 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast-Vid2Vid: Spatial-Temporal Compression for Video-to-Video Synthesis
Jul 11, 2022
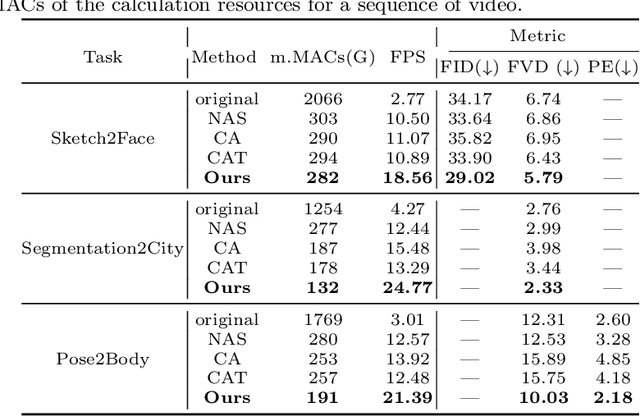
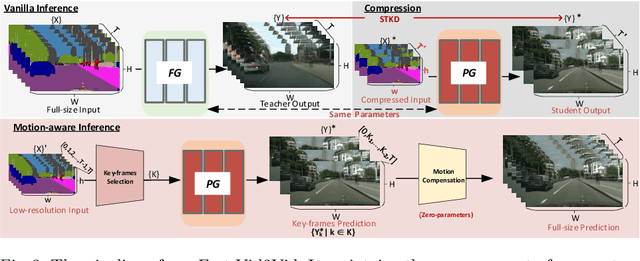
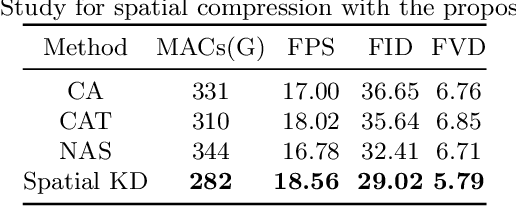
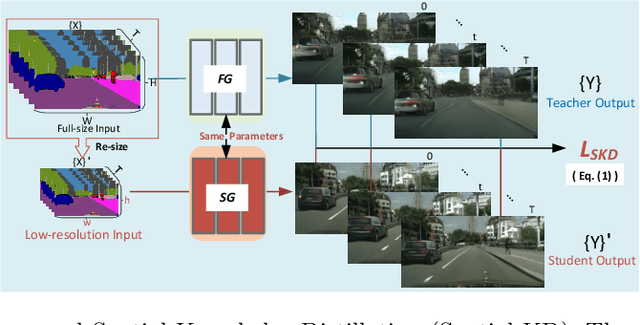
Video-to-Video synthesis (Vid2Vid) has achieved remarkable results in generating a photo-realistic video from a sequence of semantic maps. However, this pipeline suffers from high computational cost and long inference latency, which largely depends on two essential factors: 1) network architecture parameters, 2) sequential data stream. Recently, the parameters of image-based generative models have been significantly compressed via more efficient network architectures. Nevertheless, existing methods mainly focus on slimming network architectures and ignore the size of the sequential data stream. Moreover, due to the lack of temporal coherence, image-based compression is not sufficient for the compression of the video task. In this paper, we present a spatial-temporal compression framework, \textbf{Fast-Vid2Vid}, which focuses on data aspects of generative models. It makes the first attempt at time dimension to reduce computational resources and accelerate inference. Specifically, we compress the input data stream spatially and reduce the temporal redundancy. After the proposed spatial-temporal knowledge distillation, our model can synthesize key-frames using the low-resolution data stream. Finally, Fast-Vid2Vid interpolates intermediate frames by motion compensation with slight latency. On standard benchmarks, Fast-Vid2Vid achieves around real-time performance as 20 FPS and saves around 8x computational cost on a single V100 GPU.
