 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Anomaly Detection with Test Time Augmentation and Consistency Evaluation
Jun 06, 2022
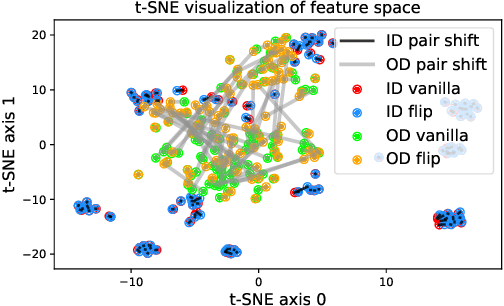
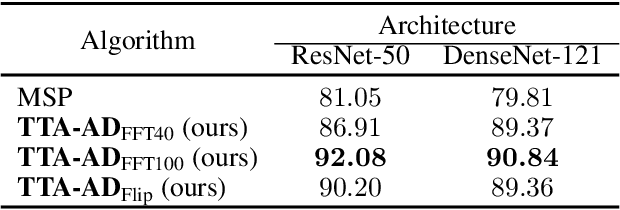

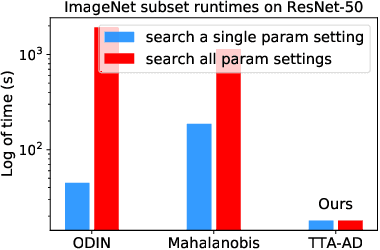
Deep neural networks are known to be vulnerable to unseen data: they may wrongly assign high confidence stcores to out-distribuion samples. Recent works try to solve the problem using representation learning methods and specific metrics. In this paper, we propose a simple, yet effective post-hoc anomaly detection algorithm named Test Time Augmentation Anomaly Detection (TTA-AD), inspired by a novel observation. Specifically, we observe that in-distribution data enjoy more consistent predictions for its original and augmented versions on a trained network than out-distribution data, which separates in-distribution and out-distribution samples. Experiments on various high-resolution image benchmark datasets demonstrate that TTA-AD achieves comparable or better detection performance under dataset-vs-dataset anomaly detection settings with a 60%~90\% running time reduction of existing classifier-based algorithms. We provide empirical verification that the key to TTA-AD lies in the remaining classes between augmented features, which has long been partially ignored by previous works. Additionally, we use RUNS as a surrogate to analyze our algorithm theoretically.
Polynomial Time Near-Time-Optimal Multi-Robot Path Planning in Three Dimensions with Applications to Large-Scale UAV Coordination
Jul 06, 2022
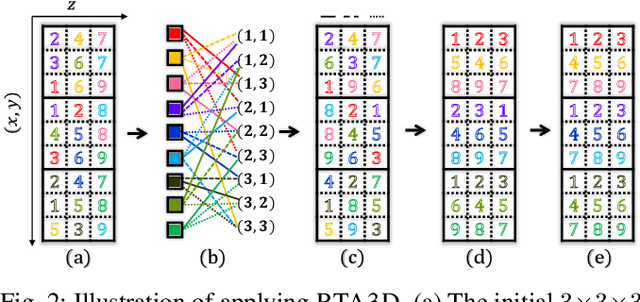
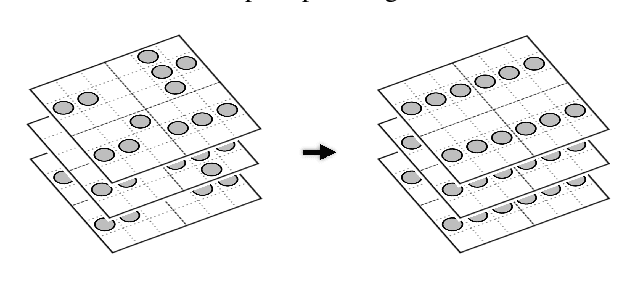
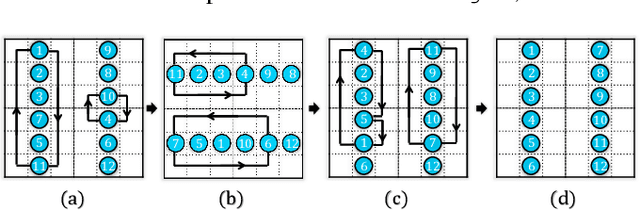
For enabling efficient, large-scale coordination of unmanned aerial vehicles (UAVs) under the labeled setting, in this work, we develop the first polynomial time algorithm for the reconfiguration of many moving bodies in three-dimensional spaces, with provable $1.x$ asymptotic makespan optimality guarantee under high robot density. More precisely, on an $m_1\times m_2 \times m_3$ grid, $m_1\ge m_2\ge m_3$, our method computes solutions for routing up to $\frac{m_1m_2m_3}{3}$ uniquely labeled robots with uniformly randomly distributed start and goal configurations within a makespan of $m_1 + 2m_2 +2m_3+o(m_1)$, with high probability. Because the makespan lower bound for such instances is $m_1 + m_2+m_3 - o(m_1)$, also with high probability, as $m_1 \to \infty$, $\frac{m_1+2m_2+2m_3}{m_1+m_2+m_3}$ optimality guarantee is achieved. $\frac{m_1+2m_2+2m_3}{m_1+m_2+m_3} \in (1, \frac{5}{3}]$, yielding $1.x$ optimality. In contrast, it is well-known that multi-robot path planning is NP-hard to optimally solve. In numerical evaluations, our method readily scales to support the motion planning of over $100,000$ robots in 3D while simultaneously achieving $1.x$ optimality. We demonstrate the application of our method in coordinating many quadcopters in both simulation and hardware experiments.
