 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Conservative Contextual Combinatorial Cascading Bandit
Apr 23, 2021

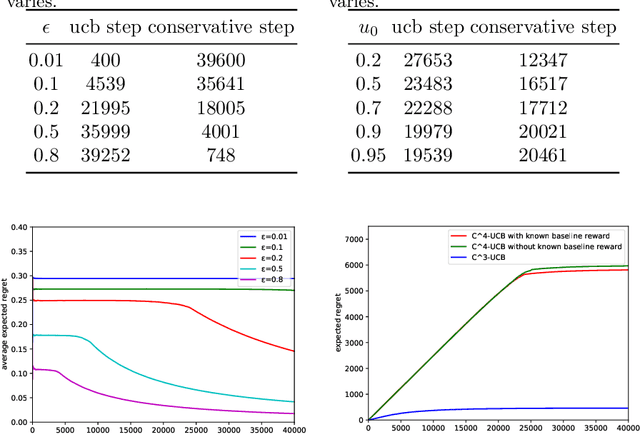
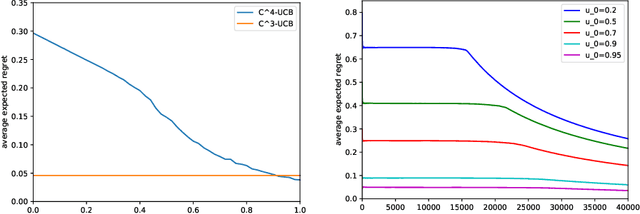
Conservative mechanism is a desirable property in decision-making problems which balance the tradeoff between the exploration and exploitation. We propose the novel \emph{conservative contextual combinatorial cascading bandit ($C^4$-bandit)}, a cascading online learning game which incorporates the conservative mechanism. At each time step, the learning agent is given some contexts and has to recommend a list of items but not worse than the base strategy and then observes the reward by some stopping rules. We design the $C^4$-UCB algorithm to solve the problem and prove its n-step upper regret bound for two situations: known baseline reward and unknown baseline reward. The regret in both situations can be decomposed into two terms: (a) the upper bound for the general contextual combinatorial cascading bandit; and (b) a constant term for the regret from the conservative mechanism. We also improve the bound of the conservative contextual combinatorial bandit as a by-product. Experiments on synthetic data demonstrate its advantages and validate our theoretical analysis.
Privacy-Preserving Machine Learning with Fully Homomorphic Encryption for Deep Neural Network
Jun 14, 2021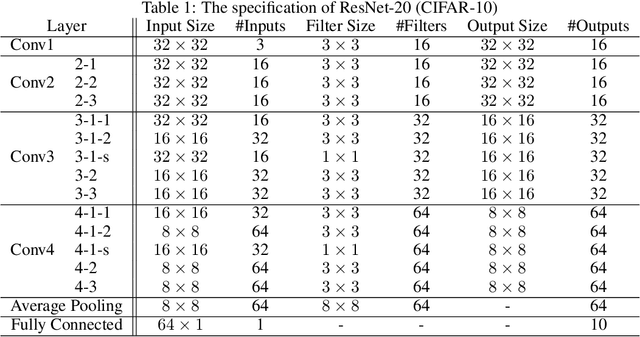
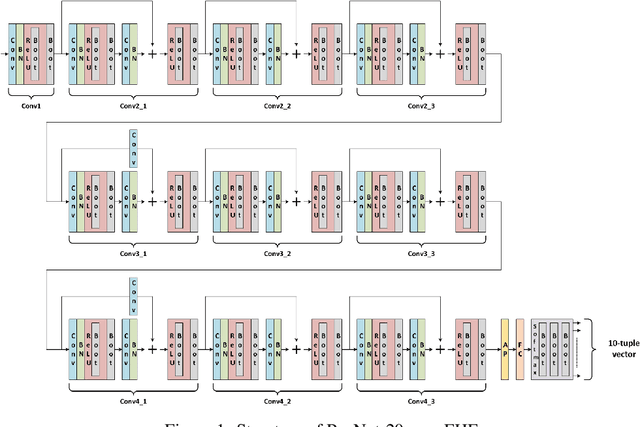


Fully homomorphic encryption (FHE) is one of the prospective tools for privacypreserving machine learning (PPML), and several PPML models have been proposed based on various FHE schemes and approaches. Although the FHE schemes are known as suitable tools to implement PPML models, previous PPML models on FHE encrypted data are limited to only simple and non-standard types of machine learning models. These