 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LRRU: Long-short Range Recurrent Updating Networks for Depth Completion
Oct 13, 2023
Existing deep learning-based depth completion methods generally employ massive stacked layers to predict the dense depth map from sparse input data. Although such approaches greatly advance this task, their accompanied huge computational complexity hinders their practical applications. To accomplish depth completion more efficiently, we propose a novel lightweight deep network framework, the Long-short Range Recurrent Updating (LRRU) network. Without learning complex feature representations, LRRU first roughly fills the sparse input to obtain an initial dense depth map, and then iteratively updates it through learned spatially-variant kernels. Our iterative update process is content-adaptive and highly flexible, where the kernel weights are learned by jointly considering the guidance RGB images and the depth map to be updated, and large-to-small kernel scopes are dynamically adjusted to capture long-to-short range dependencies. Our initial depth map has coarse but complete scene depth information, which helps relieve the burden of directly regressing the dense depth from sparse ones, while our proposed method can effectively refine it to an accurate depth map with less learnable parameters and inference time. Experimental results demonstrate that our proposed LRRU variants achieve state-of-the-art performance across different parameter regimes. In particular, the LRRU-Base model outperforms competing approaches on the NYUv2 dataset, and ranks 1st on the KITTI depth completion benchmark at the time of submission. Project page: https://npucvr.github.io/LRRU/.
A Spatio-Temporal Attention-Based Method for Detecting Student Classroom Behaviors
Oct 18, 2023Accurately detecting student behavior from classroom videos is beneficial for analyzing their classroom status and improving teaching efficiency. However, low accuracy in student classroom behavior detection is a prevalent issue. To address this issue, we propose a Spatio-Temporal Attention-Based Method for Detecting Student Classroom Behaviors (BDSTA). Firstly, the SlowFast network is used to generate motion and environmental information feature maps from the video. Then, the spatio-temporal attention module is applied to the feature maps, including information aggregation, compression and stimulation processes. Subsequently, attention maps in the time, channel and space dimensions are obtained, and multi-label behavior classification is performed based on these attention maps. To solve the long-tail data problem that exists in student classroom behavior datasets, we use an improved focal loss function to assign more weight to the tail class data during training. Experimental results are conducted on a self-made student classroom behavior dataset named STSCB. Compared with the SlowFast model, the average accuracy of student behavior classification detection improves by 8.94\% using BDSTA.
On Identifying Points of Semantic Shift Across Domains
Oct 18, 2023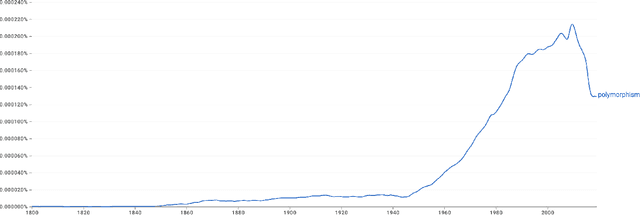
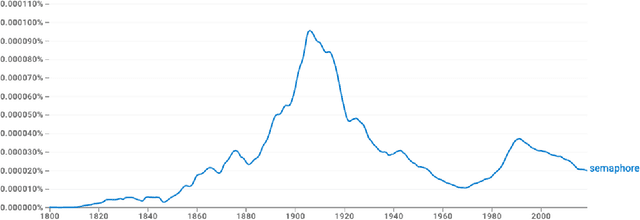
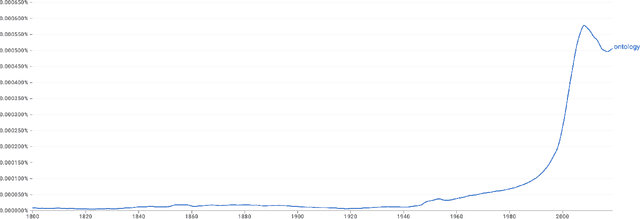
The semantics used for particular terms in an academic field organically evolve over time. Tracking this evolution through inspection of published literature has either been from the perspective of Linguistic scholars or has concentrated the focus of term evolution within a single domain of study. In this paper, we performed a case study to identify semantic evolution across different domains and identify examples of inter-domain semantic shifts. We initially used keywords as the basis of our search and executed an iterative process of following citations to find the initial mention of the concepts in the field. We found that a select set of keywords like ``semaphore'', ``polymorphism'', and ``ontology'' were mentioned within Computer Science literature and tracked the seminal study that borrowed those terms from original fields by citations. We marked these events as semantic evolution points. Through this manual investigation method, we can identify term evolution across different academic fields. This study reports our initial findings that will seed future automated and computational methods of incorporating concepts from additional academic fields.
