 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-Time Trajectory Optimization in Robot-Assisted Exercise and Rehabilitation
Apr 22, 2021
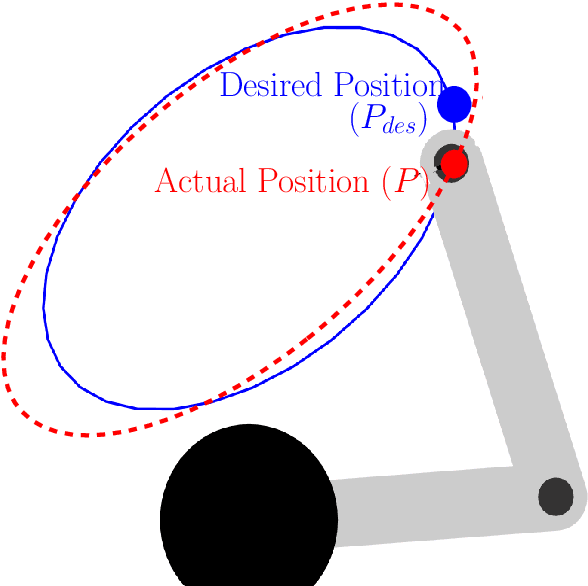
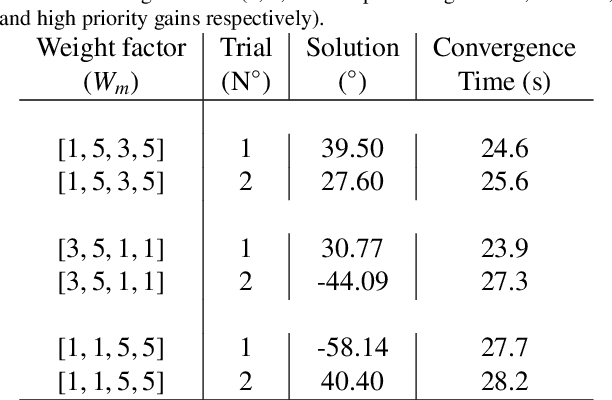
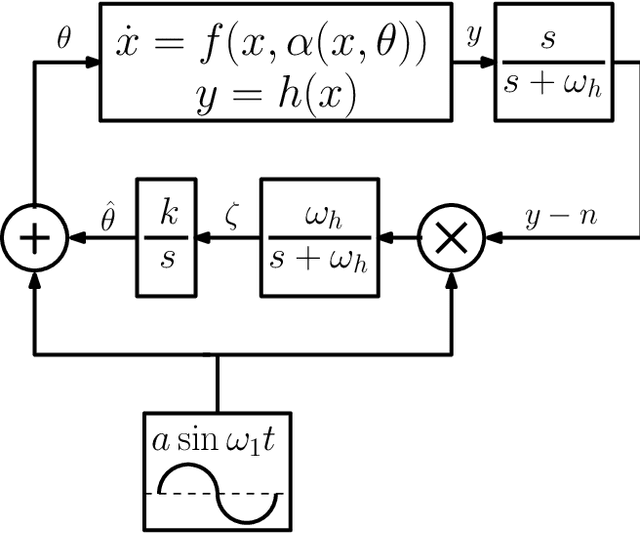
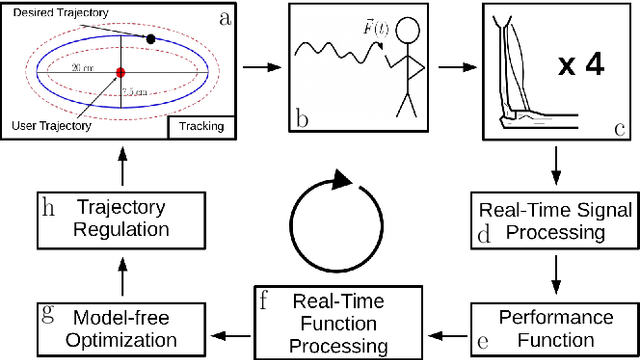
This work focuses on the optimization of the training trajectory orientation using a robot as an advanced exercise machine (AEM) and muscle activations as biofeedback. Muscle recruitment patterns depend on trajectory parameters of the AEMs and correlate with the efficiency of exercise. Thus, improvements to training efficiency may be achieved by optimizing these parameters. The optimal regulation of these parameters is challenging because of the complexity of the physiological dynamics from person to person as a result of the unique physical features such as musculoskeletal distribution. Furthermore, these effects can vary due to fatigue, body temperature, and other physiological factors. In this paper, a model-free optimization method using Extremum Seeking Control (ESC) as a real-time optimizer is proposed. After selecting a muscle objective, this method seeks for the optimal combination of parameters using the muscle activations as biofeedback. The muscle objective can be selected by a therapist to emphasize or de-emphasize certain muscle groups. The feasibility of this method has been proven for the automatic regulation of an ellipsoidal curve orientation, suggesting the existence of two local optimal orientations. This methodology can also be applied to other parameter regulations using a different physiological effects such as oxygen consumption and heart rate as biofeedback.
