 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Prediction via a Multi-Sensor System for Autonomous Racing
Sep 28, 2024



Autonomous racing has rapidly gained research attention. Traditionally, racing cars rely on 2D LiDAR as their primary visual system. In this work, we explore the integration of an event camera with the existing system to provide enhanced temporal information. Our goal is to fuse the 2D LiDAR data with event data in an end-to-end learning framework for steering prediction, which is crucial for autonomous racing. To the best of our knowledge, this is the first study addressing this challenging research topic. We start by creating a multisensor dataset specifically for steering prediction. Using this dataset, we establish a benchmark by evaluating various SOTA fusion methods. Our observations reveal that existing methods often incur substantial computational costs. To address this, we apply low-rank techniques to propose a novel, efficient, and effective fusion design. We introduce a new fusion learning policy to guide the fusion process, enhancing robustness against misalignment. Our fusion architecture provides better steering prediction than LiDAR alone, significantly reducing the RMSE from 7.72 to 1.28. Compared to the second-best fusion method, our work represents only 11% of the learnable parameters while achieving better accuracy. The source code, dataset, and benchmark will be released to promote future research.
DSEC-MOS: Segment Any Moving Object with Moving Ego Vehicle
Apr 28, 2023



Moving Object Segmentation (MOS), a crucial task in computer vision, has numerous applications such as surveillance, autonomous driving, and video analytics. Existing datasets for moving object segmentation mainly focus on RGB or Lidar videos, but lack additional event information that can enhance the understanding of dynamic scenes. To address this limitation, we propose a novel dataset, called DSEC-MOS. Our dataset includes frames captured by RGB cameras embedded on moving vehicules and incorporates event data, which provide high temporal resolution and low-latency information about changes in the scenes. To generate accurate segmentation mask annotations for moving objects, we apply the recently emerged large model SAM - Segment Anything Model - with moving object bounding boxes from DSEC-MOD serving as prompts and calibrated RGB frames, then further revise the results. Our DSEC-MOS dataset contains in total 16 sequences (13314 images). To the best of our knowledge, DSEC-MOS is also the first moving object segmentation dataset that includes event camera in autonomous driving. Project Page: https://github.com/ZZY-Zhou/DSEC-MOS.
RGB-Event Fusion for Moving Object Detection in Autonomous Driving
Sep 17, 2022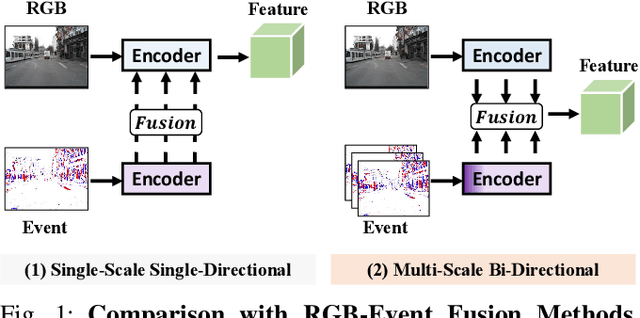
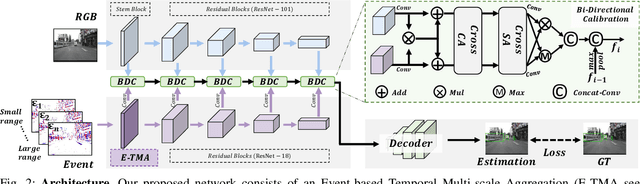
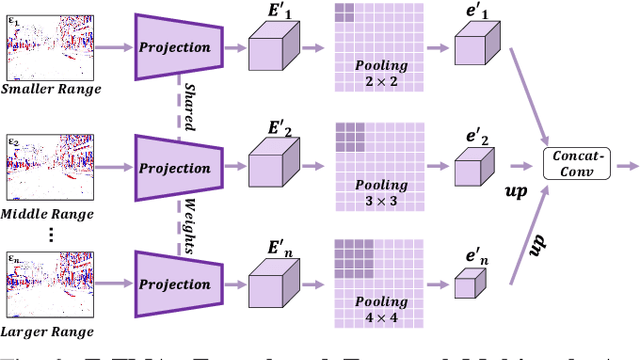
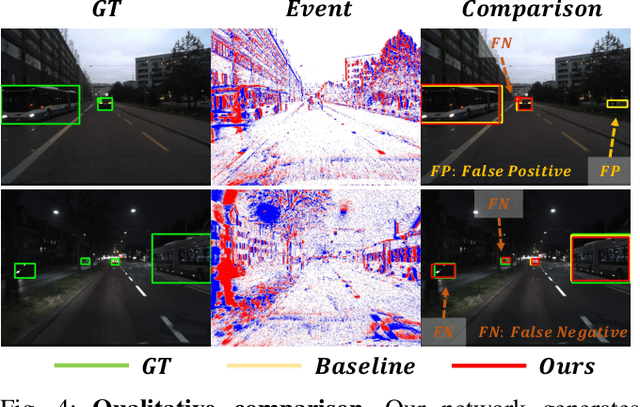
Moving Object Detection (MOD) is a critical vision task for successfully achieving safe autonomous driving. Despite plausible results of deep learning methods, most existing approaches are only frame-based and may fail to reach reasonable performance when dealing with dynamic traffic participants. Recent advances in sensor technologies, especially the Event camera, can naturally complement the conventional camera approach to better model moving objects. However, event-based works often adopt a pre-defined time window for event representation, and simply integrate it to estimate image intensities from events, neglecting much of the rich temporal information from the available asynchronous events. Therefore, from a new perspective, we propose RENet, a novel RGB-Event fusion Network, that jointly exploits the two complementary modalities to achieve more robust MOD under challenging scenarios for autonomous driving. Specifically, we first design a temporal multi-scale aggregation module to fully leverage event frames from both the RGB exposure time and larger intervals. Then we introduce a bi-directional fusion module to attentively calibrate and fuse multi-modal features. To evaluate the performance of our network, we carefully select and annotate a sub-MOD dataset from the commonly used DSEC dataset. Extensive experiments demonstrate that our proposed method performs significantly better than the state-of-the-art RGB-Event fusion alternatives.
