 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Randomized Signature Layers for Signal Extraction in Time Series Data
Jan 02, 2022
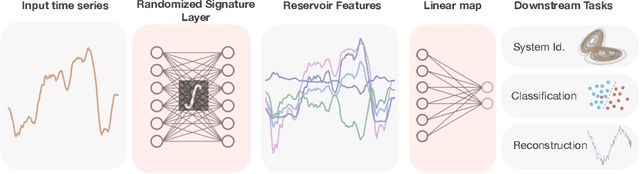

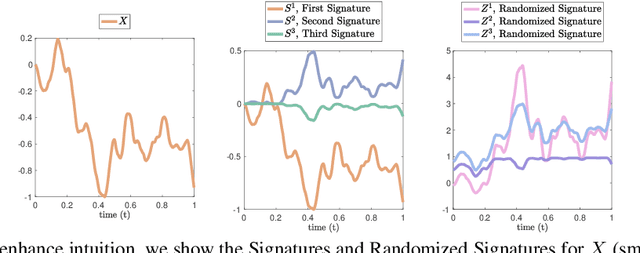
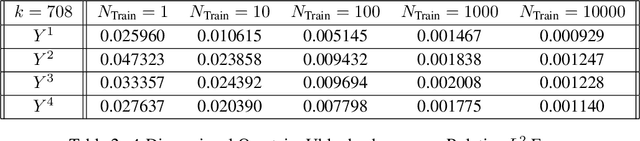
Time series analysis is a widespread task in Natural Sciences, Social Sciences, and Engineering. A fundamental problem is finding an expressive yet efficient-to-compute representation of the input time series to use as a starting point to perform arbitrary downstream tasks. In this paper, we build upon recent works that use the Signature of a path as a feature map and investigate a computationally efficient technique to approximate these features based on linear random projections. We present several theoretical results to justify our approach and empirically validate that our random projections can effectively retrieve the underlying Signature of a path. We show the surprising performance of the proposed random features on several tasks, including (1) mapping the controls of stochastic differential equations to the corresponding solutions and (2) using the Randomized Signatures as time series representation for classification tasks. When compared to corresponding truncated Signature approaches, our Randomizes Signatures are more computationally efficient in high dimensions and often lead to better accuracy and faster training. Besides providing a new tool to extract Signatures and further validating the high level of expressiveness of such features, we believe our results provide interesting conceptual links between several existing research areas, suggesting new intriguing directions for future investigations.
RGB-Event Fusion for Moving Object Detection in Autonomous Driving
Sep 17, 2022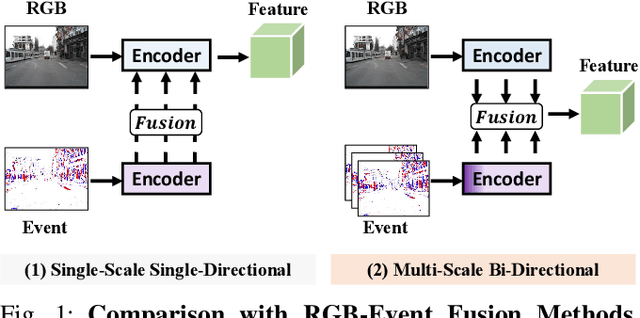
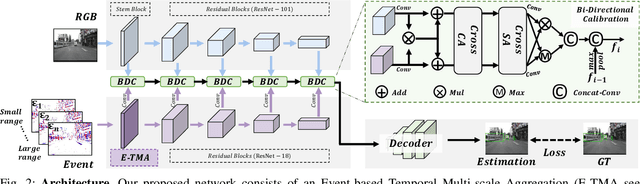
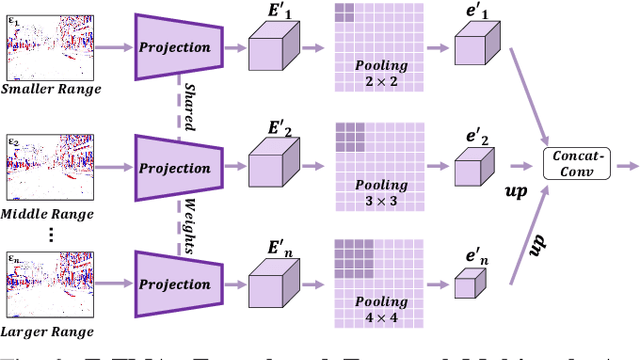
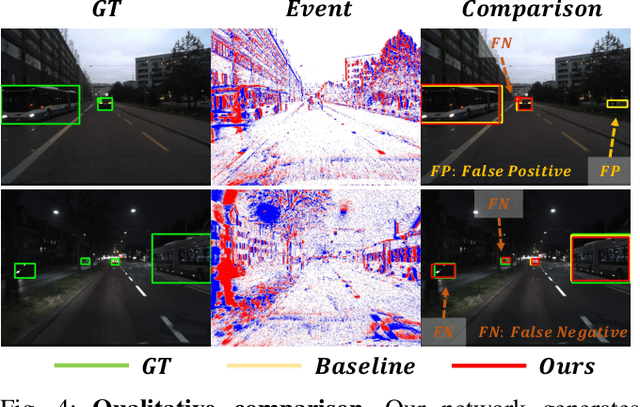
Moving Object Detection (MOD) is a critical vision task for successfully achieving safe autonomous driving. Despite plausible results of deep learning methods, most existing approaches are only frame-based and may fail to reach reasonable performance when dealing with dynamic traffic participants. Recent advances in sensor technologies, especially the Event camera, can naturally complement the conventional camera approach