint. To this end, we propose MIRA (MItigating Reward hAcking), a training-free, inference-time alignment method. MIRA introduces an image-space, score-based KL surrogate that regularizes the sampling trajectory with a frozen backbone, constraining the output distribution so reward can increase without off-distribution drift (reward hacking). We derive a tractable approximation to KL using diffusion scores. Across SDv1.5 and SDXL, multiple rewards (Aesthetic, HPSv2, PickScore), and public datasets (e.g., Animal-Animal, HPDv2), MIRA achieves >60\% win rate vs. strong baselines while preserving prompt adherence; mechanism plots show reward gains with near-zero drift, whereas DNO drifts as compute increases. We further introduce MIRA-DPO, mapping preference optimization to inference time with a frozen backbone, extending MIRA to non-differentiable rewards without fine-tuning.
Hierarchical Preference Optimization: Learning to achieve goals via feasible subgoals prediction
Nov 01, 2024



This work introduces Hierarchical Preference Optimization (HPO), a novel approach to hierarchical reinforcement learning (HRL) that addresses non-stationarity and infeasible subgoal generation issues when solving complex robotic control tasks. HPO leverages maximum entropy reinforcement learning combined with token-level Direct Preference Optimization (DPO), eliminating the need for pre-trained reference policies that are typically unavailable in challenging robotic scenarios. Mathematically, we formulate HRL as a bi-level optimization problem and transform it into a primitive-regularized DPO formulation, ensuring feasible subgoal generation and avoiding degenerate solutions. Extensive experiments on challenging robotic navigation and manipulation tasks demonstrate impressive performance of HPO, where it shows an improvement of up to 35% over the baselines. Furthermore, ablation studies validate our design choices, and quantitative analyses confirm the ability of HPO to mitigate non-stationarity and infeasible subgoal generation issues in HRL.
Get more for less: Principled Data Selection for Warming Up Fine-Tuning in LLMs
May 05, 2024



This work focuses on leveraging and selecting from vast, unlabeled, open data to pre-fine-tune a pre-trained language model. The goal is to minimize the need for costly domain-specific data for subsequent fine-tuning while achieving desired performance levels. While many data selection algorithms have been designed for small-scale applications, rendering them unsuitable for our context, some emerging methods do cater to language data scales. However, they often prioritize data that aligns with the target distribution. While this strategy may be effective when training a model from scratch, it can yield limited results when the model has already been pre-trained on a different distribution. Differing from prior work, our key idea is to select data that nudges the pre-training distribution closer to the target distribution. We show the optimality of this approach for fine-tuning tasks under certain conditions. We demonstrate the efficacy of our methodology across a diverse array of tasks (NLU, NLG, zero-shot) with models up to 2.7B, showing that it consistently surpasses other selection methods. Moreover, our proposed method is significantly faster than existing techniques, scaling to millions of samples within a single GPU hour. Our code is open-sourced (Code repository: https://anonymous.4open.science/r/DV4LLM-D761/ ). While fine-tuning offers significant potential for enhancing performance across diverse tasks, its associated costs often limit its widespread adoption; with this work, we hope to lay the groundwork for cost-effective fine-tuning, making its benefits more accessible.
RealFM: A Realistic Mechanism to Incentivize Data Contribution and Device Participation
Oct 20, 2023Edge device participation in federating learning (FL) has been typically studied under the lens of device-server communication (e.g., device dropout) and assumes an undying desire from edge devices to participate in FL. As a result, current FL frameworks are flawed when implemented in real-world settings, with many encountering the free-rider problem. In a step to push FL towards realistic settings, we propose RealFM: the first truly federated mechanism which (1) realistically models device utility, (2) incentivizes data contribution and device participation, and (3) provably removes the free-rider phenomena. RealFM does not require data sharing and allows for a non-linear relationship between model accuracy and utility, which improves the utility gained by the server and participating devices compared to non-participating devices as well as devices participating in other FL mechanisms. On real-world data, RealFM improves device and server utility, as well as data contribution, by up to 3 magnitudes and 7x respectively compared to baseline mechanisms.
Federated Representation Learning for Automatic Speech Recognition
Aug 07, 2023



Federated Learning (FL) is a privacy-preserving paradigm, allowing edge devices to learn collaboratively without sharing data. Edge devices like Alexa and Siri are prospective sources of unlabeled audio data that can be tapped to learn robust audio representations. In this work, we bring Self-supervised Learning (SSL) and FL together to learn representations for Automatic Speech Recognition respecting data privacy constraints. We use the speaker and chapter information in the unlabeled speech dataset, Libri-Light, to simulate non-IID speaker-siloed data distributions and pre-train an LSTM encoder with the Contrastive Predictive Coding framework with FedSGD. We show that the pre-trained ASR encoder in FL performs as well as a centrally pre-trained model and produces an improvement of 12-15% (WER) compared to no pre-training. We further adapt the federated pre-trained models to a new language, French, and show a 20% (WER) improvement over no pre-training.
Performance Scaling via Optimal Transport: Enabling Data Selection from Partially Revealed Sources
Jul 05, 2023