ZeroC: A Neuro-Symbolic Model for Zero-shot Concept Recognition and Acquisition at Inference Time
Jun 30, 2022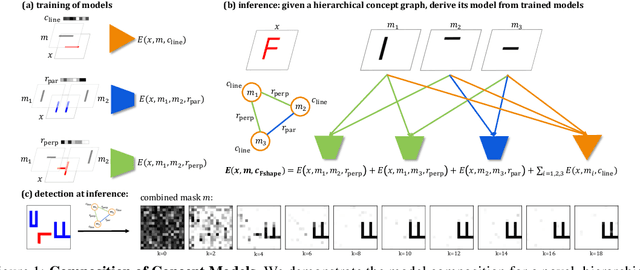
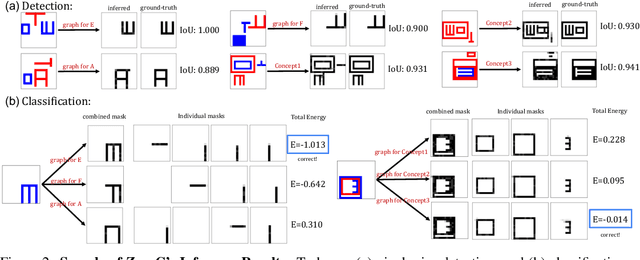
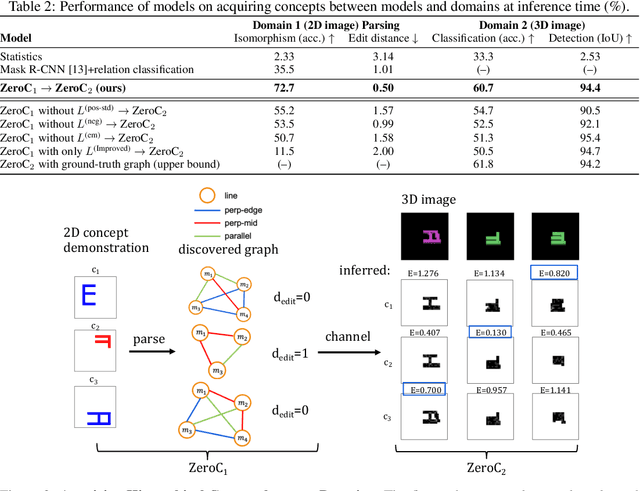
Humans have the remarkable ability to recognize and acquire novel visual concepts in a zero-shot manner. Given a high-level, symbolic description of a novel concept in terms of previously learned visual concepts and their relations, humans can recognize novel concepts without seeing any examples. Moreover, they can acquire new concepts by parsing and communicating symbolic structures using learned visual concepts and relations. Endowing these capabilities in machines is pivotal in improving their generalization capability at inference time. In this work, we introduce Zero-shot Concept Recognition and Acquisition (ZeroC), a neuro-symbolic architecture that can recognize and acquire novel concepts in a zero-shot way. ZeroC represents concepts as graphs of constituent concept models (as nodes) and their relations (as edges). To allow inference time composition, we employ energy-based models (EBMs) to model concepts and relations. We design ZeroC architecture so that it allows a one-to-one mapping between a symbolic graph structure of a concept and its corresponding EBM, which for the first time, allows acquiring new concepts, communicating its graph structure, and applying it to classification and detection tasks (even across domains) at inference time. We introduce algorithms for learning and inference with ZeroC. We evaluate ZeroC on a challenging grid-world dataset which is designed to probe zero-shot concept recognition and acquisition, and demonstrate its capability.
