 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Task Time Series Forecasting With Shared Attention
Jan 24, 2021
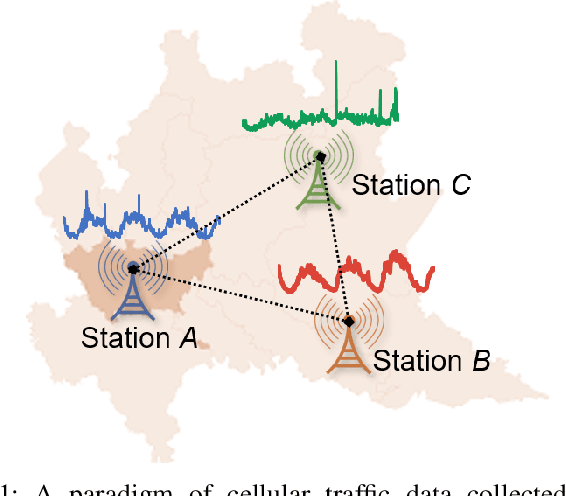
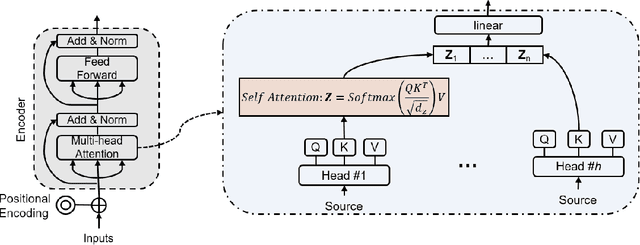
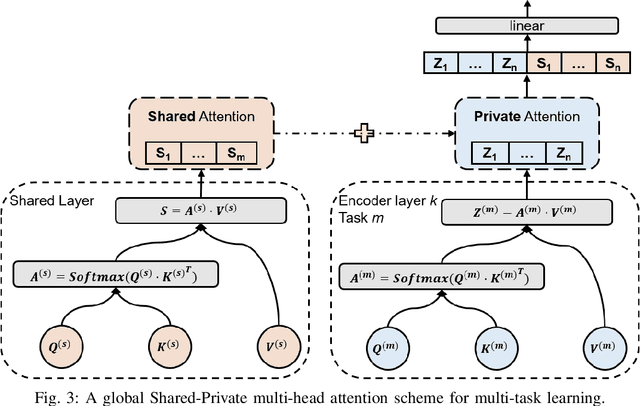
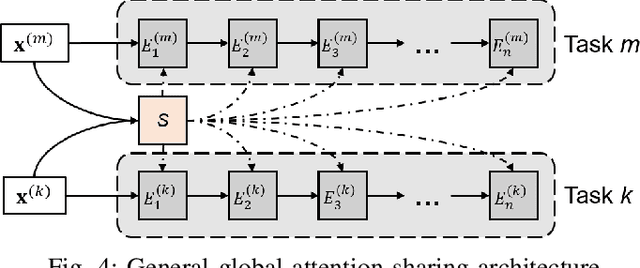
Time series forecasting is a key component in many industrial and business decision processes and recurrent neural network (RNN) based models have achieved impressive progress on various time series forecasting tasks. However, most of the existing methods focus on single-task forecasting problems by learning separately based on limited supervised objectives, which often suffer from insufficient training instances. As the Transformer architecture and other attention-based models have demonstrated its great capability of capturing long term dependency, we propose two self-attention based sharing schemes for multi-task time series forecasting which can train jointly across multiple tasks. We augment a sequence of paralleled Transformer encoders with an external public multi-head attention function, which is updated by all data of all tasks. Experiments on a number of real-world multi-task time series forecasting tasks show that our proposed architectures can not only outperform the state-of-the-art single-task forecasting baselines but also outperform the RNN-based multi-task forecasting method.
