 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimization-Free Test-Time Adaptation for Cross-Person Activity Recognition
Oct 28, 2023
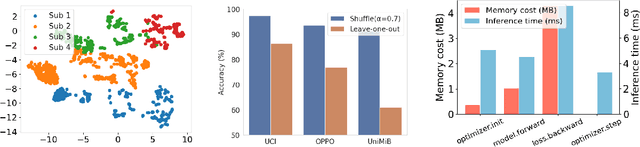


Human Activity Recognition (HAR) models often suffer from performance degradation in real-world applications due to distribution shifts in activity patterns across individuals. Test-Time Adaptation (TTA) is an emerging learning paradigm that aims to utilize the test stream to adjust predictions in real-time inference, which has not been explored in HAR before. However, the high computational cost of optimization-based TTA algorithms makes it intractable to run on resource-constrained edge devices. In this paper, we propose an Optimization-Free Test-Time Adaptation (OFTTA) framework for sensor-based HAR. OFTTA adjusts the feature extractor and linear classifier simultaneously in an optimization-free manner. For the feature extractor, we propose Exponential DecayTest-time Normalization (EDTN) to replace the conventional batch normalization (CBN) layers. EDTN combines CBN and Test-time batch Normalization (TBN) to extract reliable features against domain shifts with TBN's influence decreasing exponentially in deeper layers. For the classifier, we adjust the prediction by computing the distance between the feature and the prototype, which is calculated by a maintained support set. In addition, the update of the support set is based on the pseudo label, which can benefit from reliable features extracted by EDTN. Extensive experiments on three public cross-person HAR datasets and two different TTA settings demonstrate that OFTTA outperforms the state-of-the-art TTA approaches in both classification performance and computational efficiency. Finally, we verify the superiority of our proposed OFTTA on edge devices, indicating possible deployment in real applications. Our code is available at \href{https://github.com/Claydon-Wang/OFTTA}{this https URL}.
Energy-based Calibrated VAE with Test Time Free Lunch
Nov 07, 2023In this paper, we propose a novel Energy-Calibrated Generative Model that utilizes a Conditional EBM for enhancing Variational Autoencoders (VAEs). VAEs are sampling efficient but often suffer from blurry generation results due to the lack of training in the generative direction. On the other hand, Energy-Based Models (EBMs) can generate high-quality samples but require expensive Markov Chain Monte Carlo (MCMC) sampling. To address these issues, we introduce a Conditional EBM for calibrating the generative direction during training, without requiring it for test time sampling. Our approach enables the generative model to be trained upon data and calibrated samples with adaptive weight, thereby enhancing efficiency and effectiveness without necessitating MCMC sampling in the inference phase. We also show that the proposed approach can be extended to calibrate normalizing flows and variational posterior. Moreover, we propose to apply the proposed method to zero-shot image restoration via neural transport prior and range-null theory. We demonstrate the effectiveness of the proposed method through extensive experiments in various applications, including image generation and zero-shot image restoration. Our method shows state-of-the-art performance over single-step non-adversarial generation.
Efficient 2D Graph SLAM for Sparse Sensing
Dec 04, 2023Simultaneous localization and mapping (SLAM) plays a vital role in mapping unknown spaces and aiding autonomous navigation. Virtually all state-of-the-art solutions today for 2D SLAM are designed for dense and accurate sensors such as laser range-finders (LiDARs). However, these sensors are not suitable for resource-limited nano robots, which become increasingly capable and ubiquitous nowadays, and these robots tend to mount economical and low-power sensors that can only provide sparse and noisy measurements. This introduces a challenging problem called SLAM with sparse sensing. This work addresses the problem by adopting the form of the state-of-the-art graph-based SLAM pipeline with a novel frontend and an improvement for loop closing in the backend, both of which are designed to work with sparse and uncertain range data. Experiments show that the maps constructed by our algorithm have superior quality compared to prior works on sparse sensing. Furthermore, our method is capable of running in real-time on a modern PC with an average processing time of 1/100th the input interval time.
