 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
D-ITAGS: A Dynamic Interleaved Approach to Resilient Task Allocation, Scheduling, and Motion Planning
Sep 27, 2022
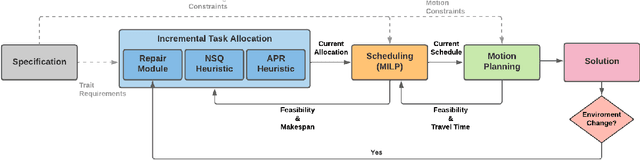
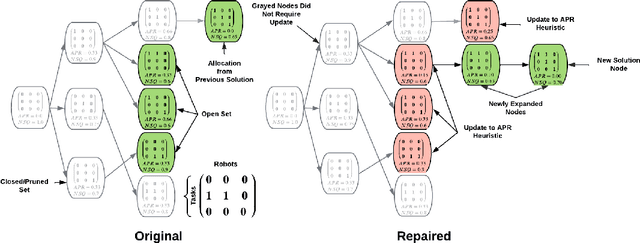

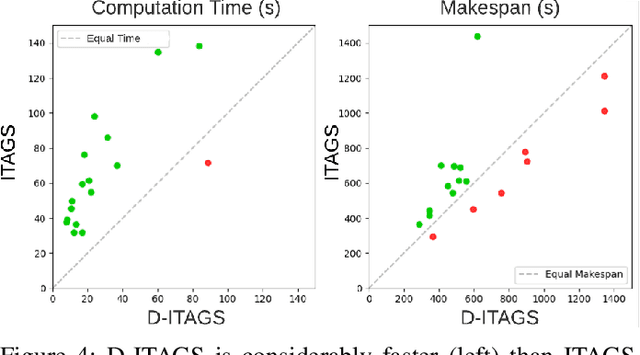
Complex, multi-objective missions require the coordination of heterogeneous robots at multiple inter-connected levels, such as coalition formation, scheduling, and motion planning. This challenge is exacerbated by dynamic changes, such as sensor and actuator failures, communication loss, and unexpected delays. We introduce Dynamic Iterative Task Allocation Graph Search (D-ITAGS) to \textit{simultaneously} address coalition formation, scheduling, and motion planning in dynamic settings involving heterogeneous teams. D-ITAGS achieves resilience via two key characteristics: i) interleaved execution, and ii) targeted repair. \textit{Interleaved execution} enables an effective search for solutions at each layer while avoiding incompatibility with other layers. \textit{Targeted repair} identifies and repairs parts of the existing solution impacted by a given disruption, while conserving the rest. In addition to algorithmic contributions, we provide theoretical insights into the inherent trade-off between time and resource optimality in these settings and derive meaningful bounds on schedule suboptimality. Our experiments reveal that i) D-ITAGS is significantly faster than recomputation from scratch in dynamic settings, with little to no loss in solution quality, and ii) the theoretical suboptimality bounds consistently hold in practice.
EEG-based Image Feature Extraction for Visual Classification using Deep Learning
Sep 27, 2022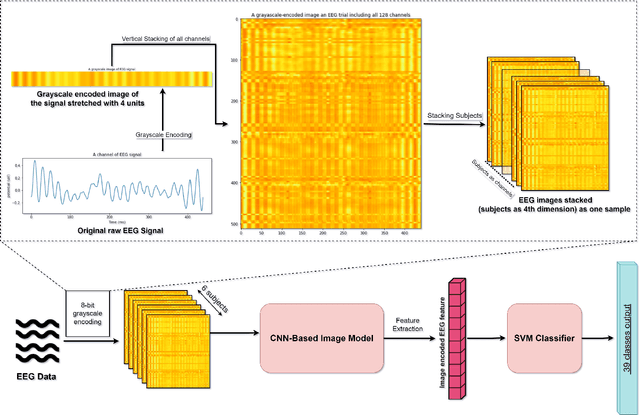
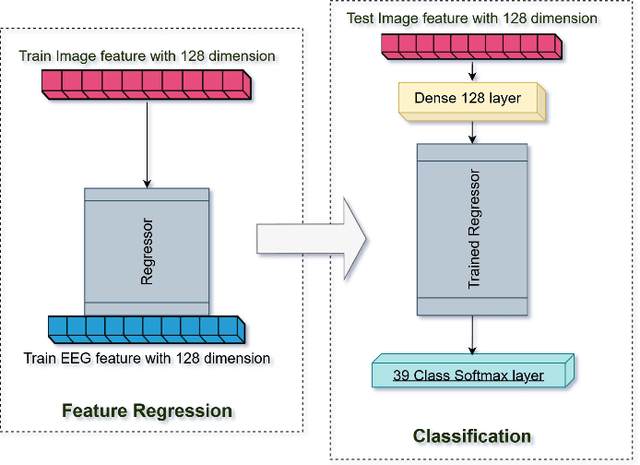
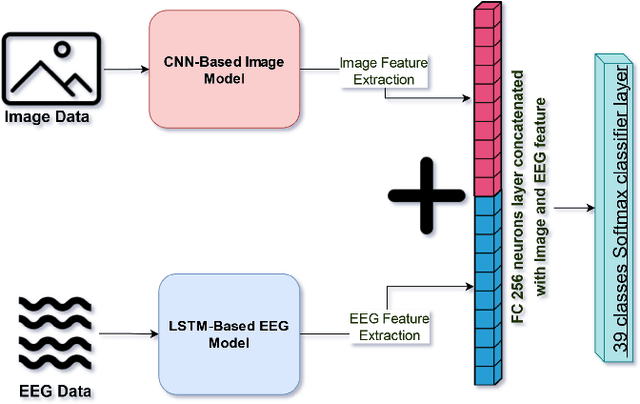
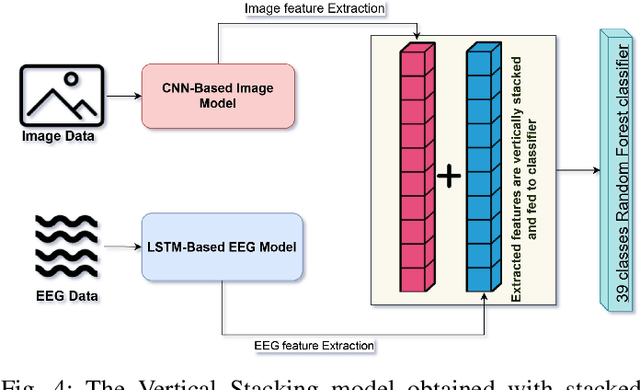