EdgeMap: CrowdSourcing High Definition Map in Automotive Edge Computing
Jan 20, 2022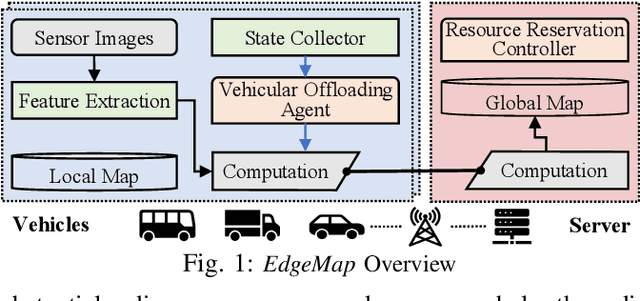
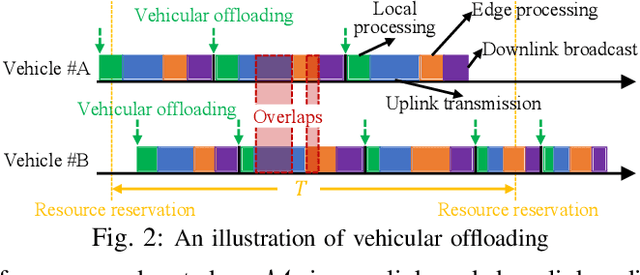
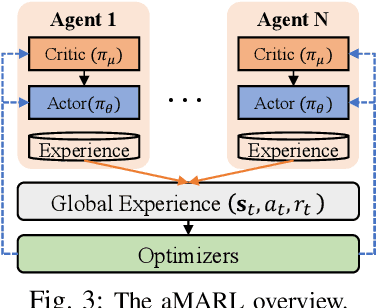
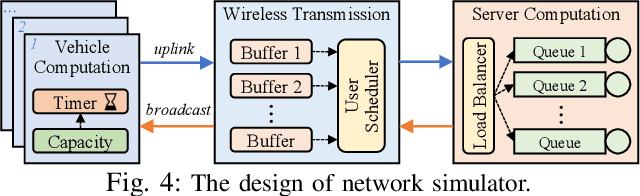
High definition (HD) map needs to be updated frequently to capture road changes, which is constrained by limited specialized collection vehicles. To maintain an up-to-date map, we explore crowdsourcing data from connected vehicles. Updating the map collaboratively is, however, challenging under constrained transmission and computation resources in dynamic networks. In this paper, we propose EdgeMap, a crowdsourcing HD map to minimize the usage of network resources while maintaining the latency requirements. We design a DATE algorithm to adaptively offload vehicular data on a small time scale and reserve network resources on a large time scale, by leveraging the multi-agent deep reinforcement learning and Gaussian process regression. We evaluate the performance of EdgeMap with extensive network simulations in a time-driven end-to-end simulator. The results show that EdgeMap reduces more than 30% resource usage as compared to state-of-the-art solutions.
Multi-phase Deformable Registration for Time-dependent Abdominal Organ Variations
Mar 08, 2021
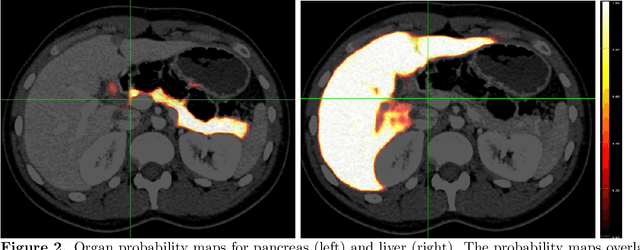
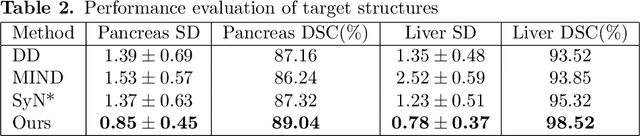
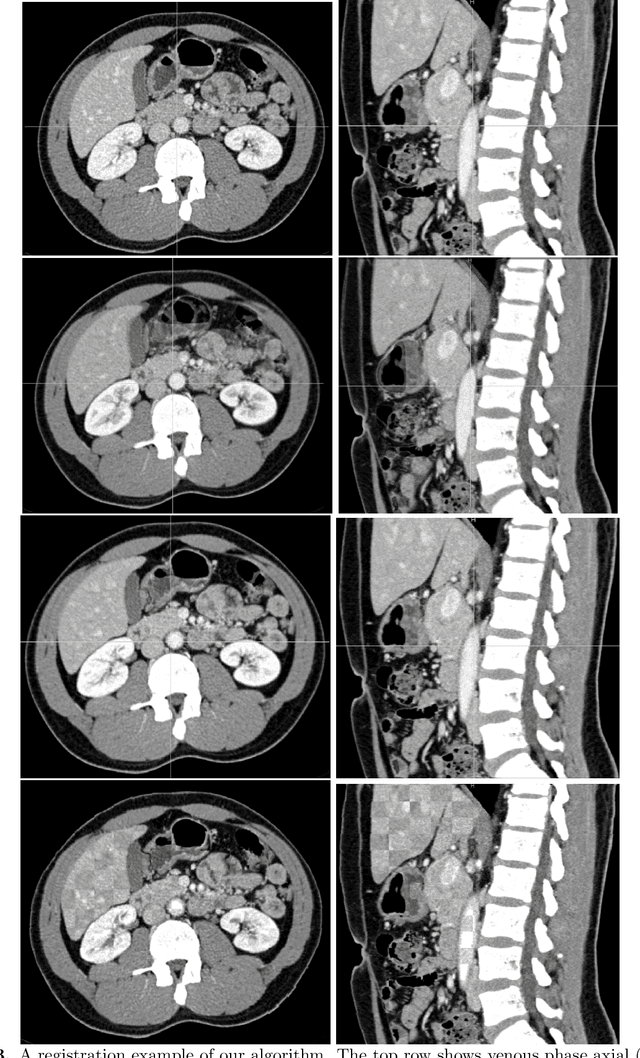
Human body is a complex dynamic system composed of various sub-dynamic parts. Especially, thoracic and abdominal organs have complex internal shape variations with different frequencies by various reasons such as respiration with fast motion and peristalsis with slower motion. CT protocols for abdominal lesions are multi-phase scans for various tumor detection to use different vascular contrast, however, they are not aligned well enough to visually check the same area. In this paper, we propose a time-efficient and accurate deformable registration algorithm for multi-phase CT scans considering abdominal organ motions, which can be applied for differentiable or non-differentiable motions of abdominal organs. Experimental results shows the registration accuracy as 0.85 +/- 0.45mm (mean +/- STD) for pancreas within 1 minute for the whole abdominal region.