non-standard machine learning models are not proven efficient and accurate with more practical and advanced datasets. Previous PPML schemes replace non-arithmetic activation functions with simple arithmetic functions instead of adopting approximation methods and do not use bootstrapping, which enables continuous homomorphic evaluations. Thus, they could not use standard activation functions and could not employ a large number of layers. The maximum classification accuracy of the existing PPML model with the FHE for the CIFAR-10 dataset was only 77% until now. In this work, we firstly implement the standard ResNet-20 model with the RNS-CKKS FHE with bootstrapping and verify the implemented model with the CIFAR-10 dataset and the plaintext model parameters. Instead of replacing the non-arithmetic functions with the simple arithmetic function, we use state-of-the-art approximation methods to evaluate these non-arithmetic functions, such as the ReLU, with sufficient precision [1]. Further, for the first time, we use the bootstrapping technique of the RNS-CKKS scheme in the proposed model, which enables us to evaluate a deep learning model on the encrypted data. We numerically verify that the proposed model with the CIFAR-10 dataset shows 98.67% identical results to the original ResNet-20 model with non-encrypted data. The classification accuracy of the proposed model is 90.67%, which is pretty close to that of the original ResNet-20 CNN model...
Performance Analysis of OTFS Modulation with Receive Antenna Selection
Mar 02, 2021
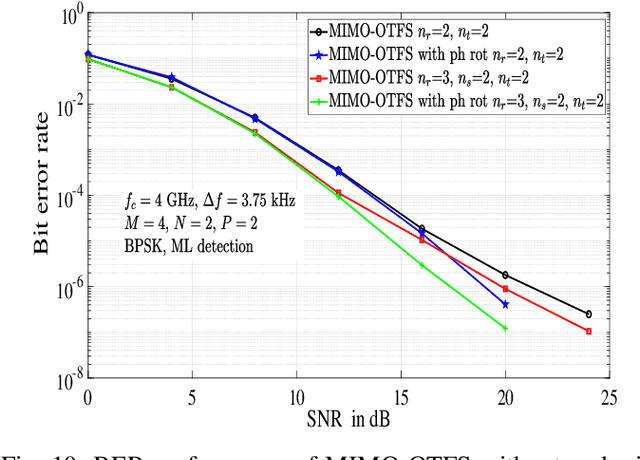
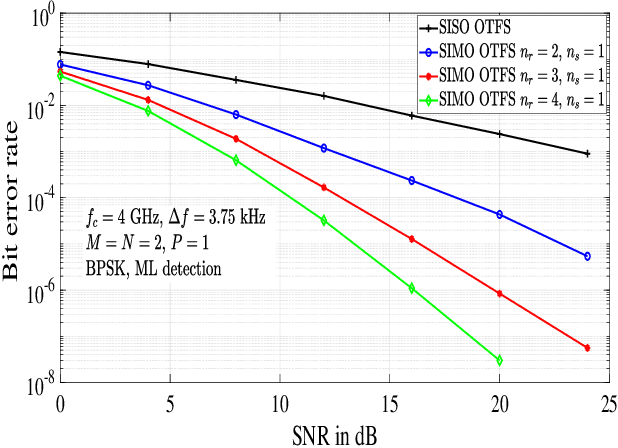
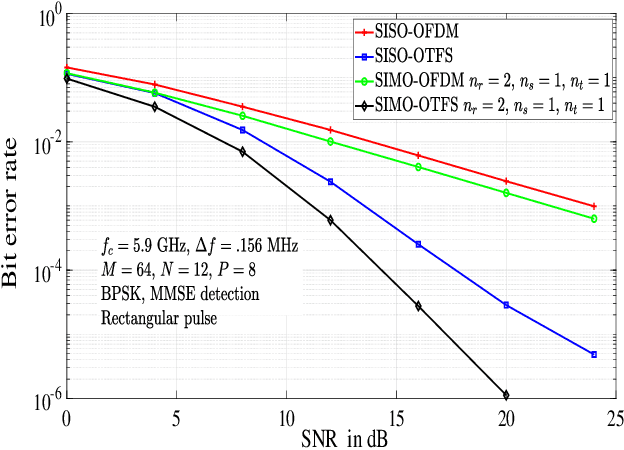