While capable of segregating visual data, humans take time to examine a single piece, let alone thousands or millions of samples. The deep learning models efficiently process sizeable information with the help of modern-day computing. However, their questionable decision-making process has raised considerable concerns. Recent studies have identified a new approach to extract image features from EEG signals and combine them with standard image features. These approaches make deep learning models more interpretable and also enables faster converging of models with fewer samples. Inspired by recent studies, we developed an efficient way of encoding EEG signals as images to facilitate a more subtle understanding of brain signals with deep learning models. Using two variations in such encoding methods, we classified the encoded EEG signals corresponding to 39 image classes with a benchmark accuracy of 70% on the layered dataset of six subjects, which is significantly higher than the existing work. Our image classification approach with combined EEG features achieved an accuracy of 82% compared to the slightly better accuracy of a pure deep learning approach; nevertheless, it demonstrates the viability of the theory.
Outage Probability Analysis of HARQ-Aided Terahertz Communications
Sep 24, 2022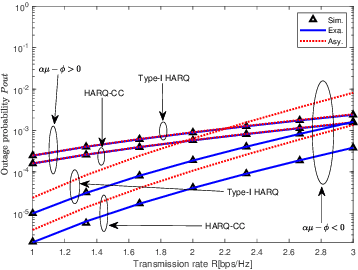
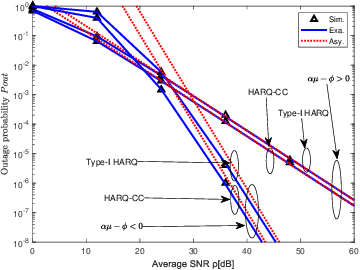
Although terahertz (THz) communications can provide mobile broadband services, it usually has a large path loss and is vulnerable to antenna misalignment. This significantly degrades the reception reliability. To address this issue, the hybrid automatic repeat request (HARQ) is proposed to further enhance the reliability of THz communications. This paper provides an in-depth investigation on the outage performance of two different types of HARQ-aided THz communications, including Type-I HARQ and HARQ with chase combining (HARQ-CC). Moreover, the effects of both fading and stochastic antenna misalignment are considered in this paper. The exact outage probabilities of HARQ-aided THz communications are derived in closed-form, with which the asymptotic outage analysis is enabled to explore helpful insights. In particular, it is revealed that full time diversity can be achieved by using HARQ assisted schemes. Besides, the HARQ-CC-aided scheme performs better than the Type-I HARQ-aided one due to its high diversity combining gain. The analytical results are eventually validated via Monte-Carlo simulations.