DASA: Difficulty-Aware Semantic Augmentation for Speaker Verification
Oct 18, 2023Data augmentation is vital to the generalization ability and robustness of deep neural networks (DNNs) models. Existing augmentation methods for speaker verification manipulate the raw signal, which are time-consuming and the augmented samples lack diversity. In this paper, we present a novel difficulty-aware semantic augmentation (DASA) approach for speaker verification, which can generate diversified training samples in speaker embedding space with negligible extra computing cost. Firstly, we augment training samples by perturbing speaker embeddings along semantic directions, which are obtained from speaker-wise covariance matrices. Secondly, accurate covariance matrices are estimated from robust speaker embeddings during training, so we introduce difficultyaware additive margin softmax (DAAM-Softmax) to obtain optimal speaker embeddings. Finally, we assume the number of augmented samples goes to infinity and derive a closed-form upper bound of the expected loss with DASA, which achieves compatibility and efficiency. Extensive experiments demonstrate the proposed approach can achieve a remarkable performance improvement. The best result achieves a 14.6% relative reduction in EER metric on CN-Celeb evaluation set.
Property-Aware Multi-Speaker Data Simulation: A Probabilistic Modelling Technique for Synthetic Data Generation
Oct 18, 2023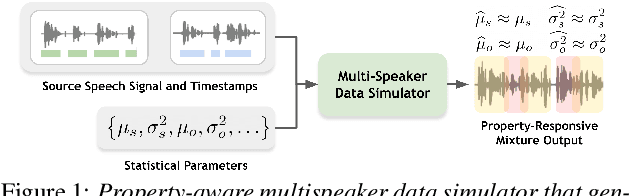
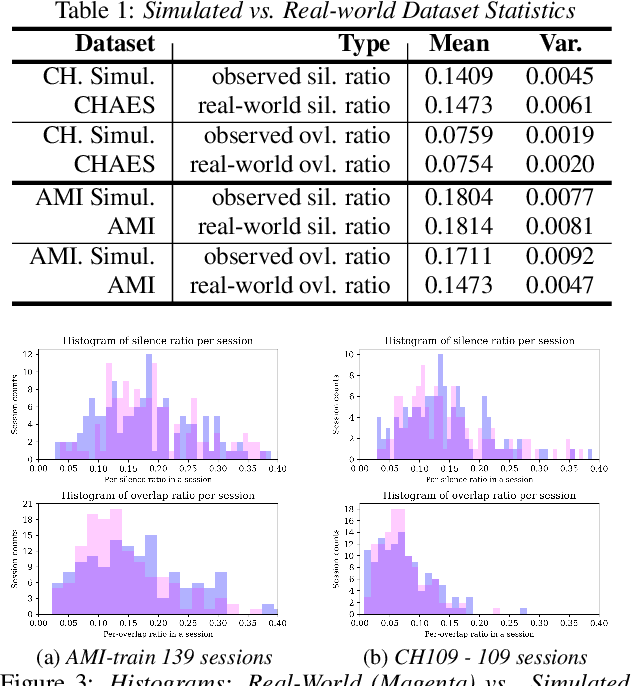
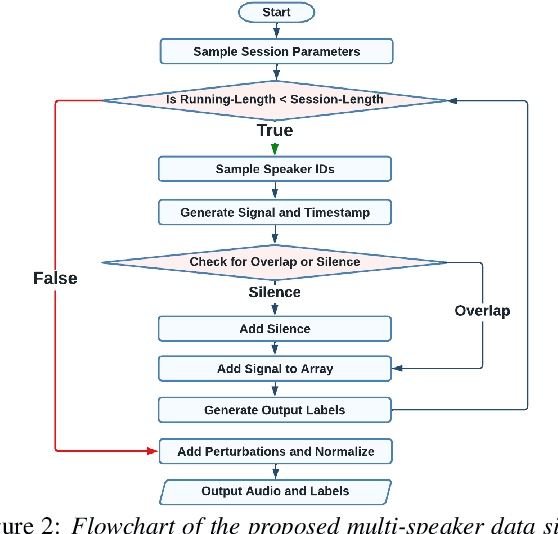
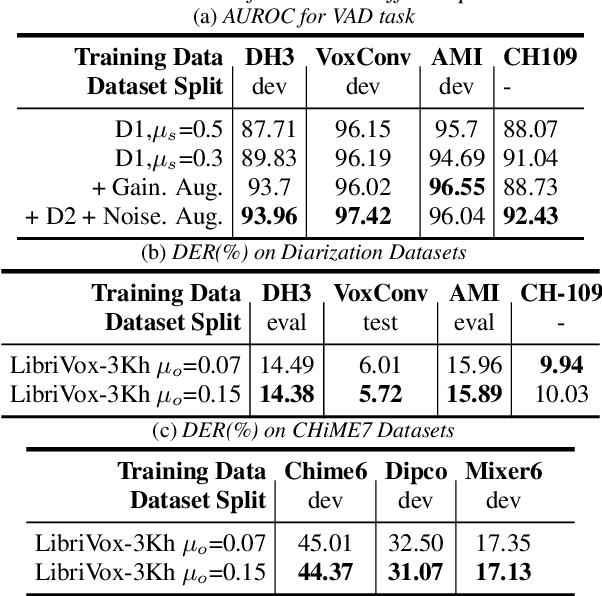
We introduce a sophisticated multi-speaker speech data simulator, specifically engineered to generate multi-speaker speech recordings. A notable feature of this simulator is its capacity to modulate the distribution of silence and overlap via the adjustment of statistical parameters. This capability offers a tailored training environment for developing neural models suited for speaker diarization and voice activity detection. The acquisition of substantial datasets for speaker diarization often presents a significant challenge, particularly in multi-speaker scenarios. Furthermore, the precise time stamp annotation of speech data is a critical factor for training both speaker diarization and voice activity detection. Our proposed multi-speaker simulator tackles these problems by generating large-scale audio mixtures that maintain statistical properties closely aligned with the input parameters. We demonstrate that the proposed multi-speaker simulator generates audio mixtures with statistical properties that closely align with the input parameters derived from real-world statistics. Additionally, we present the effectiveness of speaker diarization and voice activity detection models, which have been trained exclusively on the generated simulated datasets.