In this paper, we analyze the performance of orthogonal time frequency space (OTFS) modulation with antenna selection at the receiver, where $n_s$ out of $n_r$ receive antennas with maximum channel Frobenius norms in the delay-Doppler (DD) domain are selected. Single-input multiple-output OTFS (SIMO-OTFS), multiple-input multiple-output OTFS (MIMO-OTFS), and space-time coded OTFS (STC-OTFS) systems with receive antenna selection (RAS) are considered. We consider these systems without and with phase rotation. Our diversity analysis results show that, with no phase rotation, SIMO-OTFS and MIMO-OTFS systems with RAS are rank deficient, and therefore they do not extract the full receive diversity as well as the diversity present in the DD domain. Also, Alamouti coded STC-OTFS system with RAS and no phase rotation extracts the full transmit diversity, but it fails to extract the DD diversity. On the other hand, SIMO-OTFS and STC-OTFS systems with RAS become full-ranked when phase rotation is used, because of which they extract the full spatial as well as the DD diversity present in the system. Also, when phase rotation is used, MIMO-OTFS systems with RAS extract the full DD diversity, but they do not extract the full receive diversity because of rank deficiency. Simulation results are shown to validate the analytically predicted diversity performance.
Fast-GANFIT: Generative Adversarial Network for High Fidelity 3D Face Reconstruction
May 16, 2021
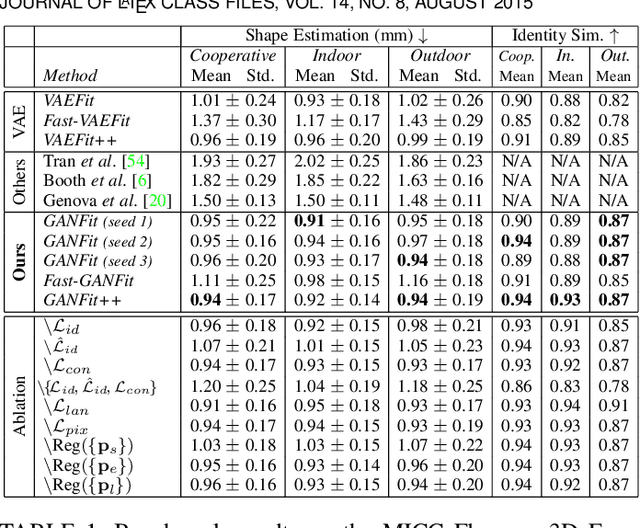
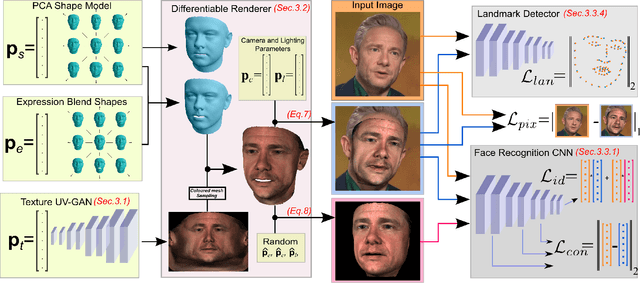
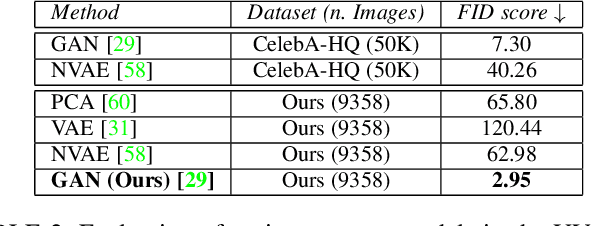
A lot of work has been done towards reconstructing the 3D facial structure from single images by capitalizing on the power of Deep Convolutional Neural Networks (DCNNs). In the recent works, the texture features either correspond to components of a linear texture space or are learned by auto-encoders directly from in-the-wild images. In all cases, the quality of the facial texture reconstruction is still not capable of modeling facial texture with high-frequency details. In this paper, we take a