Uncertainty estimations methods for a deep learning model to aid in clinical decision-making -- a clinician's perspective
Oct 02, 2022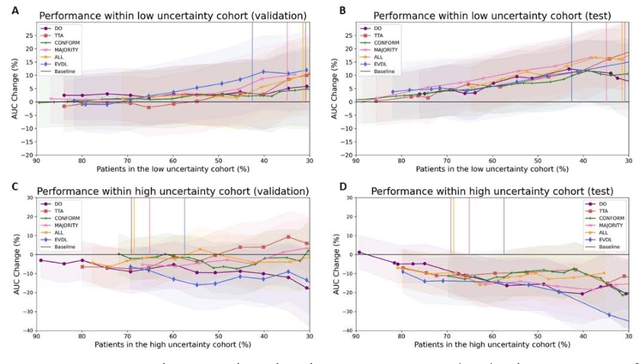
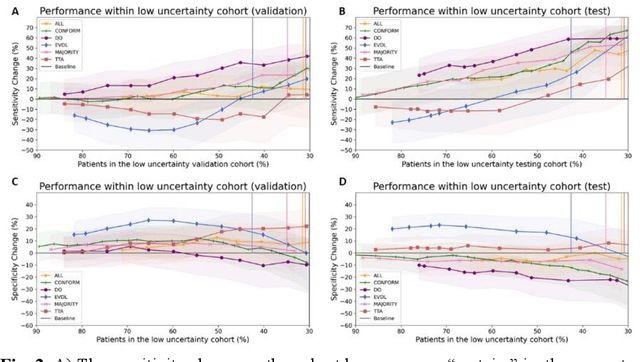
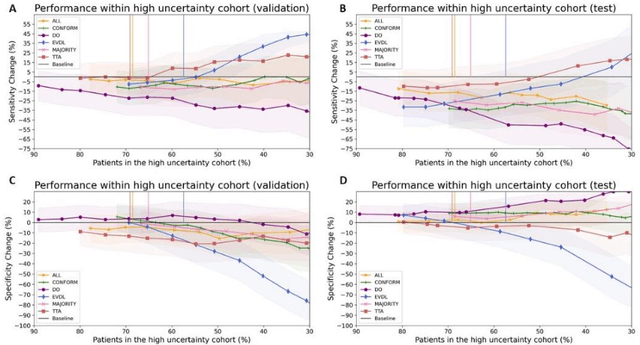
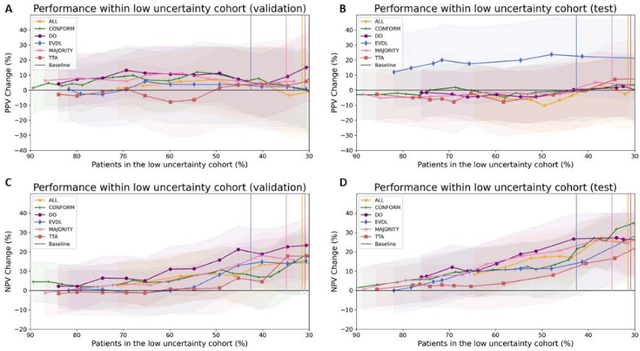
Prediction uncertainty estimation has clinical significance as it can potentially quantify prediction reliability. Clinicians may trust 'blackbox' models more if robust reliability information is available, which may lead to more models being adopted into clinical practice. There are several deep learning-inspired uncertainty estimation techniques, but few are implemented on medical datasets -- fewer on single institutional datasets/models. We sought to compare dropout variational inference (DO), test-time augmentation (TTA), conformal predictions, and single deterministic methods for estimating uncertainty using our model trained to predict feeding tube placement for 271 head and neck cancer patients treated with radiation. We compared the area under the curve (AUC), sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) trends for each method at various cutoffs that sought to stratify patients into 'certain' and 'uncertain' cohorts. These cutoffs were obtained by calculating the percentile "uncertainty" within the validation cohort and applied to the testing cohort. Broadly, the AUC, sensitivity, and NPV increased as the predictions were more 'certain' -- i.e., lower uncertainty estimates. However, when a majority vote (implementing 2/3 criteria: DO, TTA, conformal predictions) or a stricter approach (3/3 criteria) were used, AUC, sensitivity, and NPV improved without a notable loss in specificity or PPV. Especially for smaller, single institutional datasets, it may be important to evaluate multiple estimations techniques before incorporating a model into clinical practice.