Fast optical refocusing through multimode fiber bend using Cake-Cutting Hadamard encoding algorithm to improve robustness
Jul 27, 2022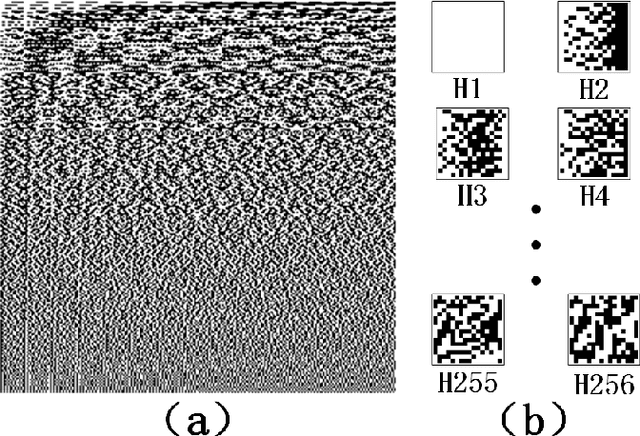

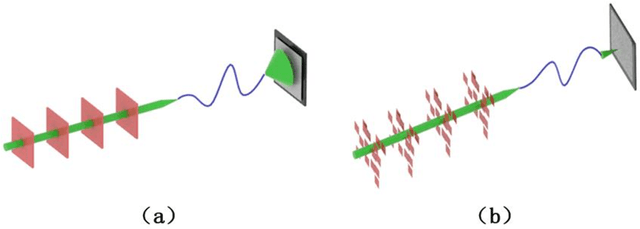
Multimode fibres offer the advantages of high resolution and miniaturization over single mode fibers in the field of optical imaging. However, multimode fibre's imaging is susceptible to perturbations of MMF that can lead to secondary spatial distortions in the transmitted image. Perturbations include random disturbances in the fiber as well as environmental noise. Here, we exploit the fast focusing capability of the Cake-Cutting Hadamard coding algorithm to counteract the effects of perturbations and improve the system's robustness. Simulation shows that it can approach the theoretical enhancement at 2000 measurements. Experimental results show that the algorithm can help the system to refocus in a short time when MMFs are perturbed. This research will further contribute to using multimode fibres in medicine, communication, and detection.
Scaling up Continuous-Time Markov Chains Helps Resolve Underspecification
Jul 06, 2021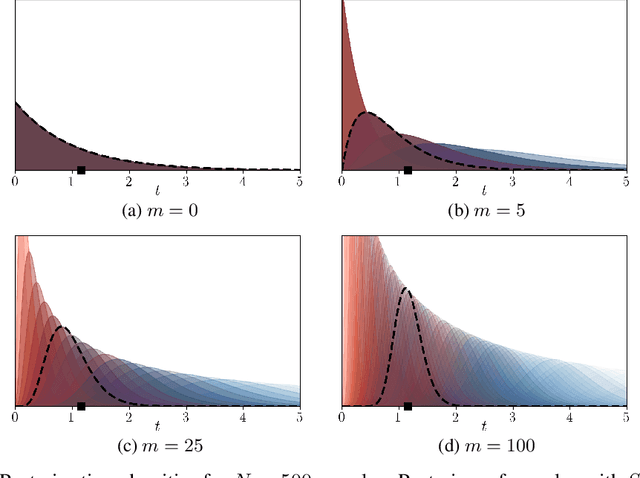
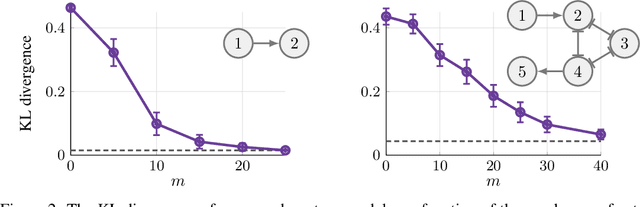
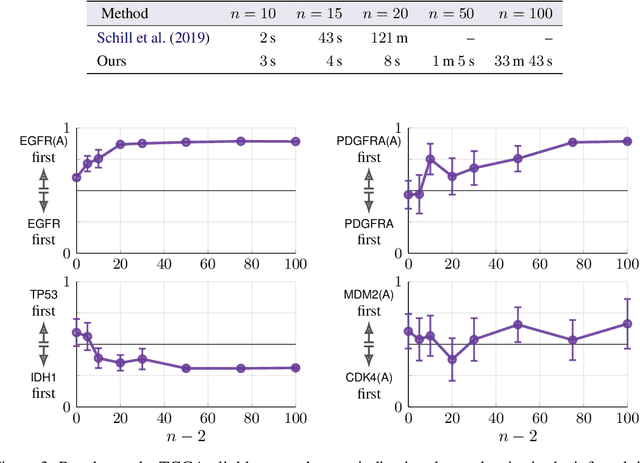
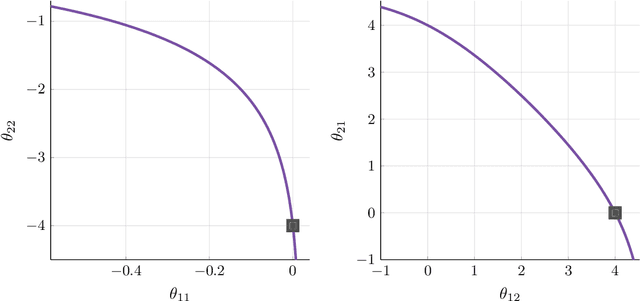
Modeling the time evolution of discrete sets of items (e.g., genetic mutations) is a fundamental problem in many biomedical applications. We approach this problem through the lens of continuous-time Markov chains, and show that the resulting learning task is generally underspecified in the usual setting of cross-sectional data. We explore a perhaps surprising remedy: including a number of additional independent items can help determine time order, and hence resolve underspecification. This is in sharp contrast to the common practice of limiting the analysis to a small subset of relevant items, which is followed largely due to