Invariance to Quantile Selection in Distributional Continuous Control
Dec 29, 2022
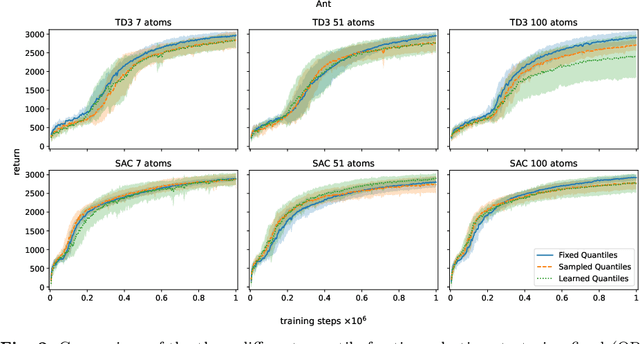
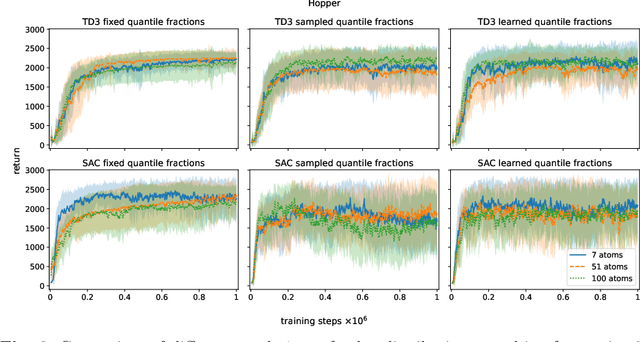
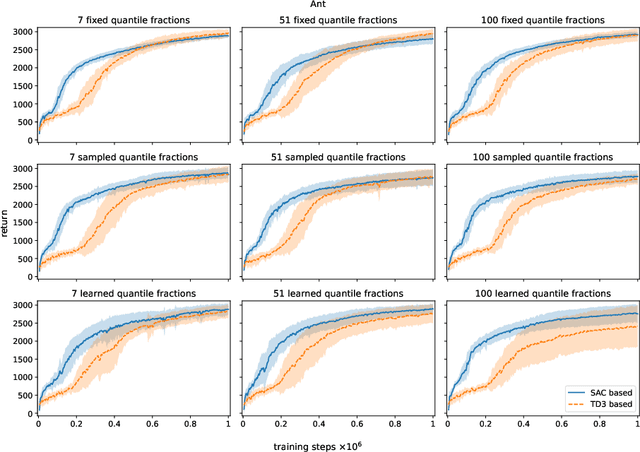
In recent years distributional reinforcement learning has produced many state of the art results. Increasingly sample efficient Distributional algorithms for the discrete action domain have been developed over time that vary primarily in the way they parameterize their approximations of value distributions, and how they quantify the differences between those distributions. In this work we transfer three of the most well-known and successful of those algorithms (QR-DQN, IQN and FQF) to the continuous action domain by extending two powerful actor-critic algorithms (TD3 and SAC) with distributional critics. We investigate whether the relative performance of the methods for the discrete action space translates to the continuous case. To that end we compare them empirically on the pybullet implementations of a set of continuous control tasks. Our results indicate qualitative invariance regarding the number and placement of distributional atoms in the deterministic, continuous action setting.
Imaging the time series of one single referenced EEG electrode for Epileptic Seizures Risk Analysis
Jun 29, 2022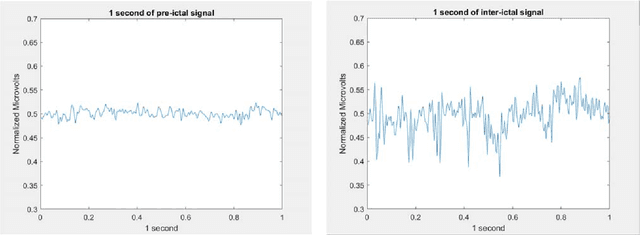



The time series captured by a single scalp electrode (plus the reference electrode) of refractory epileptic patients is used to forecast seizures susceptibility. The time series is preprocessed, segmented, and each segment transformed into an image, using three different known methods: Recurrence Plot, Gramian Angular Field, Markov Transition Field. The likelihood of the occurrence of a seizure in a future predefined time window is computed by averaging the output of the softmax layer of a CNN, differently from the usual consideration of the output of the classification layer. By thresholding this likelihood, seizure forecasting has better performance. Interestingly, for almost every patient, the best threshold was different from 50%. The results show that this technique can predict with good results for some seizures and patients. However, more tests, namely more patients and more seizures, are needed to better understand the real potential of this technique.
