 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquipping LLM with Directional Multi-Talker Speech Understanding Capabilities
Feb 06, 2026Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech understanding capabilities. However, most speech LLMs are trained on single-channel, single-talker data, which makes it challenging to directly apply them to multi-talker and multi-channel speech understanding task. In this work, we present a comprehensive investigation on how to enable directional multi-talker speech understanding capabilities for LLMs, specifically in smart glasses usecase. We propose two novel approaches to integrate directivity into LLMs: (1) a cascaded system that leverages a source separation front-end module, and (2) an end-to-end system that utilizes serialized output training. All of the approaches utilize a multi-microphone array embedded in smart glasses to optimize directivity interpretation and processing in a streaming manner. Experimental results demonstrate the efficacy of our proposed methods in endowing LLMs with directional speech understanding capabilities, achieving strong performance in both speech recognition and speech translation tasks.
Thinking in Directivity: Speech Large Language Model for Multi-Talker Directional Speech Recognition
Jun 17, 2025



Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech recognition capabilities. However, the ability of Speech LLMs to comprehend and process multi-channel audio with spatial cues remains a relatively uninvestigated area of research. In this work, we present directional-SpeechLlama, a novel approach that leverages the microphone array of smart glasses to achieve directional speech recognition, source localization, and bystander cross-talk suppression. To enhance the model's ability to understand directivity, we propose two key techniques: serialized directional output training (S-DOT) and contrastive direction data augmentation (CDDA). Experimental results show that our proposed directional-SpeechLlama effectively captures the relationship between textual cues and spatial audio, yielding strong performance in both speech recognition and source localization tasks.
M-BEST-RQ: A Multi-Channel Speech Foundation Model for Smart Glasses
Sep 17, 2024



The growing popularity of multi-channel wearable devices, such as smart glasses, has led to a surge of applications such as targeted speech recognition and enhanced hearing. However, current approaches to solve these tasks use independently trained models, which may not benefit from large amounts of unlabeled data. In this paper, we propose M-BEST-RQ, the first multi-channel speech foundation model for smart glasses, which is designed to leverage large-scale self-supervised learning (SSL) in an array-geometry agnostic approach. While prior work on multi-channel speech SSL only evaluated on simulated settings, we curate a suite of real downstream tasks to evaluate our model, namely (i) conversational automatic speech recognition (ASR), (ii) spherical active source localization, and (iii) glasses wearer voice activity detection, which are sourced from the MMCSG and EasyCom datasets. We show that a general-purpose M-BEST-RQ encoder is able to match or surpass supervised models across all tasks. For the conversational ASR task in particular, using only 8 hours of labeled speech, our model outperforms a supervised ASR baseline that is trained on 2000 hours of labeled data, which demonstrates the effectiveness of our approach.
Exploring the Feasibility of Automated Data Standardization using Large Language Models for Seamless Positioning
Aug 22, 2024We propose a feasibility study for real-time automated data standardization leveraging Large Language Models (LLMs) to enhance seamless positioning systems in IoT environments. By integrating and standardizing heterogeneous sensor data from smartphones, IoT devices, and dedicated systems such as Ultra-Wideband (UWB), our study ensures data compatibility and improves positioning accuracy using the Extended Kalman Filter (EKF). The core components include the Intelligent Data Standardization Module (IDSM), which employs a fine-tuned LLM to convert varied sensor data into a standardized format, and the Transformation Rule Generation Module (TRGM), which automates the creation of transformation rules and scripts for ongoing data standardization. Evaluated in real-time environments, our study demonstrates adaptability and scalability, enhancing operational efficiency and accuracy in seamless navigation. This study underscores the potential of advanced LLMs in overcoming sensor data integration complexities, paving the way for more scalable and precise IoT navigation solutions.
AGADIR: Towards Array-Geometry Agnostic Directional Speech Recognition
Jan 18, 2024



Wearable devices like smart glasses are approaching the compute capability to seamlessly generate real-time closed captions for live conversations. We build on our recently introduced directional Automatic Speech Recognition (ASR) for smart glasses that have microphone arrays, which fuses multi-channel ASR with serialized output training, for wearer/conversation-partner disambiguation as well as suppression of cross-talk speech from non-target directions and noise. When ASR work is part of a broader system-development process, one may be faced with changes to microphone geometries as system development progresses. This paper aims to make multi-channel ASR insensitive to limited variations of microphone-array geometry. We show that a model trained on multiple similar geometries is largely agnostic and generalizes well to new geometries, as long as they are not too different. Furthermore, training the model this way improves accuracy for seen geometries by 15 to 28\% relative. Lastly, we refine the beamforming by a novel Non-Linearly Constrained Minimum Variance criterion.
Directional Source Separation for Robust Speech Recognition on Smart Glasses
Sep 20, 2023



