 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SoS Degree Reduction with Applications to Clustering and Robust Moment Estimation
Jan 05, 2021
We develop a general framework to significantly reduce the degree of sum-of-squares proofs by introducing new variables. To illustrate the power of this framework, we use it to speed up previous algorithms based on sum-of-squares for two important estimation problems, clustering and robust moment estimation. The resulting algorithms offer the same statistical guarantees as the previous best algorithms but have significantly faster running times. Roughly speaking, given a sample of $n$ points in dimension $d$, our algorithms can exploit order-$\ell$ moments in time $d^{O(\ell)}\cdot n^{O(1)}$, whereas a naive implementation requires time $(d\cdot n)^{O(\ell)}$. Since for the aforementioned applications, the typical sample size is $d^{\Theta(\ell)}$, our framework improves running times from $d^{O(\ell^2)}$ to $d^{O(\ell)}$.
Composition Properties of Inferential Privacy for Time-Series Data
Jul 10, 2017With the proliferation of mobile devices and the internet of things, developing principled solutions for privacy in time series applications has become increasingly important. While differential privacy is the gold standard for database privacy, many time series applications require a different kind of guarantee, and a number of recent works have used some form of inferential privacy to address these situations. However, a major barrier to using inferential privacy in practice is its lack of graceful composition -- even if the same or related sensitive data is used in multiple releases that are safe individually, the combined release may have poor privacy properties. In this paper, we study composition properties of a form of inferential privacy called Pufferfish when applied to time-series data. We show that while general Pufferfish mechanisms may not compose gracefully, a specific Pufferfish mechanism, called the Markov Quilt Mechanism, which was recently introduced, has strong composition properties comparable to that of pure differential privacy when applied to time series data.
Weakly Supervised Video Salient Object Detection
Apr 06, 2021
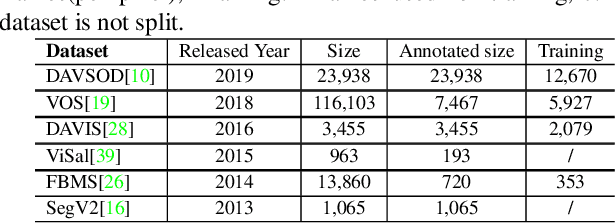
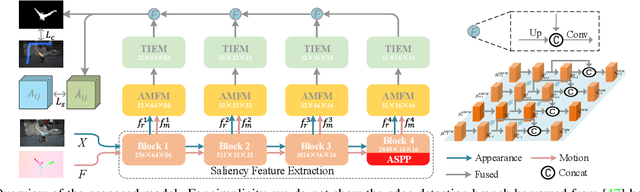
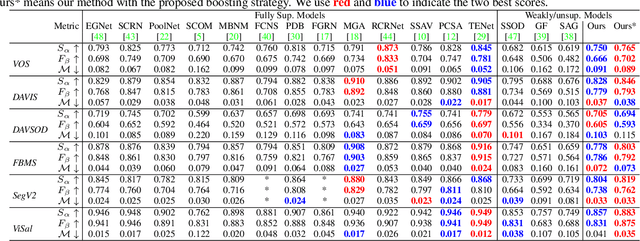
Significant performance improvement has been achieved for fully-supervised video salient object detection with the pixel-wise labeled training datasets, which are time-consuming and expensive to obtain. To relieve the burden of data annotation, we present the first weakly supervised video salient object detection model based on relabeled "fixation guided scribble annotations". Specifically, an "Appearance-motion fusion module" and bidirectional ConvLSTM based framework are proposed to achieve effective multi-modal learning and long-term temporal context modeling based on our new weak annotations. Further, we design a novel foreground-background similarity loss to further explore the labeling similarity across frames. A weak annotation boosting strategy is also introduced to boost our model performance with a new pseudo-label generation technique. Extensive experimental results on six benchmark video saliency detection datasets illustrate the effectiveness of our solution.
