 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use of Self-Supervised Representation Learning for Speaker Diarization and Separation
Dec 17, 2025



Self-supervised speech models such as wav2vec2.0 and WavLM have been shown to significantly improve the performance of many downstream speech tasks, especially in low-resource settings, over the past few years. Despite this, evaluations on tasks such as Speaker Diarization and Speech Separation remain limited. This paper investigates the quality of recent self-supervised speech representations on these two speaker identity-related tasks, highlighting gaps in the current literature that stem from limitations in the existing benchmarks, particularly the lack of diversity in evaluation datasets and variety in downstream systems associated to both diarization and separation.
Dissecting the Segmentation Model of End-to-End Diarization with Vector Clustering
Jun 13, 2025



End-to-End Neural Diarization with Vector Clustering is a powerful and practical approach to perform Speaker Diarization. Multiple enhancements have been proposed for the segmentation model of these pipelines, but their synergy had not been thoroughly evaluated. In this work, we provide an in-depth analysis on the impact of major architecture choices on the performance of the pipeline. We investigate different encoders (SincNet, pretrained and finetuned WavLM), different decoders (LSTM, Mamba, and Conformer), different losses (multilabel and multiclass powerset), and different chunk sizes. Through in-depth experiments covering nine datasets, we found that the finetuned WavLM-based encoder always results in the best systems by a wide margin. The LSTM decoder is outclassed by Mamba- and Conformer-based decoders, and while we found Mamba more robust to other architecture choices, it is slightly inferior to our best architecture, which uses a Conformer encoder. We found that multilabel and multiclass powerset losses do not have the same distribution of errors. We confirmed that the multiclass loss helps almost all models attain superior performance, except when finetuning WavLM, in which case, multilabel is the superior choice. We also evaluated the impact of the chunk size on all aforementioned architecture choices and found that newer architectures tend to better handle long chunk sizes, which can greatly improve pipeline performance. Our best system achieved state-of-the-art results on five widely used speaker diarization datasets.
On the calibration of powerset speaker diarization models
Sep 24, 2024End-to-end neural diarization models have usually relied on a multilabel-classification formulation of the speaker diarization problem. Recently, we proposed a powerset multiclass formulation that has beaten the state-of-the-art on multiple datasets. In this paper, we propose to study the calibration of a powerset speaker diarization model, and explore some of its uses. We study the calibration in-domain, as well as out-of-domain, and explore the data in low-confidence regions. The reliability of model confidence is then tested in practice: we use the confidence of the pretrained model to selectively create training and validation subsets out of unannotated data, and compare this to random selection. We find that top-label confidence can be used to reliably predict high-error regions. Moreover, training on low-confidence regions provides a better calibrated model, and validating on low-confidence regions can be more annotation-efficient than random regions.
TalTech-IRIT-LIS Speaker and Language Diarization Systems for DISPLACE 2024
Jul 17, 2024



This paper describes the submissions of team TalTech-IRIT-LIS to the DISPLACE 2024 challenge. Our team participated in the speaker diarization and language diarization tracks of the challenge. In the speaker diarization track, our best submission was an ensemble of systems based on the pyannote.audio speaker diarization pipeline utilizing powerset training and our recently proposed PixIT method that performs joint diarization and speech separation. We improve upon PixIT by using the separation outputs for speaker embedding extraction. Our ensemble achieved a diarization error rate of 27.1% on the evaluation dataset. In the language diarization track, we fine-tuned a pre-trained Wav2Vec2-BERT language embedding model on in-domain data, and clustered short segments using AHC and VBx, based on similarity scores from LDA/PLDA. This led to a language diarization error rate of 27.6% on the evaluation data. Both results were ranked first in their respective challenge tracks.
PixIT: Joint Training of Speaker Diarization and Speech Separation from Real-world Multi-speaker Recordings
Mar 04, 2024