Performer: A Novel PPG to ECG Reconstruction Transformer For a Digital Biomarker of Cardiovascular Disease Detection
Apr 27, 2022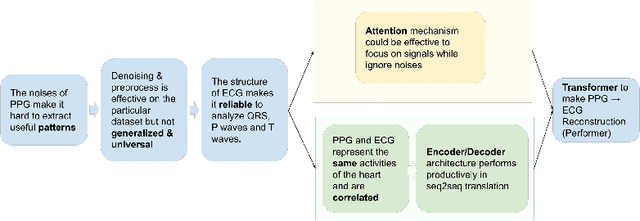
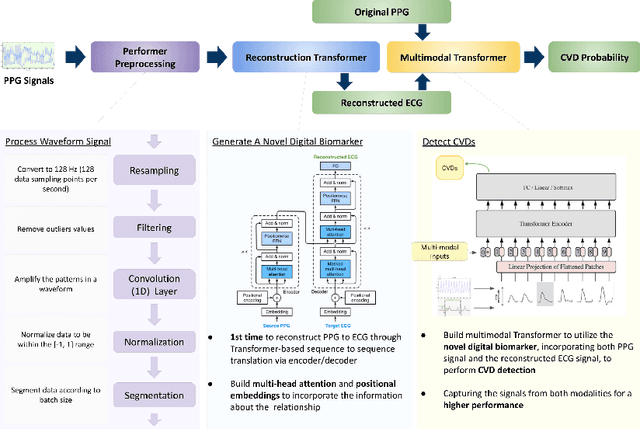
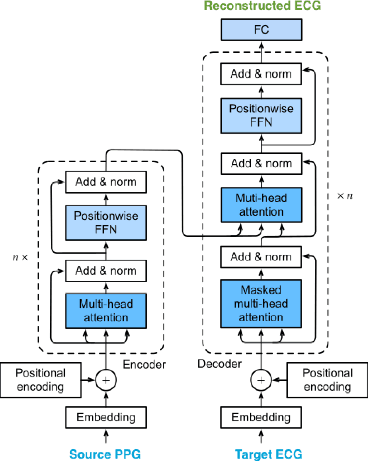
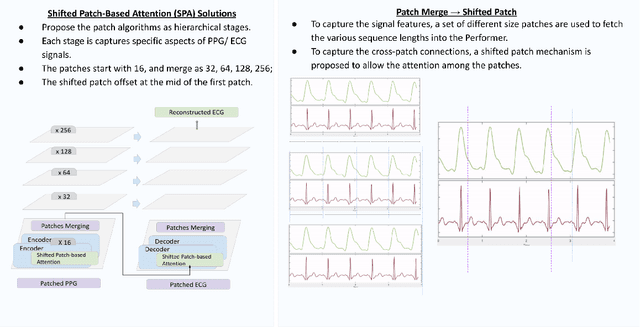
Cardiovascular diseases (CVDs) have become the top one cause of death; three-quarters of these deaths occur in lower-income communities. Electrocardiography (ECG), an electrical measurement capturing the cardiac activities, is a gold-standard to diagnose CVDs. However, ECG is infeasible for continuous cardiac monitoring due to its requirement for user participation. Meanwhile, photoplethysmography (PPG) is easy to collect, but the limited accuracy constrains its clinical usage. In this research, a novel Transformer-based architecture, Performer, is invented to reconstruct ECG from PPG and to create a novel digital biomarker, PPG along with its reconstructed ECG, as multiple modalities for CVD detection. This architecture, for the first time, performs Transformer sequence to sequence translation on biomedical waveforms, while also utilizing the advantages of the easily accessible PPG and the well-studied base of ECG. Shifted Patch-based Attention (SPA) is created to maximize the signal features by fetching the various sequence lengths as hierarchical stages into the training while also capturing cross-patch connections through the shifted patch mechanism. This architecture generates a state-of-the-art performance of 0.29 RMSE for reconstructing ECG from PPG, achieving an average of 95.9% diagnosis for CVDs on the MIMIC III dataset and 75.9% for diabetes on the PPG-BP dataset. Performer, along with its novel digital biomarker, offers a low-cost and non-invasive solution for continuous cardiac monitoring, only requiring the easily extractable PPG data to reconstruct the not-as-accessible ECG data. As a prove of concept, an earring wearable, named PEARL (prototype), is designed to scale up the point-of-care (POC) healthcare system.