Self-Supervision based Task-Specific Image Collection Summarization
Dec 19, 2020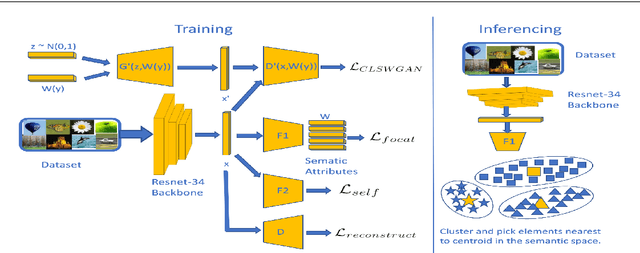
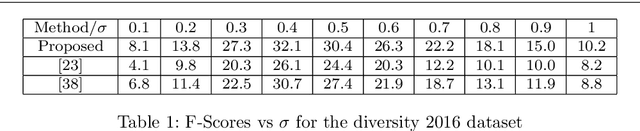
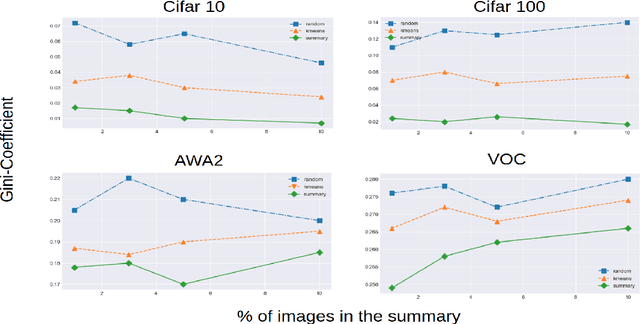
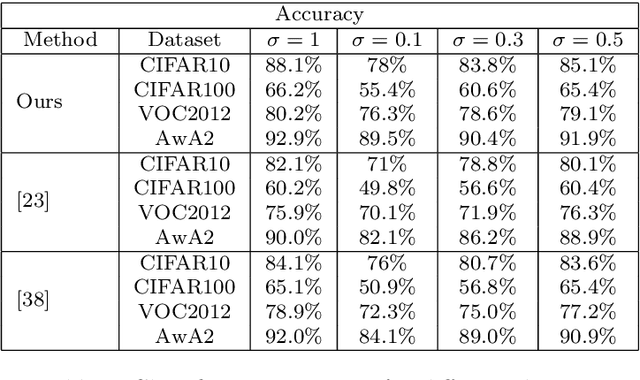
Successful applications of deep learning (DL) requires large amount of annotated data. This often restricts the benefits of employing DL to businesses and individuals with large budgets for data-collection and computation. Summarization offers a possible solution by creating much smaller representative datasets that can allow real-time deep learning and analysis of big data and thus democratize use of DL. In the proposed work, our aim is to explore a novel approach to task-specific image corpus summarization using semantic information and self-supervision. Our method uses a classification-based Wasserstein generative adversarial network (CLSWGAN) as a feature generating network. The model also leverages rotational invariance as self-supervision and classification on another task. All these objectives are added on a features from resnet34 to make it discriminative and robust. The model then generates a summary at inference time by using K-means clustering in the semantic embedding space. Thus, another main advantage of this model is that it does not need to be retrained each time to obtain summaries of different lengths which is an issue with current end-to-end models. We also test our model efficacy by means of rigorous experiments both qualitatively and quantitatively.
KVT: k-NN Attention for Boosting Vision Transformers
May 28, 2021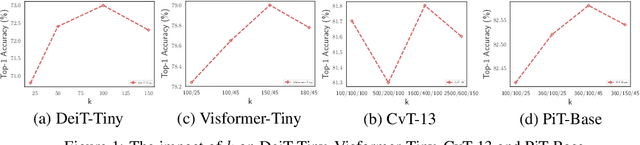
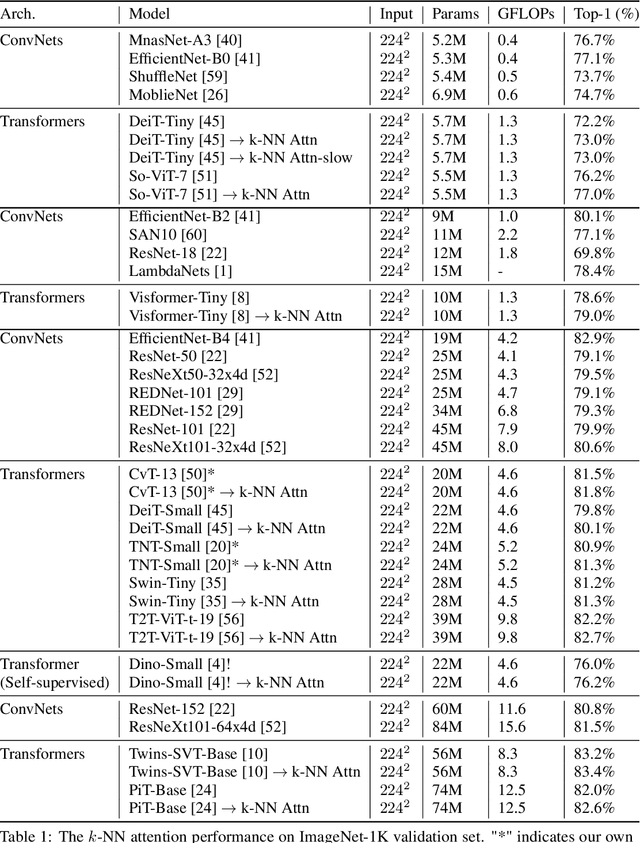
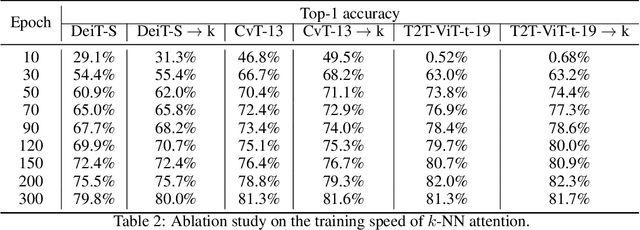
