 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Safety-Critical Decision Making and Control Framework Combining Machine Learning and Rule-based Algorithms
Jan 30, 2022
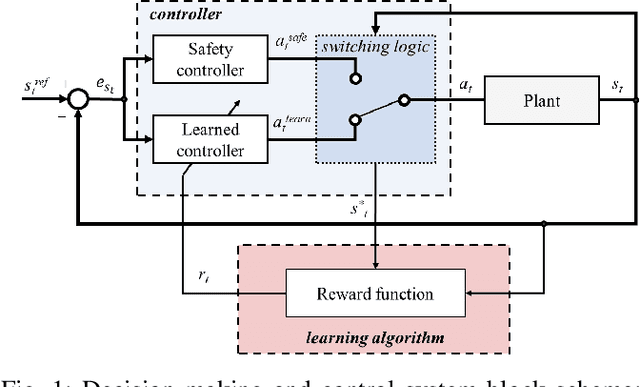
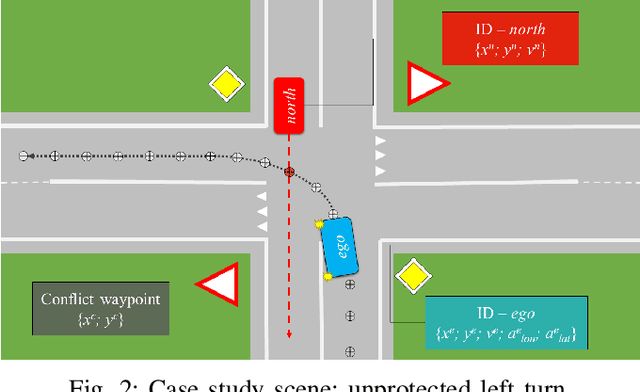
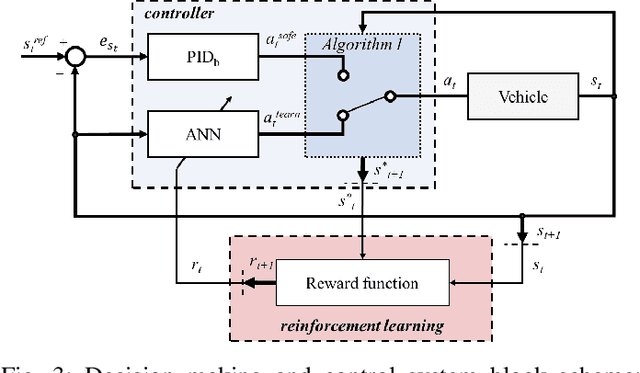
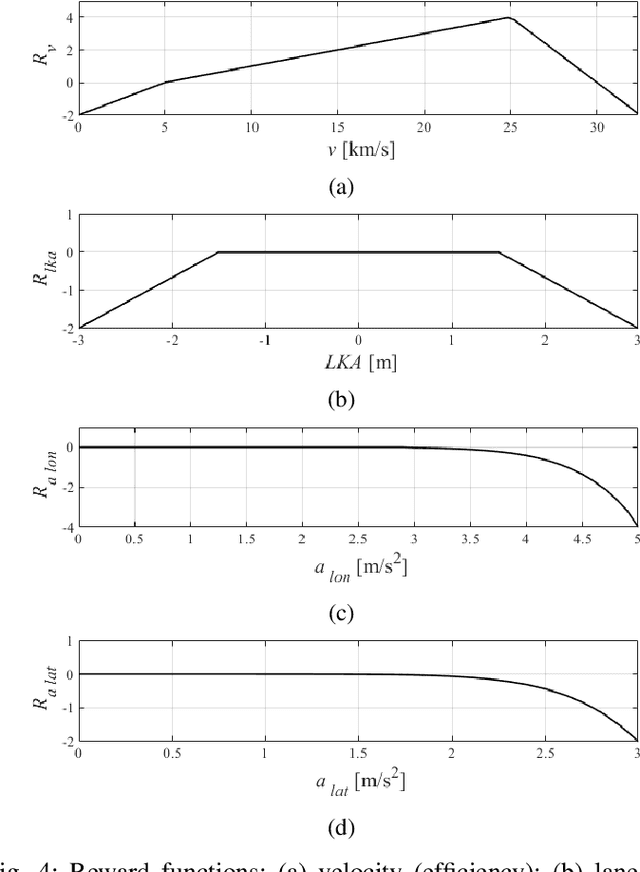
While artificial-intelligence-based methods suffer from lack of transparency, rule-based methods dominate in safety-critical systems. Yet, the latter cannot compete with the first ones in robustness to multiple requirements, for instance, simultaneously addressing safety, comfort, and efficiency. Hence, to benefit from both methods they must be joined in a single system. This paper proposes a decision making and control framework, which profits from advantages of both the rule- and machine-learning-based techniques while compensating for their disadvantages. The proposed method embodies two controllers operating in parallel, called Safety and Learned. A rule-based switching logic selects one of the actions transmitted from both controllers. The Safety controller is prioritized every time, when the Learned one does not meet the safety constraint, and also directly participates in the safe Learned controller training. Decision making and control in autonomous driving is chosen as the system case study, where an autonomous vehicle learns a multi-task policy to safely cross an unprotected intersection. Multiple requirements (i.e., safety, efficiency, and comfort) are set for vehicle operation. A numerical simulation is performed for the proposed framework validation, where its ability to satisfy the requirements and robustness to changing environment is successfully demonstrated.