A major drawback of supervised speech separation (SSep) systems is their reliance on synthetic data, leading to poor real-world generalization. Mixture invariant training (MixIT) was proposed as an unsupervised alternative that uses real recordings, yet struggles with overseparation and adapting to long-form audio. We introduce PixIT, a joint approach that combines permutation invariant training (PIT) for speaker diarization (SD) and MixIT for SSep. With a small extra requirement of needing SD labels, it solves the problem of overseparation and allows stitching local separated sources leveraging existing work on clustering-based neural SD. We measure the quality of the separated sources via applying automatic speech recognition (ASR) systems to them. PixIT boosts the performance of various ASR systems across two meeting corpora both in terms of the speaker-attributed and utterance-based word error rates while not requiring any fine-tuning.
Powerset multi-class cross entropy loss for neural speaker diarization
Oct 19, 2023


Since its introduction in 2019, the whole end-to-end neural diarization (EEND) line of work has been addressing speaker diarization as a frame-wise multi-label classification problem with permutation-invariant training. Despite EEND showing great promise, a few recent works took a step back and studied the possible combination of (local) supervised EEND diarization with (global) unsupervised clustering. Yet, these hybrid contributions did not question the original multi-label formulation. We propose to switch from multi-label (where any two speakers can be active at the same time) to powerset multi-class classification (where dedicated classes are assigned to pairs of overlapping speakers). Through extensive experiments on 9 different benchmarks, we show that this formulation leads to significantly better performance (mostly on overlapping speech) and robustness to domain mismatch, while eliminating the detection threshold hyperparameter, critical for the multi-label formulation.
BabySLM: language-acquisition-friendly benchmark of self-supervised spoken language models
Jun 08, 2023



Self-supervised techniques for learning speech representations have been shown to develop linguistic competence from exposure to speech without the need for human labels. In order to fully realize the potential of these approaches and further our understanding of how infants learn language, simulations must closely emulate real-life situations by training on developmentally plausible corpora and benchmarking against appropriate test sets. To this end, we propose a language-acquisition-friendly benchmark to probe spoken language models at the lexical and syntactic levels, both of which are compatible with the vocabulary typical of children's language experiences. This paper introduces the benchmark and summarizes a range of experiments showing its usefulness. In addition, we highlight two exciting challenges that need to be addressed for further progress: bridging the gap between text and speech and between clean speech and in-the-wild speech.
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation
Oct 27, 2022



Most automatic speech processing systems are sensitive to the acoustic environment, with degraded performance when applied to noisy or reverberant speech. But how can one tell whether speech is noisy or reverberant? We propose Brouhaha, a pipeline to simulate audio segments recorded in noisy and reverberant conditions. We then use the simulated audio to jointly train the Brouhaha model for voice activity detection, signal-to-noise ratio estimation, and C50 room acoustics prediction. We show how the predicted SNR and C50 values can be used to investigate and help diagnose errors made by automatic speech processing tools (such as pyannote.audio for speaker diarization or OpenAI's Whisper for automatic speech recognition). Both our pipeline and a pretrained model are open source and shared with the speech community.
Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation
Sep 14, 2021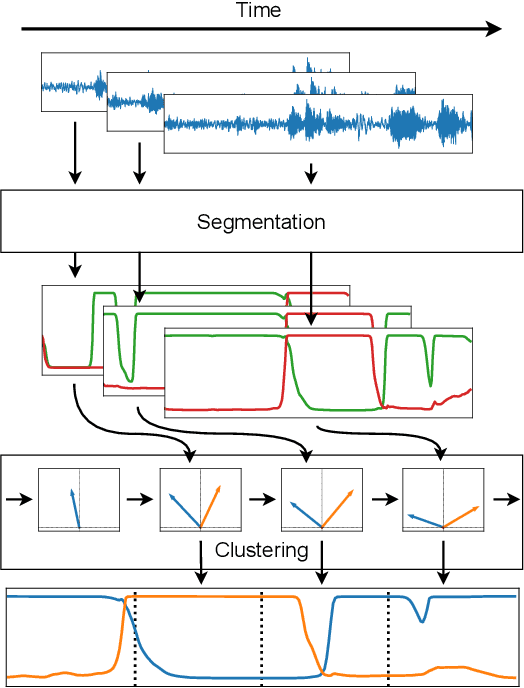

