 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Im2Pencil: Controllable Pencil Illustration from Photographs
Mar 20, 2019
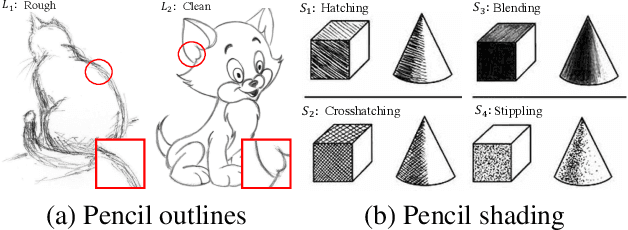


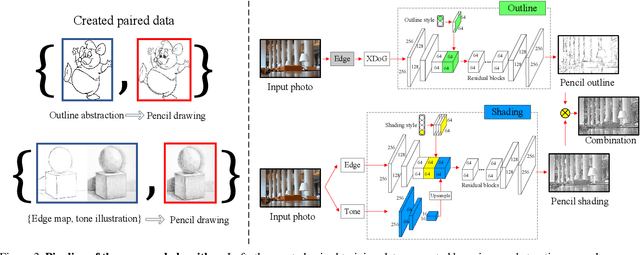
We propose a high-quality photo-to-pencil translation method with fine-grained control over the drawing style. This is a challenging task due to multiple stroke types (e.g., outline and shading), structural complexity of pencil shading (e.g., hatching), and the lack of aligned training data pairs. To address these challenges, we develop a two-branch model that learns separate filters for generating sketchy outlines and tonal shading from a collection of pencil drawings. We create training data pairs by extracting clean outlines and tonal illustrations from original pencil drawings using image filtering techniques, and we manually label the drawing styles. In addition, our model creates different pencil styles (e.g., line sketchiness and shading style) in a user-controllable manner. Experimental results on different types of pencil drawings show that the proposed algorithm performs favorably against existing methods in terms of quality, diversity and user evaluations.
ELF: Embedded Localisation of Features in pre-trained CNN
Jul 07, 2019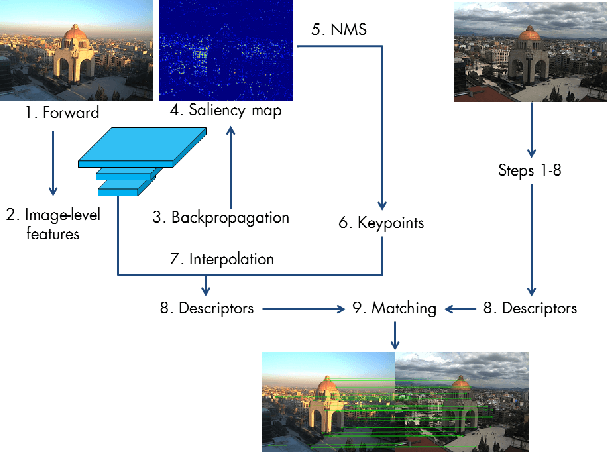
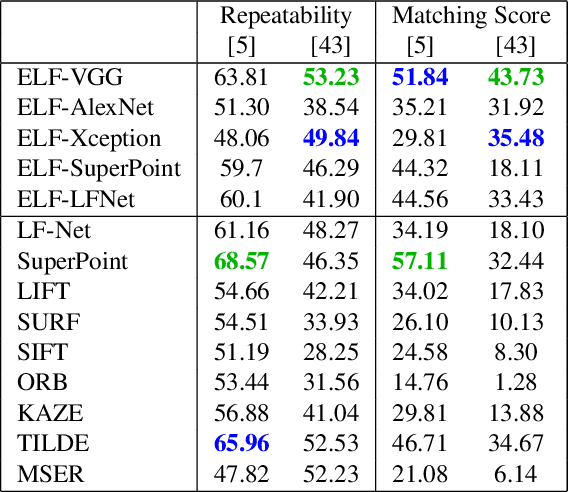

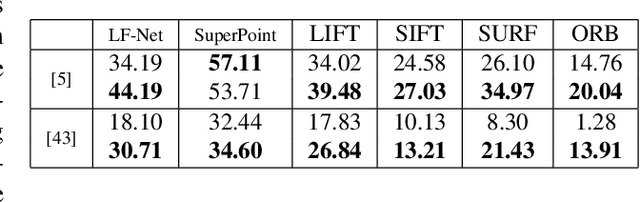
This paper introduces a novel feature detector based only on information embedded inside a CNN trained on standard tasks (e.g. classification). While previous works already show that the features of a trained CNN are suitable descriptors, we show here how to extract the feature locations from the network to build a detector. This information is computed from the gradient of the feature map with respect to the input image. This provides a saliency map with local maxima on relevant keypoint locations. Contrary to recent CNN-based detectors, this method requires neither supervised training nor finetuning. We evaluate how repeatable and how matchable the detected keypoints are with the repeatability and matching scores. Matchability is measured with a simple descriptor introduced for the sake of the evaluation. This novel detector reaches similar performances on the standard evaluation HPatches dataset, as well as comparable robustness against illumination and viewpoint changes on Webcam and photo-tourism images. These results show that a CNN trained on a standard task embeds feature location information that is as relevant as when the CNN is specifically trained for feature detection.