Quantune: Post-training Quantization of Convolutional Neural Networks using Extreme Gradient Boosting for Fast Deployment
Feb 10, 2022
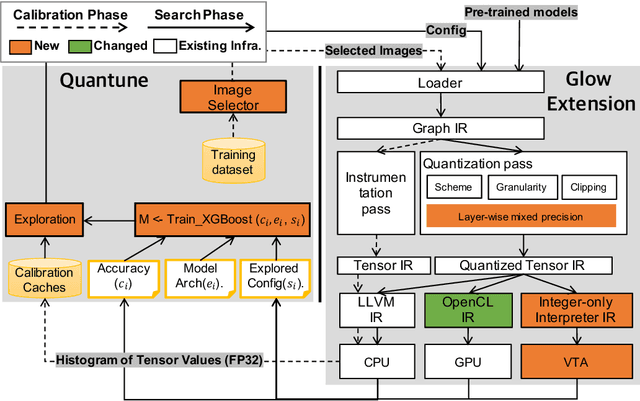
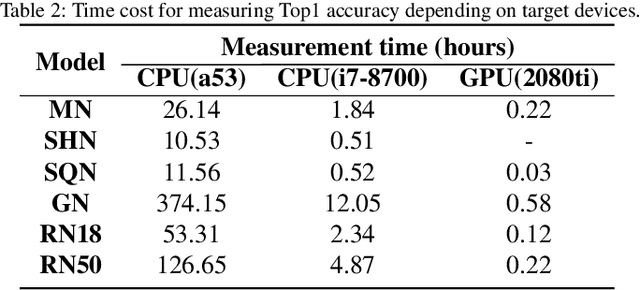
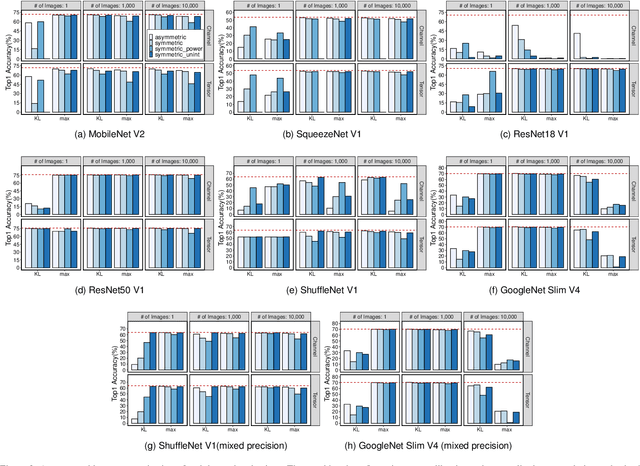
To adopt convolutional neural networks (CNN) for a range of resource-constrained targets, it is necessary to compress the CNN models by performing quantization, whereby precision representation is converted to a lower bit representation. To overcome problems such as sensitivity of the training dataset, high computational requirements, and large time consumption, post-training quantization methods that do not require retraining have been proposed. In addition, to compensate for the accuracy drop without retraining, previous studies on post-training quantization have proposed several complementary methods: calibration, schemes, clipping, granularity, and mixed-precision. To generate a quantized model with minimal error, it is necessary to study all possible combinations of the methods because each of them is complementary and the CNN models have different characteristics. However, an exhaustive or a heuristic search is either too time-consuming or suboptimal. To overcome this challenge, we propose an auto-tuner known as Quantune, which builds a gradient tree boosting model to accelerate the search for the configurations of quantization and reduce the quantization error. We evaluate and compare Quantune with the random, grid, and genetic algorithms. The experimental results show that Quantune reduces the search time for quantization by approximately 36.5x with an accuracy loss of 0.07 ~ 0.65% across six CNN models, including the fragile ones (MobileNet, SqueezeNet, and ShuffleNet). To support multiple targets and adopt continuously evolving quantization works, Quantune is implemented on a full-fledged compiler for deep learning as an open-sourced project.