radically different approach and harness the power of Generative Adversarial Networks (GANs) and DCNNs in order to reconstruct the facial texture and shape from single images. That is, we utilize GANs to train a very powerful facial texture prior \edit{from a large-scale 3D texture dataset}. Then, we revisit the original 3D Morphable Models (3DMMs) fitting making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. In order to be robust towards initialisation and expedite the fitting process, we propose a novel self-supervised regression based approach. We demonstrate excellent results in photorealistic and identity preserving 3D face reconstructions and achieve for the first time, to the best of our knowledge, facial texture reconstruction with high-frequency details.
Transfer training from smaller language model
Apr 23, 2021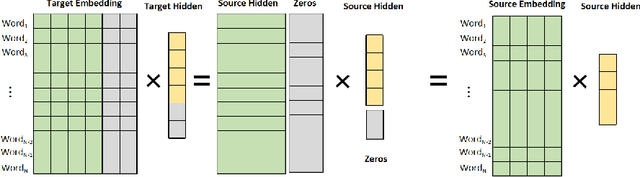

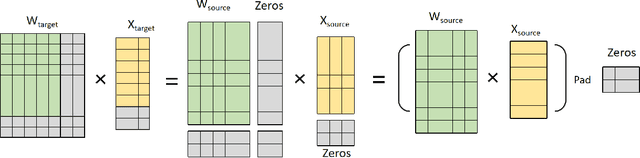
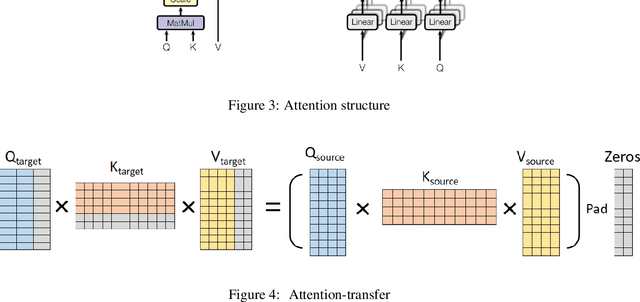
Large language models have led to state-of-the-art accuracies across a range of tasks. However,training large language model needs massive computing resource, as more and more open source pre-training models are available, it is worthy to study how to take full advantage of available model. We find a method to save training time and resource cost by changing the small well-trained model to large model. We initialize a larger target model from a smaller source model by copy weight values from source model and padding with zeros or small initialization values on it to make the source and target model have approximate outputs, which is valid due to block matrix multiplication and residual connection in transformer structure. We test the target model on several data sets and find it is still comparable with the source model. When we continue training the target model, the training loss can start from a smaller value.
