 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
EMO-SUPERB: An In-depth Look at Speech Emotion Recognition
Feb 22, 2024
Speech emotion recognition (SER) is a pivotal technology for human-computer interaction systems. However, 80.77% of SER papers yield results that cannot be reproduced. We develop EMO-SUPERB, short for EMOtion Speech Universal PERformance Benchmark, which aims to enhance open-source initiatives for SER. EMO-SUPERB includes a user-friendly codebase to leverage 15 state-of-the-art speech self-supervised learning models (SSLMs) for exhaustive evaluation across six open-source SER datasets. EMO-SUPERB streamlines result sharing via an online leaderboard, fostering collaboration within a community-driven benchmark and thereby enhancing the development of SER. On average, 2.58% of annotations are annotated using natural language. SER relies on classification models and is unable to process natural languages, leading to the discarding of these valuable annotations. We prompt ChatGPT to mimic annotators, comprehend natural language annotations, and subsequently re-label the data. By utilizing labels generated by ChatGPT, we consistently achieve an average relative gain of 3.08% across all settings.
Non-verbal information in spontaneous speech -- towards a new framework of analysis
Mar 06, 2024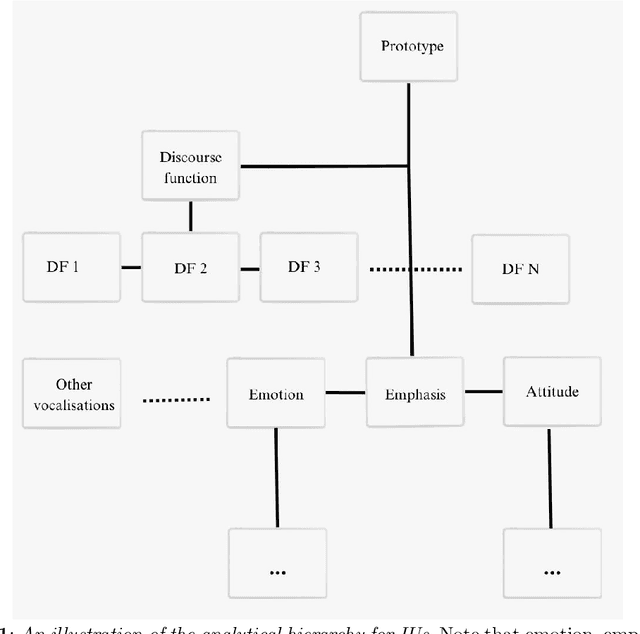
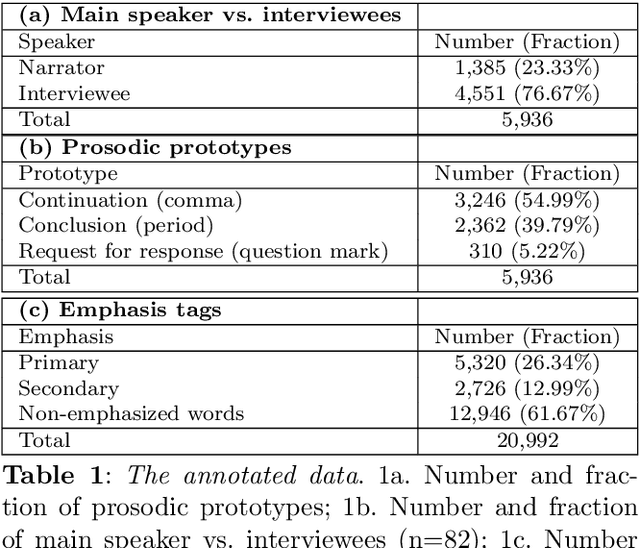
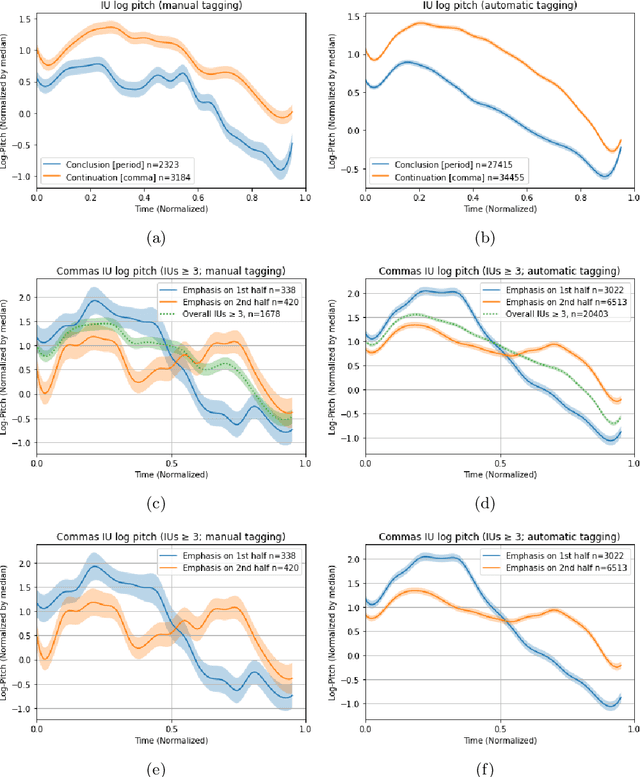
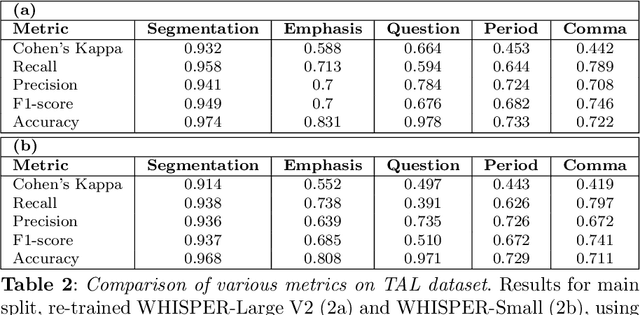
Non-verbal signals in speech are encoded by prosody and carry information that ranges from conversation action to attitude and emotion. Despite its importance, the principles that govern prosodic structure are not yet adequately understood. This paper offers an analytical schema and a technological proof-of-concept for the categorization of prosodic signals and their association with meaning. The schema interprets surface-representations of multi-layered prosodic events. As a first step towards implementation, we present a classification process that disentangles prosodic phenomena of three orders. It relies on fine-tuning a pre-trained speech recognition model, enabling the simultaneous multi-class/multi-label detection. It generalizes over a large variety of spontaneous data, performing on a par with, or superior to, human annotation. In addition to a standardized formalization of prosody, disentangling prosodic patterns can direct a theory of communication and speech organization. A welcome by-product is an interpretation of prosody that will enhance speech- and language-related technologies.