Fully Test-time Adaptation by Entropy Minimization
Jun 18, 2020
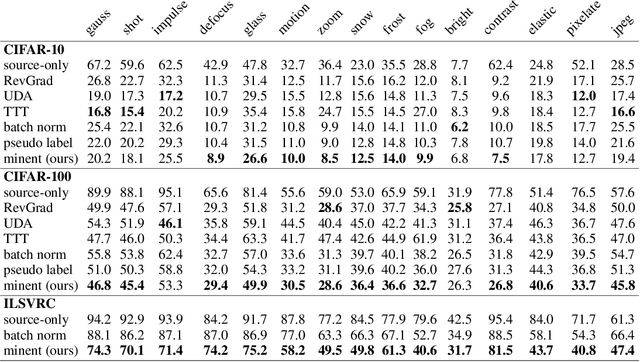

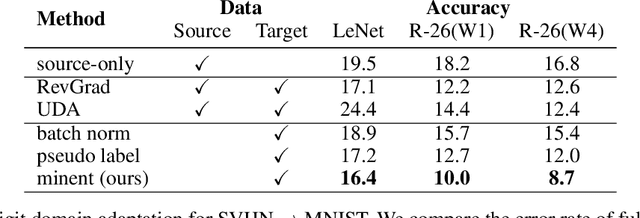
Faced with new and different data during testing, a model must adapt itself. We consider the setting of fully test-time adaptation, in which a supervised model confronts unlabeled test data from a different distribution, without the help of its labeled training data. We propose an entropy minimization approach for adaptation: we take the model's confidence as our objective as measured by the entropy of its predictions. During testing, we adapt the model by modulating its representation with affine transformations to minimize entropy. Our experiments show improved robustness to corruptions for image classification on CIFAR-10/100 and ILSVRC and demonstrate the feasibility of target-only domain adaptation for digit classification on MNIST and SVHN.
Recognition of Implicit Geographic Movement in Text
Jan 30, 2022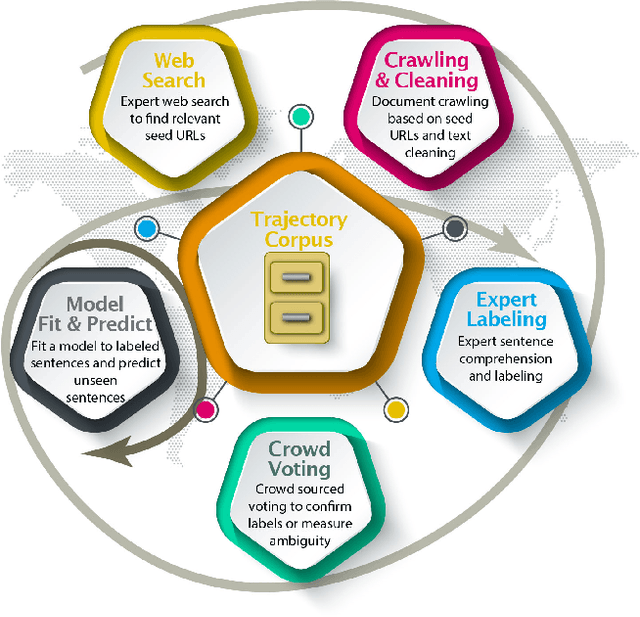
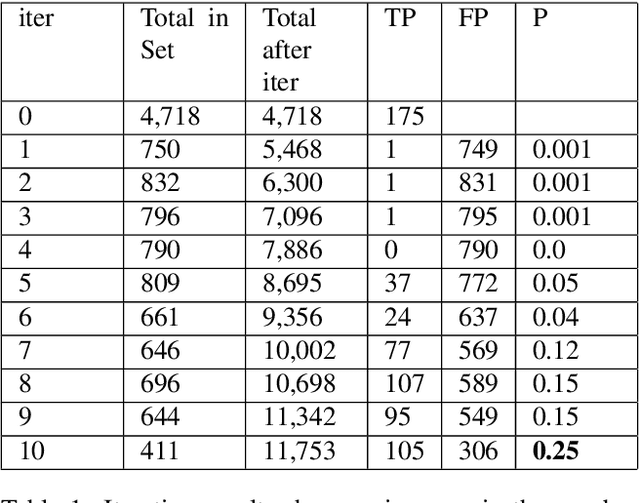

Analyzing the geographic movement of humans, animals, and other phenomena is a growing field of research. This research has benefited urban planning, logistics, animal migration understanding, and much more. Typically, the movement is captured as precise geographic coordinates and time stamps with Global Positioning Systems (GPS). Although some research uses computational techniques to take advantage of implicit movement in descriptions of route directions, hiking paths, and historical exploration routes, innovation would accelerate with a large and diverse corpus. We created a corpus of sentences labeled as describing geographic movement or not and including the type of entity moving. Creating this corpus proved difficult without any comparable corpora to start with, high human labeling costs, and since movement can at times be interpreted differently. To overcome these challenges, we developed an iterative process employing hand labeling, crowd voting for confirmation, and machine learning to