Real-Time Risk-Bounded Tube-Based Trajectory Safety Verification
Oct 01, 2021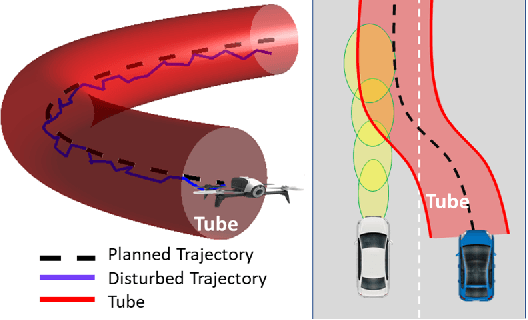
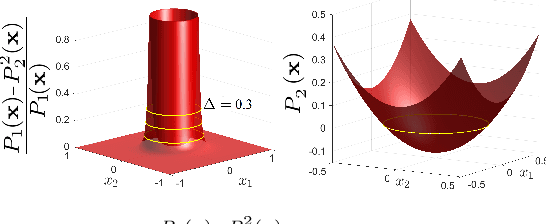
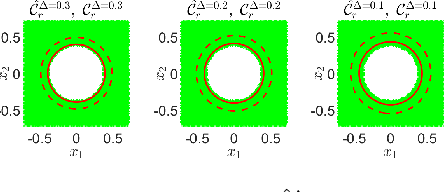
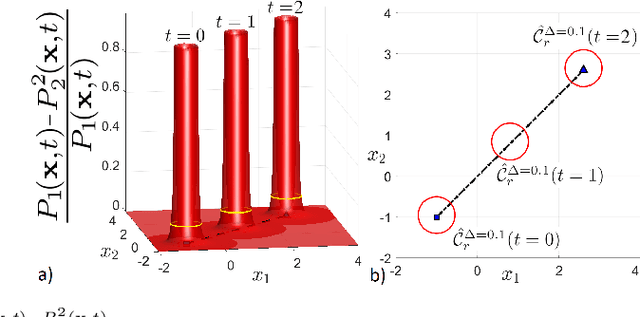
In this paper, we address the real-time risk-bounded safety verification problem of continuous-time state trajectories of autonomous systems in the presence of uncertain time-varying nonlinear safety constraints. Risk is defined as the probability of not satisfying the uncertain safety constraints. Existing approaches to address the safety verification problems under uncertainties either are limited to particular classes of uncertainties and safety constraints, e.g., Gaussian uncertainties and linear constraints, or rely on sampling based methods. In this paper, we provide a fast convex algorithm to efficiently evaluate the probabilistic nonlinear safety constraints in the presence of arbitrary probability distributions and long planning horizons in real-time, without the need for uncertainty samples and time discretization. The provided approach verifies the safety of the given state trajectory and its neighborhood (tube) to account for the execution uncertainties and risk. In the provided approach, we first use the moments of the probability distributions of the uncertainties to transform the probabilistic safety constraints into a set of deterministic safety constraints. We then use convex methods based on sum-of-squares polynomials to verify the obtained deterministic safety constraints over the entire planning time horizon without time discretization. To illustrate the performance of the proposed method, we apply the provided method to the safety verification problem of self-driving vehicles and autonomous aerial vehicles.