Language and Speech Technology for Central Kurdish Varieties
Mar 04, 2024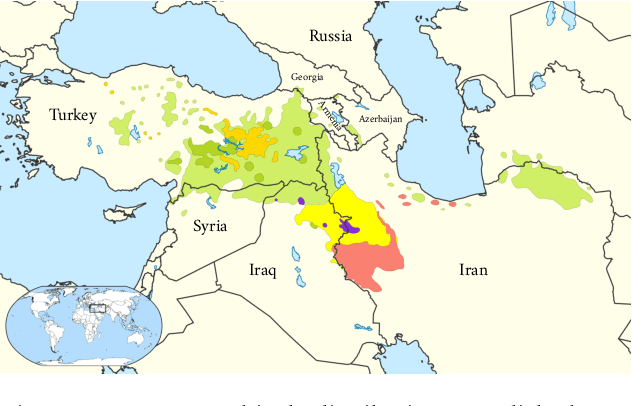
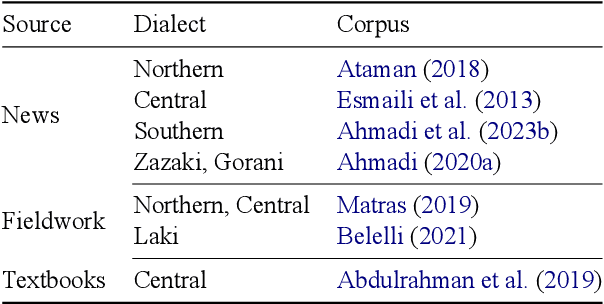
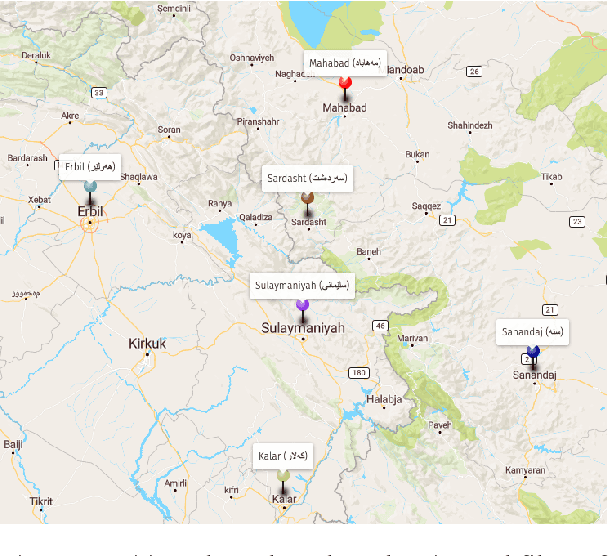
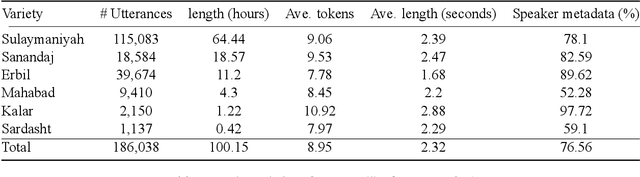
Kurdish, an Indo-European language spoken by over 30 million speakers, is considered a dialect continuum and known for its diversity in language varieties. Previous studies addressing language and speech technology for Kurdish handle it in a monolithic way as a macro-language, resulting in disparities for dialects and varieties for which there are few resources and tools available. In this paper, we take a step towards developing resources for language and speech technology for varieties of Central Kurdish, creating a corpus by transcribing movies and TV series as an alternative to fieldwork. Additionally, we report the performance of machine translation, automatic speech recognition, and language identification as downstream tasks evaluated on Central Kurdish varieties. Data and models are publicly available under an open license at https://github.com/sinaahmadi/CORDI.
Classist Tools: Social Class Correlates with Performance in NLP
Mar 07, 2024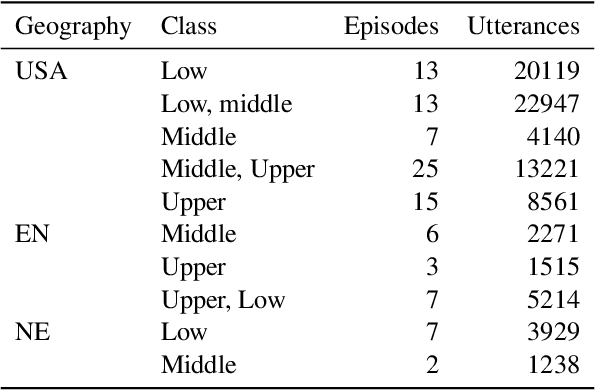
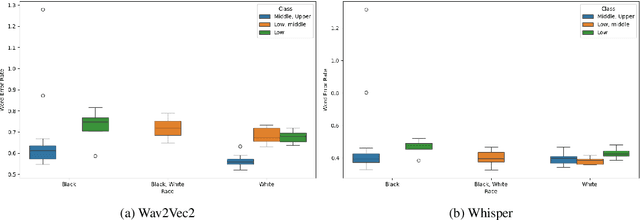
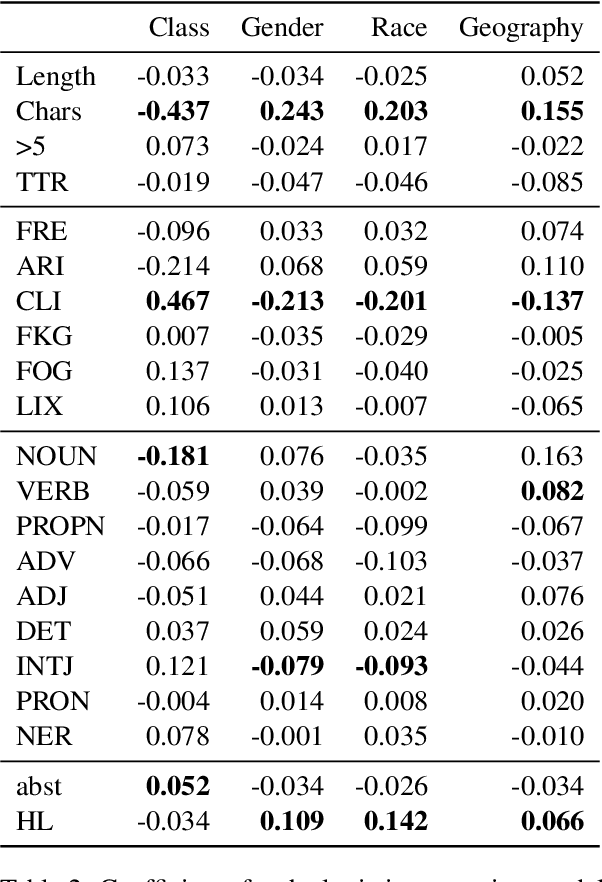