Take the aTrain. Introducing an Interface for the Accessible Transcription of Interviews
Oct 18, 2023aTrain is an open-source and offline tool for transcribing audio data in multiple languages with CPU and NVIDIA GPU support. It is specifically designed for researchers using qualitative data generated from various forms of speech interactions with research participants. aTrain requires no programming skills, runs on most computers, does not require an internet connection, and was verified not to upload data to any server. aTrain combines OpenAI's Whisper model with speaker recognition to provide output that integrates with the popular qualitative data analysis software tools MAXQDA and ATLAS.ti. It has an easy-to-use graphical interface and is provided as a Windows-App through the Microsoft Store allowing for simple installation by researchers. The source code is freely available on GitHub. Having developed aTrain with a focus on speed on local computers, we show that the transcription time on current mobile CPUs is around 2 to 3 times the duration of the audio file using the highest-accuracy transcription models. If an entry-level graphics card is available, the transcription speed increases to 20% of the audio duration.
SPEED: Speculative Pipelined Execution for Efficient Decoding
Oct 18, 2023Generative Large Language Models (LLMs) based on the Transformer architecture have recently emerged as a dominant foundation model for a wide range of Natural Language Processing tasks. Nevertheless, their application in real-time scenarios has been highly restricted due to the significant inference latency associated with these models. This is particularly pronounced due to the autoregressive nature of generative LLM inference, where tokens are generated sequentially since each token depends on all previous output tokens. It is therefore challenging to achieve any token-level parallelism, making inference extremely memory-bound. In this work, we propose SPEED, which improves inference efficiency by speculatively executing multiple future tokens in parallel with the current token using predicted values based on early-layer hidden states. For Transformer decoders that employ parameter sharing, the memory operations for the tokens executing in parallel can be amortized, which allows us to accelerate generative LLM inference. We demonstrate the efficiency of our method in terms of latency reduction relative to model accuracy and demonstrate how speculation allows for training deeper decoders with parameter sharing with minimal runtime overhead.
