 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Trend Prediction via Continually-Aligned LLM Query Generation
Jan 24, 2026Trending news detection in low-traffic search environments faces a fundamental cold-start problem, where a lack of query volume prevents systems from identifying emerging or long-tail trends. Existing methods relying on keyword frequency or query spikes are inherently slow and ineffective in these sparse settings, lagging behind real-world shifts in attention. We introduce RTTP, a novel Real-Time Trending Prediction framework that generates search queries directly from news content instead of waiting for users to issue them. RTTP leverages a continual learning LLM (CL-LLM) that converts posts into search-style queries and scores them using engagement strength + creator authority, enabling early trend surfacing before search volume forms. To ensure adaptation without degrading reasoning, we propose Mix-Policy DPO, a new preference-based continual learning approach that combines on-policy stability with off-policy novelty to mitigate catastrophic forgetting during model upgrades. Deployed at production scale on Facebook and Meta AI products, RTTP delivers +91.4% improvement in tail-trend detection precision@500 and +19% query generation accuracy over industry baselines, while sustaining stable performance after multi-week online training. This work demonstrates that LLM-generated synthetic search signals, when aligned and continually updated, unlock timely trend understanding in low-traffic search environments.
DetectBench: Can Large Language Model Detect and Piece Together Implicit Evidence?
Jun 18, 2024



Detecting evidence within the context is a key step in the process of reasoning task. Evaluating and enhancing the capabilities of LLMs in evidence detection will strengthen context-based reasoning performance. This paper proposes a benchmark called DetectBench for verifying the ability to detect and piece together implicit evidence within a long context. DetectBench contains 3,928 multiple-choice questions, with an average of 994 tokens per question. Each question contains an average of 4.55 pieces of implicit evidence, and solving the problem typically requires 7.62 logical jumps to find the correct answer. To enhance the performance of LLMs in evidence detection, this paper proposes Detective Reasoning Prompt and Finetune. Experiments demonstrate that the existing LLMs' abilities to detect evidence in long contexts are far inferior to humans. However, the Detective Reasoning Prompt effectively enhances the capability of powerful LLMs in evidence detection, while the Finetuning method shows significant effects in enhancing the performance of weaker LLMs. Moreover, when the abilities of LLMs in evidence detection are improved, their final reasoning performance is also enhanced accordingly.
Methodologies for Improving Modern Industrial Recommender Systems
Jul 21, 2023Recommender system (RS) is an established technology with successful applications in social media, e-commerce, entertainment, and more. RSs are indeed key to the success of many popular APPs, such as YouTube, Tik Tok, Xiaohongshu, Bilibili, and others. This paper explores the methodology for improving modern industrial RSs. It is written for experienced RS engineers who are diligently working to improve their key performance indicators, such as retention and duration. The experiences shared in this paper have been tested in some real industrial RSs and are likely to be generalized to other RSs as well. Most contents in this paper are industry experience without publicly available references.
Beyond the Obvious: Evaluating the Reasoning Ability In Real-life Scenarios of Language Models on Life Scapes Reasoning Benchmark~(LSR-Benchmark)
Jul 11, 2023



This paper introduces the Life Scapes Reasoning Benchmark (LSR-Benchmark), a novel dataset targeting real-life scenario reasoning, aiming to close the gap in artificial neural networks' ability to reason in everyday contexts. In contrast to domain knowledge reasoning datasets, LSR-Benchmark comprises free-text formatted questions with rich information on real-life scenarios, human behaviors, and character roles. The dataset consists of 2,162 questions collected from open-source online sources and is manually annotated to improve its quality. Experiments are conducted using state-of-the-art language models, such as gpt3.5-turbo and instruction fine-tuned llama models, to test the performance in LSR-Benchmark. The results reveal that humans outperform these models significantly, indicating a persisting challenge for machine learning models in comprehending daily human life.