Untargeted Backdoor Watermark: Towards Harmless and Stealthy Dataset Copyright Protection
Sep 27, 2022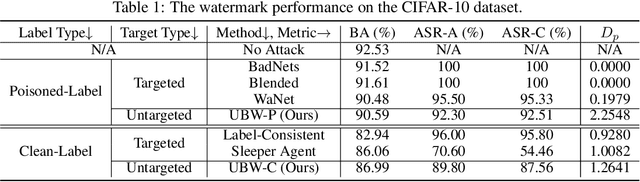


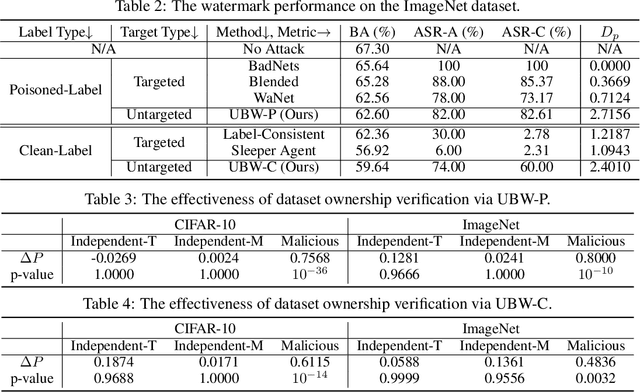
Deep neural networks (DNNs) have demonstrated their superiority in practice. Arguably, the rapid development of DNNs is largely benefited from high-quality (open-sourced) datasets, based on which researchers and developers can easily evaluate and improve their learning methods. Since the data collection is usually time-consuming or even expensive, how to protect their copyrights is of great significance and worth further exploration. In this paper, we revisit dataset ownership verification. We find that existing verification methods introduced new security risks in DNNs trained on the protected dataset, due to the targeted nature of poison-only backdoor watermarks. To alleviate this problem, in this work, we explore the untargeted backdoor watermarking scheme, where the abnormal model behaviors are not deterministic. Specifically, we introduce two dispersibilities and prove their correlation, based on which we design the untargeted backdoor watermark under both poisoned-label and clean-label settings. We also discuss how to use the proposed untargeted backdoor watermark for dataset ownership verification. Experiments on benchmark datasets verify the effectiveness of our methods and their resistance to existing backdoor defenses. Our codes are available at \url{https://github.com/THUYimingLi/Untargeted_Backdoor_Watermark}.
Make-A-Video: Text-to-Video Generation without Text-Video Data
Sep 29, 2022

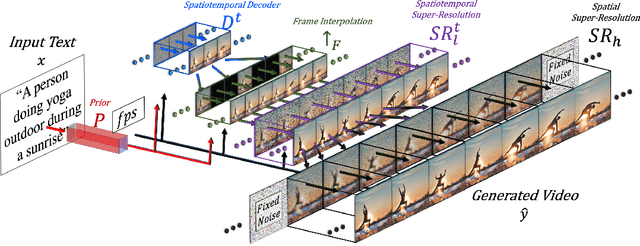
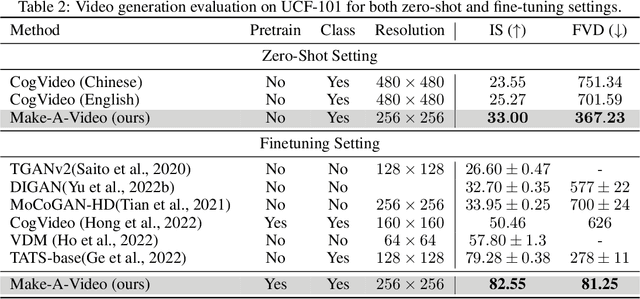
We propose Make-A-Video -- an approach for directly translating the tremendous recent progress in Text-to-Image (T2I) generation to Text-to-Video (T2V). Our intuition is simple: learn what the world looks like and how it is described from paired text-image data, and learn how the world moves from unsupervised video footage. Make-A-Video has three advantages: (1) it accelerates training of the T2V model (it does not need to learn visual and multimodal representations from scratch), (2) it does not require paired text-video data, and (3) the generated videos inherit the vastness (diversity in aesthetic, fantastical depictions, etc.) of today's image generation models. We design a simple yet effective way to build on T2I models with novel and effective spatial-temporal modules. First, we decompose the full temporal U-Net and attention tensors and approximate them in space and time. Second, we design a spatial temporal pipeline to generate high resolution and frame rate videos with a video decoder, interpolation model and two super resolution models that can enable various applications besides T2V. In all aspects, spatial and temporal resolution, faithfulness to text, and quality, Make-A-Video sets the new state-of-the-art in text-to-video generation, as determined by both qualitative and quantitative measures.