Cross-Modal Information Maximization for Medical Imaging: CMIM
Oct 20, 2020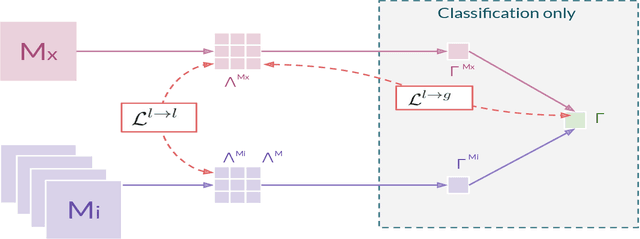
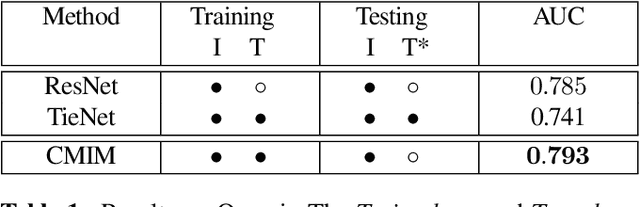
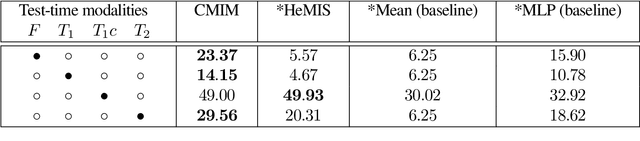
In hospitals, data are siloed to specific information systems that make the same information available under different modalities such as the different medical imaging exams the patient undergoes (CT scans, MRI, PET, Ultrasound, etc.) and their associated radiology reports. This offers unique opportunities to obtain and use at train-time those multiple views of the same information that might not always be available at test-time. In this paper, we propose an innovative framework that makes the most of available data by learning good representations of a multi-modal input that are resilient to modality dropping at test-time, using recent advances in mutual information maximization. By maximizing cross-modal information at train time, we are able to outperform several state-of-the-art baselines in two different settings, medical image classification, and segmentation. In particular, our method is shown to have a strong impact on the inference-time performance of weaker modalities.
The Generalized Mean Densest Subgraph Problem
Jun 04, 2021



Finding dense subgraphs of a large graph is a standard problem in graph mining that has been studied extensively both for its theoretical richness and its many practical applications. In this paper we introduce a new family of dense subgraph objectives, parameterized by a single parameter $p$, based on computing generalized means of degree sequences of a subgraph. Our objective captures both the standard densest subgraph problem and the maximum $k$-core as special cases, and provides a way to interpolate between and extrapolate beyond these two objectives when searching for other notions of dense subgraphs. In terms of algorithmic contributions, we first show that our objective can be minimized in polynomial time for all $p \geq 1$ using repeated submodular minimization. A major contribution of our work is analyzing the performance of different types of peeling algorithms for dense subgraphs both in theory and practice. We prove that the standard peeling algorithm can perform arbitrarily poorly on our generalized objective, but we then design a more sophisticated peeling method which for $p \geq 1$ has an approximation guarantee that is always at least $1/2$ and converges to 1 as $p \rightarrow \infty$. In practice, we show that this algorithm obtains extremely good approximations to the optimal solution, scales to large graphs, and highlights a range of different meaningful notions of density on graphs coming from numerous domains. Furthermore, it is typically able to approximate the densest subgraph problem better than the standard peeling algorithm, by better accounting for how the removal of one node affects other nodes in its neighborhood.