Hierarchical-Absolute Reciprocity Calibration for Millimeter-wave Hybrid Beamforming Systems
Apr 14, 2022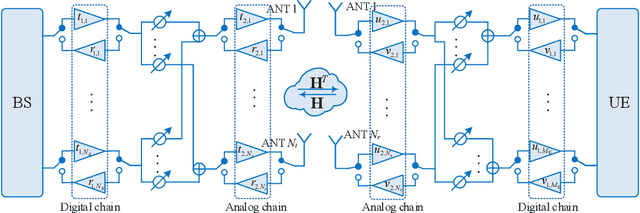
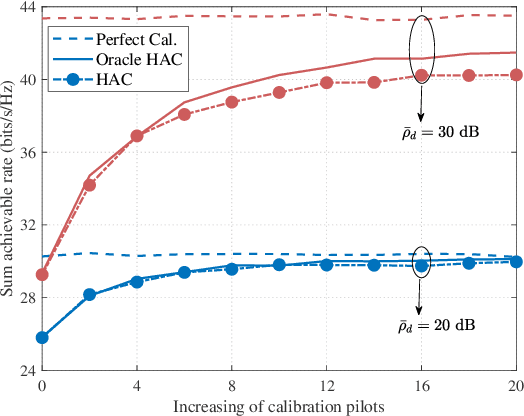
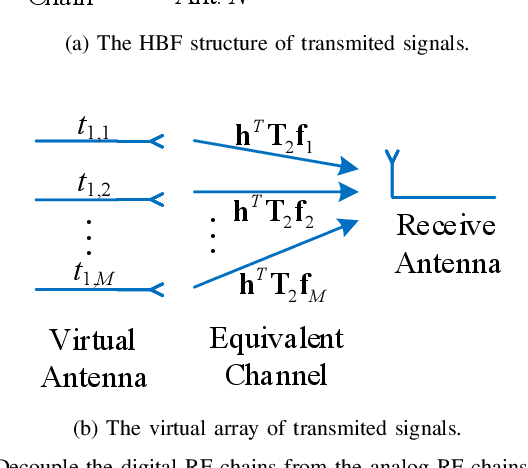

In time-division duplexing (TDD) millimeter-wave (mmWave) massive multiple-input multiple-output (MIMO) systems, the reciprocity mismatch severely degrades the performance of the hybrid beamforming (HBF). In this work, to mitigate the detrimental effect of the reciprocity mismatch, we investigate reciprocity calibration for the mmWave-HBF system with a fully-connected phase shifter network. To reduce the overhead and computational complexity of reciprocity calibration, we first decouple digital radio frequency (RF) chains and analog RF chains with beamforming design. Then, the entire calibration problem of the HBF system is equivalently decomposed into two subproblems corresponding to the digital-chain calibration and analog-chain calibration. To solve the calibration problems efficiently, a closed-form solution to the digital-chain calibration problem is derived, while an iterative-alternating optimization algorithm for the analog-chain calibration problem is proposed. To measure the performance of the proposed algorithm, we derive the Cram\'er-Rao lower bound on the errors in estimating mismatch coefficients. The results reveal that the estimation errors of mismatch coefficients of digital and analog chains are uncorrelated, and that the mismatch coefficients of receive digital chains can be estimated perfectly. Simulation results are presented to validate the analytical results and to show the performance of the proposed calibration approach.