Deep Double Descent via Smooth Interpolation
Sep 21, 2022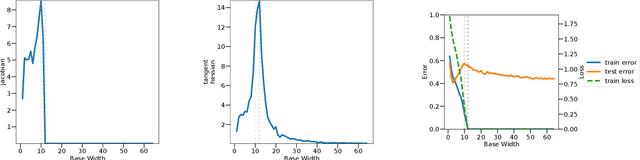
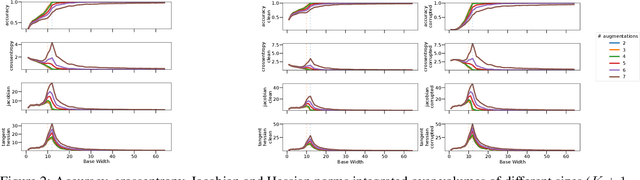
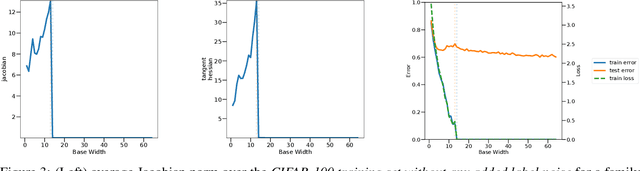
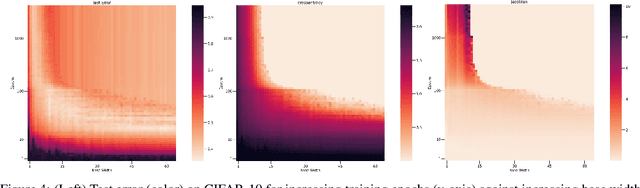
Overparameterized deep networks are known to be able to perfectly fit the training data while at the same time showing good generalization performance. A common paradigm drawn from intuition on linear regression suggests that large networks are able to interpolate even noisy data, without considerably deviating from the ground-truth signal. At present, a precise characterization of this phenomenon is missing. In this work, we present an empirical study of sharpness of the loss landscape of deep networks as we systematically control the number of model parameters and training epochs. We extend our study to neighbourhoods of the training data, as well as around cleanly- and noisily-labelled samples. Our findings show that the loss sharpness in the input space follows both model- and epoch-wise double descent, with worse peaks observed around noisy labels. While small interpolating models sharply fit both clean and noisy data, large models express a smooth and flat loss landscape, in contrast with existing intuition.
Diversified Dynamic Routing for Vision Tasks
Sep 26, 2022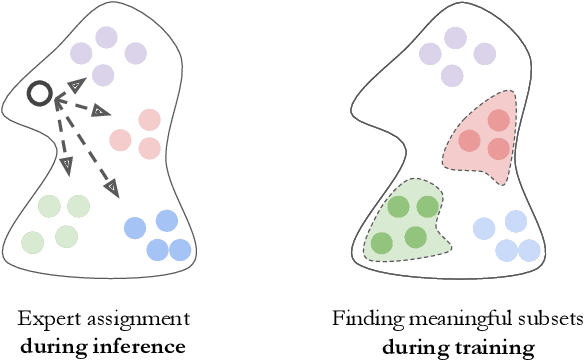
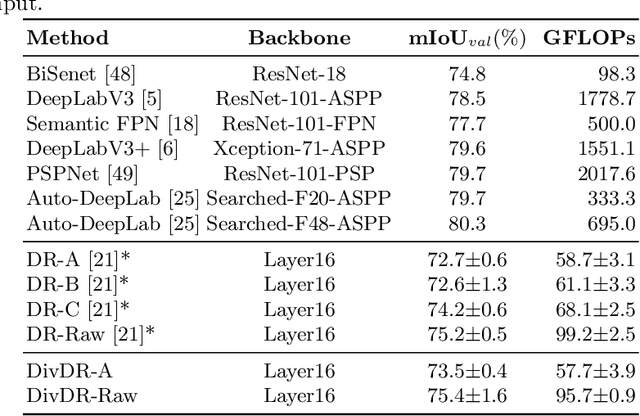
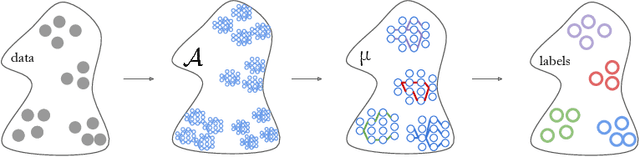
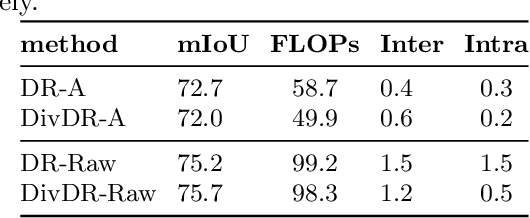
Deep learning models for vision tasks are trained on large datasets under the assumption that there exists a universal representation that can be used to make predictions for all samples. Whereas high complexity models are proven to be capable of learning such representations, a mixture of experts trained on specific subsets of the data can infer the labels more efficiently. However using mixture of experts poses two new problems, namely (i) assigning the correct expert at inference time when a new unseen sample is presented. (ii) Finding the optimal partitioning of the training data, such that the experts rely the least on common features. In Dynamic Routing (DR) a novel architecture is proposed where each layer is composed of a set of experts, however without addressing the two challenges we demonstrate that the model reverts to using the same subset of experts. In our method, Diversified Dynamic Routing (DivDR) the model is explicitly trained to solve the challenge of finding relevant partitioning of the data and assigning the correct experts in an unsupervised approach. We conduct several experiments on semantic segmentation on Cityscapes and object detection and instance segmentation on MS-COCO showing improved performance over several baselines.