poor scaling of existing methods. To put our theoretical insight into practice, we develop an approximate likelihood maximization method for learning continuous-time Markov chains, which can scale to hundreds of items and is orders of magnitude faster than previous methods. We demonstrate the effectiveness of our approach on synthetic and real cancer data.
GeoECG: Data Augmentation via Wasserstein Geodesic Perturbation for Robust Electrocardiogram Prediction
Aug 10, 2022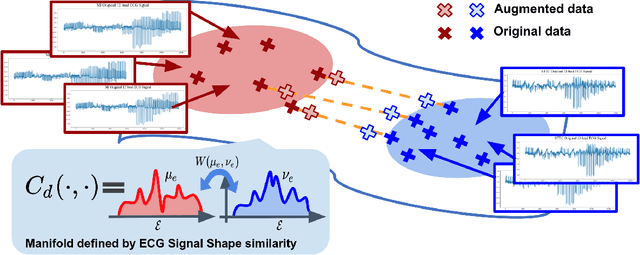


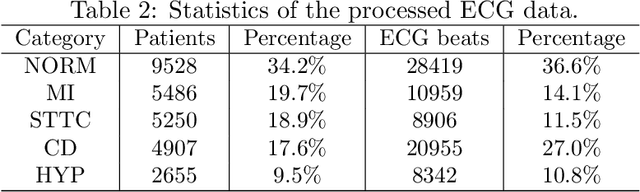
There has been an increased interest in applying deep neural networks to automatically interpret and analyze the 12-lead electrocardiogram (ECG). The current paradigms with machine learning methods are often limited by the amount of labeled data. This phenomenon is particularly problematic for clinically-relevant data, where labeling at scale can be time-consuming and costly in terms of the specialized expertise and human effort required. Moreover, deep learning classifiers may be vulnerable to adversarial examples and perturbations, which could have catastrophic consequences, for example, when applied in the context of medical treatment, clinical trials, or insurance claims. In this paper, we propose a physiologically-inspired data augmentation method to improve performance and increase the robustness of heart disease detection based on ECG signals. We obtain augmented samples by perturbing the data distribution towards other classes along the geodesic in Wasserstein space. To better utilize domain-specific knowledge, we design a ground metric that recognizes the difference between ECG signals based on physiologically determined features. Learning from 12-lead ECG signals, our model is able to distinguish five categories of cardiac conditions. Our results demonstrate improvements in accuracy and robustness, reflecting the effectiveness of our data augmentation method.