to better model moving objects. However, event-based works often adopt a pre-defined time window for event representation, and simply integrate it to estimate image intensities from events, neglecting much of the rich temporal information from the available asynchronous events. Therefore, from a new perspective, we propose RENet, a novel RGB-Event fusion Network, that jointly exploits the two complementary modalities to achieve more robust MOD under challenging scenarios for autonomous driving. Specifically, we first design a temporal multi-scale aggregation module to fully leverage event frames from both the RGB exposure time and larger intervals. Then we introduce a bi-directional fusion module to attentively calibrate and fuse multi-modal features. To evaluate the performance of our network, we carefully select and annotate a sub-MOD dataset from the commonly used DSEC dataset. Extensive experiments demonstrate that our proposed method performs significantly better than the state-of-the-art RGB-Event fusion alternatives.
Deep Learning for Real Time Satellite Pose Estimation on Low Power Edge TPU
Apr 07, 2022
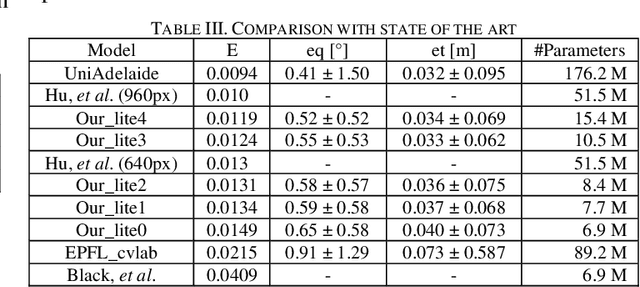
Pose estimation of an uncooperative space resident object is a key asset towards autonomy in close proximity operations. In this context monocular cameras are a valuable solution because of their low system requirements. However, the associated image processing algorithms are either too computationally expensive for real time on-board implementation, or not enough accurate. In this paper we propose a pose estimation software exploiting neural network architectures which can be scaled to different accuracy-latency trade-offs. We designed our pipeline to be compatible with Edge Tensor Processing Units to show how low power machine learning accelerators could enable Artificial Intelligence exploitation in space. The neural networks were tested both on the benchmark Spacecraft Pose Estimation Dataset, and on the purposely developed Cosmo Photorealistic Dataset, which depicts a COSMO-SkyMed satellite in a variety of random poses and steerable solar panels orientations. The lightest version of our architecture achieves state-of-the-art accuracy on both datasets but at a fraction of networks complexity, running at 7.7 frames per second on a Coral Dev Board Mini consuming just 2.2W.