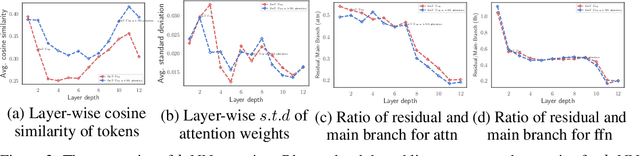
Convolutional Neural Networks (CNNs) have dominated computer vision for years, due to its ability in capturing locality and translation invariance. Recently, many vision transformer architectures have been proposed and they show promising performance. A key component in vision transformers is the fully-connected self-attention which is more powerful than CNNs in modelling long range dependencies. However, since the current dense self-attention uses all image patches (tokens) to compute attention matrix, it may neglect locality of images patches and involve noisy tokens (e.g., clutter background and occlusion), leading to a slow training process and potentially degradation of performance. To address these problems, we propose a sparse attention scheme, dubbed k-NN attention, for boosting vision transformers. Specifically, instead of involving all the tokens for attention matrix calculation, we only select the top-k similar tokens from the keys for each query to compute the attention map. The proposed k-NN attention naturally inherits the local bias of CNNs without introducing convolutional operations, as nearby tokens tend to be more similar than others. In addition, the k-NN attention allows for the exploration of long range correlation and at the same time filter out irrelevant tokens by choosing the most similar tokens from the entire image. Despite its simplicity, we verify, both theoretically and empirically, that $k$-NN attention is powerful in distilling noise from input tokens and in speeding up training. Extensive experiments are conducted by using ten different vision transformer architectures to verify that the proposed k-NN attention can work with any existing transformer architectures to improve its prediction performance.