* 26 pages, Figure 13, Machine Learning for Healthcare 2022
Algorithms for audio inpainting based on probabilistic nonnegative matrix factorization
Jun 28, 2022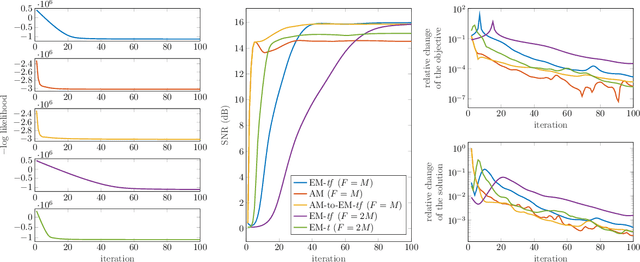
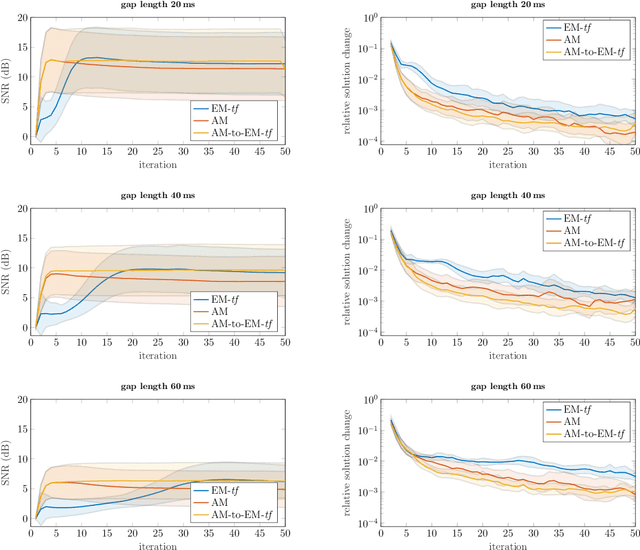
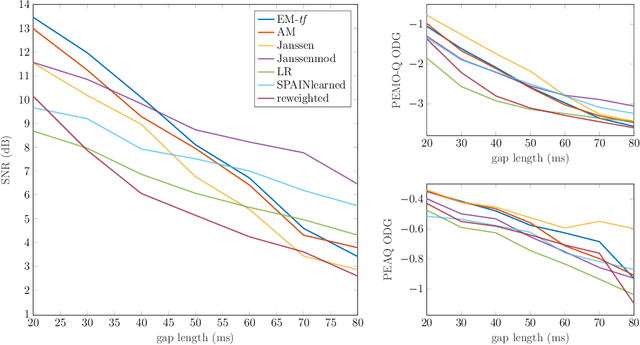
Audio inpainting, i.e., the task of restoring missing or occluded audio signal samples, usually relies on sparse representations or autoregressive modeling. In this paper, we propose to structure the spectrogram with nonnegative matrix factorization (NMF) in a probabilistic framework. First, we treat the missing samples as latent variables, and derive two expectation-maximization algorithms for estimating the parameters of the model, depending on whether we formulate the problem in the time- or time-frequency domain. Then, we treat the missing samples as parameters, and we address this novel problem by deriving an alternating minimization scheme. We assess the potential of these algorithms for the task of restoring short- to middle-length gaps in music signals. Experiments reveal great convergence properties of the proposed methods, as well as competitive performance when compared to state-of-the-art audio inpainting techniques.