Inductive Logical Query Answering in Knowledge Graphs
Oct 13, 2022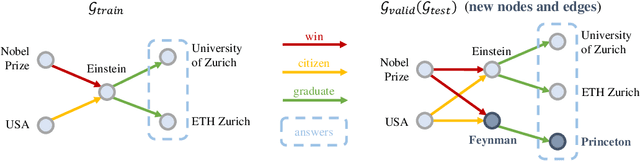
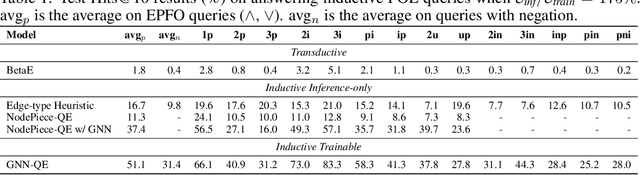
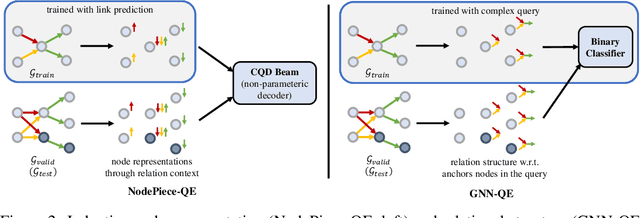

Formulating and answering logical queries is a standard communication interface for knowledge graphs (KGs). Alleviating the notorious incompleteness of real-world KGs, neural methods achieved impressive results in link prediction and complex query answering tasks by learning representations of entities, relations, and queries. Still, most existing query answering methods rely on transductive entity embeddings and cannot generalize to KGs containing new entities without retraining the entity embeddings. In this work, we study the inductive query answering task where inference is performed on a graph containing new entities with queries over both seen and unseen entities. To this end, we devise two mechanisms leveraging inductive node and relational structure representations powered by graph neural networks (GNNs). Experimentally, we show that inductive models are able to perform logical reasoning at inference time over unseen nodes generalizing to graphs up to 500% larger than training ones. Exploring the efficiency--effectiveness trade-off, we find the inductive relational structure representation method generally achieves higher performance, while the inductive node representation method is able to answer complex queries in the inference-only regime without any training on queries and scales to graphs of millions of nodes. Code is available at https://github.com/DeepGraphLearning/InductiveQE.
Self-Supervised Geometric Correspondence for Category-Level 6D Object Pose Estimation in the Wild
Oct 13, 2022
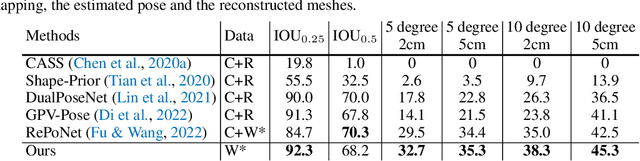
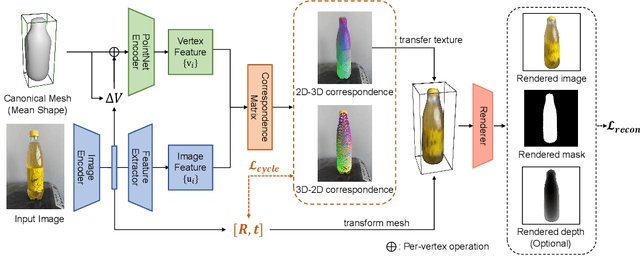
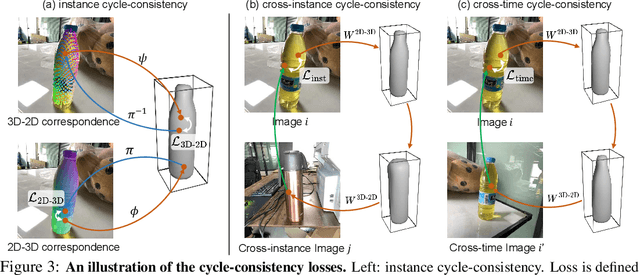
While 6D object pose estimation has wide applications across computer vision and robotics, it remains far from being solved due to the lack of annotations. The problem becomes even more challenging when moving to category-level 6D pose, which requires generalization to unseen instances. Current approaches are restricted by leveraging annotations from simulation or collected from humans. In this paper, we overcome this barrier by introducing a self-supervised learning approach trained directly on large-scale real-world object videos for category-level 6D pose estimation in the wild. Our framework reconstructs the canonical 3D shape of an object category and learns dense correspondences between input images and the canonical shape via surface embedding. For training, we propose novel geometrical cycle-consistency losses which construct cycles across 2D-3D spaces, across different instances and different time steps. The learned correspondence can be applied for 6D pose estimation and other downstream tasks such as keypoint transfer. Surprisingly, our method, without any human annotations or simulators, can achieve on-par or even better performance than previous supervised or semi-supervised methods on in-the-wild images. Our project page is: https://kywind.github.io/self-pose .