Xiezhi: An Ever-Updating Benchmark for Holistic Domain Knowledge Evaluation
Jun 15, 2023



New Natural Langauge Process~(NLP) benchmarks are urgently needed to align with the rapid development of large language models (LLMs). We present Xiezhi, the most comprehensive evaluation suite designed to assess holistic domain knowledge. Xiezhi comprises multiple-choice questions across 516 diverse disciplines ranging from 13 different subjects with 249,587 questions and accompanied by Xiezhi-Specialty and Xiezhi-Interdiscipline, both with 15k questions. We conduct evaluation of the 47 cutting-edge LLMs on Xiezhi. Results indicate that LLMs exceed average performance of humans in science, engineering, agronomy, medicine, and art, but fall short in economics, jurisprudence, pedagogy, literature, history, and management. We anticipate Xiezhi will help analyze important strengths and shortcomings of LLMs, and the benchmark is released in~\url{https://github.com/MikeGu721/XiezhiBenchmark}.
RefGPT: Reference -> Truthful & Customized Dialogues Generation by GPTs and for GPTs
May 25, 2023General chat models, like ChatGPT, have attained impressive capability to resolve a wide range of NLP tasks by tuning Large Language Models (LLMs) with high-quality instruction data. However, collecting human-written high-quality data, especially multi-turn dialogues, is expensive and unattainable for most people. Though previous studies have used powerful LLMs to generate the dialogues automatically, but they all suffer from generating untruthful dialogues because of the LLMs hallucination. Therefore, we propose a method called RefGPT to generate enormous truthful and customized dialogues without worrying about factual errors caused by the model hallucination. RefGPT solves the model hallucination in dialogue generation by restricting the LLMs to leverage the given reference instead of reciting their own knowledge to generate dialogues. Additionally, RefGPT adds detailed controls on every utterances to enable highly customization capability, which previous studies have ignored. On the basis of RefGPT, we also propose two high-quality dialogue datasets generated by GPT-4, namely RefGPT-Fact and RefGPT-Code. RefGPT-Fact is 100k multi-turn dialogue datasets based on factual knowledge and RefGPT-Code is 76k multi-turn dialogue dataset covering a wide range of coding scenarios. Our code and datasets are released in https://github.com/ziliwangnlp/RefGPT
An End-to-End Framework for Marketing Effectiveness Optimization under Budget Constraint
Feb 09, 2023



Online platforms often incentivize consumers to improve user engagement and platform revenue. Since different consumers might respond differently to incentives, individual-level budget allocation is an essential task in marketing campaigns. Recent advances in this field often address the budget allocation problem using a two-stage paradigm: the first stage estimates the individual-level treatment effects using causal inference algorithms, and the second stage invokes integer programming techniques to find the optimal budget allocation solution. Since the objectives of these two stages might not be perfectly aligned, such a two-stage paradigm could hurt the overall marketing effectiveness. In this paper, we propose a novel end-to-end framework to directly optimize the business goal under budget constraints. Our core idea is to construct a regularizer to represent the marketing goal and optimize it efficiently using gradient estimation techniques. As such, the obtained models can learn to maximize the marketing goal directly and precisely. We extensively evaluate our proposed method in both offline and online experiments, and experimental results demonstrate that our method outperforms current state-of-the-art methods. Our proposed method is currently deployed to allocate marketing budgets for hundreds of millions of users on a short video platform and achieves significant business goal improvements. Our code will be publicly available.