Concept Drift Adaptation for CTR Prediction in Online Advertising Systems
Apr 01, 2022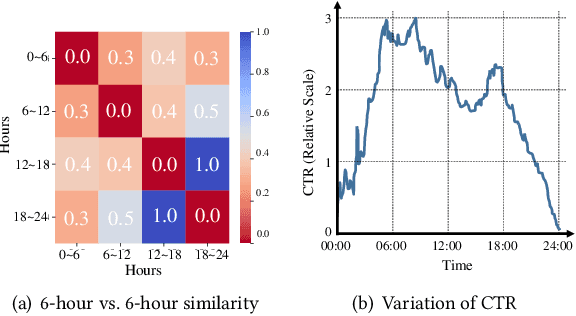
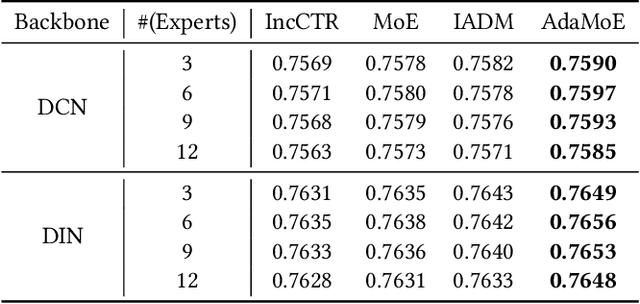
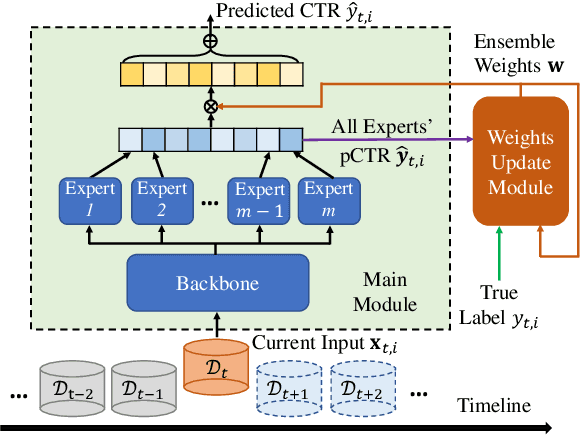
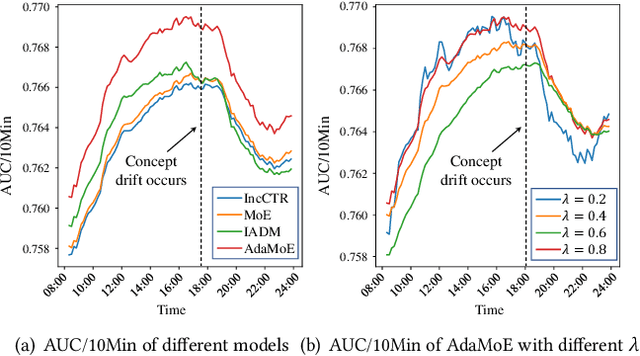
Click-through rate (CTR) prediction is a crucial task in web search, recommender systems, and online advertisement displaying. In practical application, CTR models often serve with high-speed user-generated data streams, whose underlying distribution rapidly changing over time. The concept drift problem inevitably exists in those streaming data, which can lead to performance degradation due to the timeliness issue. To ensure model freshness, incremental learning has been widely adopted in real-world production systems. However, it is hard for the incremental update to achieve the balance of the CTR models between the adaptability to capture the fast-changing trends and generalization ability to retain common knowledge. In this paper, we propose adaptive mixture of experts (AdaMoE), a new framework to alleviate the concept drift problem by adaptive filtering in the data stream of CTR prediction. The extensive experiments on the offline industrial dataset and online A/B tests show that our AdaMoE significantly outperforms all incremental learning frameworks considered.
ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Mar 29, 2022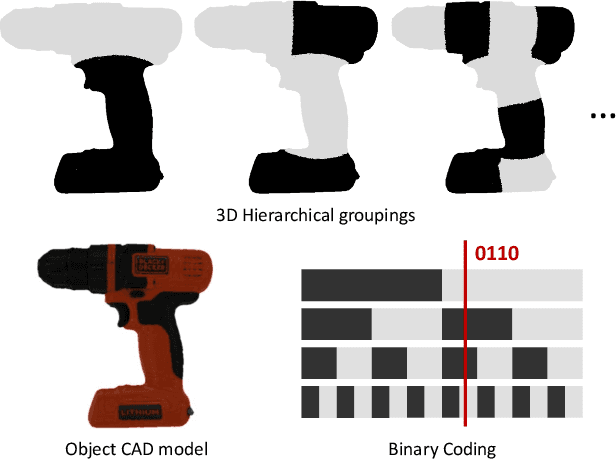
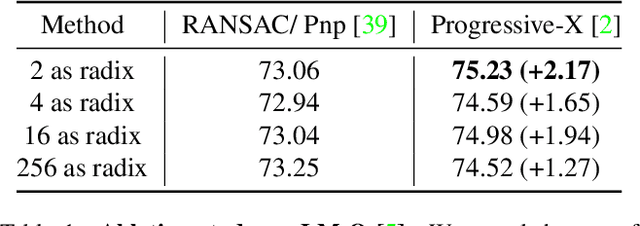
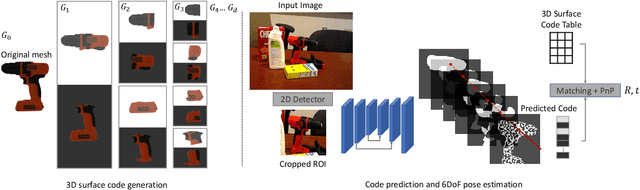

Establishing correspondences from image to 3D has been a key task of 6DoF object pose estimation for a long time. To predict pose more accurately, deeply learned dense maps replaced sparse templates. Dense methods also improved pose estimation in the presence of occlusion. More recently researchers have shown improvements by learning object fragments as segmentation. In this work, we present a discrete descriptor, which can represent the object surface densely. By incorporating a hierarchical binary grouping, we can encode the object surface very efficiently. Moreover, we propose a coarse to fine training strategy, which enables fine-grained correspondence prediction. Finally, by matching predicted codes with object surface and using a PnP solver, we estimate the 6DoF pose. Results on the public LM-O and YCB-V datasets show major improvement over the state of the art w.r.t. ADD(-S) metric, even surpassing RGB-D based methods in some cases.
Picosecond Hyperspectral Fringe Pattern Projection for 3D Surface Measurement
Mar 18, 2022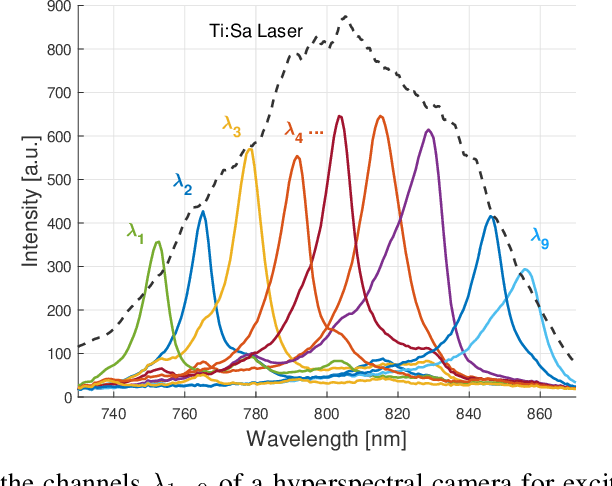
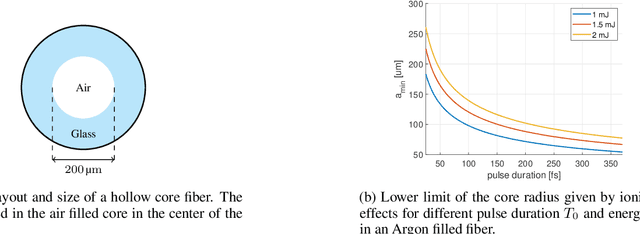
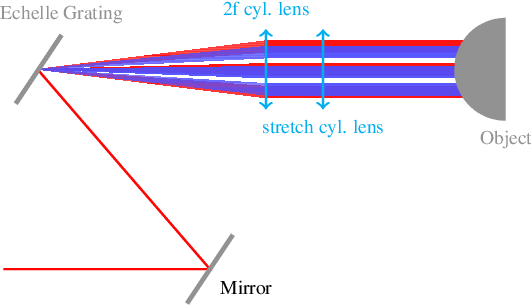

Active stereovision systems for the 3D measurement of surfaces rely on the sequential projection of different fringe patterns onto the scene to robustly and accurately generate 3D surface data. This limits the temporal resolution to the time by which a sufficiently high number of patterns can be projected and recorded. By encoding patterns spectrally and recording them with a hyperspectral imager, it is possible to record several patterns in a single image, limiting the temporal resolution to only the duration of the illumination. A picosecond 3D surface measurement was demonstrated using a high pulse energy femtosecond Ti:Sa laser, spectrally broadened in a hollow core fiber, and two hyperspectral cameras recording the patterns generated by diffraction at an Echelle grating.