LiDAR point clouds correction acquired from a moving car based on CAN-bus data
Jun 19, 2017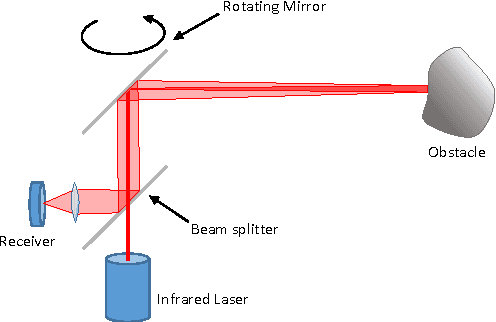
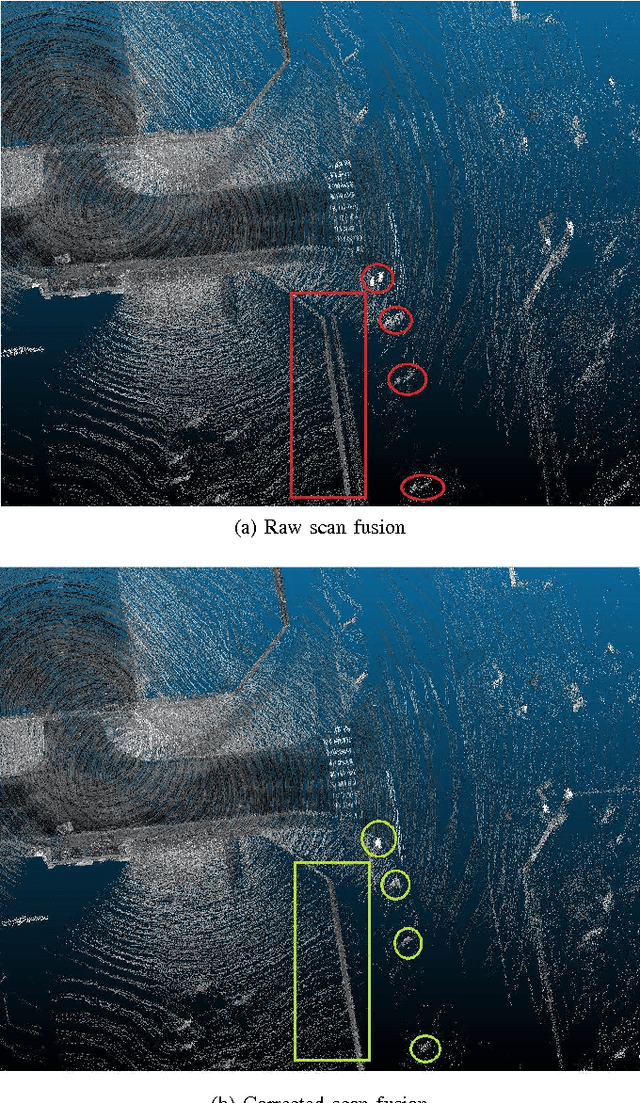
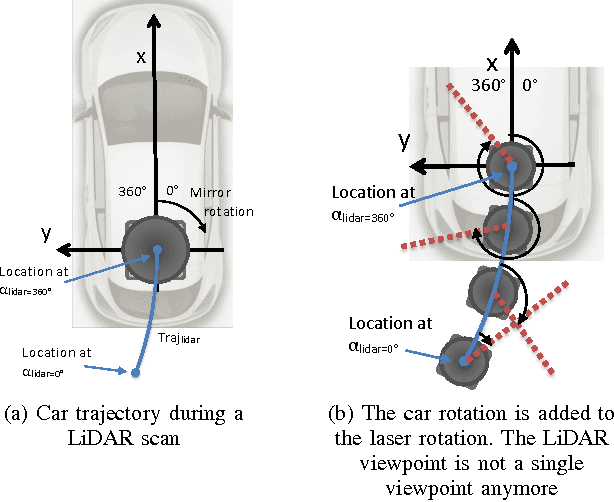
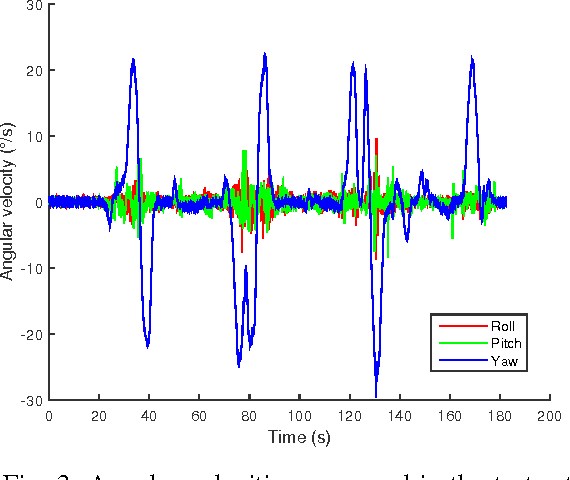
In this paper, we investigate the impact of different kind of car trajectories on LiDAR scans. In fact, LiDAR scanning speeds are considerably slower than car speeds introducing distortions. We propose a method to overcome this issue as well as new metrics based on CAN bus data. Our results suggest that the vehicle trajectory should be taken into account when building 3D large-scale maps from a LiDAR mounted on a moving vehicle.