Transferable Multi-Agent Reinforcement Learning with Dynamic Participating Agents
Aug 04, 2022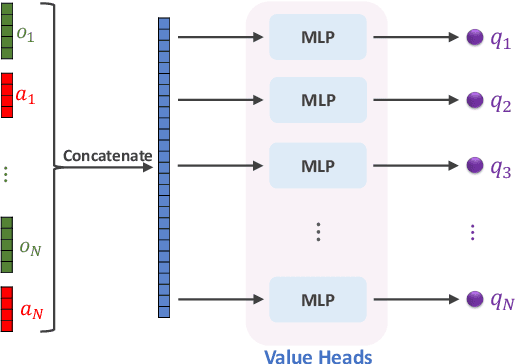
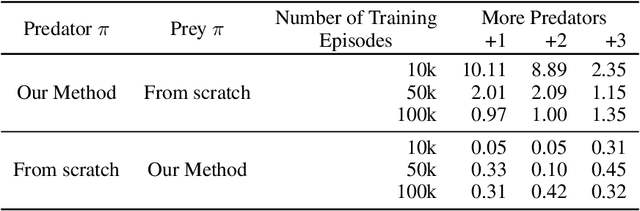
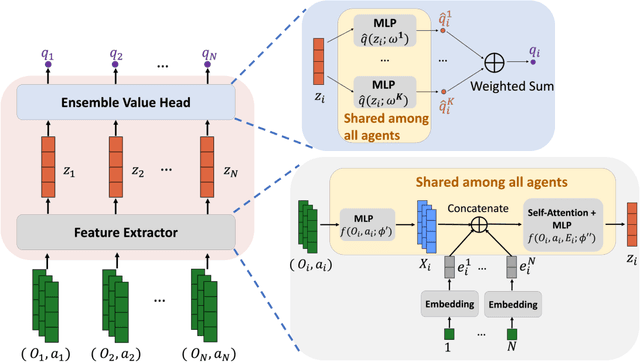
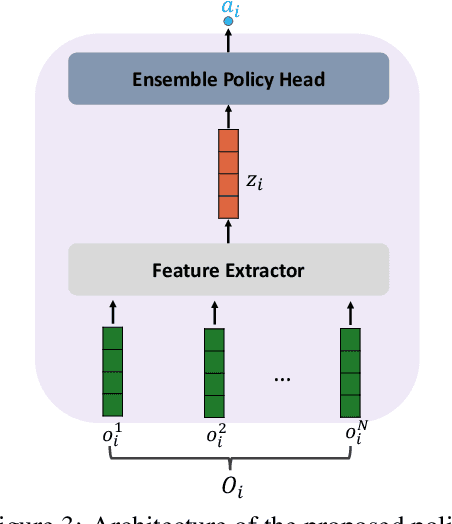
We study multi-agent reinforcement learning (MARL) with centralized training and decentralized execution. During the training, new agents may join, and existing agents may unexpectedly leave the training. In such situations, a standard deep MARL model must be trained again from scratch, which is very time-consuming. To tackle this problem, we propose a special network architecture with a few-shot learning algorithm that allows the number of agents to vary during centralized training. In particular, when a new agent joins the centralized training, our few-shot learning algorithm trains its policy network and value network using a small number of samples; when an agent leaves the training, the training process of the remaining agents is not affected. Our experiments show that using the proposed network architecture and algorithm, model adaptation when new agents join can be 100+ times faster than the baseline. Our work is applicable to any setting, including cooperative, competitive, and mixed.
Federated Reinforcement Learning with Environment Heterogeneity
Apr 06, 2022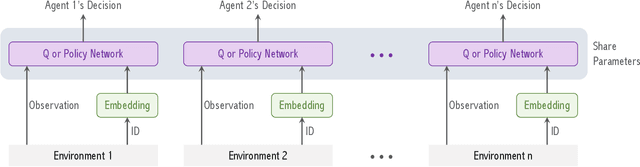
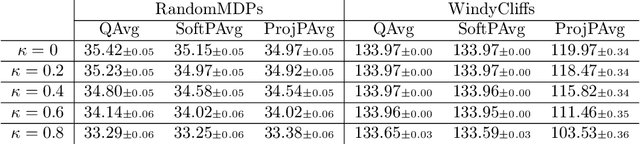

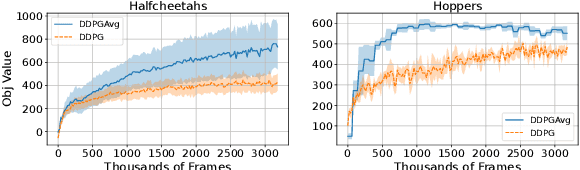
We study a Federated Reinforcement Learning (FedRL) problem in which $n$ agents collaboratively learn a single policy without sharing the trajectories they collected during agent-environment interaction. We stress the constraint of environment heterogeneity, which means $n$ environments corresponding to these $n$ agents have different state transitions. To obtain a value function or a policy function which optimizes the overall performance in all environments, we propose two federated RL algorithms, \texttt{QAvg} and \texttt{PAvg}. We theoretically prove that these algorithms converge to suboptimal solutions, while such suboptimality depends on how heterogeneous these $n$ environments are. Moreover, we propose a heuristic that achieves personalization by embedding the $n$ environments into $n$ vectors. The personalization heuristic not only improves the training but also allows for better generalization to new environments.