predict more labels. By merging advances in word embeddings with traditional machine learning models and model ensembling, prediction accuracy is at an acceptable level to produce a large silver-standard corpus despite the small gold-standard corpus training set. Our corpus will likely benefit computational processing of geography in text and spatial cognition, in addition to detection of movement.
Predicting Breakdown Risk Based on Historical Maintenance Data for Air Force Ground Vehicles
Dec 22, 2021

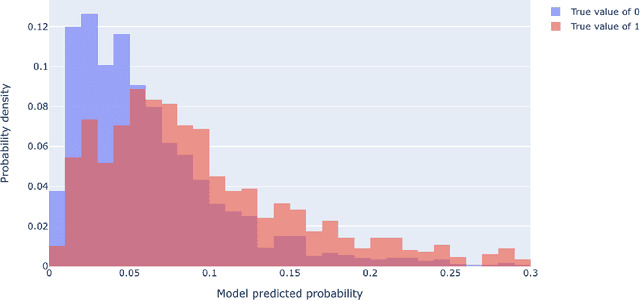
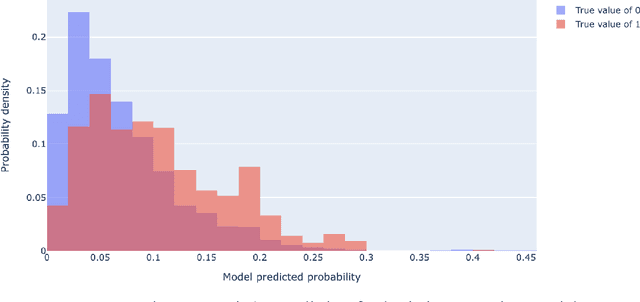
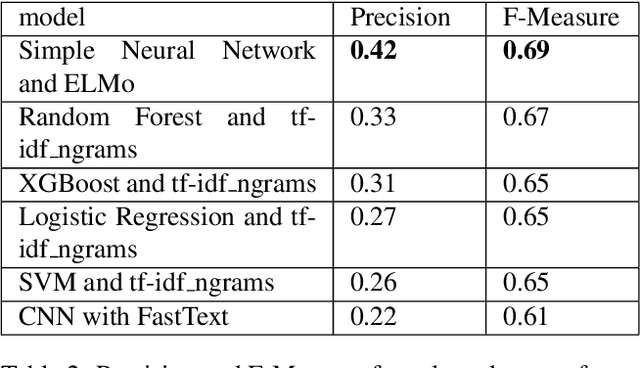
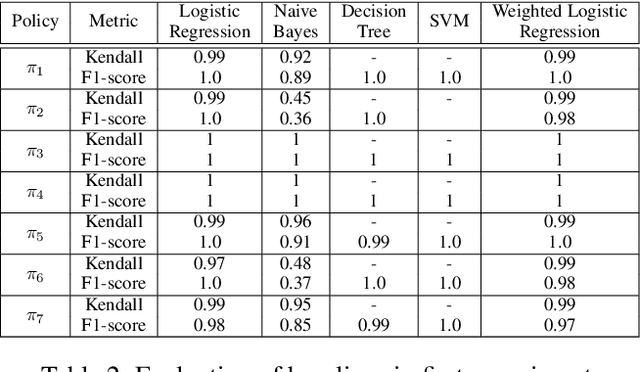
Unscheduled maintenance has contributed to longer downtime for vehicles and increased costs for Logistic Readiness Squadrons (LRSs) in the Air Force. When vehicles are in need of repair outside of their scheduled time, depending on their priority level, the entire squadron's slated repair schedule is transformed negatively. The repercussions of unscheduled maintenance are specifically seen in the increase of man hours required to maintain vehicles that should have been working well: this can include more man hours spent on maintenance itself, waiting for parts to arrive, hours spent re-organizing the repair schedule, and more. The dominant trend in the current maintenance system at LRSs is that they do not have predictive maintenance infrastructure to counteract the influx of unscheduled repairs they experience currently, and as a result, their readiness and performance levels are lower than desired. We use data pulled from the Defense Property and Accountability System (DPAS), that the LRSs currently use to store their vehicle maintenance information. Using historical vehicle maintenance data we receive from DPAS, we apply three different algorithms independently to construct an accurate predictive system to optimize maintenance schedules at any given time. Through the application of Logistics Regression, Random Forest, and Gradient Boosted Trees algorithms, we found