DeepRacing: Parameterized Trajectories for Autonomous Racing
May 06, 2020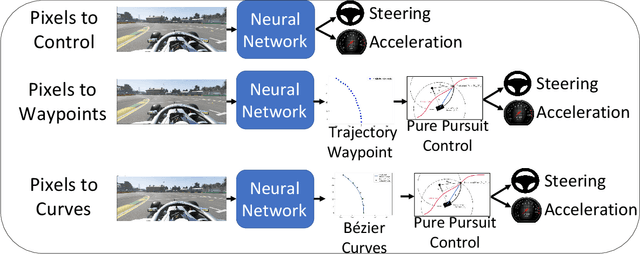
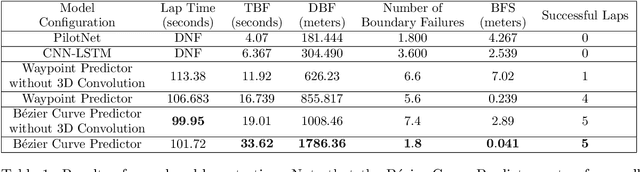
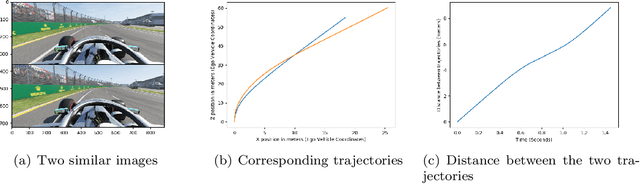
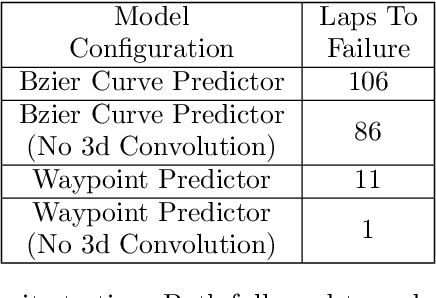
We consider the challenging problem of high speed autonomous racing in a realistic Formula One environment. DeepRacing is a novel end-to-end framework, and a virtual testbed for training and evaluating algorithms for autonomous racing. The virtual testbed is implemented using the realistic F1 series of video games, developed by Codemasters, which many Formula One drivers use for training. This virtual testbed is released under an open-source license both as a standalone C++ API and as a binding to the popular Robot Operating System 2 (ROS2) framework. This open-source API allows anyone to use the high fidelity physics and photo-realistic capabilities of the F1 game as a simulator, and without hacking any game engine code. We use this framework to evaluate several neural network methodologies for autonomous racing. Specifically, we consider several fully end-to-end models that directly predict steering and acceleration commands for an autonomous race car as well as a model that predicts a list of waypoints to follow in the car's local coordinate system, with the task of selecting a steering/throttle angle left to a classical control algorithm. We also present a novel method of autonomous racing by training a deep neural network to predict a parameterized representation of a trajectory rather than a list of waypoints. We evaluate these models performance in our open-source simulator and show that trajectory prediction far outperforms end-to-end driving. Additionally, we show that open-loop performance for an end-to-end model, i.e. root-mean-square error for a model's predicted control values, does not necessarily correlate with increased driving performance in the closed-loop sense, i.e. actual ability to race around a track. Finally, we show that our proposed model of parameterized trajectory prediction outperforms both end-to-end control and waypoint prediction.