Temporal Inductive Logic Reasoning
Jun 09, 2022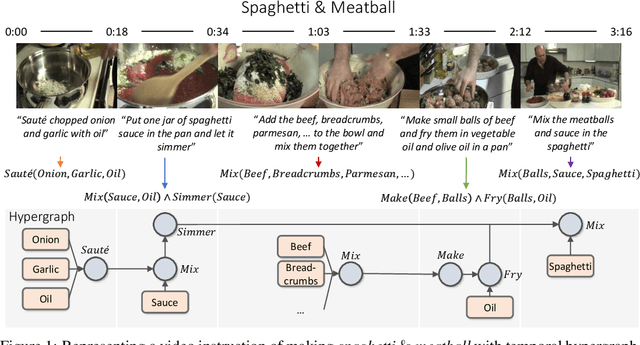
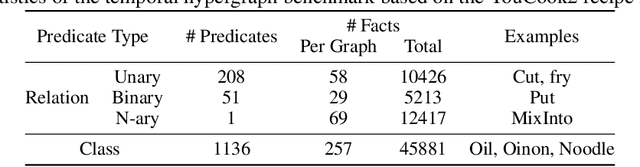
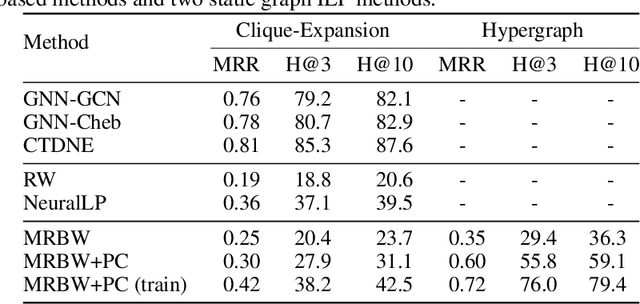
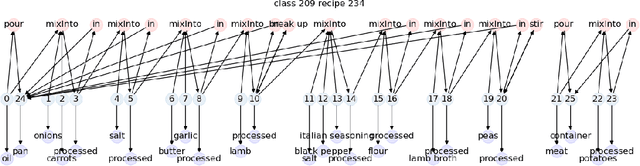
Inductive logic reasoning is one of the fundamental tasks on graphs, which seeks to generalize patterns from the data. This task has been studied extensively for traditional graph datasets such as knowledge graphs (KGs), with representative techniques such as inductive logic programming (ILP). Existing ILP methods typically assume learning from KGs with static facts and binary relations. Beyond KGs, graph structures are widely present in other applications such as video instructions, scene graphs and program executions. While inductive logic reasoning is also beneficial for these applications, applying ILP to the corresponding graphs is nontrivial: they are more complex than KGs, which usually involve timestamps and n-ary relations, effectively a type of hypergraph with temporal events. In this work, we study two of such applications and propose to represent them as hypergraphs with time intervals. To reason on this graph, we propose the multi-start random B-walk that traverses this hypergraph. Combining it with a path-consistency algorithm, we propose an efficient backward-chaining ILP method that learns logic rules by generalizing from both the temporal and the relational data.
Coupling Visual Semantics of Artificial Neural Networks and Human Brain Function via Synchronized Activations
Jun 22, 2022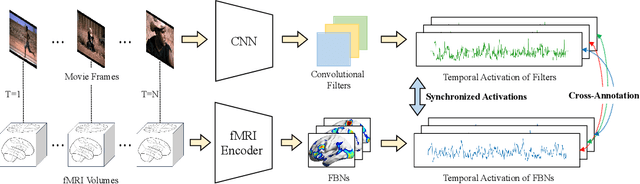
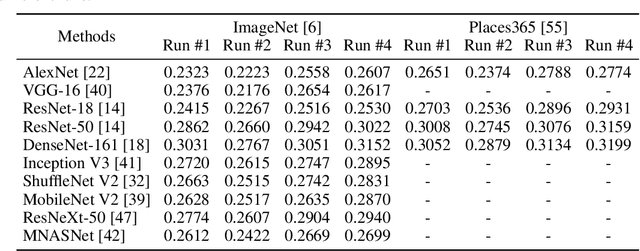
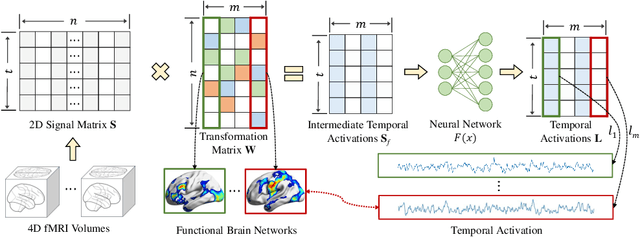
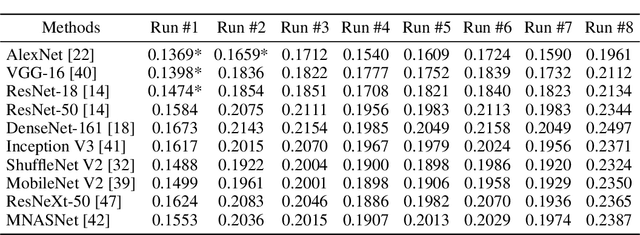
Artificial neural networks (ANNs), originally inspired by biological neural networks (BNNs), have achieved remarkable successes in many tasks such as visual representation learning. However, whether there exists semantic correlations/connections between the visual representations in ANNs and those in BNNs remains largely unexplored due to both the lack of an effective tool to link and couple two different domains, and the lack of a general and effective framework of representing the visual semantics in BNNs such as human functional brain networks (FBNs). To answer this question, we propose a novel computational framework, Synchronized Activations (Sync-ACT), to couple the visual representation spaces and semantics between ANNs and BNNs in human brain based on naturalistic functional magnetic resonance imaging (nfMRI) data. With this