TASKOGRAPHY: Evaluating robot task planning over large 3D scene graphs
Jul 11, 2022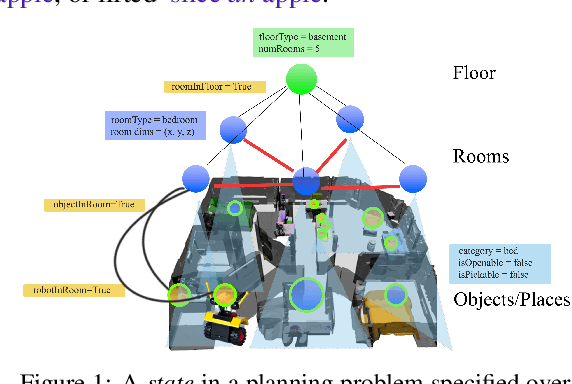
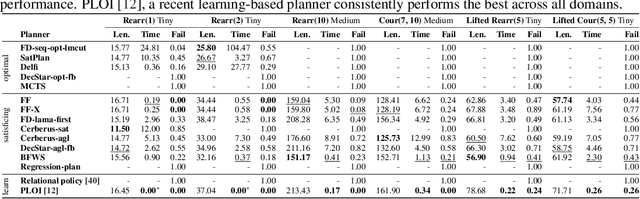
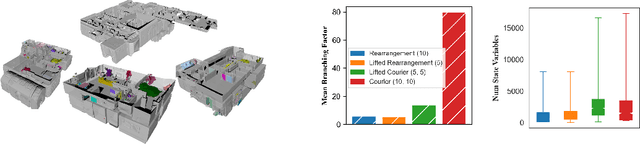
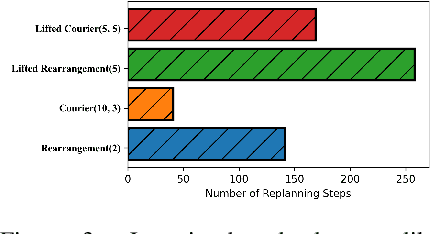
3D scene graphs (3DSGs) are an emerging description; unifying symbolic, topological, and metric scene representations. However, typical 3DSGs contain hundreds of objects and symbols even for small environments; rendering task planning on the full graph impractical. We construct TASKOGRAPHY, the first large-scale robotic task planning benchmark over 3DSGs. While most benchmarking efforts in this area focus on vision-based planning, we systematically study symbolic planning, to decouple planning performance from visual representation learning. We observe that, among existing methods, neither classical nor learning-based planners are capable of real-time planning over full 3DSGs. Enabling real-time planning demands progress on both (a) sparsifying 3DSGs for tractable planning and (b) designing planners that better exploit 3DSG hierarchies. Towards the former goal, we propose SCRUB, a task-conditioned 3DSG sparsification method; enabling classical planners to match and in some cases surpass state-of-the-art learning-based planners. Towards the latter goal, we propose SEEK, a procedure enabling learning-based planners to exploit 3DSG structure, reducing the number of replanning queries required by current best approaches by an order of magnitude. We will open-source all code and baselines to spur further research along the intersections of robot task planning, learning and 3DSGs.
* Video: https://www.youtube.com/watch?v=mM4v5hP4LdA&ab_channel=KrishnaMurthy . Project page: https://taskography.github.io/ . 18 pages, 7 figures. In proceedings of Conference on Robot Learning (CoRL) 2021. The first two authors contributed equally
Transferable Multi-Agent Reinforcement Learning with Dynamic Participating Agents
Aug 04, 2022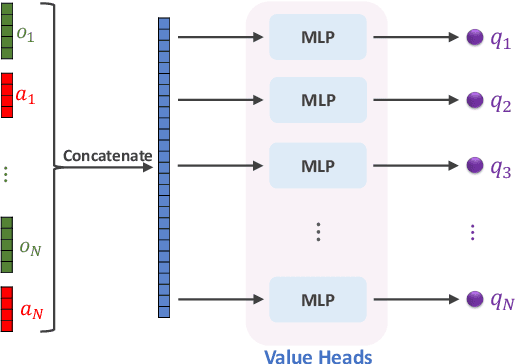
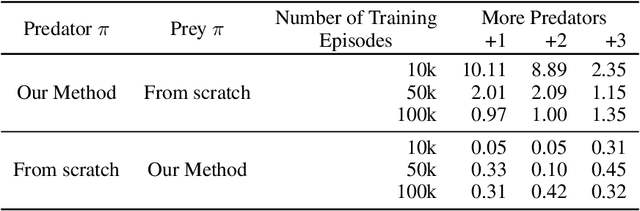
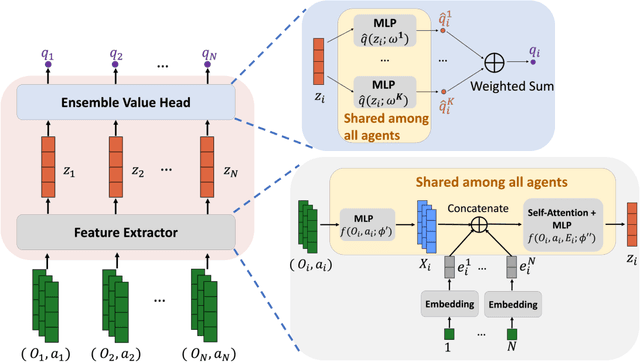
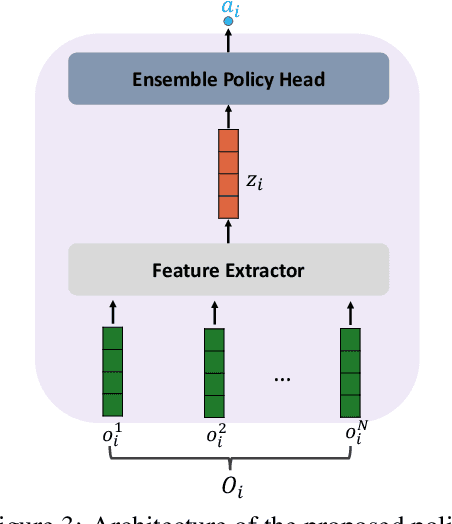