Camera-based Image Forgery Localization using Convolutional Neural Networks
Aug 29, 2018
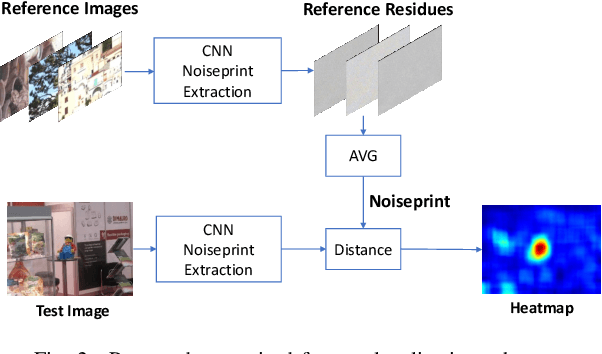
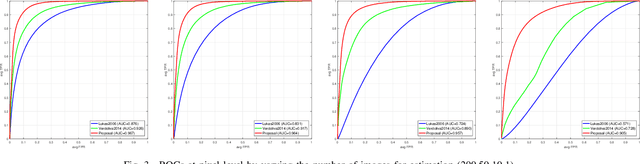
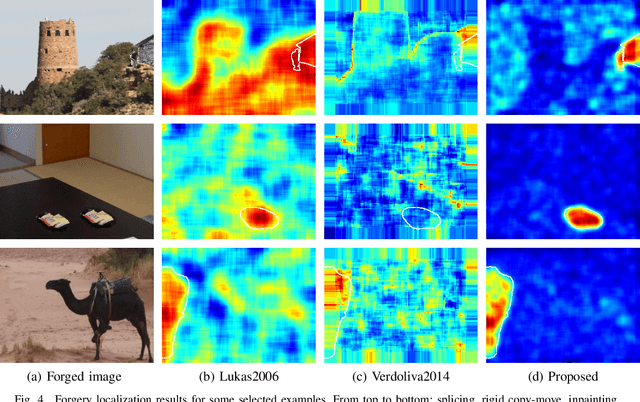
Camera fingerprints are precious tools for a number of image forensics tasks. A well-known example is the photo response non-uniformity (PRNU) noise pattern, a powerful device fingerprint. Here, to address the image forgery localization problem, we rely on noiseprint, a recently proposed CNN-based camera model fingerprint. The CNN is trained to minimize the distance between same-model patches, and maximize the distance otherwise. As a result, the noiseprint accounts for model-related artifacts just like the PRNU accounts for device-related non-uniformities. However, unlike the PRNU, it is only mildly affected by residuals of high-level scene content. The experiments show that the proposed noiseprint-based forgery localization method improves over the PRNU-based reference.