approach, we are able to semantically annotate the neurons in ANNs with biologically meaningful description derived from human brain imaging for the first time. We evaluated the Sync-ACT framework on two publicly available movie-watching nfMRI datasets. The experiments demonstrate a) the significant correlation and similarity of the semantics between the visual representations in FBNs and those in a variety of convolutional neural networks (CNNs) models; b) the close relationship between CNN's visual representation similarity to BNNs and its performance in image classification tasks. Overall, our study introduces a general and effective paradigm to couple the ANNs and BNNs and provides novel insights for future studies such as brain-inspired artificial intelligence.
Sound Model Factory: An Integrated System Architecture for Generative Audio Modelling
Jun 27, 2022We introduce a new system for data-driven audio sound model design built around two different neural network architectures, a Generative Adversarial Network(GAN) and a Recurrent Neural Network (RNN), that takes advantage of the unique characteristics of each to achieve the system objectives that neither is capable of addressing alone. The objective of the system is to generate interactively controllable sound models given (a) a range of sounds the model should be able to synthesize, and (b) a specification of the parametric controls for navigating that space of sounds. The range of sounds is defined by a dataset provided by the designer, while the means of navigation is defined by a combination of data labels and the selection of a sub-manifold from the latent space learned by the GAN. Our proposed system takes advantage of the rich latent space of a GAN that consists of sounds that fill out the spaces ''between" real data-like sounds. This augmented data from the GAN is then used to train an RNN for its ability to respond immediately and continuously to parameter changes and to generate audio over unlimited periods of time. Furthermore, we develop a self-organizing map technique for ``smoothing" the latent space of GAN that results in perceptually smooth interpolation between audio timbres. We validate this process through user studies. The system contributes advances to the state of the art for generative sound model design that include system configuration and components for improving interpolation and the expansion of audio modeling capabilities beyond musical pitch and percussive instrument sounds into the more complex space of audio textures.