Undistillable: Making A Nasty Teacher That CANNOT teach students
May 16, 2021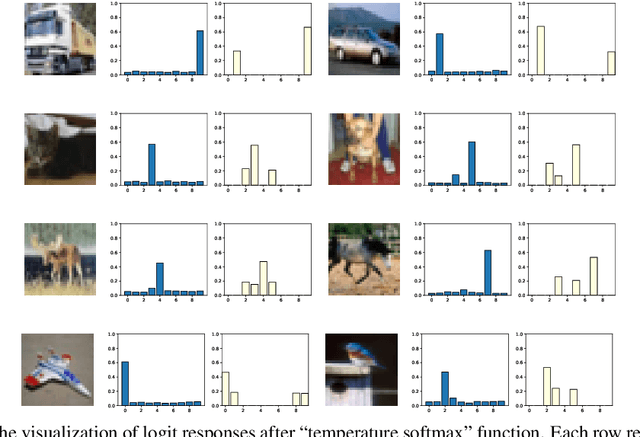
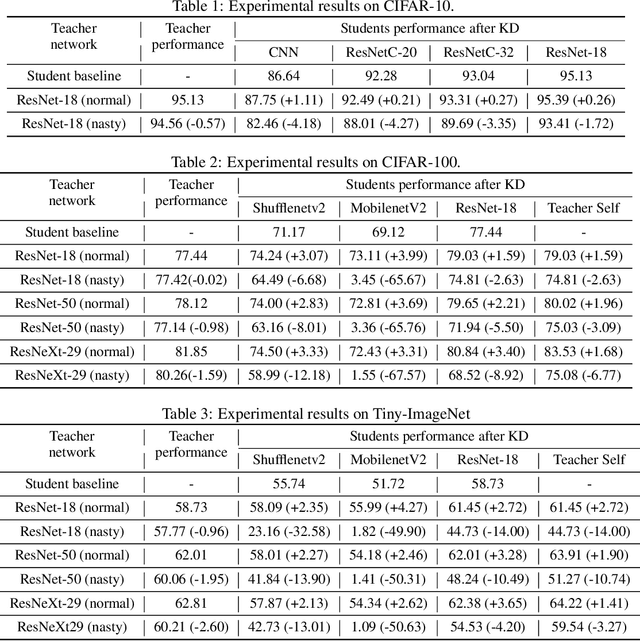
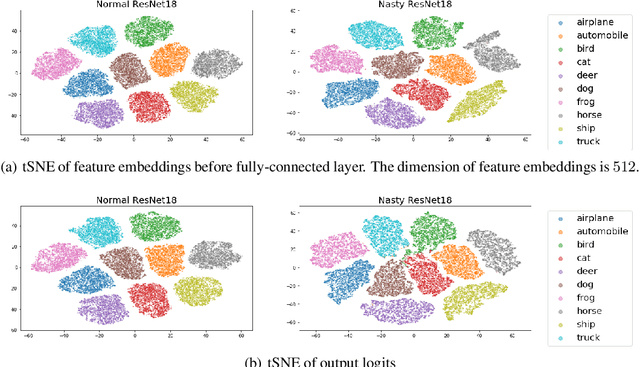
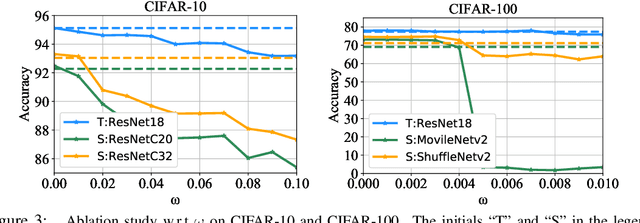
Knowledge Distillation (KD) is a widely used technique to transfer knowledge from pre-trained teacher models to (usually more lightweight) student models. However, in certain situations, this technique is more of a curse than a blessing. For instance, KD poses a potential risk of exposing intellectual properties (IPs): even if a trained machine learning model is released in 'black boxes' (e.g., as executable software or APIs without open-sourcing code), it can still be replicated by KD through imitating input-output behaviors. To prevent this unwanted effect of KD, this paper introduces and investigates a concept called Nasty Teacher: a specially trained teacher network that yields nearly the same performance as a normal one, but would significantly degrade the performance of student models learned by imitating it. We propose a simple yet effective algorithm to build the nasty teacher, called self-undermining knowledge distillation. Specifically, we aim to maximize the difference between the output of the nasty teacher and a normal pre-trained network. Extensive experiments on several datasets demonstrate that our method is effective on both standard KD and data-free KD, providing the desirable KD-immunity to model owners for the first time. We hope our preliminary study can draw more awareness and interest in this new practical problem of both social and legal importance.