Modern smart glasses leverage advanced audio sensing and machine learning technologies to offer real-time transcribing and captioning services, considerably enriching human experiences in daily communications. However, such systems frequently encounter challenges related to environmental noises, resulting in degradation to speech recognition and speaker change detection. To improve voice quality, this work investigates directional source separation using the multi-microphone array. We first explore multiple beamformers to assist source separation modeling by strengthening the directional properties of speech signals. In addition to relying on predetermined beamformers, we investigate neural beamforming in multi-channel source separation, demonstrating that automatic learning directional characteristics effectively improves separation quality. We further compare the ASR performance leveraging separated outputs to noisy inputs. Our results show that directional source separation benefits ASR for the wearer but not for the conversation partner. Lastly, we perform the joint training of the directional source separation and ASR model, achieving the best overall ASR performance.
Modality Confidence Aware Training for Robust End-to-End Spoken Language Understanding
Jul 22, 2023End-to-end (E2E) spoken language understanding (SLU) systems that generate a semantic parse from speech have become more promising recently. This approach uses a single model that utilizes audio and text representations from pre-trained speech recognition models (ASR), and outperforms traditional pipeline SLU systems in on-device streaming scenarios. However, E2E SLU systems still show weakness when text representation quality is low due to ASR transcription errors. To overcome this issue, we propose a novel E2E SLU system that enhances robustness to ASR errors by fusing audio and text representations based on the estimated modality confidence of ASR hypotheses. We introduce two novel techniques: 1) an effective method to encode the quality of ASR hypotheses and 2) an effective approach to integrate them into E2E SLU models. We show accuracy improvements on STOP dataset and share the analysis to demonstrate the effectiveness of our approach.
Egocentric Audio-Visual Noise Suppression
Nov 07, 2022



This paper studies audio-visual suppression for egocentric videos -- where the speaker is not captured in the video. Instead, potential noise sources are visible on screen with the camera emulating the off-screen speaker's view of the outside world. This setting is different from prior work in audio-visual speech enhancement that relies on lip and facial visuals. In this paper, we first demonstrate that egocentric visual information is helpful for noise suppression. We compare object recognition and action classification based visual feature extractors, and investigate methods to align audio and visual representations. Then, we examine different fusion strategies for the aligned features, and locations within the noise suppression model to incorporate visual information. Experiments demonstrate that visual features are most helpful when used to generate additive correction masks. Finally, in order to ensure that the visual features are discriminative with respect to different noise types, we introduce a multi-task learning framework that jointly optimizes audio-visual noise suppression and video based acoustic event detection. This proposed multi-task framework outperforms the audio only baseline on all metrics, including a 0.16 PESQ improvement. Extensive ablations reveal the improved performance of the proposed model with multiple active distractors, over all noise types and across different SNRs.
Deep Learning for Needle Detection in a Cannulation Simulator
May 05, 2021

