 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxKnesset: A Large-Scale Longitudinal Hebrew Speech Dataset for Aging Speaker Modeling
Mar 05, 2026Speech processing systems face a fundamental challenge: the human voice changes with age, yet few datasets support rigorous longitudinal evaluation. We introduce VoxKnesset, an open-access dataset of ~2,300 hours of Hebrew parliamentary speech spanning 2009-2025, comprising 393 speakers with recording spans of up to 15 years. Each segment includes aligned transcripts and verified demographic metadata from official parliamentary records. We benchmark modern speech embeddings (WavLM-Large, ECAPA-TDNN, Wav2Vec2-XLSR-1B) on age prediction and speaker verification under longitudinal conditions. Speaker verification EER rises from 2.15\% to 4.58\% over 15 years for the strongest model, and cross-sectionally trained age regressors fail to capture within-speaker aging, while longitudinally trained models recover a meaningful temporal signal. We publicly release the dataset and pipeline to support aging-robust speech systems and Hebrew speech processing.
HPP-Voice: A Large-Scale Evaluation of Speech Embeddings for Multi-Phenotypic Classification
May 22, 2025Human speech contains paralinguistic cues that reflect a speaker's physiological and neurological state, potentially enabling non-invasive detection of various medical phenotypes. We introduce the Human Phenotype Project Voice corpus (HPP-Voice): a dataset of 7,188 recordings in which Hebrew-speaking adults count for 30 seconds, with each speaker linked to up to 15 potentially voice-related phenotypes spanning respiratory, sleep, mental health, metabolic, immune, and neurological conditions. We present a systematic comparison of 14 modern speech embedding models, where modern speech embeddings from these 30-second counting tasks outperform MFCCs and demographics for downstream health condition classifications. We found that embedding learned from a speaker identification model can predict objectively measured moderate to severe sleep apnea in males with an AUC of 0.64 $\pm$ 0.03, while MFCC and demographic features led to AUCs of 0.56 $\pm$ 0.02 and 0.57 $\pm$ 0.02, respectively. Additionally, our results reveal gender-specific patterns in model effectiveness across different medical domains. For males, speaker identification and diarization models consistently outperformed speech foundation models for respiratory conditions (e.g., asthma: 0.61 $\pm$ 0.03 vs. 0.56 $\pm$ 0.02) and sleep-related conditions (insomnia: 0.65 $\pm$ 0.04 vs. 0.59 $\pm$ 0.05). For females, speaker diarization models performed best for smoking status (0.61 $\pm$ 0.02 vs 0.55 $\pm$ 0.02), while Hebrew-specific models performed best (0.59 $\pm$ 0.02 vs. 0.58 $\pm$ 0.02) in classifying anxiety compared to speech foundation models. Our findings provide evidence that a simple counting task can support large-scale, multi-phenotypic voice screening and highlight which embedding families generalize best to specific conditions, insights that can guide future vocal biomarker research and clinical deployment.
Non-verbal information in spontaneous speech -- towards a new framework of analysis
Mar 13, 2024


Non-verbal signals in speech are encoded by prosody and carry information that ranges from conversation action to attitude and emotion. Despite its importance, the principles that govern prosodic structure are not yet adequately understood. This paper offers an analytical schema and a technological proof-of-concept for the categorization of prosodic signals and their association with meaning. The schema interprets surface-representations of multi-layered prosodic events. As a first step towards implementation, we present a classification process that disentangles prosodic phenomena of three orders. It relies on fine-tuning a pre-trained speech recognition model, enabling the simultaneous multi-class/multi-label detection. It generalizes over a large variety of spontaneous data, performing on a par with, or superior to, human annotation. In addition to a standardized formalization of prosody, disentangling prosodic patterns can direct a theory of communication and speech organization. A welcome by-product is an interpretation of prosody that will enhance speech- and language-related technologies.
ivrit.ai: A Comprehensive Dataset of Hebrew Speech for AI Research and Development
Jul 17, 2023