Bayesian Identification of Nonseparable Hamiltonian Systems Using Stochastic Dynamic Models
Sep 15, 2022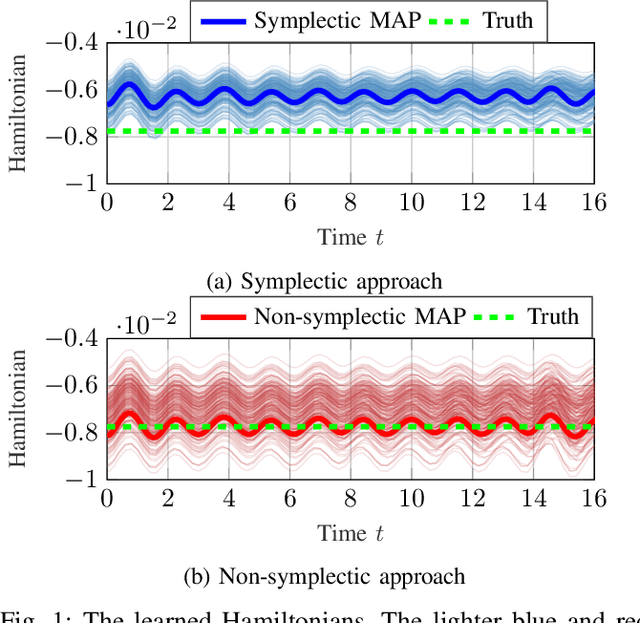
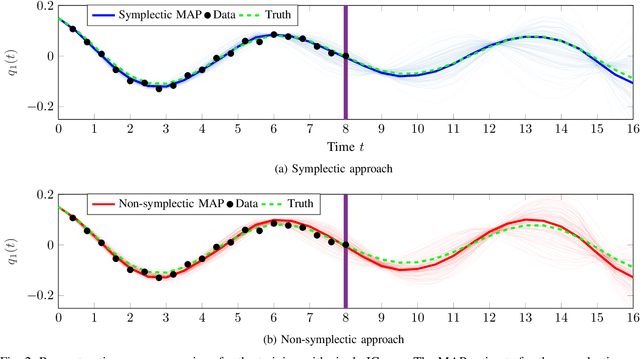
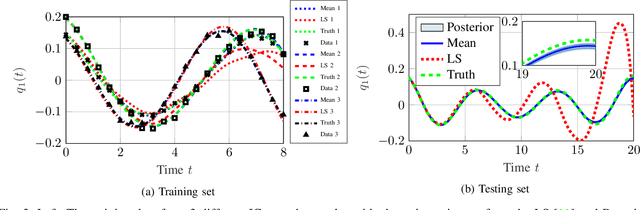
This paper proposes a probabilistic Bayesian formulation for system identification (ID) and estimation of nonseparable Hamiltonian systems using stochastic dynamic models. Nonseparable Hamiltonian systems arise in models from diverse science and engineering applications such as astrophysics, robotics, vortex dynamics, charged particle dynamics, and quantum mechanics. The numerical experiments demonstrate that the proposed method recovers dynamical systems with higher accuracy and reduced predictive uncertainty compared to state-of-the-art approaches. The results further show that accurate predictions far outside the training time interval in the presence of sparse and noisy measurements are possible, which lends robustness and generalizability to the proposed approach. A quantitative benefit is prediction accuracy with less than 10% relative error for more than 12 times longer than a comparable least-squares-based method on a benchmark problem.