Lite-FPN for Keypoint-based Monocular 3D Object Detection
May 01, 2021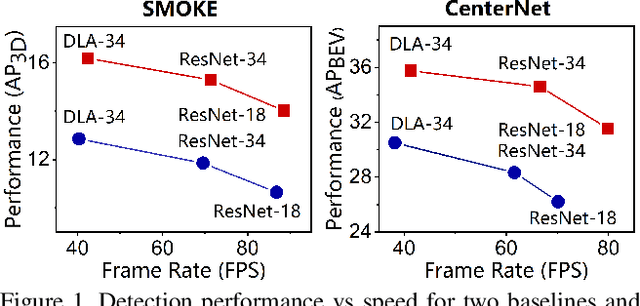
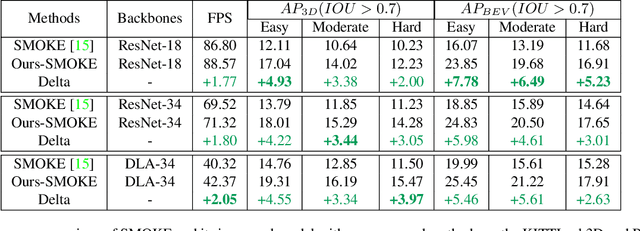
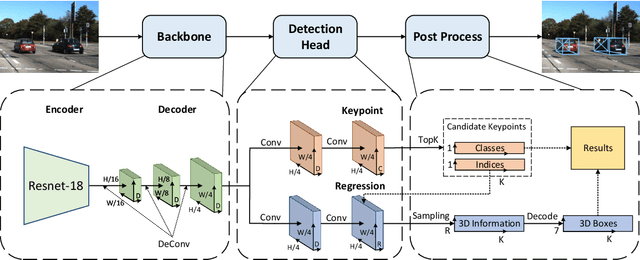
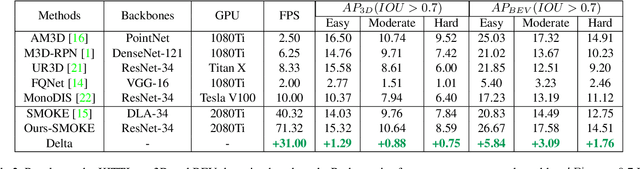
3D object detection with a single image is an essential and challenging task for autonomous driving. Recently, keypoint-based monocular 3D object detection has made tremendous progress and achieved great speed-accuracy trade-off. However, there still exists a huge gap with LIDAR-based methods in terms of accuracy. To improve their performance without sacrificing efficiency, we propose a sort of lightweight feature pyramid network called Lite-FPN to achieve multi-scale feature fusion in an effective and efficient way, which can boost the multi-scale detection capability of keypoint-based detectors. Besides, the misalignment between the classification score and the localization precision is further relieved by introducing a novel regression loss named attention loss. With the proposed loss, predictions with high confidence but poor localization are treated with more attention during the training phase. Comparative experiments based on several state-of-the-art keypoint-based detectors on the KITTI dataset show that our proposed method achieves significantly higher accuracy and frame rate at the same time. The code and pretrained models will be available at https://github.com/yanglei18/Lite-FPN.
DeepMultiCap: Performance Capture of Multiple Characters Using Sparse Multiview Cameras
May 01, 2021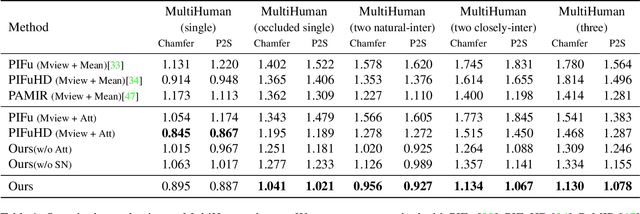
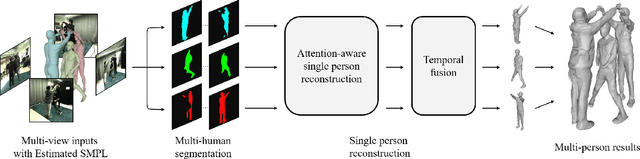
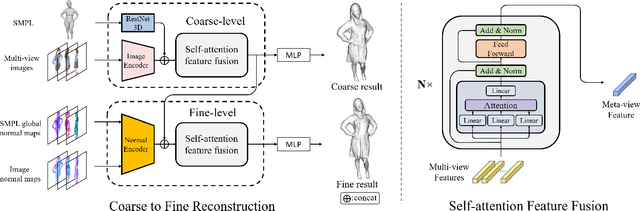

We propose DeepMultiCap, a novel method for multi-person performance capture using sparse multi-view cameras. Our method can capture time varying surface details without the need of using pre-scanned template models. To tackle with the serious occlusion challenge for close interacting scenes, we combine a recently proposed pixel-aligned implicit function with parametric model for robust reconstruction of the invisible surface areas. An effective attention-aware module is designed to obtain the fine-grained geometry details from multi-view images, where high-fidelity results can be generated. In addition to the spatial attention method, for video inputs, we further propose a novel temporal fusion method to alleviate the noise and temporal inconsistencies for moving character reconstruction. For quantitative evaluation, we contribute a high quality multi-person dataset, MultiHuman, which consists of 150 static scenes with different levels of occlusions and ground truth 3D human models. Experimental results demonstrate the state-of-the-art performance of our method and the well generalization to real multiview video data, which outperforms the prior works by a large margin.