Privacy-Preserving Distributed SVD via Federated Power
Mar 01, 2021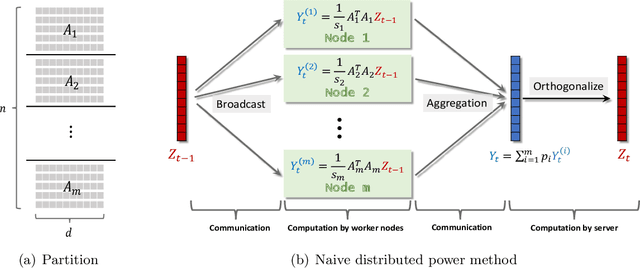
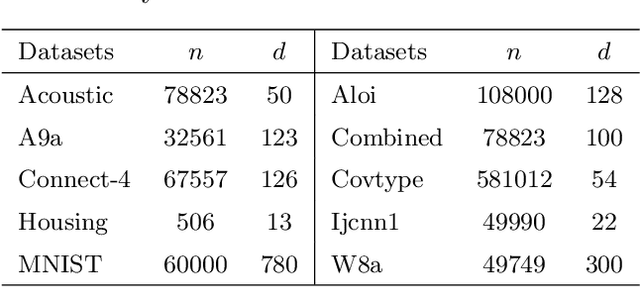
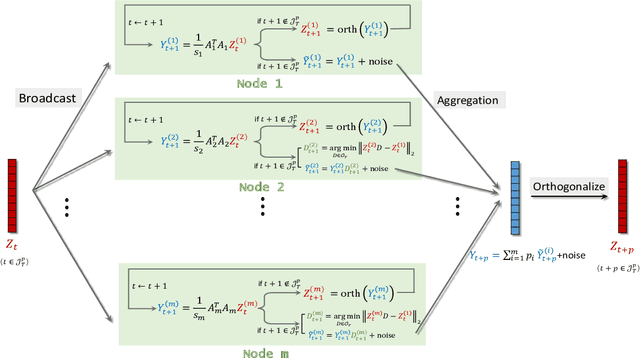
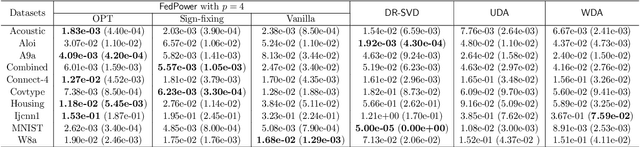
Singular value decomposition (SVD) is one of the most fundamental tools in machine learning and statistics.The modern machine learning community usually assumes that data come from and belong to small-scale device users. The low communication and computation power of such devices, and the possible privacy breaches of users' sensitive data make the computation of SVD challenging. Federated learning (FL) is a paradigm enabling a large number of devices to jointly learn a model in a communication-efficient way without data sharing. In the FL framework, we develop a class of algorithms called FedPower for the computation of partial SVD in the modern setting. Based on the well-known power method, the local devices alternate between multiple local power iterations and one global aggregation to improve communication efficiency. In the aggregation, we propose to weight each local eigenvector matrix with Orthogonal Procrustes Transformation (OPT). Considering the practical stragglers' effect, the aggregation can be fully participated or partially participated, where for the latter we propose two sampling and aggregation schemes. Further, to ensure strong privacy protection, we add Gaussian noise whenever the communication happens by adopting the notion of differential privacy (DP). We theoretically show the convergence bound for FedPower. The resulting bound is interpretable with each part corresponding to the effect of Gaussian noise, parallelization, and random sampling of devices, respectively. We also conduct experiments to demonstrate the merits of FedPower. In particular, the local iterations not only improve communication efficiency but also reduce the chance of privacy breaches.