Analyzing Solar Irradiance Variation From GPS and Cameras
Apr 19, 2018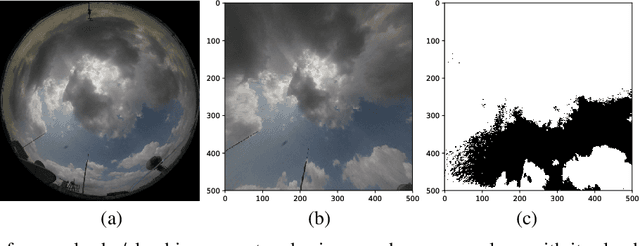
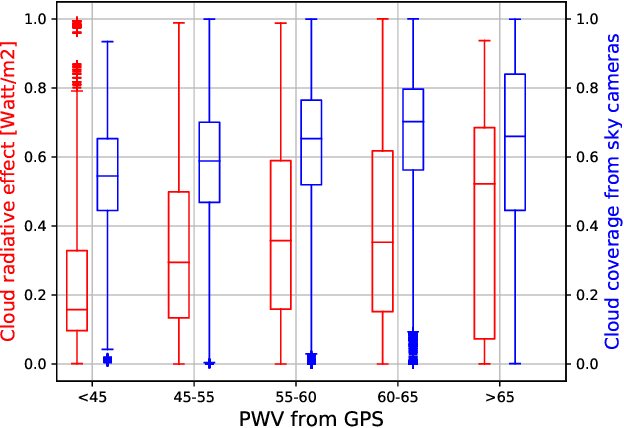
The total amount of solar irradiance falling on the earth's surface is an important area of study amongst the photo-voltaic (PV) engineers and remote sensing analysts. The received solar irradiance impacts the total amount of generated solar energy. However, this generation is often hindered by the high degree of solar irradiance variability. In this paper, we study the main factors behind such variability with the assistance of Global Positioning System (GPS) and ground-based, high-resolution sky cameras. This analysis will also be helpful for understanding cloud phenomenon and other events in the earth's atmosphere.
ClsGAN: Selective Attribute Editing Based On Classification Adversarial Network
Oct 25, 2019

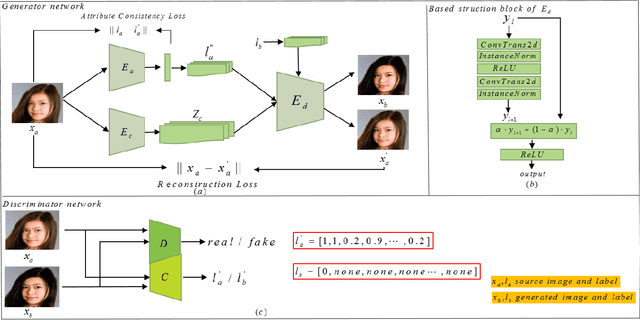

Attribution editing has shown remarking progress by the incorporating of encoder-decoder structure and generative adversarial network. However, there are still some challenges in the quality and attribute transformation of the generated images. Encoder-decoder structure leads to blurring of images and the skip-connection of encoder-decoder structure weakens the attribute transfer ability. To address these limitations, we propose a classification adversarial model(Cls-GAN) that can balance between attribute transfer and generated photo-realistic images. Considering that the transfer images are affected by the original attribute using skip-connection, we introduce upper convolution residual network(Tr-resnet) to selectively extract information from the source image and target label. Specially, we apply to the attribute classification adversarial network to learn about the defects of attribute transfer images so as to guide the generator. Finally, to meet the requirement of multimodal and improve reconstruction effect, we build two encoders including the content and style network, and select a attribute label approximation between source label and the output of style network. Experiments that operates at the dataset of CelebA show that images are superiority against the existing state-of-the-art models in image quality and transfer accuracy. Experiments on wikiart and seasonal datasets demonstrate that ClsGAN can effectively implement styel transfer.