that a Logistic Regression algorithm, fitted to our data, produced the most accurate results. Our findings indicate that not only would continuing the use of Logistic Regression be prudent for our research purposes, but that there is opportunity to further tune and optimize our Logistic Regression model for higher accuracy.
A Deep-Learning Based Optimization Approach to Address Stop-Skipping Strategy in Urban Rail Transit Lines
Sep 17, 2021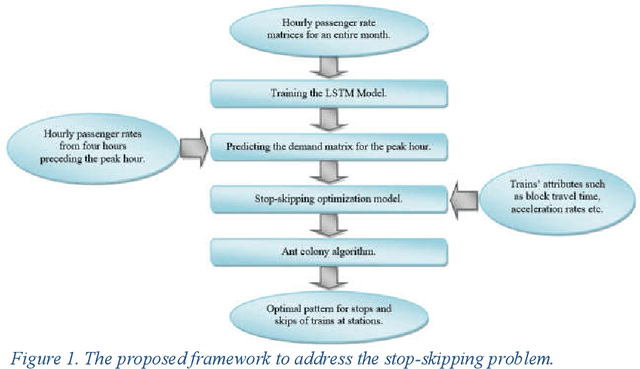

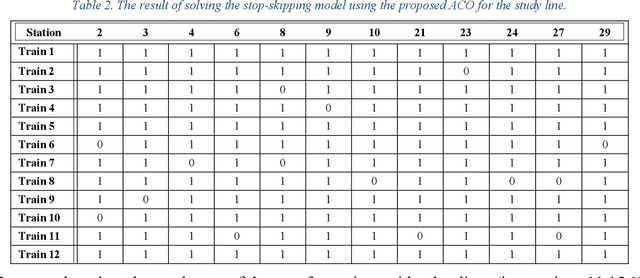
Different passenger demand rates in transit stations underscore the importance of adopting operational strategies to provide a demand-responsive service. Aiming at improving passengers' travel time, the present study introduces an advanced data-driven optimization approach to determine the optimal stop-skip pattern in urban rail transit lines. In detail, first, using the time-series smart card data for an entire month, we employ a Long Short-Term Memory (LSTM) deep learning model to predict the station-level demand rates for the peak hour. This prediction is based on four preceding hours and is especially important knowing that the true demand rates of the peak hour are posterior information that can be obtained only after the peak hour operation is finished. Moreover, utilizing a real-time prediction instead of assuming fixed demand rates, allows us to account for unexpected real-time changes which can be detrimental to the subsequent analyses. Then, we integrate the output of the LSTM model as an input to an optimization model with the objective of minimizing patrons' total travel time. Considering the exponential nature of the problem, we propose an Ant Colony Optimization technique to solve the problem in a desirable amount of time. Finally, the performance of the proposed models and the solution algorithm is assessed using real case data. The results suggest that the proposed approach can enhance the performance of the service by improving both passengers' in-vehicle time as well as passengers' waiting time.