CNTN: Cyclic Noise-tolerant Network for Gait Recognition
Oct 13, 2022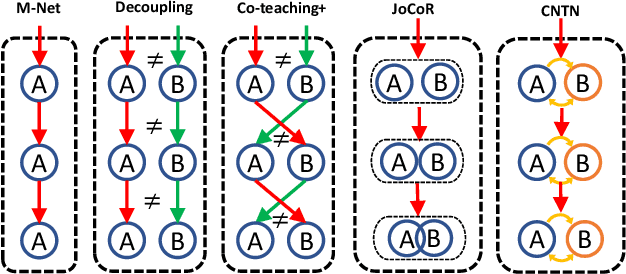
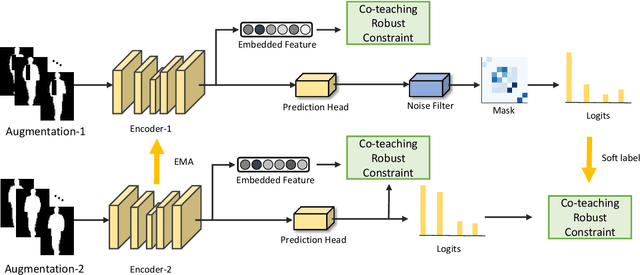
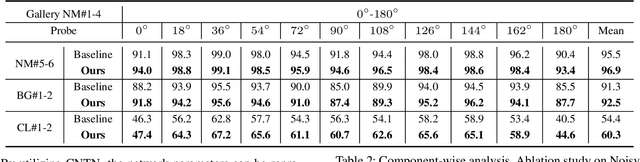
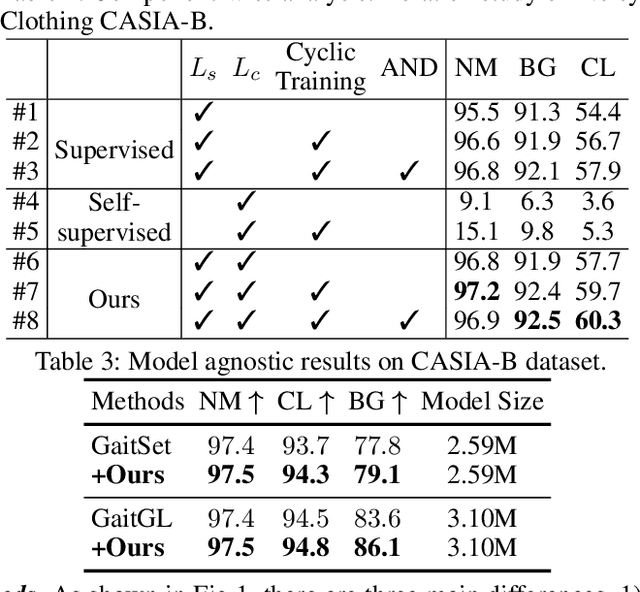
Gait recognition aims to identify individuals by recognizing their walking patterns. However, an observation is made that most of the previous gait recognition methods degenerate significantly due to two memorization effects, namely appearance memorization and label noise memorization. To address the problem, for the first time noisy gait recognition is studied, and a cyclic noise-tolerant network (CNTN) is proposed with a cyclic training algorithm, which equips the two parallel networks with explicitly different abilities, namely one forgetting network and one memorizing network. The overall model will not memorize the pattern unless the two different networks both memorize it. Further, a more refined co-teaching constraint is imposed to help the model learn intrinsic patterns which are less influenced by memorization. Also, to address label noise memorization, an adaptive noise detection module is proposed to rule out the samples with high possibility to be noisy from updating the model. Experiments are conducted on the three most popular benchmarks and CNTN achieves state-of-the-art performances. We also reconstruct two noisy gait recognition datasets, and CNTN gains significant improvements (especially 6% improvements on CL setting). CNTN is also compatible with any off-the-shelf backbones and improves them consistently.
