 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictors of disease outbreaks at continentalscale in the African region: Insights and predictions with geospatial artificial intelligence using earth observations and routine disease surveillance data
Nov 10, 2024



Objectives: Our research adopts computational techniques to analyze disease outbreaks weekly over a large geographic area while maintaining local-level analysis by incorporating relevant high-spatial resolution cultural and environmental datasets. The abundance of data about disease outbreaks gives scientists an excellent opportunity to uncover patterns in disease spread and make future predictions. However, data over a sizeable geographic area quickly outpace human cognition. Our study area covers a significant portion of the African continent (about 17,885,000 km2). The data size makes computational analysis vital to assist human decision-makers. Methods: We first applied global and local spatial autocorrelation for malaria, cholera, meningitis, and yellow fever case counts. We then used machine learning to predict the weekly presence of these diseases in the second-level administrative district. Lastly, we used machine learning feature importance methods on the variables that affect spread. Results: Our spatial autocorrelation results show that geographic nearness is critical but varies in effect and space. Moreover, we identified many interesting hot and cold spots and spatial outliers. The machine learning model infers a binary class of cases or none with the best F1 score of 0.96 for malaria. Machine learning feature importance uncovered critical cultural and environmental factors affecting outbreaks and variations between diseases. Conclusions: Our study shows that data analytics and machine learning are vital to understanding and monitoring disease outbreaks locally across vast areas. The speed at which these methods produce insights can be critical during epidemics and emergencies.
* 15 pages, 3 figures, 7 tables
Recognition of Implicit Geographic Movement in Text
Jan 30, 2022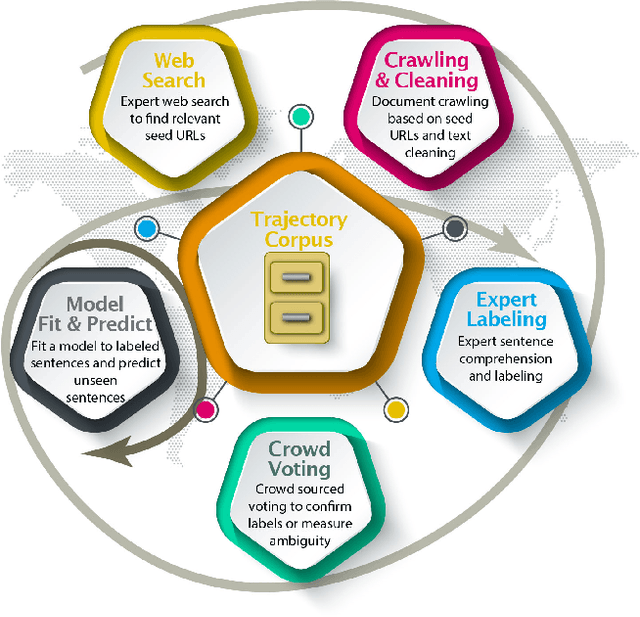
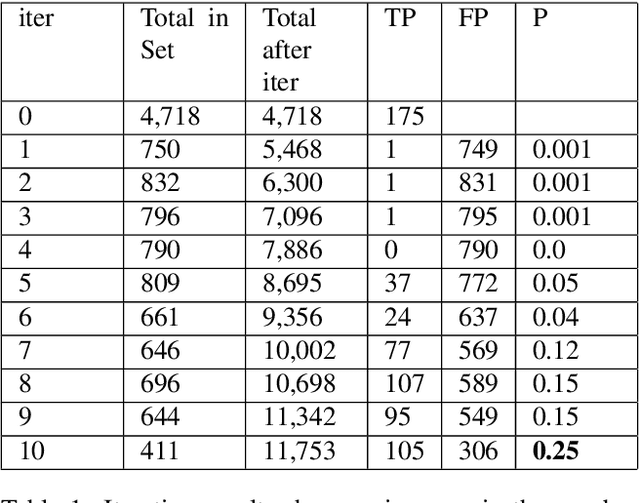

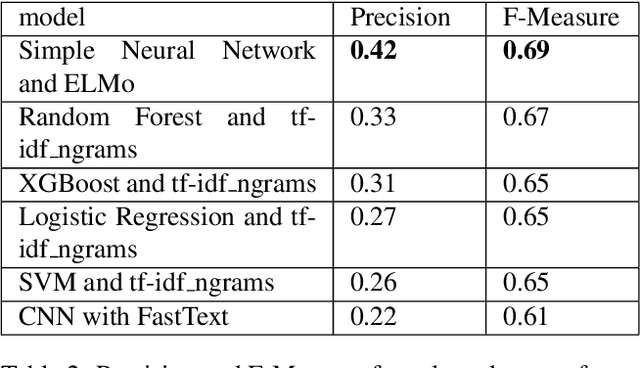
Analyzing the geographic movement of humans, animals, and other phenomena is a growing field of research. This research has benefited urban planning, logistics, animal migration understanding, and much more. Typically, the movement is captured as precise geographic coordinates and time stamps with Global Positioning Systems (GPS). Although some research uses computational techniques to take advantage of implicit movement in descriptions of route directions, hiking paths, and historical exploration routes, innovation would accelerate with a large and diverse corpus. We created a corpus of sentences labeled as describing geographic movement or not and including the type of entity moving. Creating this corpus proved difficult without any comparable corpora to start with, high human labeling costs, and since movement can at times be interpreted differently. To overcome these challenges, we developed an iterative process employing hand labeling, crowd voting for confirmation, and machine learning to predict more labels. By merging advances in word embeddings with traditional machine learning models and model ensembling, prediction accuracy is at an acceptable level to produce a large silver-standard corpus despite the small gold-standard corpus training set. Our corpus will likely benefit computational processing of geography in text and spatial cognition, in addition to detection of movement.