Real-time Pose and Shape Reconstruction of Two Interacting Hands With a Single Depth Camera
Jun 15, 2021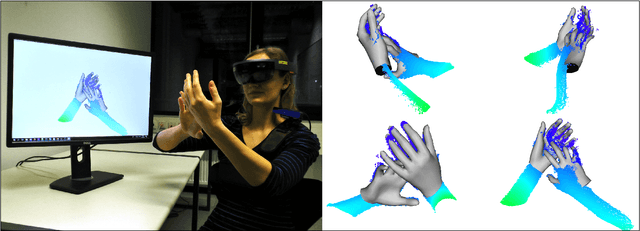

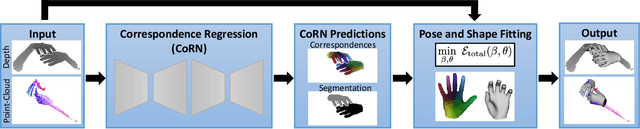

We present a novel method for real-time pose and shape reconstruction of two strongly interacting hands. Our approach is the first two-hand tracking solution that combines an extensive list of favorable properties, namely it is marker-less, uses a single consumer-level depth camera, runs in real time, handles inter- and intra-hand collisions, and automatically adjusts to the user's hand shape. In order to achieve this, we embed a recent parametric hand pose and shape model and a dense correspondence predictor based on a deep neural network into a suitable energy minimization framework. For training the correspondence prediction network, we synthesize a two-hand dataset based on physical simulations that includes both hand pose and shape annotations while at the same time avoiding inter-hand penetrations. To achieve real-time rates, we phrase the model fitting in terms of a nonlinear least-squares problem so that the energy can be optimized based on a highly efficient GPU-based Gauss-Newton optimizer. We show state-of-the-art results in scenes that exceed the complexity level demonstrated by previous work, including tight two-hand grasps, significant inter-hand occlusions, and gesture interaction.
Visual Acuity Prediction on Real-Life Patient Data Using a Machine Learning Based Multistage System
Apr 25, 2022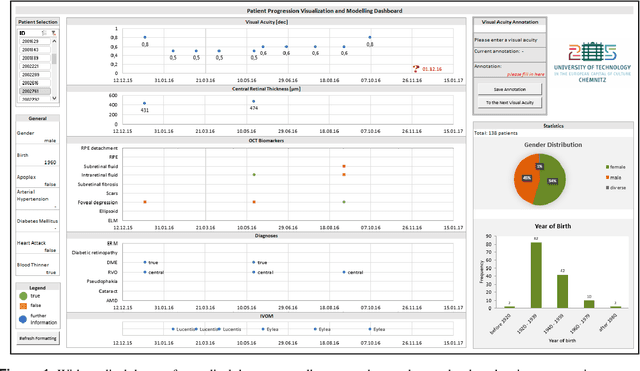

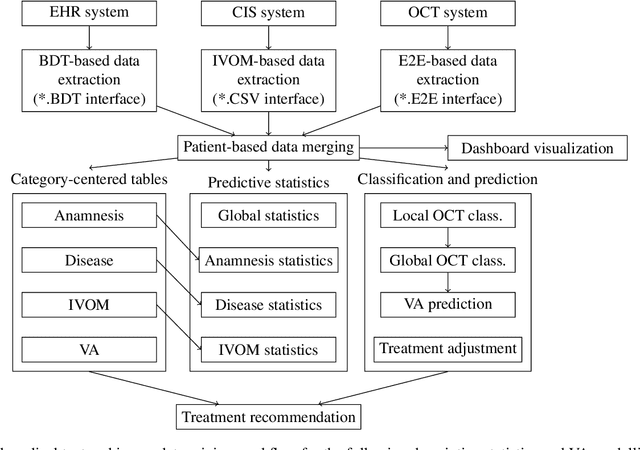
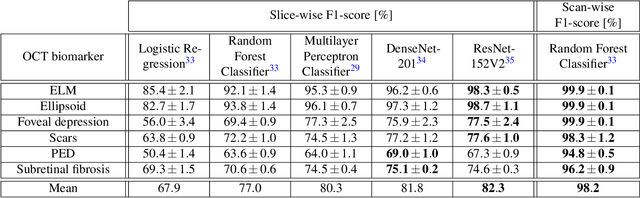
In ophthalmology, intravitreal operative medication therapy (IVOM) is widespread treatment for diseases such as the age-related macular degeneration (AMD), the diabetic macular edema (DME), as well as the retinal vein occlusion (RVO). However, in real-world settings, patients often suffer from loss of vision on time scales of years despite therapy, whereas the prediction of the visual acuity (VA) and the earliest possible detection of deterioration under real-life conditions is challenging due to heterogeneous and incomplete data. In this contribution, we present a workflow for the development of a research-compatible data corpus fusing different IT systems of the department of ophthalmology of a German maximum care hospital. The extensive data corpus allows predictive statements of the expected progression of a patient and his or her VA in each of the three diseases. Within our proposed multistage system, we classify the VA progression into the three groups of therapy "winners", "stabilizers", and "losers" (WSL scheme). Our OCT biomarker classification using an ensemble of deep neural networks results in a classification accuracy (F1-score) of over 98 %, enabling us to complete incomplete OCT documentations while allowing us to exploit them for a more precise VA modelling process. Our VA prediction requires at least four VA examinations and optionally OCT biomarkers from the same time period to predict the VA progression within a forecasted time frame. While achieving a prediction accuracy of up to 69 % (macro average F1-score) when considering all three WSL-based progression groups, this corresponds to an improvement by 11 % in comparison to our ophthalmic expertise (58 %).