Learning Driving Policies for End-to-End Autonomous Driving
Oct 13, 2022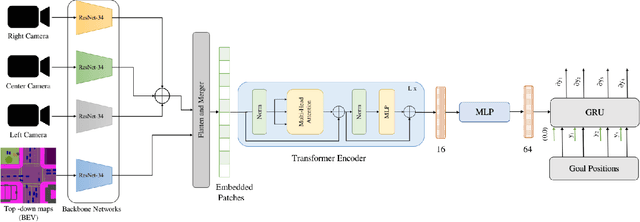

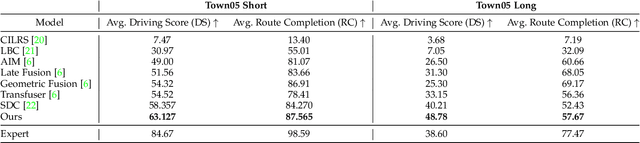
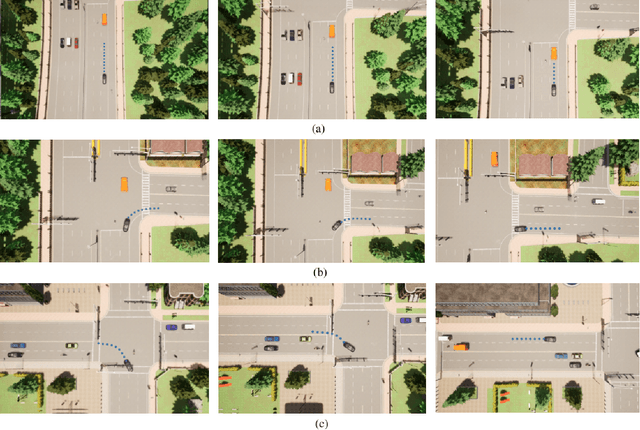
Humans tend to drive vehicles efficiently by relying on contextual and spatial information through the sensory organs. Inspired by this, most of the research is focused on how to learn robust and efficient driving policies. These works are mostly categorized as making modular or end-to-end systems for learning driving policies. However, the former approach has limitations due to the manual supervision of specific modules that hinder the scalability of these systems. In this work, we focus on the latter approach to formalize a framework for learning driving policies for end-to-end autonomous driving. In order to take inspiration from human driving, we have proposed a framework that incorporates three RGB cameras (left, right, and center) to mimic the human field of view and top-down semantic information for contextual representation in predicting the driving policies for autonomous driving. The sensor information is fused and encoded by the self-attention mechanism and followed by the auto-regressive waypoint prediction module. The proposed method's efficacy is experimentally evaluated using the CARLA simulator and outperforms the state-of-the-art methods by achieving the highest driving score at the evaluation time.
Deepfake Detection System for the ADD Challenge Track 3.2 Based on Score Fusion
Oct 13, 2022
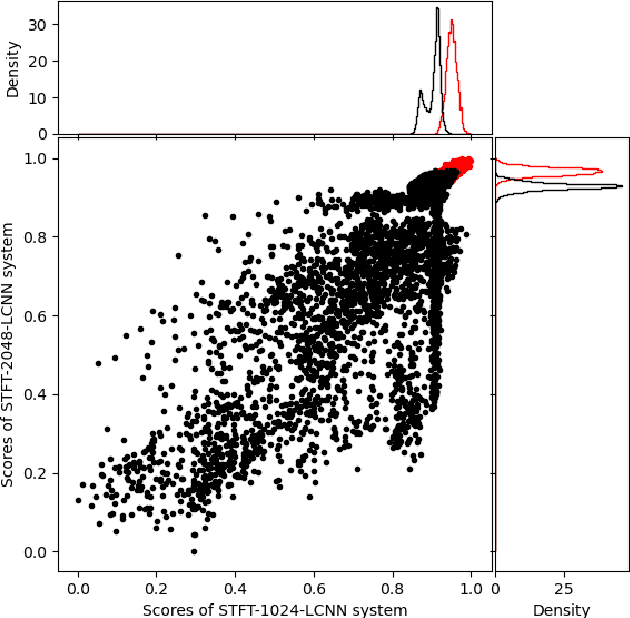
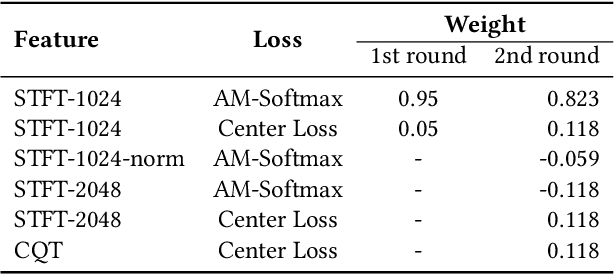
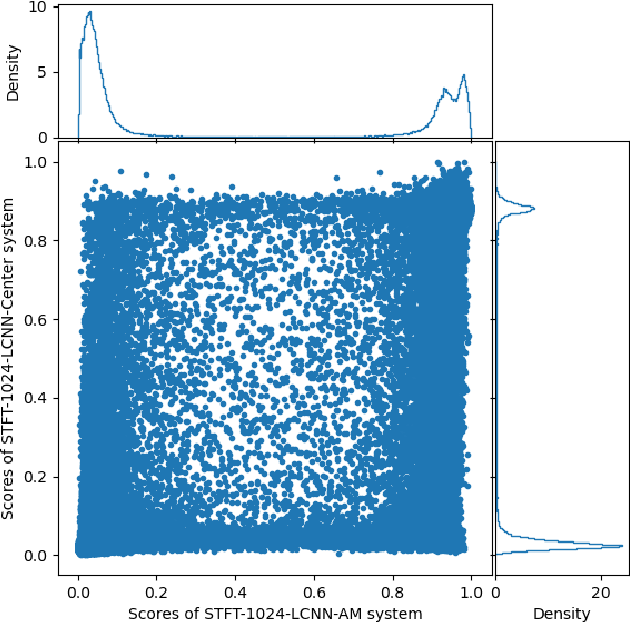
This paper describes the deepfake audio detection system submitted to the Audio Deep Synthesis Detection (ADD) Challenge Track 3.2 and gives an analysis of score fusion. The proposed system is a score-level fusion of several light convolutional neural network (LCNN) based models. Various front-ends are used as input features, including low-frequency short-time Fourier transform and Constant Q transform. Due to the complex noise and rich synthesis algorithms, it is difficult to obtain the desired performance using the training set directly. Online data