Illumination strategies for space-bandwidth-time product improvement in Fourier ptychography
Aug 26, 2023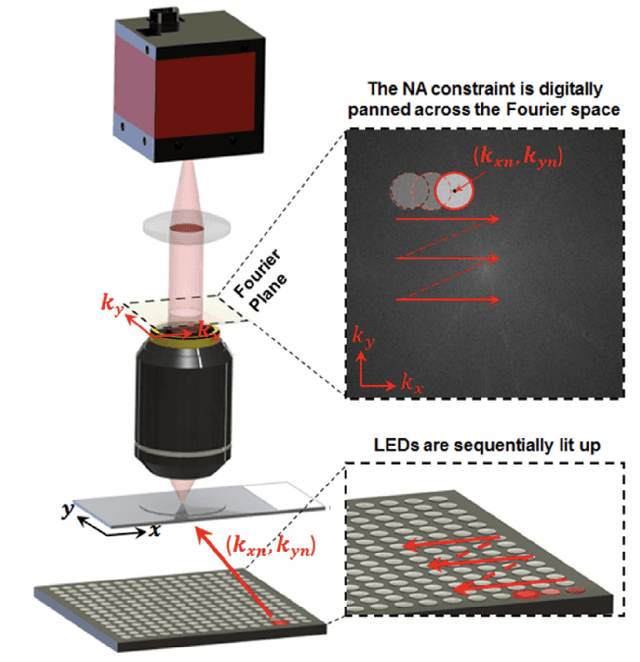
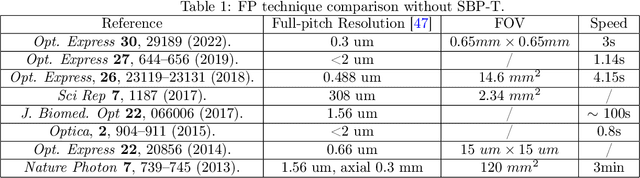
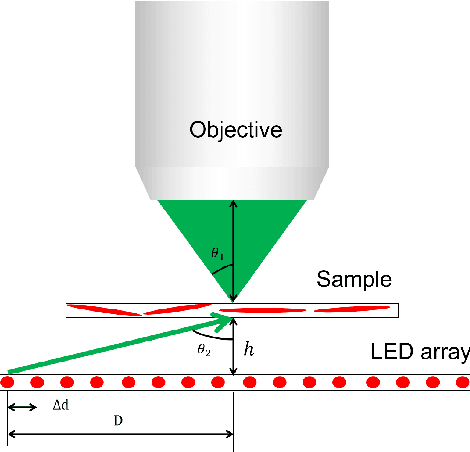
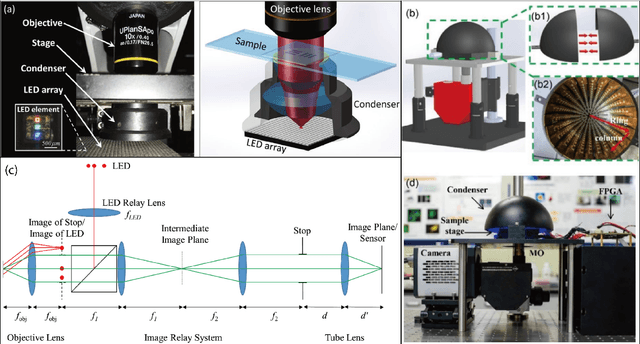
Fourier ptychography (FP) is a promising technique for high-throughput imaging. Reconstruction algorithms and illumination paradigm are two key aspects of FP. In this review, we mainly focus on illumination strategies in FP. We derive the space-bandwidth-time product (SBP-T) for the characterization of FP performance. Based on the analysis of SBP-T, we categorize the illumination strategy in FP effectively and discuss each category
Rapid Non-cartesian Reconstruction Using an Implicit Representation of GROG Kernels
Oct 16, 2023MRI data is acquired in Fourier space. Data acquisition is typically performed on a Cartesian grid in this space to enable the use of a fast Fourier transform algorithm to achieve fast and efficient reconstruction. However, it has been shown that for multiple applications, non-Cartesian data acquisition can improve the performance of MR imaging by providing fast and more efficient data acquisition, and improving motion robustness. Nonetheless, the image reconstruction process of non-Cartesian data is more involved and can be time-consuming, even through the use of efficient algorithms such as non-uniform FFT (NUFFT). This work provides an efficient approach (iGROG) to transform the non-Cartesian data into Cartesian data, to achieve simpler and faster reconstruction which should help enable non-Cartesian data sampling to be performed more widely in MRI.
KAKURENBO: Adaptively Hiding Samples in Deep Neural Network Training
Oct 16, 2023This paper proposes a method for hiding the least-important samples during the training of deep neural networks to increase efficiency, i.e., to reduce the cost of training. Using information about the loss and prediction confidence during training, we adaptively find samples to exclude in a given epoch based on their contribution to the overall learning process, without significantly degrading accuracy. We explore the converge properties when accounting for the reduction in the number of SGD updates. Empirical results on various large-scale datasets and models used directly in image classification and segmentation show that while the with-replacement importance sampling algorithm performs poorly on large datasets, our method can reduce total training time by up to 22% impacting accuracy only by 0.4% compared to the baseline. Code available at https://github.com/TruongThaoNguyen/kakurenbo