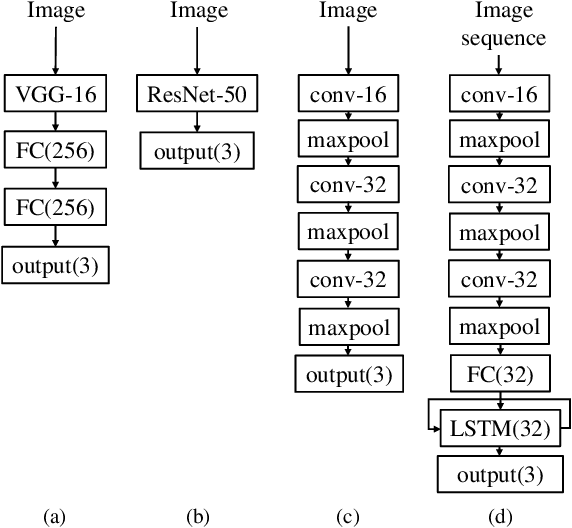
Cannulation for hemodialysis is the act of inserting a needle into a surgically created vascular access (e.g., an arteriovenous fistula) for the purpose of dialysis. The main risk associated with cannulation is infiltration, the puncture of the wall of the vascular access after entry, which can cause medical complications. Simulator-based training allows clinicians to gain cannulation experience without putting patients at risk. In this paper, we propose to use deep-learning-based techniques for detecting, based on video, whether the needle tip is in or has infiltrated the simulated fistula. Three categories of deep neural networks are investigated in this work: modified pre-trained models based on VGG-16 and ResNet-50, light convolutional neural networks (light CNNs), and convolutional recurrent neural networks (CRNNs). CRNNs consist of convolutional layers and a long short-term memory (LSTM) layer. A data set of cannulation experiments was collected and analyzed. The results show that both the light CNN and the CRNN achieve better performance than the pre-trained baseline models. The CRNN was implemented in real time on commodity hardware for use in the cannulation simulator, and the performance was verified. Deep-learning video analysis is a viable method for detecting needle state in a low cost cannulation simulator. Our data sets and code are released at https://github.com/axin233/DL_for_Needle_Detection_Cannulation
Speech Enhancement Using Multi-Stage Self-Attentive Temporal Convolutional Networks
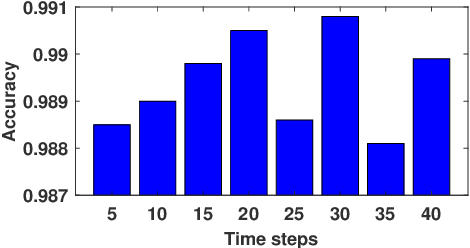
Feb 24, 2021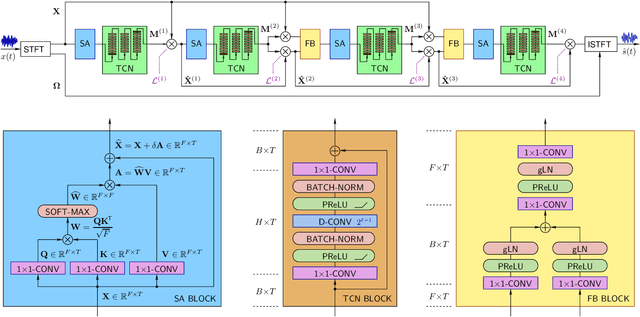
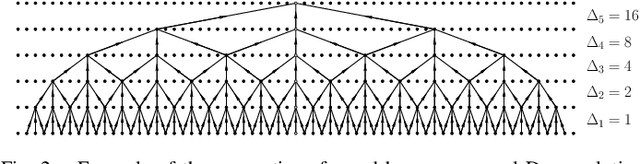
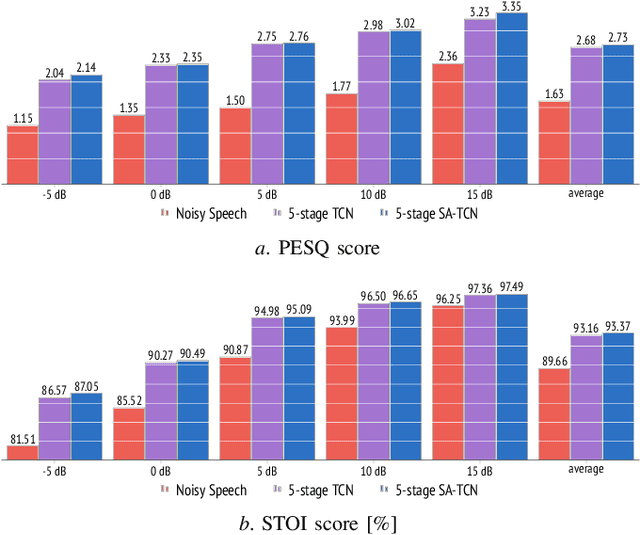
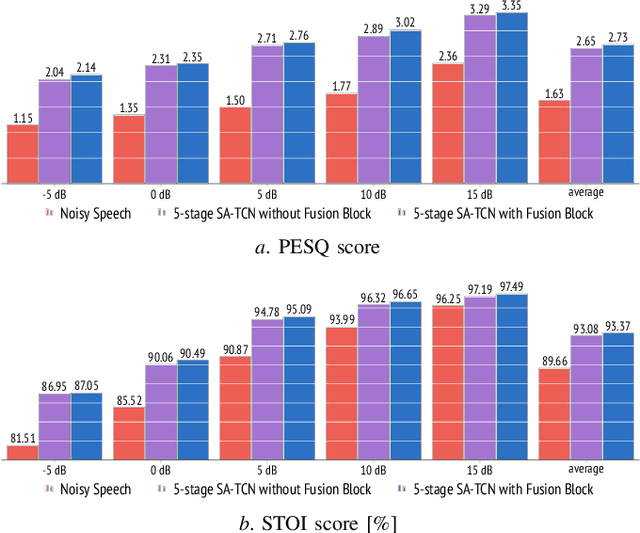
Multi-stage learning is an effective technique to invoke multiple deep-learning modules sequentially. This paper applies multi-stage learning to speech enhancement by using a multi-stage structure, where each stage comprises a self-attention (SA) block followed by stacks of temporal convolutional network (TCN) blocks with doubling dilation factors. Each stage generates a prediction that is refined in a subsequent stage. A fusion block is inserted at the input of later stages to re-inject original information. The resulting multi-stage speech enhancement system, in short, multi-stage SA-TCN, is compared with state-of-the-art deep-learning speech enhancement methods using the LibriSpeech and VCTK data sets. The multi-stage SA-TCN system's hyper-parameters are fine-tuned, and the impact of the SA block, the fusion block and the number of stages are determined. The use of a multi-stage SA-TCN system as a front-end for automatic speech recognition systems is investigated as well. It is shown that the multi-stage SA-TCN systems perform well relative to other state-of-the-art systems in terms of speech enhancement and speech recognition scores.