We study multi-agent reinforcement learning (MARL) with centralized training and decentralized execution. During the training, new agents may join, and existing agents may unexpectedly leave the training. In such situations, a standard deep MARL model must be trained again from scratch, which is very time-consuming. To tackle this problem, we propose a special network architecture with a few-shot learning algorithm that allows the number of agents to vary during centralized training. In particular, when a new agent joins the centralized training, our few-shot learning algorithm trains its policy network and value network using a small number of samples; when an agent leaves the training, the training process of the remaining agents is not affected. Our experiments show that using the proposed network architecture and algorithm, model adaptation when new agents join can be 100+ times faster than the baseline. Our work is applicable to any setting, including cooperative, competitive, and mixed.
EvolveHypergraph: Group-Aware Dynamic Relational Reasoning for Trajectory Prediction
Aug 10, 2022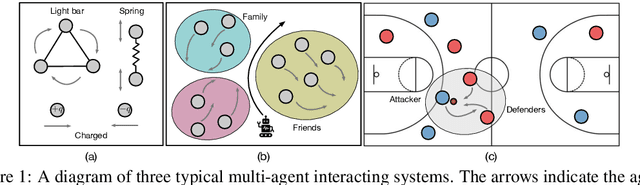
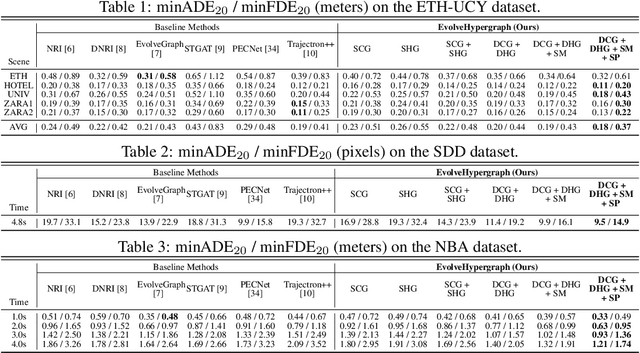
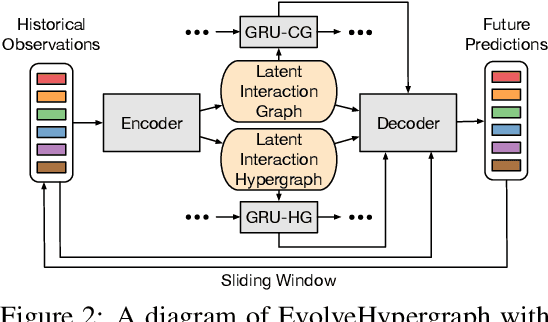
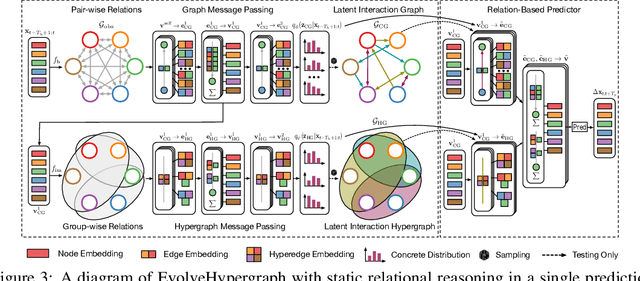
While the modeling of pair-wise relations has been widely studied in multi-agent interacting systems, its ability to capture higher-level and larger-scale group-wise activities is limited. In this paper, we propose a group-aware relational reasoning approach (named EvolveHypergraph) with explicit inference of the underlying dynamically evolving relational structures, and we demonstrate its effectiveness for multi-agent trajectory prediction. In addition to the edges between a pair of nodes (i.e., agents), we propose to infer hyperedges that adaptively connect multiple nodes to enable group-aware relational reasoning in an unsupervised manner without fixing the number of hyperedges. The proposed approach infers the dynamically evolving relation graphs and hypergraphs over time to capture the evolution of relations, which are used by the trajectory predictor to obtain future states. Moreover, we propose to regularize the smoothness of the relation evolution and the sparsity of the inferred graphs or hypergraphs, which effectively improves training stability and enhances the explainability of inferred relations. The proposed approach is validated on both synthetic crowd simulations and multiple real-world benchmark datasets. Our approach infers explainable, reasonable group-aware relations and achieves state-of-the-art performance in long-term prediction.