Differentiating Geographic Movement Described in Text Documents
Jan 12, 2022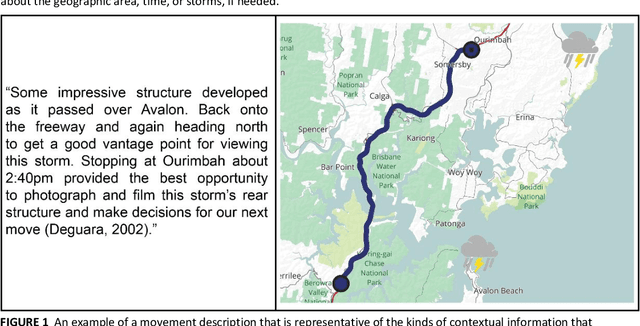
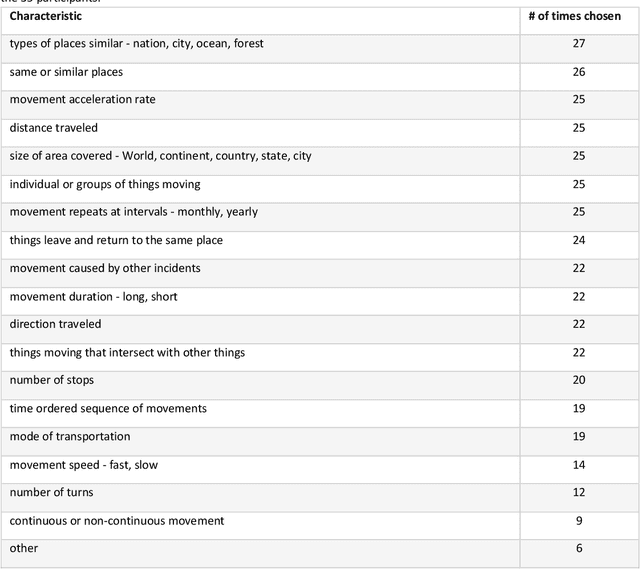
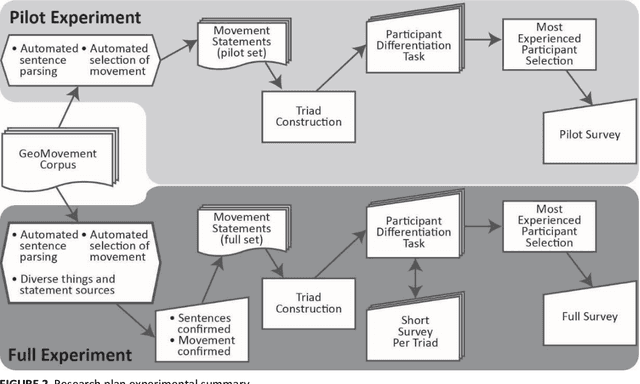
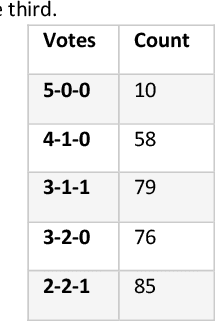
Understanding movement described in text documents is important since text descriptions of movement contain a wealth of geographic and contextual information about the movement of people, wildlife, goods, and much more. Our research makes several contributions to improve our understanding of movement descriptions in text. First, we show how interpreting geographic movement described in text is challenging because of general spatial terms, linguistic constructions that make the thing(s) moving unclear, and many types of temporal references and groupings, among others. Next, as a step to overcome these challenges, we report on an experiment with human subjects through which we identify multiple important characteristics of movement descriptions (found in text) that humans use to differentiate one movement description from another. Based on our empirical results, we provide recommendations for computational analysis using movement described in text documents. Our findings contribute towards an improved understanding of the important characteristics of the underused information about geographic movement that is in the form of text descriptions.