Building an Integrated Mobile Robotic System for Real-Time Applications in Construction
Apr 18, 2018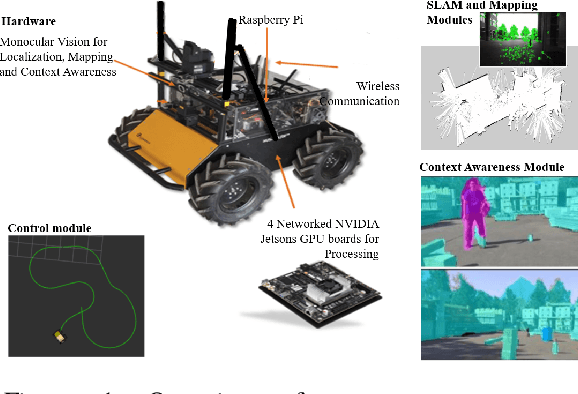
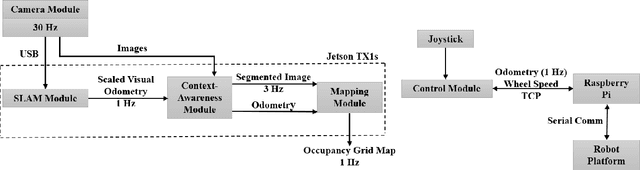

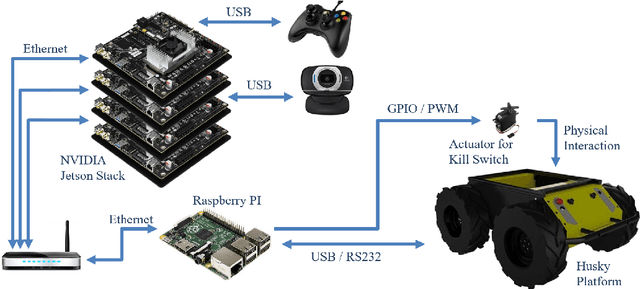
One of the major challenges of a real-time autonomous robotic system for construction monitoring is to simultaneously localize, map, and navigate over the lifetime of the robot, with little or no human intervention. Past research on Simultaneous Localization and Mapping (SLAM) and context-awareness are two active research areas in the computer vision and robotics communities. The studies that integrate both in real-time into a single modular framework for construction monitoring still need further investigation. A monocular vision system and real-time scene understanding are computationally heavy and the major state-of-the-art algorithms are tested on high-end desktops and/or servers with a high CPU- and/or GPU- computing capabilities, which affect their mobility and deployment for real-world applications. To address these challenges and achieve automation, this paper proposes an integrated robotic computer vision system, which generates a real-world spatial map of the obstacles and traversable space present in the environment in near real-time. This is done by integrating contextual Awareness and visual SLAM into a ground robotics agent. This paper presents the hardware utilization and performance of the aforementioned system for three different outdoor environments, which represent the applicability of this pipeline to diverse outdoor scenes in near real-time. The entire system is also self-contained and does not require user input, which demonstrates the potential of this computer vision system for autonomous navigation.