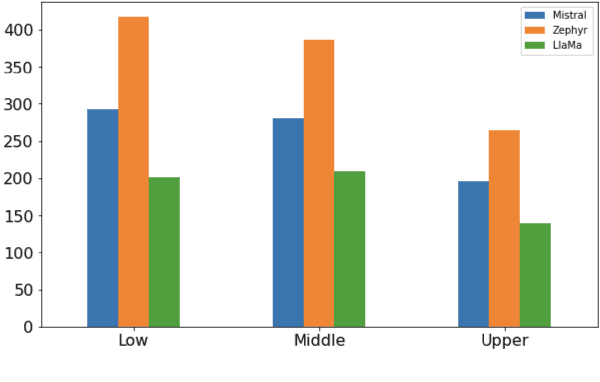
Since the foundational work of William Labov on the social stratification of language (Labov, 1964), linguistics has made concentrated efforts to explore the links between sociodemographic characteristics and language production and perception. But while there is strong evidence for socio-demographic characteristics in language, they are infrequently used in Natural Language Processing (NLP). Age and gender are somewhat well represented, but Labov's original target, socioeconomic status, is noticeably absent. And yet it matters. We show empirically that NLP disadvantages less-privileged socioeconomic groups. We annotate a corpus of 95K utterances from movies with social class, ethnicity and geographical language variety and measure the performance of NLP systems on three tasks: language modelling, automatic speech recognition, and grammar error correction. We find significant performance disparities that can be attributed to socioeconomic status as well as ethnicity and geographical differences. With NLP technologies becoming ever more ubiquitous and quotidian, they must accommodate all language varieties to avoid disadvantaging already marginalised groups. We argue for the inclusion of socioeconomic class in future language technologies.
