 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiSin: Efficient High-Resolution Sinogram Inpainting via Resolution-Guided Progressive Inference
Jun 10, 2025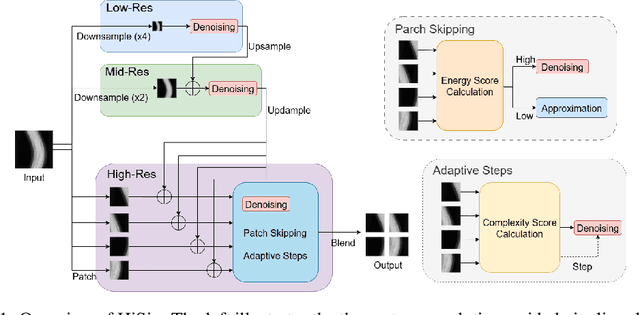
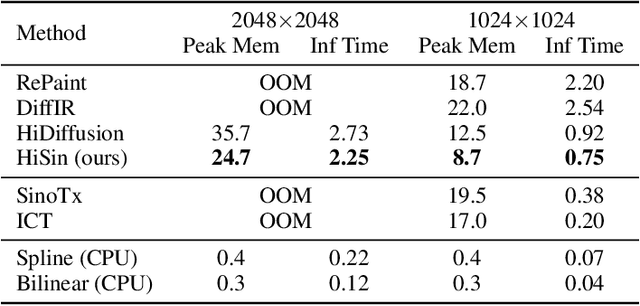
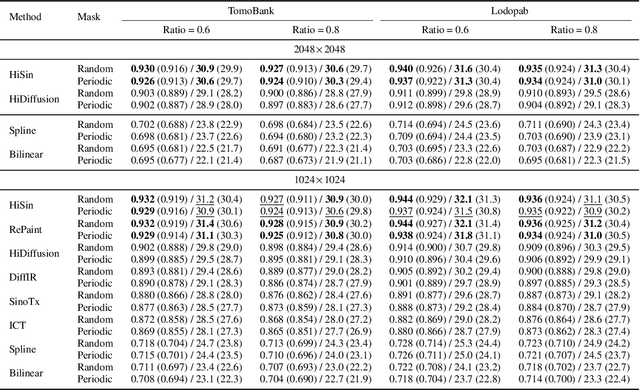
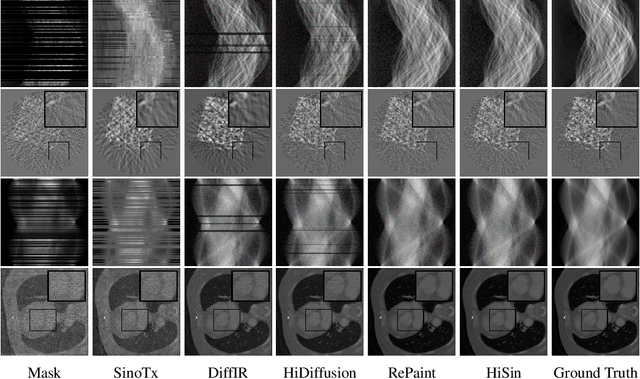
High-resolution sinogram inpainting is essential for computed tomography reconstruction, as missing high-frequency projections can lead to visible artifacts and diagnostic errors. Diffusion models are well-suited for this task due to their robustness and detail-preserving capabilities, but their application to high-resolution inputs is limited by excessive memory and computational demands. To address this limitation, we propose HiSin, a novel diffusion based framework for efficient sinogram inpainting via resolution-guided progressive inference. It progressively extracts global structure at low resolution and defers high-resolution inference to small patches, enabling memory-efficient inpainting. It further incorporates frequency-aware patch skipping and structure-adaptive step allocation to reduce redundant computation. Experimental results show that HiSin reduces peak memory usage by up to 31.25% and inference time by up to 18.15%, and maintains inpainting accuracy across datasets, resolutions, and mask conditions.
Multi-Task Time Series Forecasting With Shared Attention
Jan 24, 2021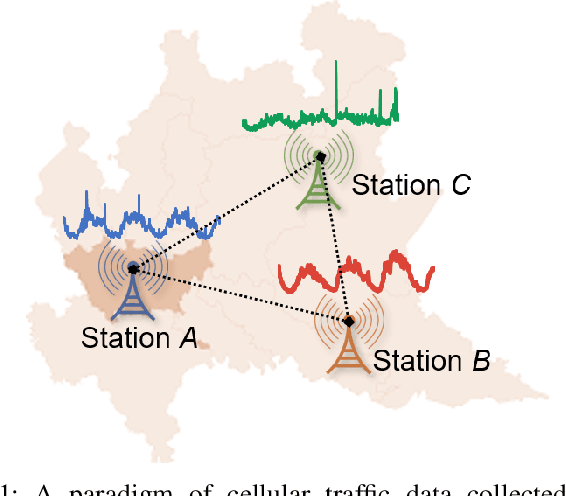
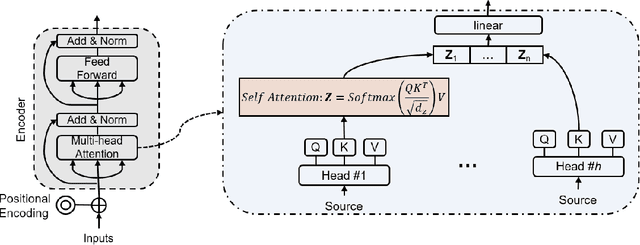
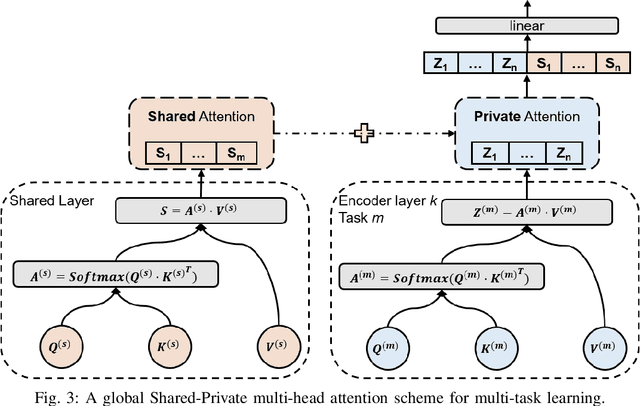
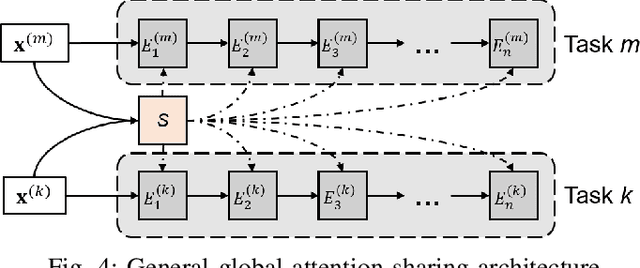
Time series forecasting is a key component in many industrial and business decision processes and recurrent neural network (RNN) based models have achieved impressive progress on various time series forecasting tasks. However, most of the existing methods focus on single-task forecasting problems by learning separately based on limited supervised objectives, which often suffer from insufficient training instances. As the Transformer architecture and other attention-based models have demonstrated its great capability of capturing long term dependency, we propose two self-attention based sharing schemes for multi-task time series forecasting which can train jointly across multiple tasks. We augment a sequence of paralleled Transformer encoders with an external public multi-head attention function, which is updated by all data of all tasks. Experiments on a number of real-world multi-task time series forecasting tasks show that our proposed architectures can not only outperform the state-of-the-art single-task forecasting baselines but also outperform the RNN-based multi-task forecasting method.