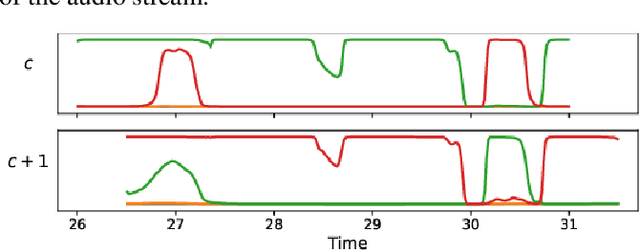
We propose to address online speaker diarization as a combination of incremental clustering and local diarization applied to a rolling buffer updated every 500ms. Every single step of the proposed pipeline is designed to take full advantage of the strong ability of a recently proposed end-to-end overlap-aware segmentation to detect and separate overlapping speakers. In particular, we propose a modified version of the statistics pooling layer (initially introduced in the x-vector architecture) to give less weight to frames where the segmentation model predicts simultaneous speakers. Furthermore, we derive cannot-link constraints from the initial segmentation step to prevent two local speakers from being wrongfully merged during the incremental clustering step. Finally, we show how the latency of the proposed approach can be adjusted between 500ms and 5s to match the requirements of a particular use case, and we provide a systematic analysis of the influence of latency on the overall performance (on AMI, DIHARD and VoxConverse).
End-to-end speaker segmentation for overlap-aware resegmentation
Apr 08, 2021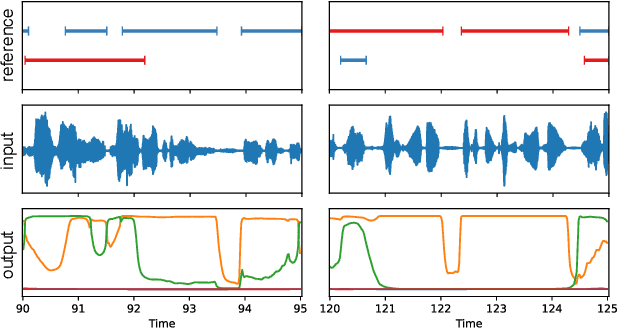
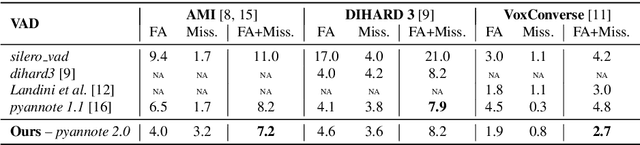
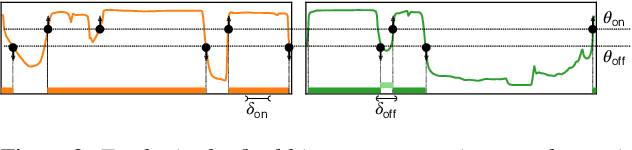

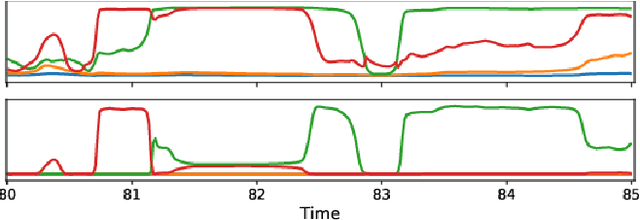
Speaker segmentation consists in partitioning a conversation between one or more speakers into speaker turns. Usually addressed as the late combination of three sub-tasks (voice activity detection, speaker change detection, and overlapped speech detection), we propose to train an end-to-end segmentation model that does it directly. Inspired by the original end-to-end neural speaker diarization approach (EEND), the task is modeled as a multi-label classification problem using permutation-invariant training. The main difference is that our model operates on short audio chunks (5 seconds) but at a much higher temporal resolution (every 16ms). Experiments on multiple speaker diarization datasets conclude that our model can be used with great success on both voice activity detection and overlapped speech detection. Our proposed model can also be used as a post-processing step, to detect and correctly assign overlapped speech regions. Relative diarization error rate improvement over the best considered baseline (VBx) reaches 18% on AMI, 17% on DIHARD 3, and 16% on VoxConverse.