* ICLR 2021(Spotlight). Code is available at https://github.com/VITA-Group/Nasty-Teacher
GEOMScope: Large Field-of-view 3D Lensless Microscopy with Low Computational Complexity
Jan 20, 2021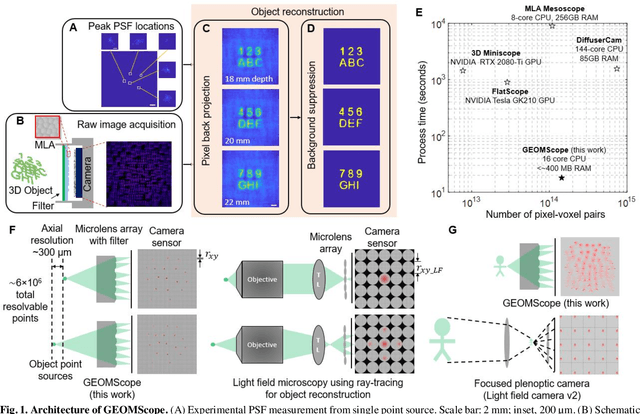
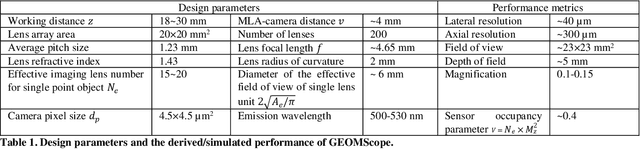
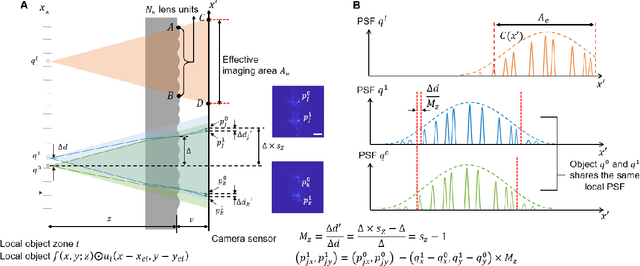
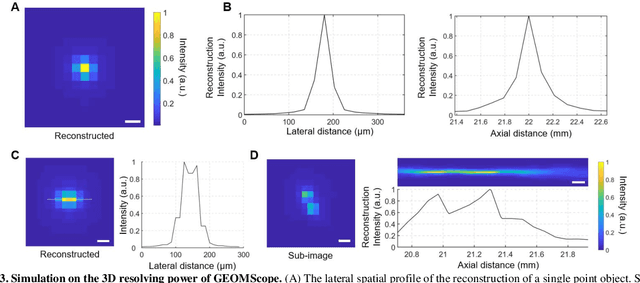
Recent development of lensless imagers has enabled three-dimensional (3D) imaging through a thin piece of optics in close proximity to a camera sensor. A general challenge of wide-field lensless imaging is the high computational complexity and slow speed to reconstruct 3D objects through iterative optimization process. Here, we demonstrated GEOMScope, a lensless 3D microscope that forms image through a single layer of microlens array and reconstructs objects through a geometrical-optics-based pixel back projection algorithm and background suppressions. Compared to others, our method allows local reconstruction, which significantly reduces the required computation resource and increases the reconstruction speed by orders of magnitude. This enables near real-time object reconstructions across a large volume of 23x23x5 mm^3, with a lateral resolution of 40 um and axial resolution of 300 um. Our system opens new avenues for broad biomedical applications such as endoscopy, which requires both miniaturized device footprint and real-time high resolution visualization.
Low Rank Forecasting
Jan 29, 2021
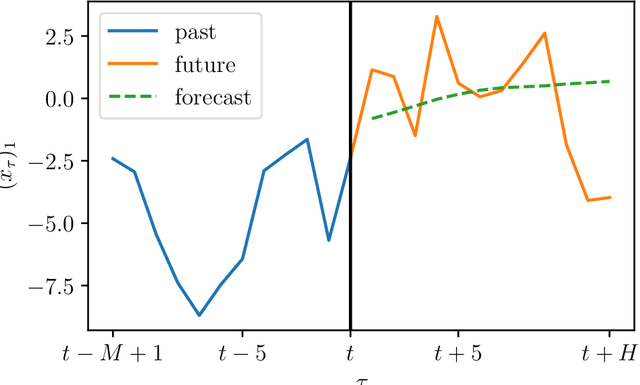
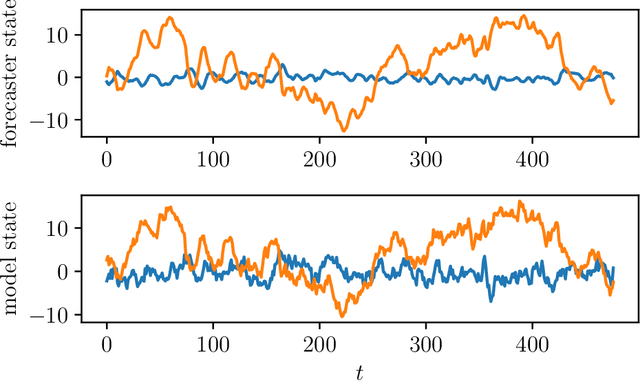
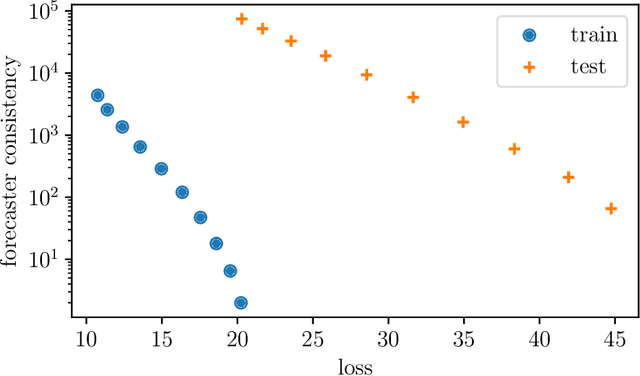
We consider the problem of forecasting multiple values of the future of a vector time series, using some past values. This problem, and related ones such as one-step-ahead prediction, have a very long history, and there are a number of well-known methods for it, including vector auto-regressive models, state-space methods, multi-task regression, and others. Our focus is on low rank forecasters, which break forecasting up into two steps: estimating a vector that can be interpreted as a latent state, given the past, and then estimating the future values of the time series, given the latent state estimate. We introduce the concept of forecast consistency, which means that the estimates of the same value made at different times are consistent. We formulate the forecasting problem in general form, and focus on linear forecasters, for which we propose a formulation that can be solved via convex optimization. We describe a number of extensions and variations, including nonlinear forecasters, data weighting, the inclusion of auxiliary data, and additional objective terms. We illustrate our methods with several examples.
A-SDF: Learning Disentangled Signed Distance Functions for Articulated Shape Representation
Apr 15, 2021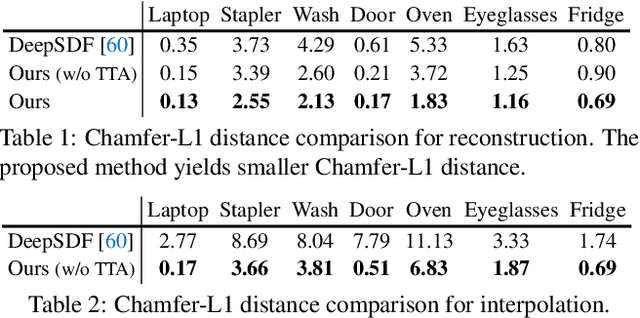
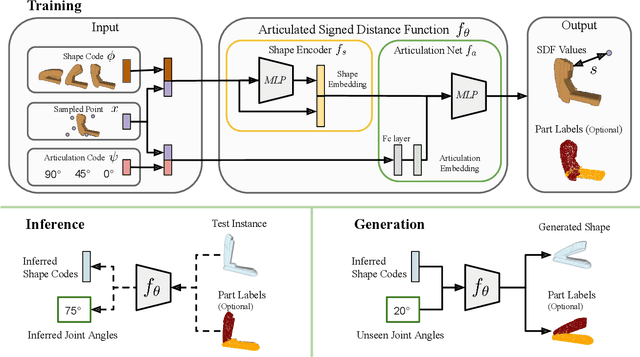
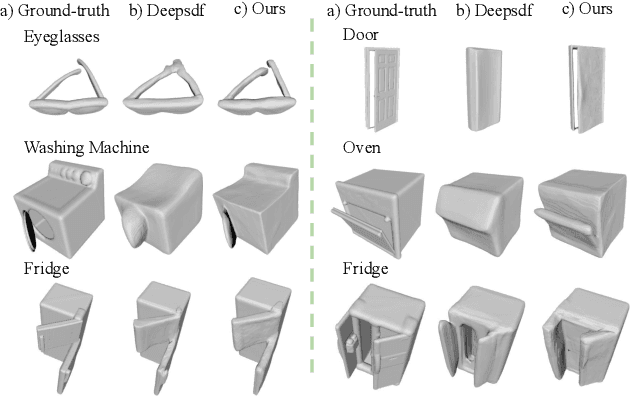

Recent work has made significant progress on using implicit functions, as a continuous representation for 3D rigid object shape reconstruction. However, much less effort has been devoted to modeling general articulated objects. Compared to rigid objects, articulated objects have higher degrees of freedom, which makes it hard to generalize to unseen shapes. To deal with the large shape variance, we introduce Articulated Signed Distance Functions (A-SDF) to represent articulated shapes with a disentangled latent space, where we have separate codes for encoding shape and articulation. We assume no prior knowledge on part geometry, articulation status, joint type, joint axis, and joint location. With this disentangled continuous representation, we demonstrate that we can control the articulation input and animate unseen instances with unseen joint angles. Furthermore, we propose a Test-Time Adaptation inference algorithm to adjust our model during inference. We demonstrate our model generalize well to out-of-distribution and unseen data, e.g., partial point clouds and real-world depth images.