VideoRF: Rendering Dynamic Radiance Fields as 2D Feature Video Streams
Dec 03, 2023Neural Radiance Fields (NeRFs) excel in photorealistically rendering static scenes. However, rendering dynamic, long-duration radiance fields on ubiquitous devices remains challenging, due to data storage and computational constraints. In this paper, we introduce VideoRF, the first approach to enable real-time streaming and rendering of dynamic radiance fields on mobile platforms. At the core is a serialized 2D feature image stream representing the 4D radiance field all in one. We introduce a tailored training scheme directly applied to this 2D domain to impose the temporal and spatial redundancy of the feature image stream. By leveraging the redundancy, we show that the feature image stream can be efficiently compressed by 2D video codecs, which allows us to exploit video hardware accelerators to achieve real-time decoding. On the other hand, based on the feature image stream, we propose a novel rendering pipeline for VideoRF, which has specialized space mappings to query radiance properties efficiently. Paired with a deferred shading model, VideoRF has the capability of real-time rendering on mobile devices thanks to its efficiency. We have developed a real-time interactive player that enables online streaming and rendering of dynamic scenes, offering a seamless and immersive free-viewpoint experience across a range of devices, from desktops to mobile phones.
Learn or Recall? Revisiting Incremental Learning with Pre-trained Language Models
Dec 13, 2023Incremental Learning (IL) has been a long-standing problem in both vision and Natural Language Processing (NLP) communities. In recent years, as Pre-trained Language Models (PLMs) have achieved remarkable progress in various NLP downstream tasks, utilizing PLMs as backbones has become a common practice in recent research of IL in NLP. Most assume that catastrophic forgetting is the biggest obstacle to achieving superior IL performance and propose various techniques to overcome this issue. However, we find that this assumption is problematic. Specifically, we revisit more than 20 methods on four classification tasks (Text Classification, Intent Classification, Relation Extraction, and Named Entity Recognition) under the two most popular IL settings (Class-Incremental and Task-Incremental) and reveal that most of them severely underestimate the inherent anti-forgetting ability of PLMs. Based on the observation, we propose a frustratingly easy method called SEQ* for IL with PLMs. The results show that SEQ* has competitive or superior performance compared to state-of-the-art (SOTA) IL methods and requires considerably less trainable parameters and training time. These findings urge us to revisit the IL with PLMs and encourage future studies to have a fundamental understanding of the catastrophic forgetting in PLMs. The data, code and scripts are publicly available at https://github.com/zzz47zzz/pretrained-lm-for-incremental-learning.
Memory-Efficient Reversible Spiking Neural Networks
Dec 13, 2023Spiking neural networks (SNNs) are potential competitors to artificial neural networks (ANNs) due to their high energy-efficiency on neuromorphic hardware. However, SNNs are unfolded over simulation time steps during the training process. Thus, SNNs require much more memory than ANNs, which impedes the training of deeper SNN models. In this paper, we propose the reversible spiking neural network to reduce the memory cost of intermediate activations and membrane potentials during training. Firstly, we extend the reversible architecture along temporal dimension and propose the reversible spiking block, which can reconstruct the computational graph and recompute all intermediate variables in forward pass with a reverse process. On this basis, we adopt the state-of-the-art SNN models to the reversible variants, namely reversible spiking ResNet (RevSResNet) and reversible spiking transformer (RevSFormer). Through experiments on static and neuromorphic datasets, we demonstrate that the memory cost per image of our reversible SNNs does not increase with the network depth. On CIFAR10 and CIFAR100 datasets, our RevSResNet37 and RevSFormer-4-384 achieve comparable accuracies and consume 3.79x and 3.00x lower GPU memory per image than their counterparts with roughly identical model complexity and parameters. We believe that this work can unleash the memory constraints in SNN training and pave the way for training extremely large and deep SNNs. The code is available at https://github.com/mi804/RevSNN.git.