Medical Image Segmentation on MRI Images with Missing Modalities: A Review
Mar 11, 2022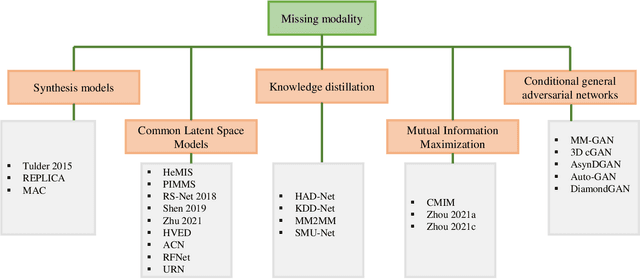
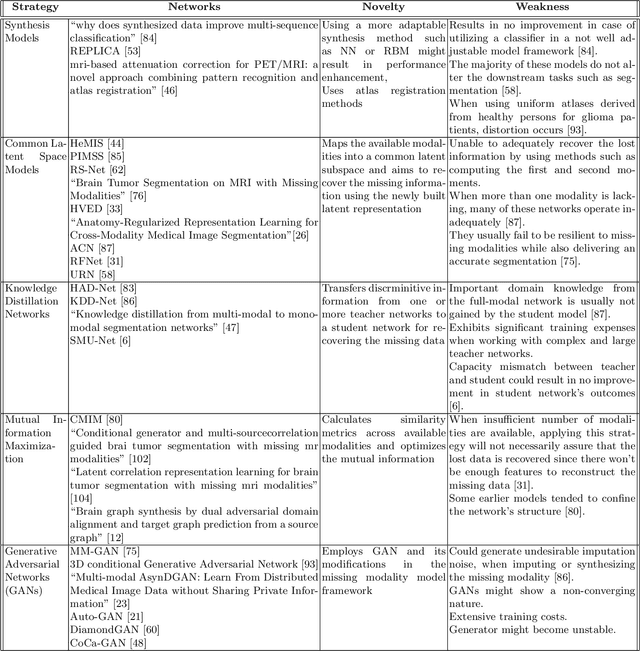
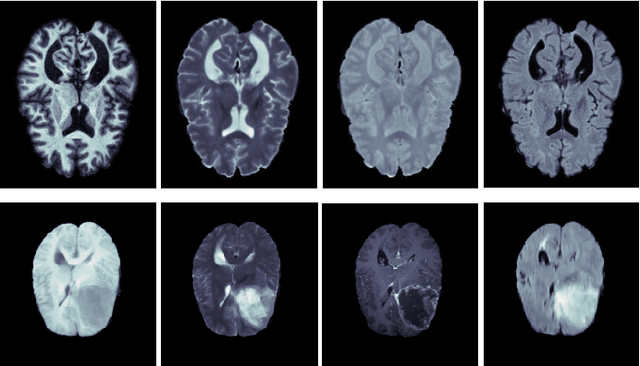
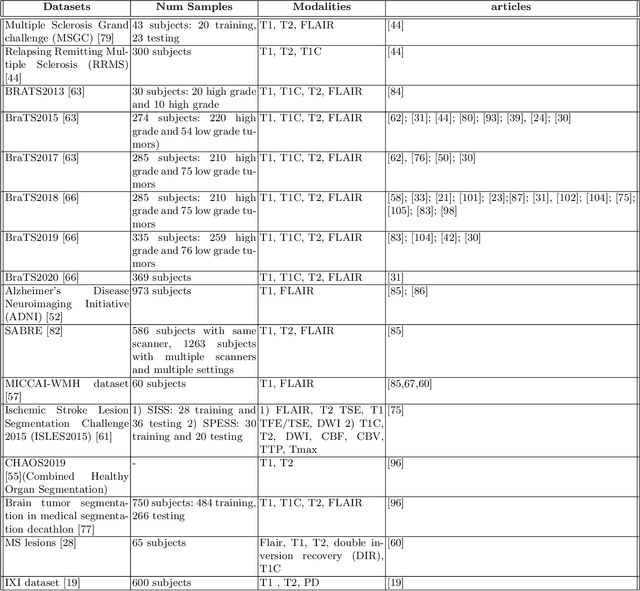
Dealing with missing modalities in Magnetic Resonance Imaging (MRI) and overcoming their negative repercussions is considered a hurdle in biomedical imaging. The combination of a specified set of modalities, which is selected depending on the scenario and anatomical part being scanned, will provide medical practitioners with full information about the region of interest in the human body, hence the missing MRI sequences should be reimbursed. The compensation of the adverse impact of losing useful information owing to the lack of one or more modalities is a well-known challenge in the field of computer vision, particularly for medical image processing tasks including tumour segmentation, tissue classification, and image generation. Various approaches have been developed over time to mitigate this problem's negative implications and this literature review goes through a significant number of the networks that seek to do so. The approaches reviewed in this work are reviewed in detail, including earlier techniques such as synthesis methods as well as later approaches that deploy deep learning, such as common latent space models, knowledge distillation networks, mutual information maximization, and generative adversarial networks (GANs). This work discusses the most important approaches that have been offered at the time of this writing, examining the novelty, strength, and weakness of each one. Furthermore, the most commonly used MRI datasets are highlighted and described. The main goal of this research is to offer a performance evaluation of missing modality compensating networks, as well as to outline future strategies for dealing with this issue.