On Synchronization of Wireless Acoustic Sensor Networks in the Presence of Time-varying Sampling Rate Offsets and Speaker Changes
Oct 25, 2021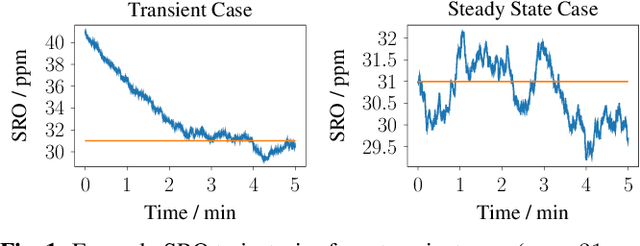
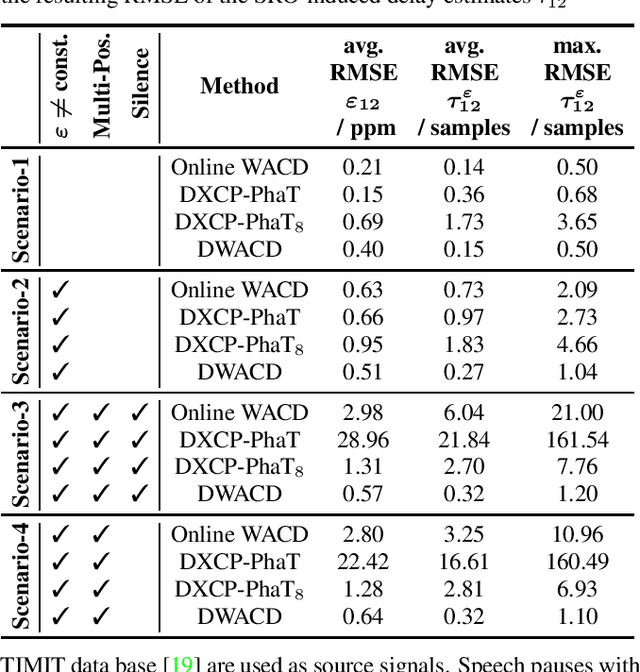
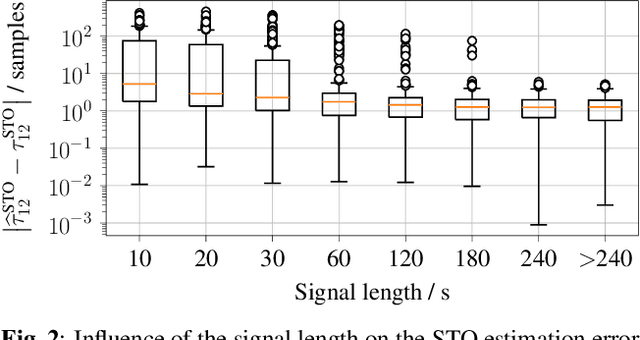
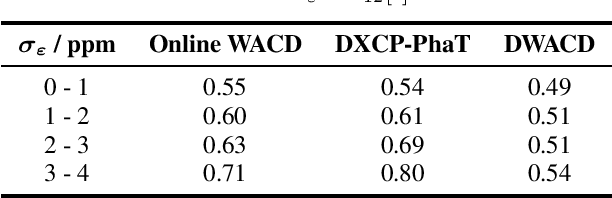
A wireless acoustic sensor network records audio signals with sampling time and sampling rate offsets between the audio streams, if the analog-digital converters (ADCs) of the network devices are not synchronized. Here, we introduce a new sampling rate offset model to simulate time-varying sampling frequencies caused, for example, by temperature changes of ADC crystal oscillators, and propose an estimation algorithm to handle this dynamic aspect in combination with changing acoustic source positions. Furthermore, we show how deep neural network based estimates of the distances between microphones and human speakers can be used to determine the sampling time offsets. This enables a synchronization of the audio streams to reflect the physical time differences of flight.