RamanNet: A generalized neural network architecture for Raman Spectrum Analysis
Jan 20, 2022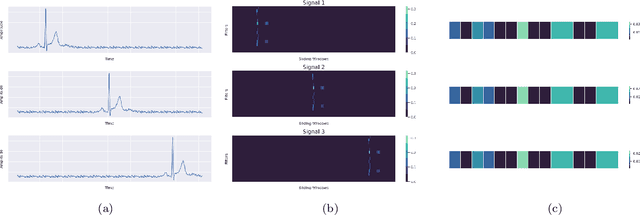
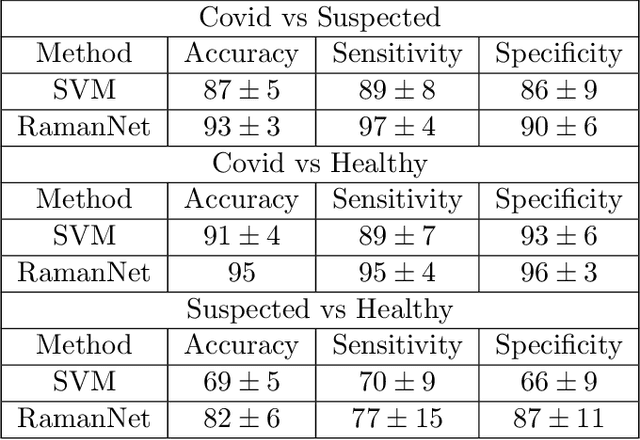
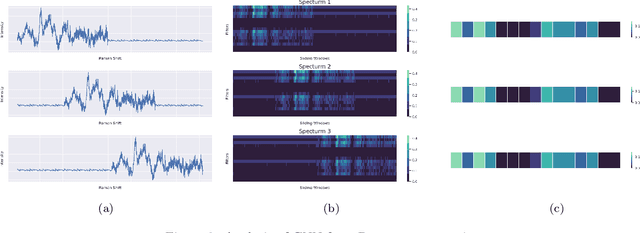

Raman spectroscopy provides a vibrational profile of the molecules and thus can be used to uniquely identify different kind of materials. This sort of fingerprinting molecules has thus led to widespread application of Raman spectrum in various fields like medical dignostics, forensics, mineralogy, bacteriology and virology etc. Despite the recent rise in Raman spectra data volume, there has not been any significant effort in developing generalized machine learning methods for Raman spectra analysis. We examine, experiment and evaluate existing methods and conjecture that neither current sequential models nor traditional machine learning models are satisfactorily sufficient to analyze Raman spectra. Both has their perks and pitfalls, therefore we attempt to mix the best of both worlds and propose a novel network architecture RamanNet. RamanNet is immune to invariance property in CNN and at the same time better than traditional machine learning models for the inclusion of sparse connectivity. Our experiments on 4 public datasets demonstrate superior performance over the much complex state-of-the-art methods and thus RamanNet has the potential to become the defacto standard in Raman spectra data analysis
Assistive Tele-op: Leveraging Transformers to Collect Robotic Task Demonstrations
Dec 09, 2021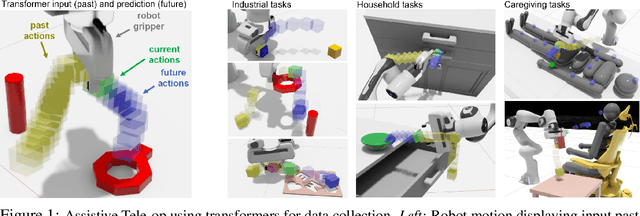
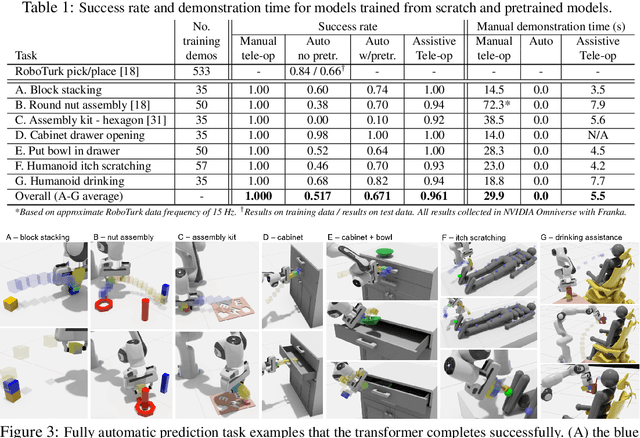
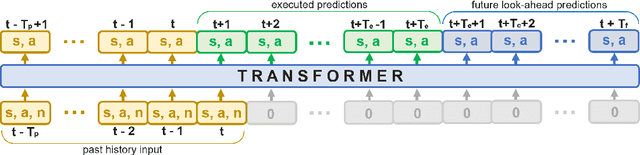
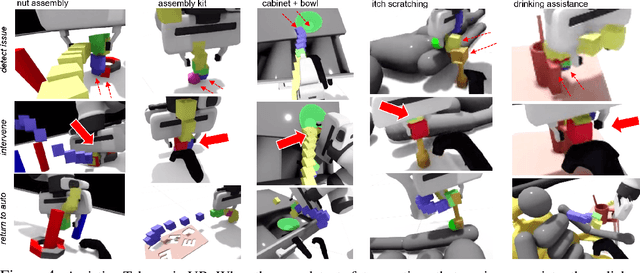
Sharing autonomy between robots and human operators could facilitate data collection of robotic task demonstrations to continuously improve learned models. Yet, the means to communicate intent and reason about the future are disparate between humans and robots. We present Assistive Tele-op, a virtual reality (VR) system for collecting robot task demonstrations that displays an autonomous trajectory forecast to communicate the robot's intent. As the robot moves, the user can switch between autonomous and manual control when desired. This allows users to collect task demonstrations with both a high success rate and with greater ease than manual teleoperation systems. Our system is powered by transformers, which can provide a window of potential states and actions far into the future -- with almost no added computation time. A key insight is that human intent can be injected at any location within the transformer