augmentation methods effectively improve the robustness of fake audio detection systems. In particular, the reasons for the poor improvement of score fusion are explored through visualization of the score distributions and comparison with score distribution on another dataset. The overfitting of the model to the training set leads to extreme values of the scores and low correlation of the score distributions, which makes score fusion difficult. Fusion with partially fake audio detection system improves system performance further. The submission on track 3.2 obtained the weighted equal error rate (WEER) of 11.04\%, which is one of the best performing systems in the challenge.
Object-Category Aware Reinforcement Learning
Oct 13, 2022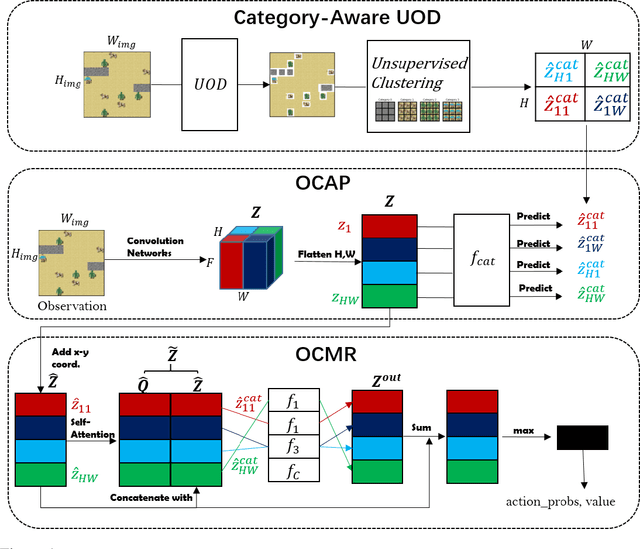

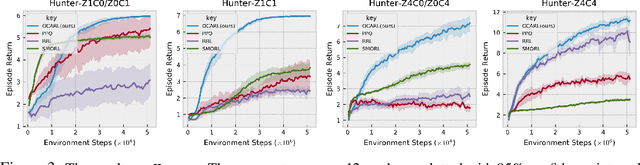

Object-oriented reinforcement learning (OORL) is a promising way to improve the sample efficiency and generalization ability over standard RL. Recent works that try to solve OORL tasks without additional feature engineering mainly focus on learning the object representations and then solving tasks via reasoning based on these object representations. However, none of these works tries to explicitly model the inherent similarity between different object instances of the same category. Objects of the same category should share similar functionalities; therefore, the category is the most critical property of an object. Following this insight, we propose a novel framework named Object-Category Aware Reinforcement Learning (OCARL), which utilizes the category information of objects to facilitate both perception and reasoning. OCARL consists of three parts: (1) Category-Aware Unsupervised Object Discovery (UOD), which discovers the objects as well as their corresponding categories; (2) Object-Category Aware Perception, which encodes the category information and is also robust to the incompleteness of (1) at the same time; (3) Object-Centric Modular Reasoning, which adopts multiple independent and object-category-specific networks when reasoning based on objects. Our experiments show that OCARL can improve both the sample efficiency and generalization in the OORL domain.