Cross-Speaker Encoding Network for Multi-Talker Speech Recognition
Jan 08, 2024End-to-end multi-talker speech recognition has garnered great interest as an effective approach to directly transcribe overlapped speech from multiple speakers. Current methods typically adopt either 1) single-input multiple-output (SIMO) models with a branched encoder, or 2) single-input single-output (SISO) models based on attention-based encoder-decoder architecture with serialized output training (SOT). In this work, we propose a Cross-Speaker Encoding (CSE) network to address the limitations of SIMO models by aggregating cross-speaker representations. Furthermore, the CSE model is integrated with SOT to leverage both the advantages of SIMO and SISO while mitigating their drawbacks. To the best of our knowledge, this work represents an early effort to integrate SIMO and SISO for multi-talker speech recognition. Experiments on the two-speaker LibrispeechMix dataset show that the CES model reduces word error rate (WER) by 8% over the SIMO baseline. The CSE-SOT model reduces WER by 10% overall and by 16% on high-overlap speech compared to the SOT model.
PixIT: Joint Training of Speaker Diarization and Speech Separation from Real-world Multi-speaker Recordings
Mar 04, 2024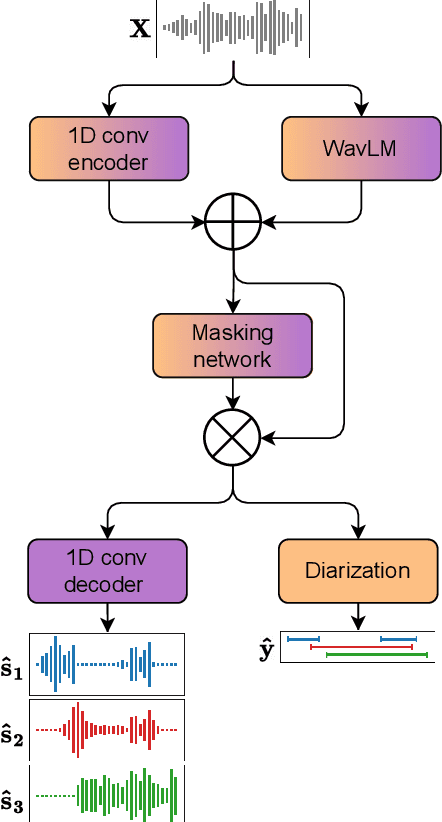
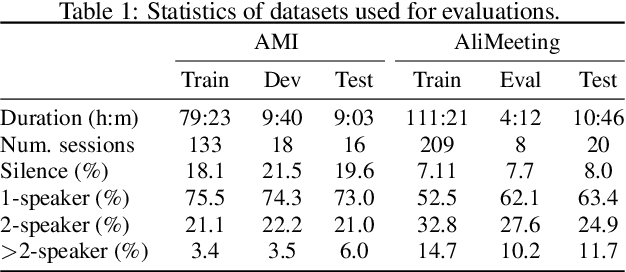
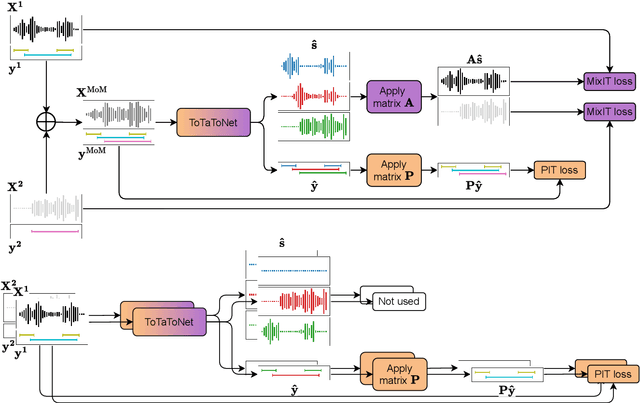
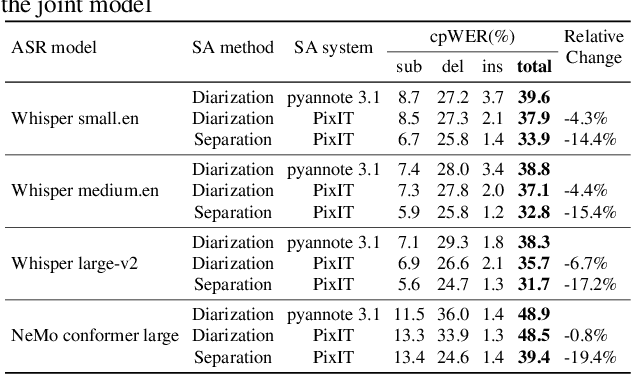
A major drawback of supervised speech separation (SSep) systems is their reliance on synthetic data, leading to poor real-world generalization. Mixture invariant training (MixIT) was proposed as an unsupervised alternative that uses real recordings, yet struggles with overseparation and adapting to long-form audio. We introduce PixIT, a joint approach that combines permutation invariant training (PIT) for speaker diarization (SD) and MixIT for SSep. With a small extra requirement of needing SD labels, it solves the problem of overseparation and allows stitching local separated sources leveraging existing work on clustering-based neural SD. We measure the quality of the separated sources via applying automatic speech recognition (ASR) systems to them. PixIT boosts the performance of various ASR systems across two meeting corpora both in terms of the speaker-attributed and utterance-based word error rates while not requiring any fine-tuning.