ProNeRF: Learning Efficient Projection-Aware Ray Sampling for Fine-Grained Implicit Neural Radiance Fields
Dec 13, 2023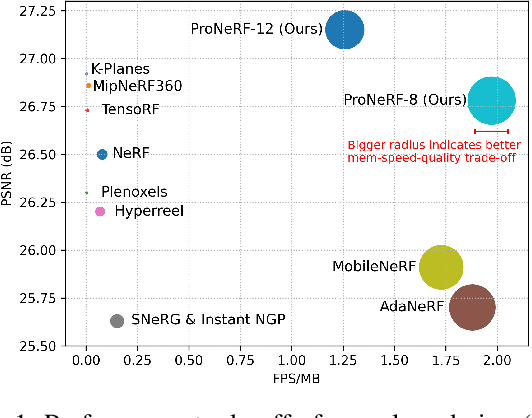
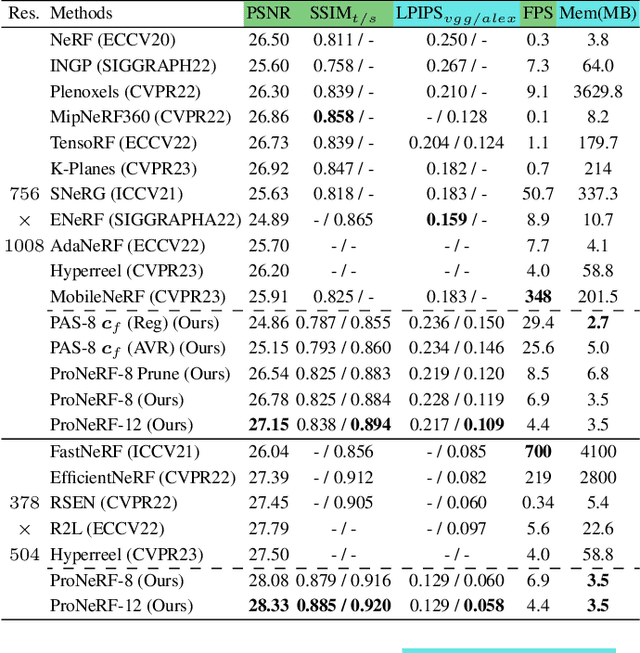
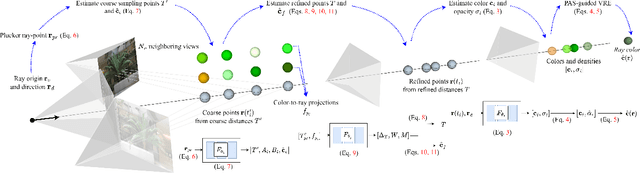
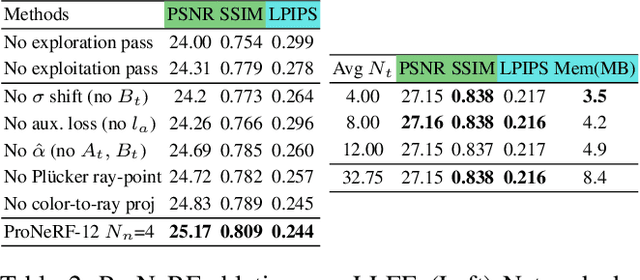
Recent advances in neural rendering have shown that, albeit slow, implicit compact models can learn a scene's geometries and view-dependent appearances from multiple views. To maintain such a small memory footprint but achieve faster inference times, recent works have adopted `sampler' networks that adaptively sample a small subset of points along each ray in the implicit neural radiance fields. Although these methods achieve up to a 10$\times$ reduction in rendering time, they still suffer from considerable quality degradation compared to the vanilla NeRF. In contrast, we propose ProNeRF, which provides an optimal trade-off between memory footprint (similar to NeRF), speed (faster than HyperReel), and quality (better than K-Planes). ProNeRF is equipped with a novel projection-aware sampling (PAS) network together with a new training strategy for ray exploration and exploitation, allowing for efficient fine-grained particle sampling. Our ProNeRF yields state-of-the-art metrics, being 15-23x faster with 0.65dB higher PSNR than NeRF and yielding 0.95dB higher PSNR than the best published sampler-based method, HyperReel. Our exploration and exploitation training strategy allows ProNeRF to learn the full scenes' color and density distributions while also learning efficient ray sampling focused on the highest-density regions. We provide extensive experimental results that support the effectiveness of our method on the widely adopted forward-facing and 360 datasets, LLFF and Blender, respectively.