Machine Learning Sensors for Diagnosis of COVID-19 Disease Using Routine Blood Values for Internet of Things Application
Sep 08, 2022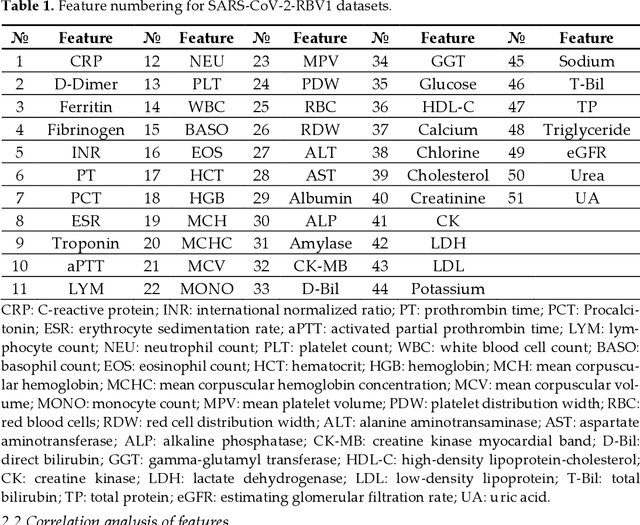
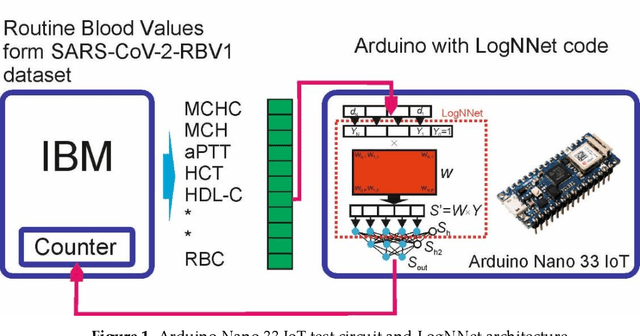
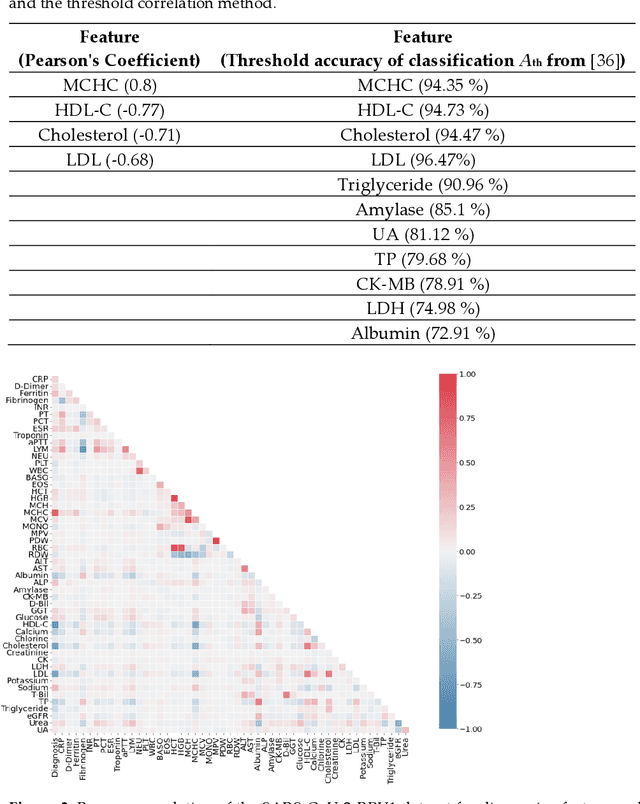
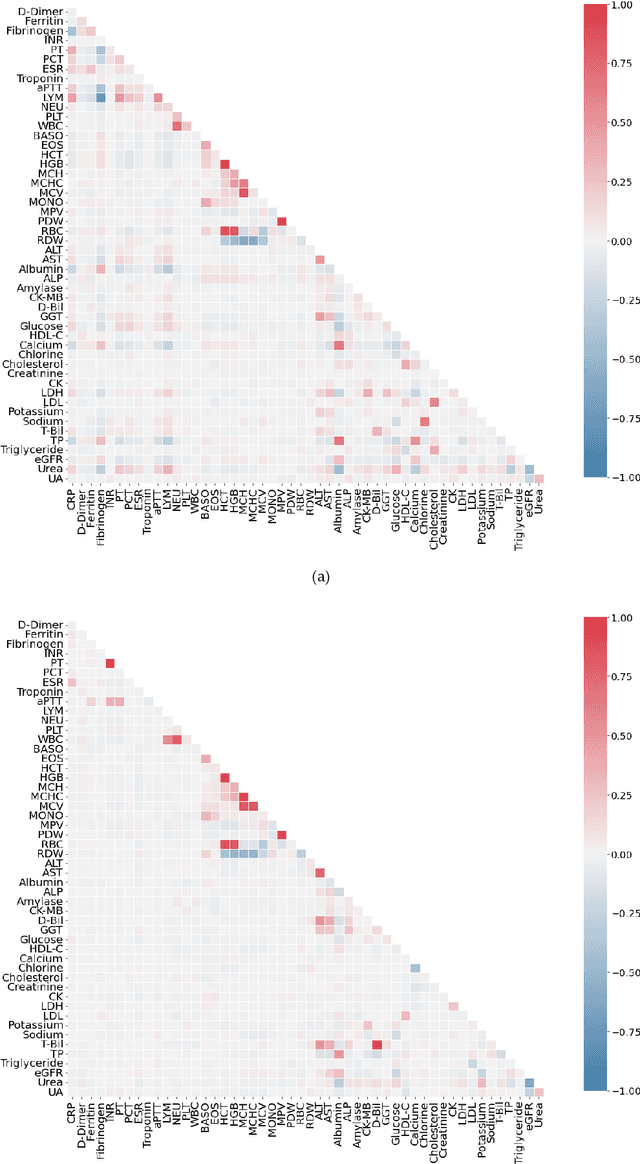
Healthcare digitalization needs effective methods of human sensorics, when various parameters of the human body are instantly monitored in everyday life and connected to the Internet of Things (IoT). In particular, Machine Learning (ML) sensors for the prompt diagnosis of COVID-19 is an important case for IoT application in healthcare and Ambient Assistance Living (AAL). Determining the infected status of COVID-19 with various diagnostic tests and imaging results is costly and time-consuming. The aim of this study is to provide a fast, reliable and economical alternative tool for the diagnosis of COVID-19 based on the Routine Blood Values (RBV) values measured at admission. The dataset of the study consists of a total of 5296 patients with the same number of negative and positive COVID-19 test results and 51 routine blood values. In this study, 13 popular classifier machine learning models and LogNNet neural network model were exanimated. The most successful classifier model in terms of time and accuracy in the detection of the disease was the Histogram-based Gradient Boosting (HGB). The HGB classifier identified the 11 most important features (LDL, Cholesterol, HDL-C, MCHC, Triglyceride, Amylase, UA, LDH, CK-MB, ALP and MCH) to detect the disease with 100% accuracy, learning time 6.39 sec. In addition, the importance of single, double and triple combinations of these features in the diagnosis of the disease was discussed. We propose to use these 11 traits and their combinations as important biomarkers for ML sensors in diagnosis of the disease, supporting edge computing on Arduino and cloud IoT service.