Simplex Neural Population Learning: Any-Mixture Bayes-Optimality in Symmetric Zero-sum Games
May 31, 2022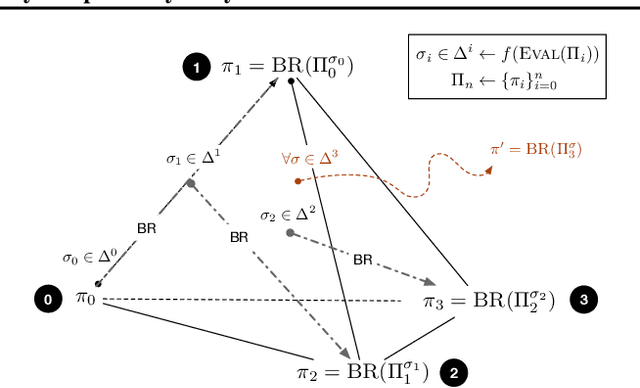
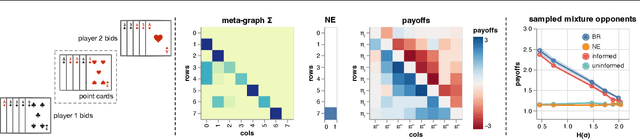
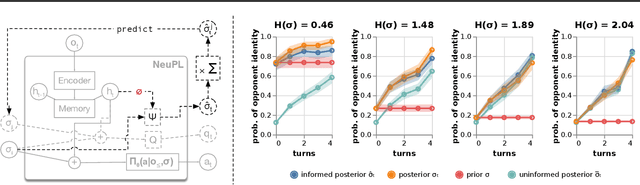
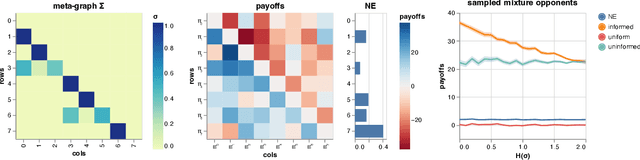
Learning to play optimally against any mixture over a diverse set of strategies is of important practical interests in competitive games. In this paper, we propose simplex-NeuPL that satisfies two desiderata simultaneously: i) learning a population of strategically diverse basis policies, represented by a single conditional network; ii) using the same network, learn best-responses to any mixture over the simplex of basis policies. We show that the resulting conditional policies incorporate prior information about their opponents effectively, enabling near optimal returns against arbitrary mixture policies in a game with tractable best-responses. We verify that such policies behave Bayes-optimally under uncertainty and offer insights in using this flexibility at test time. Finally, we offer evidence that learning best-responses to any mixture policies is an effective auxiliary task for strategic exploration, which, by itself, can lead to more performant populations.