Traditionally, data selection has been studied in settings where all samples from prospective sources are fully revealed to a machine learning developer. However, in practical data exchange scenarios, data providers often reveal only a limited subset of samples before an acquisition decision is made. Recently, there have been efforts to fit scaling laws that predict model performance at any size and data source composition using the limited available samples. However, these scaling functions are black-box, computationally expensive to fit, highly susceptible to overfitting, or/and difficult to optimize for data selection. This paper proposes a framework called <projektor>, which predicts model performance and supports data selection decisions based on partial samples of prospective data sources. Our approach distinguishes itself from existing work by introducing a novel *two-stage* performance inference process. In the first stage, we leverage the Optimal Transport distance to predict the model's performance for any data mixture ratio within the range of disclosed data sizes. In the second stage, we extrapolate the performance to larger undisclosed data sizes based on a novel parameter-free mapping technique inspired by neural scaling laws. We further derive an efficient gradient-based method to select data sources based on the projected model performance. Evaluation over a diverse range of applications demonstrates that <projektor> significantly improves existing performance scaling approaches in terms of both the accuracy of performance inference and the computation costs associated with constructing the performance predictor. Also, <projektor> outperforms by a wide margin in data selection effectiveness compared to a range of other off-the-shelf solutions.
Learning When to Trust Which Teacher for Weakly Supervised ASR
Jun 21, 2023



Automatic speech recognition (ASR) training can utilize multiple experts as teacher models, each trained on a specific domain or accent. Teacher models may be opaque in nature since their architecture may be not be known or their training cadence is different from that of the student ASR model. Still, the student models are updated incrementally using the pseudo-labels generated independently by the expert teachers. In this paper, we exploit supervision from multiple domain experts in training student ASR models. This training strategy is especially useful in scenarios where few or no human transcriptions are available. To that end, we propose a Smart-Weighter mechanism that selects an appropriate expert based on the input audio, and then trains the student model in an unsupervised setting. We show the efficacy of our approach using LibriSpeech and LibriLight benchmarks and find an improvement of 4 to 25\% over baselines that uniformly weight all the experts, use a single expert model, or combine experts using ROVER.
Federated Self-Learning with Weak Supervision for Speech Recognition
Jun 21, 2023



Automatic speech recognition (ASR) models with low-footprint are increasingly being deployed on edge devices for conversational agents, which enhances privacy. We study the problem of federated continual incremental learning for recurrent neural network-transducer (RNN-T) ASR models in the privacy-enhancing scheme of learning on-device, without access to ground truth human transcripts or machine transcriptions from a stronger ASR model. In particular, we study the performance of a self-learning based scheme, with a paired teacher model updated through an exponential moving average of ASR models. Further, we propose using possibly noisy weak-supervision signals such as feedback scores and natural language understanding semantics determined from user behavior across multiple turns in a session of interactions with the conversational agent. These signals are leveraged in a multi-task policy-gradient training approach to improve the performance of self-learning for ASR. Finally, we show how catastrophic forgetting can be mitigated by combining on-device learning with a memory-replay approach using selected historical datasets. These innovations allow for 10% relative improvement in WER on new use cases with minimal degradation on other test sets in the absence of strong-supervision signals such as ground-truth transcriptions.
ILASR: Privacy-Preserving Incremental Learning for Automatic Speech Recognition at Production Scale
Jul 22, 2022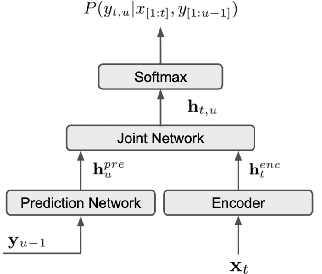
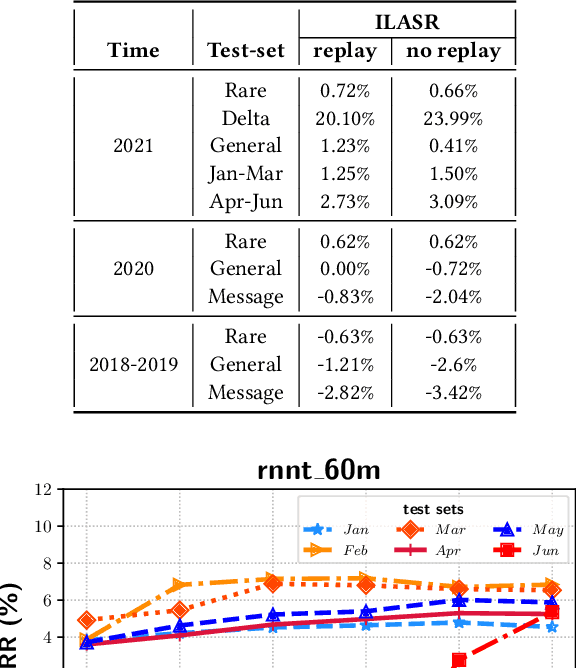
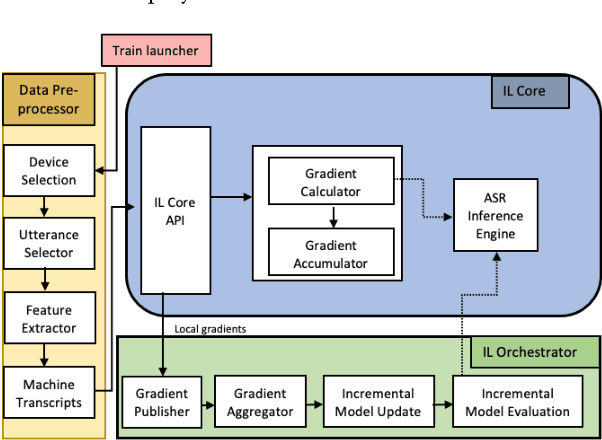
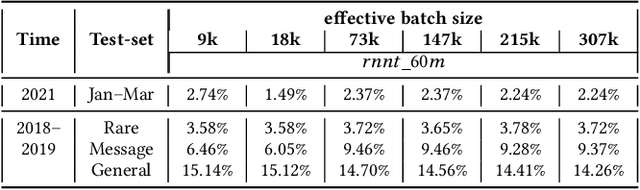
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.