Modeling Photographic Composition via Triangles
May 31, 2016
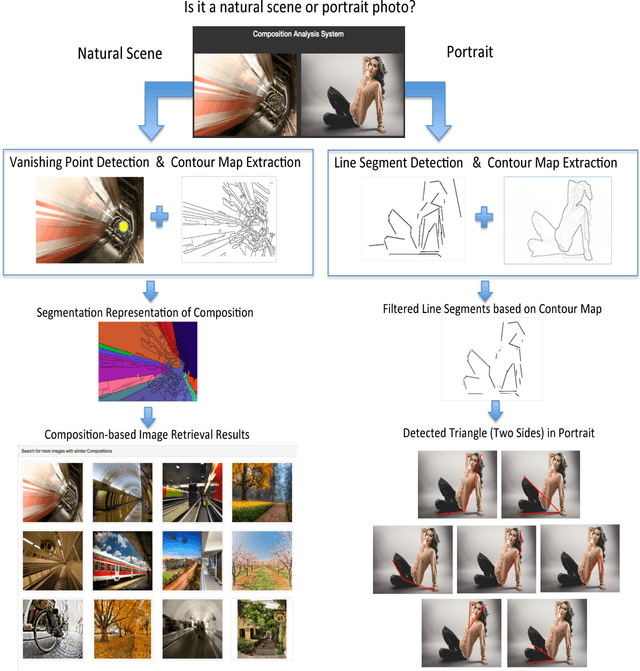

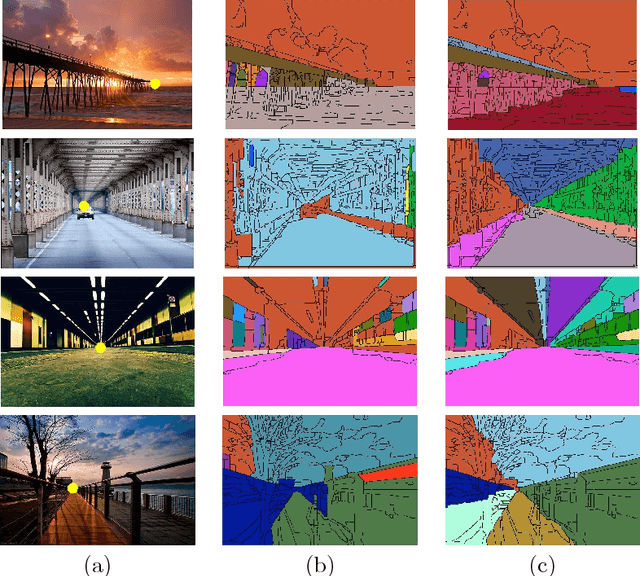
The capacity of automatically modeling photographic composition is valuable for many real-world machine vision applications such as digital photography, image retrieval, image understanding, and image aesthetics assessment. The triangle technique is among those indispensable composition methods on which professional photographers often rely. This paper proposes a system that can identify prominent triangle arrangements in two major categories of photographs: natural or urban scenes, and portraits. For the natural or urban scene pictures, the focus is on the effect of linear perspective. For portraits, we carefully examine the positioning of human subjects in a photo. We show that line analysis is highly advantageous for modeling composition in both categories. Based on the detected triangles, new mathematical descriptors for composition are formulated and used to retrieve similar images. Leveraging the rich source of high aesthetics photos online, similar approaches can potentially be incorporated in future smart cameras to enhance a person's photo composition skills.
Embodied Question Answering in Photorealistic Environments with Point Cloud Perception
Apr 06, 2019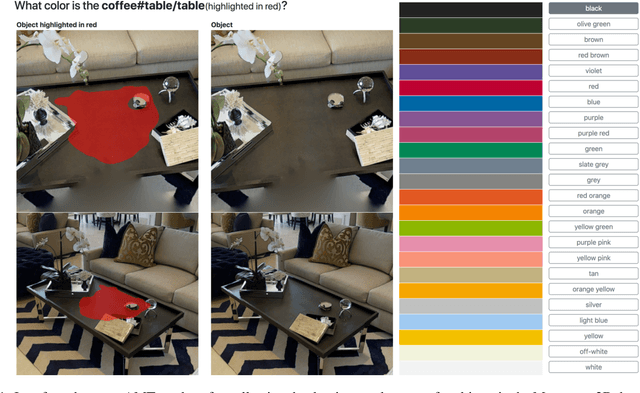
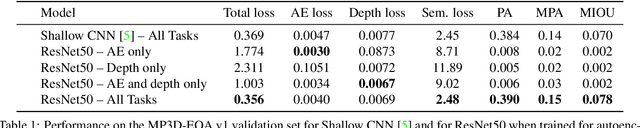
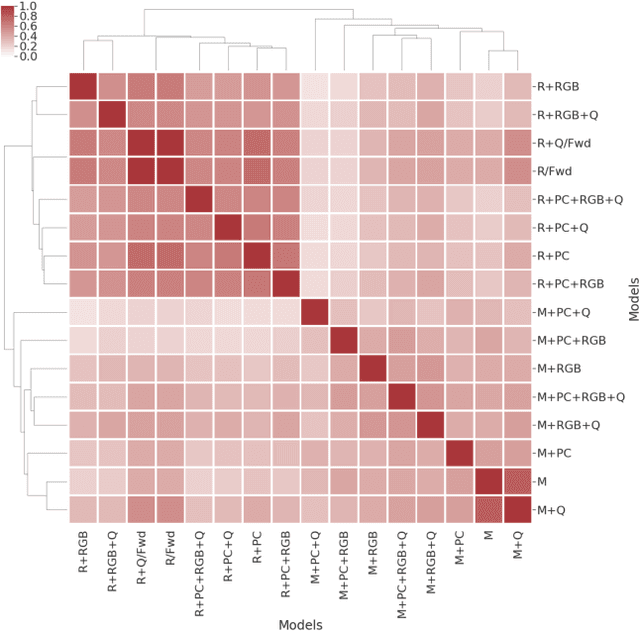
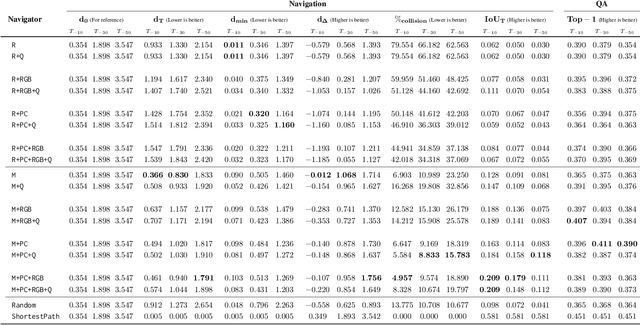
To help bridge the gap between internet vision-style problems and the goal of vision for embodied perception we instantiate a large-scale navigation task -- Embodied Question Answering [1] in photo-realistic environments (Matterport 3D). We thoroughly study navigation policies that utilize 3D point clouds, RGB images, or