Self-supervised Pretraining and Transfer Learning Enable Flu and COVID-19 Predictions in Small Mobile Sensing Datasets
May 26, 2022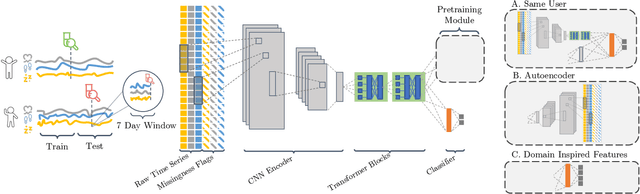
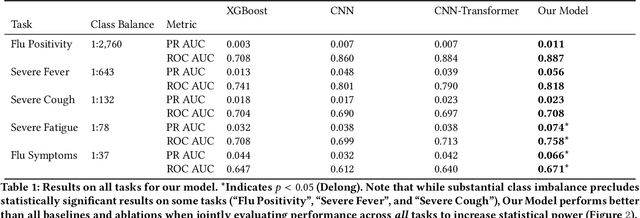
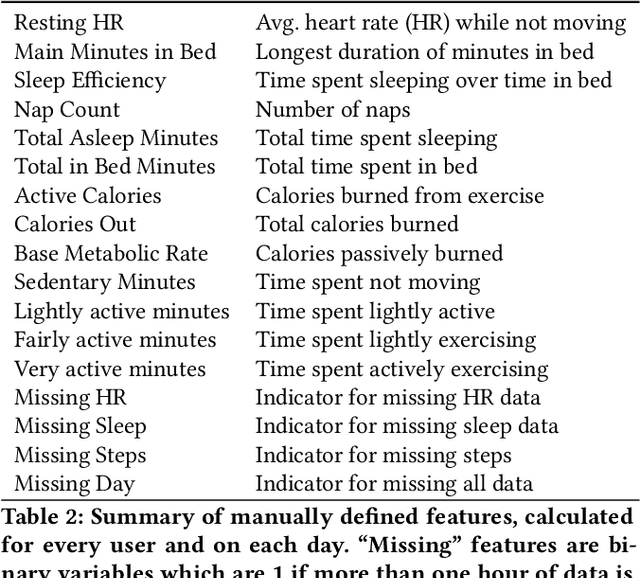
Detailed mobile sensing data from phones, watches, and fitness trackers offer an unparalleled opportunity to quantify and act upon previously unmeasurable behavioral changes in order to improve individual health and accelerate responses to emerging diseases. Unlike in natural language processing and computer vision, deep representation learning has yet to broadly impact this domain, in which the vast majority of research and clinical applications still rely on manually defined features and boosted tree models or even forgo predictive modeling altogether due to insufficient accuracy. This is due to unique challenges in the behavioral health domain, including very small datasets (~10^1 participants), which frequently contain missing data, consist of long time series with critical long-range dependencies (length>10^4), and extreme class imbalances (>10^3:1).
Disentangling the Computational Complexity of Network Untangling
Apr 06, 2022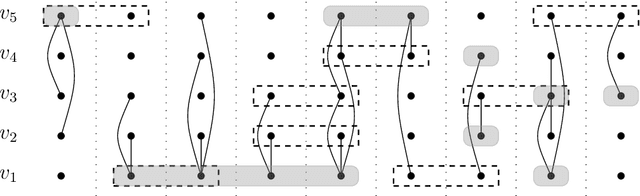
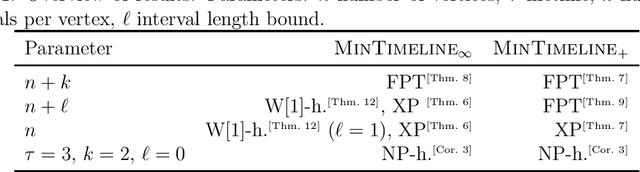
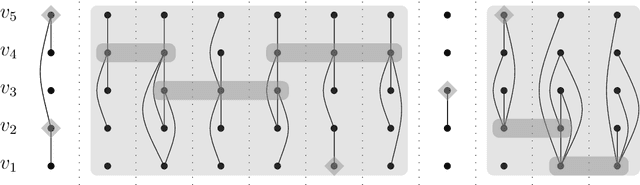
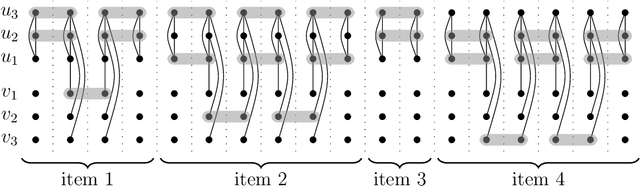
We study the network untangling problem introduced by Rozenshtein, Tatti, and Gionis [DMKD 2021], which is a variant of Vertex Cover on temporal graphs -- graphs whose edge set changes over discrete time steps. They introduce two problem variants. The goal is to select at most $k$ time intervals for each vertex such that all time-edges are covered and (depending on the problem variant) either the maximum interval length or the total sum of interval lengths is minimized. This problem has data mining applications in finding activity timelines that explain the interactions of entities in complex networks. Both variants of the problem are NP-hard. In this paper, we initiate a multivariate complexity analysis involving the following parameters: number of vertices, lifetime of the temporal graph, number of intervals per vertex, and the interval length bound. For both problem versions, we (almost) completely settle the parameterized complexity for all combinations of those four parameters, thereby delineating the border of fixed-parameter tractability.