A New Approach to Capacity Scaling Augmented With Unreliable Machine Learning Predictions
Jan 28, 2021
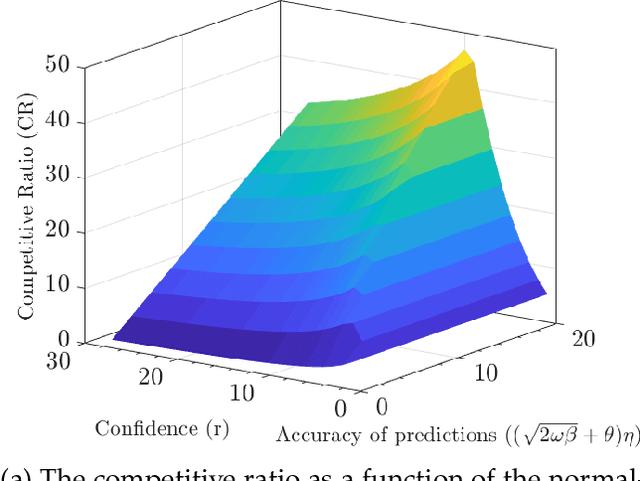
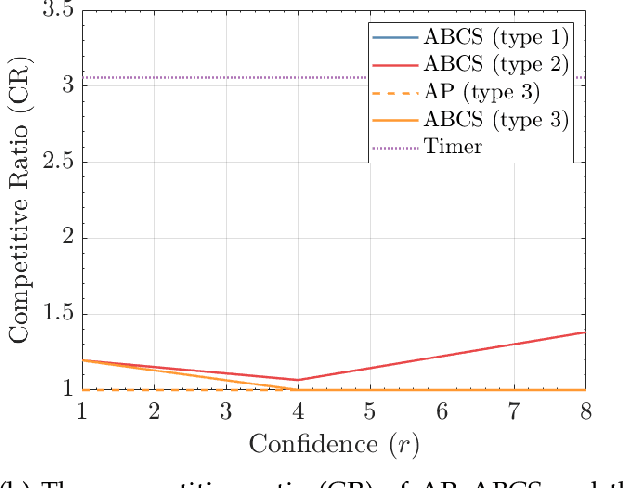
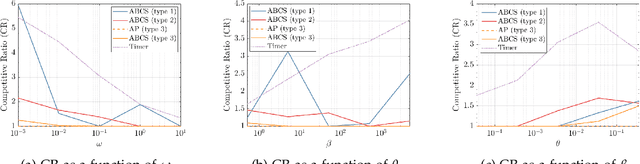
Modern data centers suffer from immense power consumption. The erratic behavior of internet traffic forces data centers to maintain excess capacity in the form of idle servers in case the workload suddenly increases. As an idle server still consumes a significant fraction of the peak energy, data center operators have heavily invested in capacity scaling solutions. In simple terms, these aim to deactivate servers if the demand is low and to activate them again when the workload increases. To do so, an algorithm needs to strike a delicate balance between power consumption, flow-time, and switching costs. Over the last decade, the research community has developed competitive online algorithms with worst-case guarantees. In the presence of historic data patterns, prescription from Machine Learning (ML) predictions typically outperform such competitive algorithms. This, however, comes at the cost of sacrificing the robustness of performance, since unpredictable surges in the workload are not uncommon. The current work builds on the emerging paradigm of augmenting unreliable ML predictions with online algorithms to develop novel robust algorithms that enjoy the benefits of both worlds. We analyze a continuous-time model for capacity scaling, where the goal is to minimize the weighted sum of flow-time, switching cost, and power consumption in an online fashion. We propose a novel algorithm, called Adaptive Balanced Capacity Scaling (ABCS), that has access to black-box ML predictions, but is completely oblivious to the accuracy of these predictions. In particular, if the predictions turn out to be accurate in hindsight, we prove that ABCS is $(1+\varepsilon)$-competitive. Moreover, even when the predictions are inaccurate, ABCS guarantees a bounded competitive ratio. The performance of the ABCS algorithm on a real-world dataset positively support the theoretical results.