RADIA -- Radio Advertisement Detection with Intelligent Analytics
Mar 06, 2024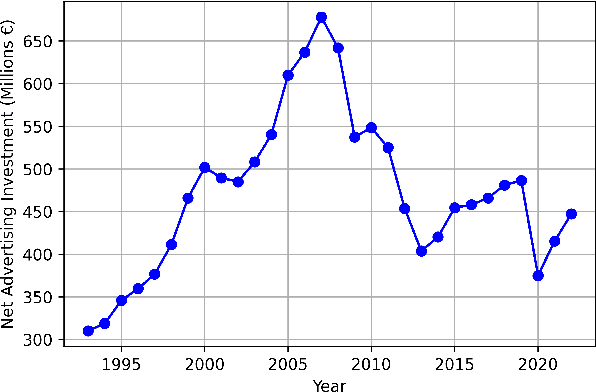
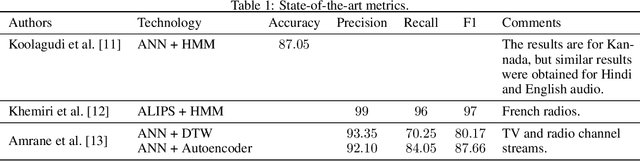
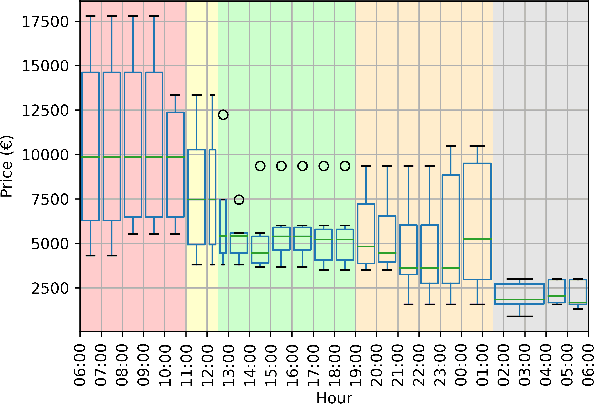
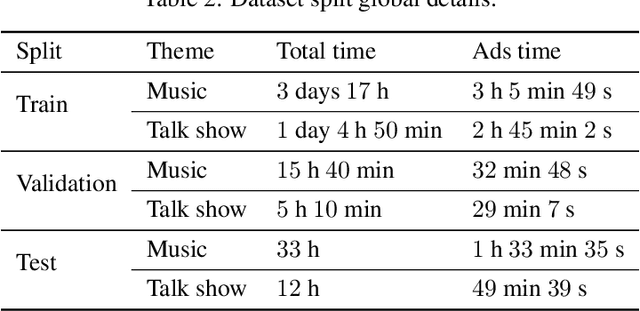
Radio advertising remains an integral part of modern marketing strategies, with its appeal and potential for targeted reach undeniably effective. However, the dynamic nature of radio airtime and the rising trend of multiple radio spots necessitates an efficient system for monitoring advertisement broadcasts. This study investigates a novel automated radio advertisement detection technique incorporating advanced speech recognition and text classification algorithms. RadIA's approach surpasses traditional methods by eliminating the need for prior knowledge of the broadcast content. This contribution allows for detecting impromptu and newly introduced advertisements, providing a comprehensive solution for advertisement detection in radio broadcasting. Experimental results show that the resulting model, trained on carefully segmented and tagged text data, achieves an F1-macro score of 87.76 against a theoretical maximum of 89.33. This paper provides insights into the choice of hyperparameters and their impact on the model's performance. This study demonstrates its potential to ensure compliance with advertising broadcast contracts and offer competitive surveillance. This groundbreaking research could fundamentally change how radio advertising is monitored and open new doors for marketing optimization.