We introduce "ivrit.ai", a comprehensive Hebrew speech dataset, addressing the distinct lack of extensive, high-quality resources for advancing Automated Speech Recognition (ASR) technology in Hebrew. With over 3,300 speech hours and a over a thousand diverse speakers, ivrit.ai offers a substantial compilation of Hebrew speech across various contexts. It is delivered in three forms to cater to varying research needs: raw unprocessed audio; data post-Voice Activity Detection, and partially transcribed data. The dataset stands out for its legal accessibility, permitting use at no cost, thereby serving as a crucial resource for researchers, developers, and commercial entities. ivrit.ai opens up numerous applications, offering vast potential to enhance AI capabilities in Hebrew. Future efforts aim to expand ivrit.ai further, thereby advancing Hebrew's standing in AI research and technology.
Image Animation with Keypoint Mask
Dec 21, 2021
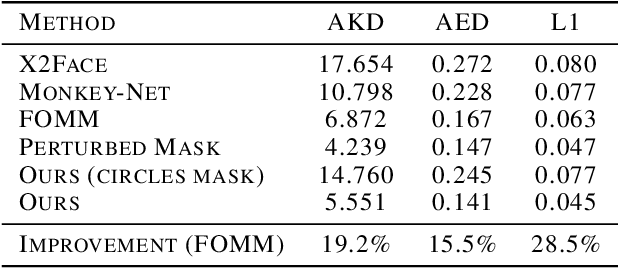

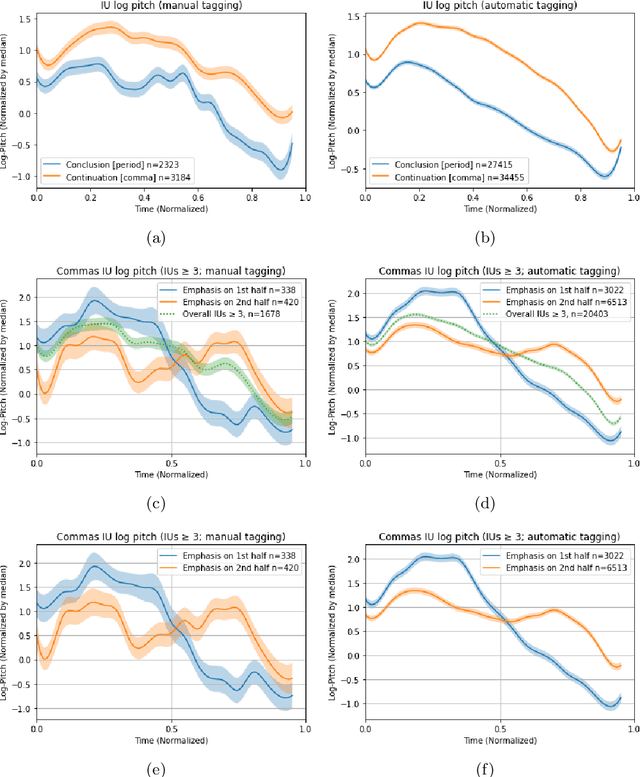
Motion transfer is the task of synthesizing future video frames of a single source image according to the motion from a given driving video. In order to solve it, we face the challenging complexity of motion representation and the unknown relations between the driving video and the source image. Despite its difficulty, this problem attracted great interests from researches at the recent years, with gradual improvements. The goal is often thought as the decoupling of motion and appearance, which is may be solved by extracting the motion from keypoint movement. We chose to tackle the generic, unsupervised setting, where we need to apply animation to any arbitrary object, without any domain specific model for the structure of the input. In this work, we extract the structure from a keypoint heatmap, without an explicit motion representation. Then, the structures from the image and the video are extracted to warp the image according to the video, by a deep generator. We suggest two variants of the structure from different steps in the keypoint module, and show superior qualitative pose and quantitative scores.