sequence if the user decides that the model-predicted actions are inappropriate. At every time step, the user can (1) do nothing and allow autonomous operation to continue while observing the robot's future plan sequence, or (2) take over and momentarily prescribe a different set of actions to nudge the model back on track. We host the videos and other supplementary material at https://sites.google.com/view/assistive-teleop.
Machine Learning of Time Series Using Time-delay Embedding and Precision Annealing
Feb 12, 2019Tasking machine learning to predict segments of a time series requires estimating the parameters of a ML model with input/output pairs from the time series. Using the equivalence between statistical data assimilation and supervised machine learning, we revisit this task. The training method for the machine utilizes a precision annealing approach to identifying the global minimum of the action (-log[P]). In this way we are able to identify the number of training pairs required to produce good generalizations (predictions) for the time series. We proceed from a scalar time series $s(t_n); t_n = t_0 + n \Delta t$ and using methods of nonlinear time series analysis show how to produce a $D_E > 1$ dimensional time delay embedding space in which the time series has no false neighbors as does the observed $s(t_n)$ time series. In that $D_E$-dimensional space we explore the use of feed forward multi-layer perceptrons as network models operating on $D_E$-dimensional input and producing $D_E$-dimensional outputs.
Human-like Time Series Summaries via Trend Utility Estimation
Jan 16, 2020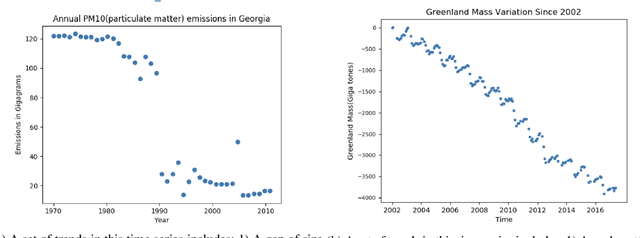

In many scenarios, humans prefer a text-based representation of quantitative data over numerical, tabular, or graphical representations. The attractiveness of textual summaries for complex data has inspired research on data-to-text systems. While there are several data-to-text tools for time series, few of them try to mimic how humans summarize for time series. In this paper, we propose a model to create human-like text descriptions for time series. Our system finds patterns in time series data and ranks these patterns based on empirical observations of human behavior using utility estimation. Our proposed utility estimation model is a Bayesian network capturing interdependencies between different patterns. We describe the learning steps for this network and introduce baselines along with their performance for each step. The output of our system is a natural language description of time series that attempts to match a human's summary of the same data.