LCB-net: Long-Context Biasing for Audio-Visual Speech Recognition
Jan 12, 2024The growing prevalence of online conferences and courses presents a new challenge in improving automatic speech recognition (ASR) with enriched textual information from video slides. In contrast to rare phrase lists, the slides within videos are synchronized in real-time with the speech, enabling the extraction of long contextual bias. Therefore, we propose a novel long-context biasing network (LCB-net) for audio-visual speech recognition (AVSR) to leverage the long-context information available in videos effectively. Specifically, we adopt a bi-encoder architecture to simultaneously model audio and long-context biasing. Besides, we also propose a biasing prediction module that utilizes binary cross entropy (BCE) loss to explicitly determine biased phrases in the long-context biasing. Furthermore, we introduce a dynamic contextual phrases simulation to enhance the generalization and robustness of our LCB-net. Experiments on the SlideSpeech, a large-scale audio-visual corpus enriched with slides, reveal that our proposed LCB-net outperforms general ASR model by 9.4%/9.1%/10.9% relative WER/U-WER/B-WER reduction on test set, which enjoys high unbiased and biased performance. Moreover, we also evaluate our model on LibriSpeech corpus, leading to 23.8%/19.2%/35.4% relative WER/U-WER/B-WER reduction over the ASR model.
AGADIR: Towards Array-Geometry Agnostic Directional Speech Recognition
Jan 18, 2024Wearable devices like smart glasses are approaching the compute capability to seamlessly generate real-time closed captions for live conversations. We build on our recently introduced directional Automatic Speech Recognition (ASR) for smart glasses that have microphone arrays, which fuses multi-channel ASR with serialized output training, for wearer/conversation-partner disambiguation as well as suppression of cross-talk speech from non-target directions and noise. When ASR work is part of a broader system-development process, one may be faced with changes to microphone geometries as system development progresses. This paper aims to make multi-channel ASR insensitive to limited variations of microphone-array geometry. We show that a model trained on multiple similar geometries is largely agnostic and generalizes well to new geometries, as long as they are not too different. Furthermore, training the model this way improves accuracy for seen geometries by 15 to 28\% relative. Lastly, we refine the beamforming by a novel Non-Linearly Constrained Minimum Variance criterion.
Parameter Efficient Finetuning for Speech Emotion Recognition and Domain Adaptation
Feb 19, 2024Foundation models have shown superior performance for speech emotion recognition (SER). However, given the limited data in emotion corpora, finetuning all parameters of large pre-trained models for SER can be both resource-intensive and susceptible to overfitting. This paper investigates parameter-efficient finetuning (PEFT) for SER. Various PEFT adaptors are systematically studied for both classification of discrete emotion categories and prediction of dimensional emotional attributes. The results demonstrate that the combination of PEFT methods surpasses full finetuning with a significant reduction in the number of trainable parameters. Furthermore, a two-stage adaptation strategy is proposed to adapt models trained on acted emotion data, which is more readily available, to make the model more adept at capturing natural emotional expressions. Both intra- and cross-corpus experiments validate the efficacy of the proposed approach in enhancing the performance on both the source and target domains.