Deep Semi-Supervised and Self-Supervised Learning for Diabetic Retinopathy Detection
Aug 04, 2022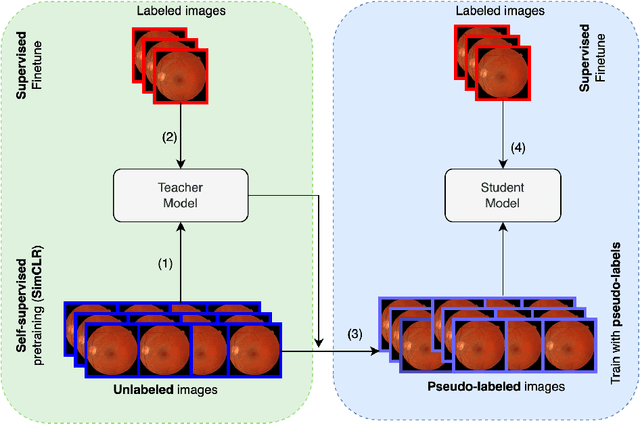
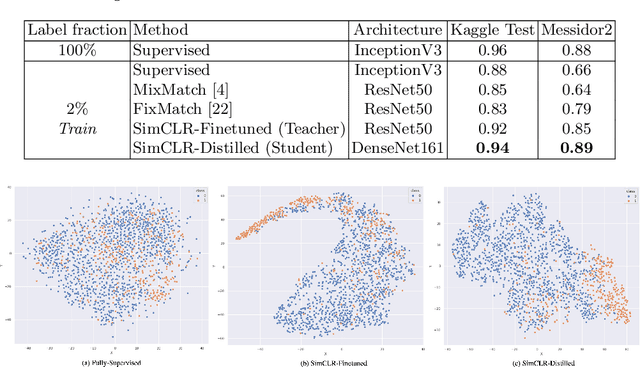
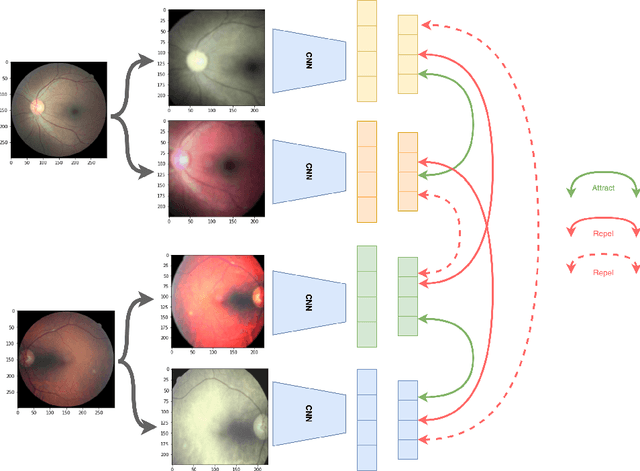

Diabetic retinopathy (DR) is one of the leading causes of blindness in the working-age population of developed countries, caused by a side effect of diabetes that reduces the blood supply to the retina. Deep neural networks have been widely used in automated systems for DR classification on eye fundus images. However, these models need a large number of annotated images. In the medical domain, annotations from experts are costly, tedious, and time-consuming; as a result, a limited number of annotated images are available. This paper presents a semi-supervised method that leverages unlabeled images and labeled ones to train a model that detects diabetic retinopathy. The proposed method uses unsupervised pretraining via self-supervised learning followed by supervised fine-tuning with a small set of labeled images and knowledge distillation to increase the performance in classification task. This method was evaluated on the EyePACS test and Messidor-2 dataset achieving 0.94 and 0.89 AUC respectively using only 2% of EyePACS train labeled images.