Training-Set Distillation for Real-Time UAV Object Tracking
Mar 11, 2020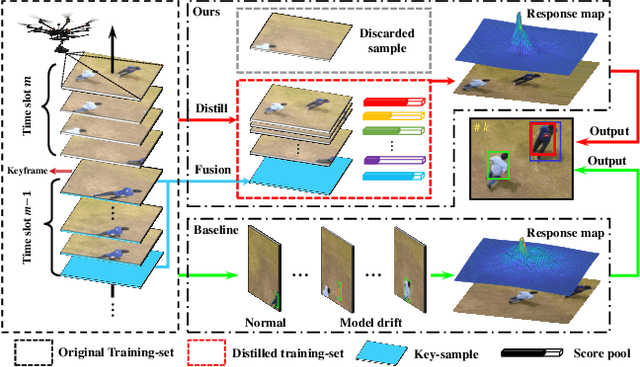
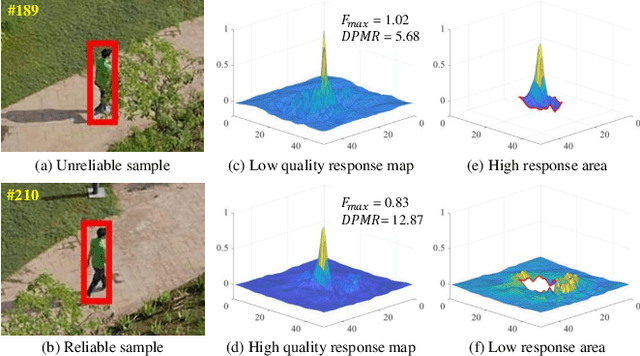
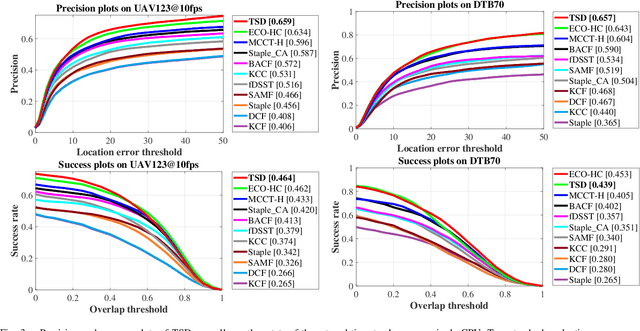
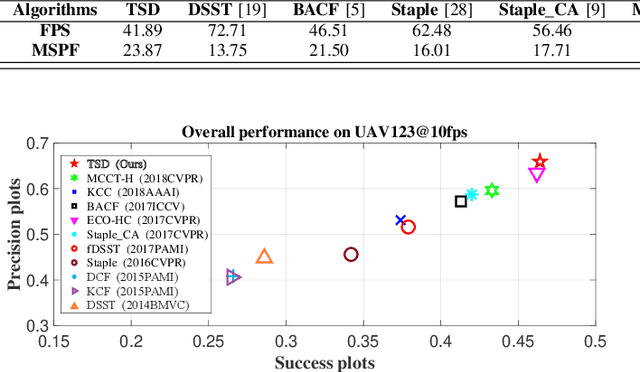
Correlation filter (CF) has recently exhibited promising performance in visual object tracking for unmanned aerial vehicle (UAV). Such online learning method heavily depends on the quality of the training-set, yet complicated aerial scenarios like occlusion or out of view can reduce its reliability. In this work, a novel time slot-based distillation approach is proposed to efficiently and effectively optimize the training-set's quality on the fly. A cooperative energy minimization function is established to score the historical samples adaptively. To accelerate the scoring process, frames with high confident tracking results are employed as the keyframes to divide the tracking process into multiple time slots. After the establishment of a new slot, the weighted fusion of the previous samples generates one key-sample, in order to reduce the number of samples to be scored. Besides, when the current time slot exceeds the maximum frame number, which can be scored, the sample with the lowest score will be discarded. Consequently, the training-set can be efficiently and reliably distilled. Comprehensive tests on two well-known UAV benchmarks prove the effectiveness of our method with real-time speed on a single CPU.