 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageRAGTurbo: Towards One-step Text-to-Image Generation with Retrieval-Augmented Diffusion Models
Feb 13, 2026Diffusion models have emerged as the leading approach for text-to-image generation. However, their iterative sampling process, which gradually morphs random noise into coherent images, introduces significant latency that limits their applicability. While recent few-step diffusion models reduce the number of sampling steps to as few as one to four steps, they often compromise image quality and prompt alignment, especially in one-step generation. Additionally, these models require computationally expensive training procedures. To address these limitations, we propose ImageRAGTurbo, a novel approach to efficiently finetune few-step diffusion models via retrieval augmentation. Given a text prompt, we retrieve relevant text-image pairs from a database and use them to condition the generation process. We argue that such retrieved examples provide rich contextual information to the UNet denoiser that helps reduce the number of denoising steps without compromising image quality. Indeed, our initial investigations show that using the retrieved content to edit the denoiser's latent space ($\mathcal{H}$-space) without additional finetuning already improves prompt fidelity. To further improve the quality of the generated images, we augment the UNet denoiser with a trainable adapter in the $\mathcal{H}$-space, which efficiently blends the retrieved content with the target prompt using a cross-attention mechanism. Experimental results on fast text-to-image generation demonstrate that our approach produces high-fidelity images without compromising latency compared to existing methods.
Real-world Mapping of Gaze Fixations Using Instance Segmentation for Road Construction Safety Applications
Feb 01, 2019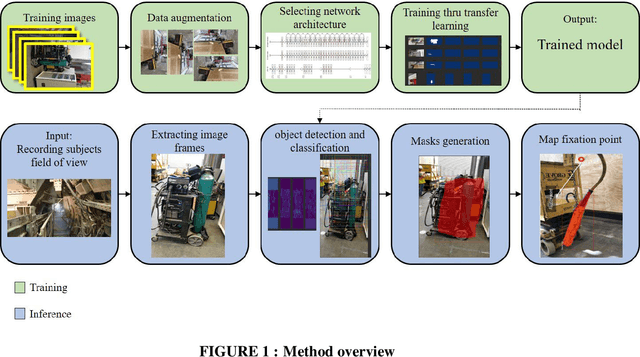
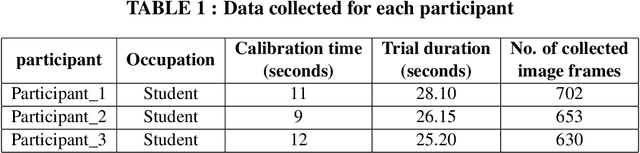

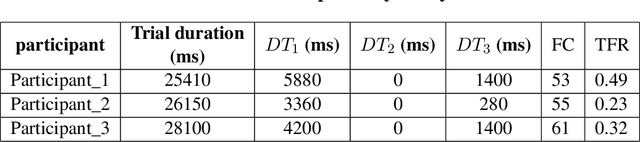
Research studies have shown that a large proportion of hazards remain unrecognized, which expose construction workers to unanticipated safety risks. Recent studies have also found that a strong correlation exists between viewing patterns of workers, captured using eye-tracking devices, and their hazard recognition performance. Therefore, it is important to analyze the viewing patterns of workers to gain a better understanding of their hazard recognition performance. This paper proposes a method that can automatically map the gaze fixations collected using a wearable eye-tracker to the predefined areas of interests. The proposed method detects these areas or objects (i.e., hazards) of interests through a computer vision-based segmentation technique and transfer learning. The mapped fixation data is then used to analyze the viewing behaviors of workers and compute their attention distribution. The proposed method is implemented on an under construction road as a case study to evaluate the performance of the proposed method.
Building an Integrated Mobile Robotic System for Real-Time Applications in Construction
Apr 18, 2018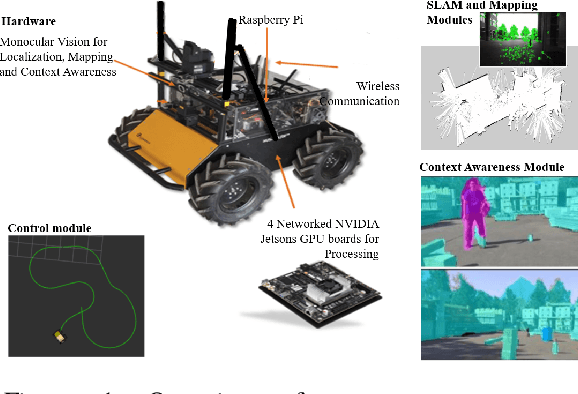
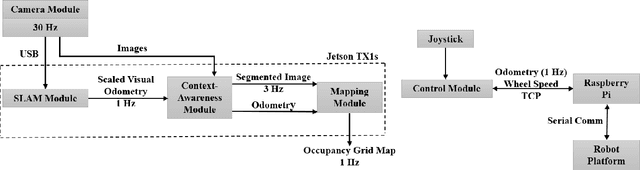

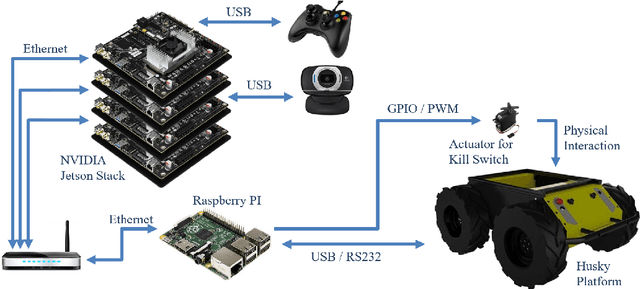
One of the major challenges of a real-time autonomous robotic system for construction monitoring is to simultaneously localize, map, and navigate over the lifetime of the robot, with little or no human intervention. Past research on Simultaneous Localization and Mapping (SLAM) and context-awareness are two active research areas in the computer vision and robotics communities. The studies that integrate both in real-time into a single modular framework for construction monitoring still need further investigation. A monocular vision system and real-time scene understanding are computationally heavy and the major state-of-the-art algorithms are tested on high-end desktops and/or servers with a high CPU- and/or GPU- computing capabilities, which affect their mobility and deployment for real-world applications. To address these challenges and achieve automation, this paper proposes an integrated robotic computer vision system, which generates a real-world spatial map of the obstacles and traversable space present in the environment in near real-time. This is done by integrating contextual Awareness and visual SLAM into a ground robotics agent. This paper presents the hardware utilization and performance of the aforementioned system for three different outdoor environments, which represent the applicability of this pipeline to diverse outdoor scenes in near real-time. The entire system is also self-contained and does not require user input, which demonstrates the potential of this computer vision system for autonomous navigation.