Decoupled Dynamic Spatial-Temporal Graph Neural Network for Traffic Forecasting
Jun 22, 2022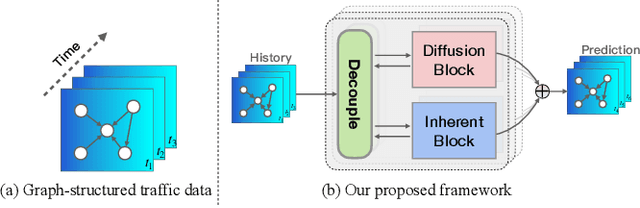

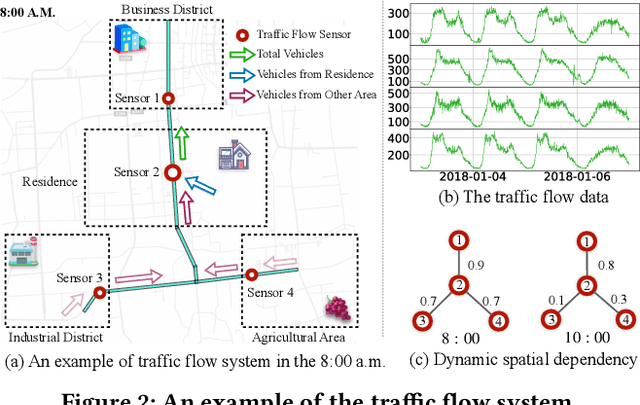
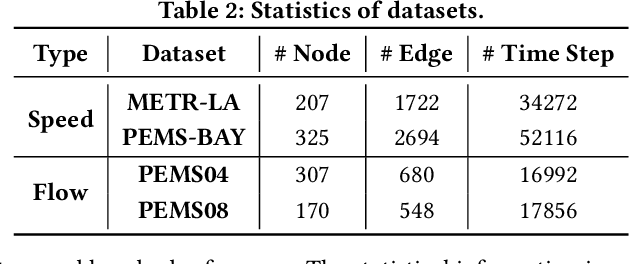
We all depend on mobility, and vehicular transportation affects the daily lives of most of us. Thus, the ability to forecast the state of traffic in a road network is an important functionality and a challenging task. Traffic data is often obtained from sensors deployed in a road network. Recent proposals on spatial-temporal graph neural networks have achieved great progress at modeling complex spatial-temporal correlations in traffic data, by modeling traffic data as a diffusion process. However, intuitively, traffic data encompasses two different kinds of hidden time series signals, namely the diffusion signals and inherent signals. Unfortunately, nearly all previous works coarsely consider traffic signals entirely as the outcome of the diffusion, while neglecting the inherent signals, which impacts model performance negatively. To improve modeling performance, we propose a novel Decoupled Spatial-Temporal Framework (DSTF) that separates the diffusion and inherent traffic information in a data-driven manner, which encompasses a unique estimation gate and a residual decomposition mechanism. The separated signals can be handled subsequently by the diffusion and inherent modules separately. Further, we propose an instantiation of DSTF, Decoupled Dynamic Spatial-Temporal Graph Neural Network (D2STGNN), that captures spatial-temporal correlations and also features a dynamic graph learning module that targets the learning of the dynamic characteristics of traffic networks. Extensive experiments with four real-world traffic datasets demonstrate that the framework is capable of advancing the state-of-the-art.