Coordinated Intra- and Inter-system Interference Management in Integrated Satellite Terrestrial Networks
Dec 13, 2023Leveraging the advantage of satellite and terrestrial networks, the integrated satellite terrestrial networks (ISTNs) can help to achieve seamless global access and eliminate the digital divide. However, the dense deployment and frequent handover of satellites aggravate intra- and inter-system interference, resulting in a decrease in downlink sum rate. To address this issue, we propose a coordinated intra- and inter-system interference management algorithm for ISTN. This algorithm coordinates multidimensional interference through a joint design of inter-satellite handover and resource allocation method. On the one hand, we take inter-system interference between low earth orbit (LEO) and geostationary orbit (GEO) satellites as a constraint, and reduce interference to GEO satellite ground stations (GEO-GS) while ensuring system capacity through inter-satellite handover. On the other hand, satellite and terrestrial resource allocation schemes are designed based on the matching idea, and channel gain and interference to other channels are considered during the matching process to coordinate co-channel interference. In order to avoid too many unnecessary handovers, we consider handover scenarios related to service capabilities and service time to determine the optimal handover target satellite. Numerical results show that the gap between the results on the system sum rate obtained by the proposed method and the upper bound is reduced as the user density increases, and the handover frequency can be significantly reduced.
EventAid: Benchmarking Event-aided Image/Video Enhancement Algorithms with Real-captured Hybrid Dataset
Dec 13, 2023Event cameras are emerging imaging technology that offers advantages over conventional frame-based imaging sensors in dynamic range and sensing speed. Complementing the rich texture and color perception of traditional image frames, the hybrid camera system of event and frame-based cameras enables high-performance imaging. With the assistance of event cameras, high-quality image/video enhancement methods make it possible to break the limits of traditional frame-based cameras, especially exposure time, resolution, dynamic range, and frame rate limits. This paper focuses on five event-aided image and video enhancement tasks (i.e., event-based video reconstruction, event-aided high frame rate video reconstruction, image deblurring, image super-resolution, and high dynamic range image reconstruction), provides an analysis of the effects of different event properties, a real-captured and ground truth labeled benchmark dataset, a unified benchmarking of state-of-the-art methods, and an evaluation for two mainstream event simulators. In detail, this paper collects a real-captured evaluation dataset EventAid for five event-aided image/video enhancement tasks, by using "Event-RGB" multi-camera hybrid system, taking into account scene diversity and spatiotemporal synchronization. We further perform quantitative and visual comparisons for state-of-the-art algorithms, provide a controlled experiment to analyze the performance limit of event-aided image deblurring methods, and discuss open problems to inspire future research.
LMD: Faster Image Reconstruction with Latent Masking Diffusion
Dec 13, 2023As a class of fruitful approaches, diffusion probabilistic models (DPMs) have shown excellent advantages in high-resolution image reconstruction. On the other hand, masked autoencoders (MAEs), as popular self-supervised vision learners, have demonstrated simpler and more effective image reconstruction and transfer capabilities on downstream tasks. However, they all require extremely high training costs, either due to inherent high temporal-dependence (i.e., excessively long diffusion steps) or due to artificially low spatial-dependence (i.e., human-formulated high mask ratio, such as 0.75). To the end, this paper presents LMD, a faster image reconstruction framework with latent masking diffusion. First, we propose to project and reconstruct images in latent space through a pre-trained variational autoencoder, which is theoretically more efficient than in the pixel-based space. Then, we combine the advantages of MAEs and DPMs to design a progressive masking diffusion model, which gradually increases the masking proportion by three different schedulers and reconstructs the latent features from simple to difficult, without sequentially performing denoising diffusion as in DPMs or using fixed high masking ratio as in MAEs, so as to alleviate the high training time-consumption predicament. Our approach allows for learning high-capacity models and accelerate their training (by 3x or more) and barely reduces the original accuracy. Inference speed in downstream tasks also significantly outperforms the previous approaches.