their combination. Our analysis of these models reveals several key findings. We find that two seemingly naive navigation baselines, forward-only and random, are strong navigators and challenging to outperform, due to the specific choice of the evaluation setting presented by [1]. We find a novel loss-weighting scheme we call Inflection Weighting to be important when training recurrent models for navigation with behavior cloning and are able to out perform the baselines with this technique. We find that point clouds provide a richer signal than RGB images for learning obstacle avoidance, motivating the use (and continued study) of 3D deep learning models for embodied navigation.
Generate, Segment and Replace: Towards Generic Manipulation Segmentation
Nov 24, 2018
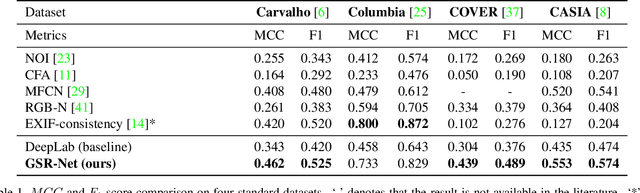
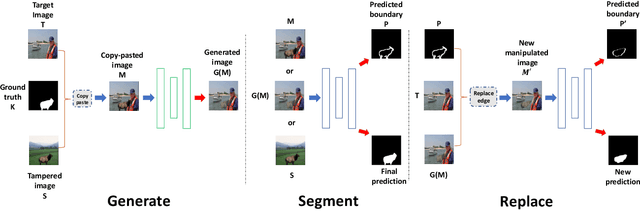
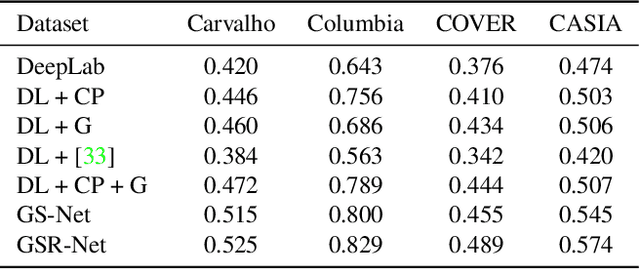
It has been witnessed an emerging demand for image manipulation segmentation to distinguish between fake images produced by advanced photo editing software and authentic ones. In this paper, we describe an approach based on semantic segmentation for detecting image manipulation. The approach consists of three stages. A generation stage generates hard manipulated images from authentic images using a Generative Adversarial Network (GAN) based model by cutting a region out of a training sample, pasting it into an authentic image and then passing the image through a GAN to generate harder true positive tampered region. A segmentation stage and a replacement stage, sharing weights with each other, then collaboratively construct dense predictions of tampered regions. We achieve state-of-the-art performance on four public image manipulation detection benchmarks while maintaining robustness to various attacks.
Wavelet Domain Style Transfer for an Effective Perception-distortion Tradeoff in Single Image Super-Resolution
Oct 09, 2019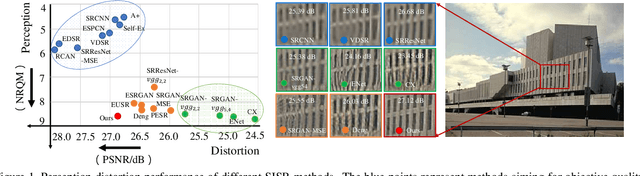
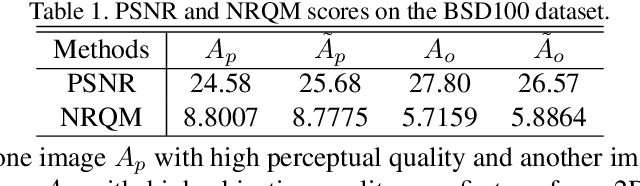
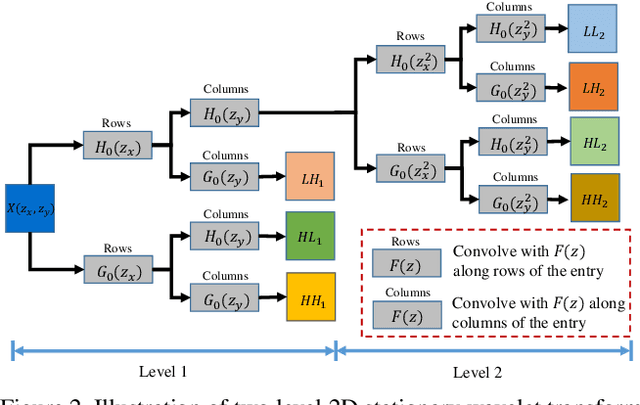
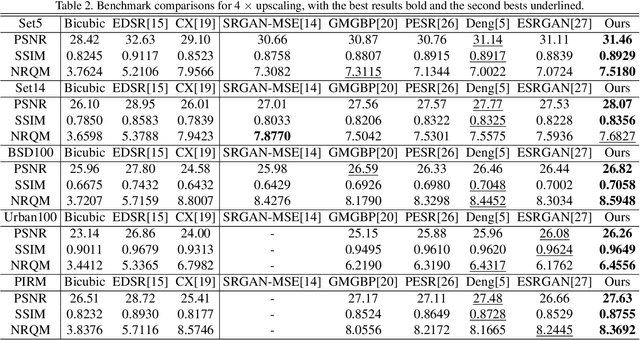
In single image super-resolution (SISR), given a low-resolution (LR) image, one wishes to find a high-resolution (HR) version of it which is both accurate and photo-realistic. Recently, it has been shown that there exists a fundamental tradeoff between low distortion and high perceptual quality, and the generative adversarial network (GAN) is demonstrated to approach the perception-distortion (PD) bound effectively. In this paper, we propose a novel method based on wavelet domain style transfer (WDST), which achieves a better PD tradeoff than the GAN based methods. Specifically, we propose to use 2D stationary wavelet transform (SWT) to decompose one image into low-frequency and high-frequency sub-bands. For the low-frequency sub-band, we improve its objective quality through an enhancement network. For the high-frequency sub-band, we propose to use WDST to effectively improve its perceptual quality. By feat of the perfect reconstruction property of wavelets, these sub-bands can be re-combined to obtain an image which has simultaneously high objective and perceptual quality. The numerical results on various datasets show that our method achieves the best trade-off between the distortion and perceptual quality among the existing state-of-the-art SISR methods.