Sound Localization by Self-Supervised Time Delay Estimation
Apr 26, 2022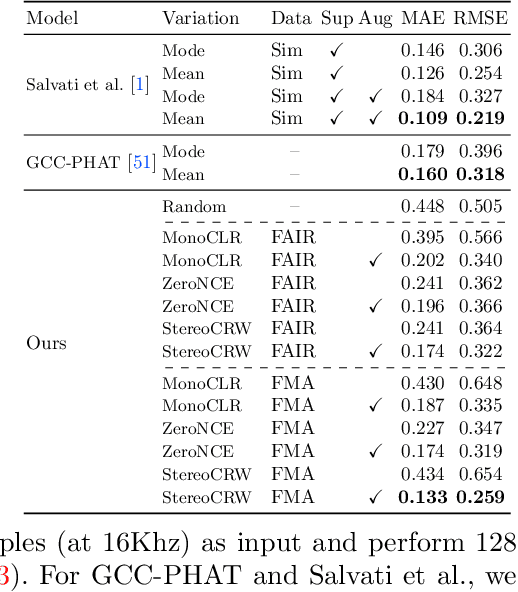
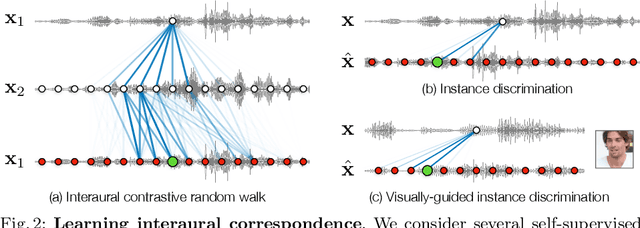
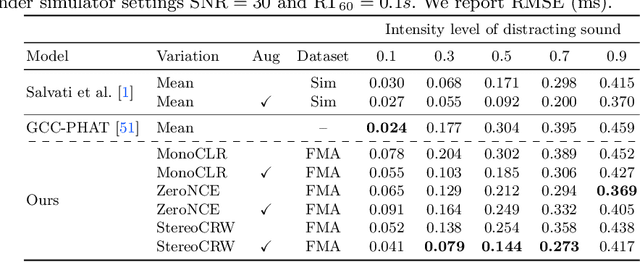

Sounds reach one microphone in a stereo pair sooner than the other, resulting in an interaural time delay that conveys their directions. Estimating a sound's time delay requires finding correspondences between the signals recorded by each microphone. We propose to learn these correspondences through self-supervision, drawing on recent techniques from visual tracking. We adapt the contrastive random walk of Jabri et al. to learn a cycle-consistent representation from unlabeled stereo sounds, resulting in a model that performs on par with supervised methods on "in the wild" internet recordings. We also propose a multimodal contrastive learning model that solves a visually-guided localization task: estimating the time delay for a particular person in a multi-speaker mixture, given a visual representation of their face. Project site: https://ificl.github.io/stereocrw/
AdverSAR: Adversarial Search and Rescue via Multi-Agent Reinforcement Learning
Dec 20, 2022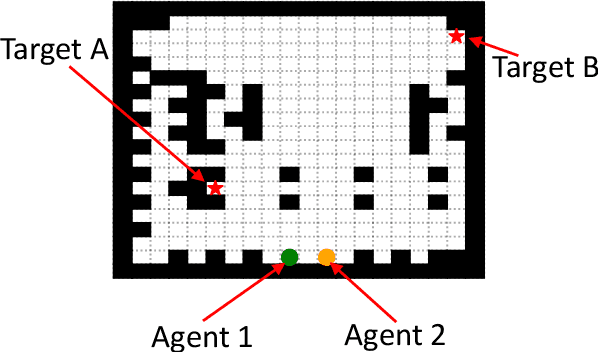
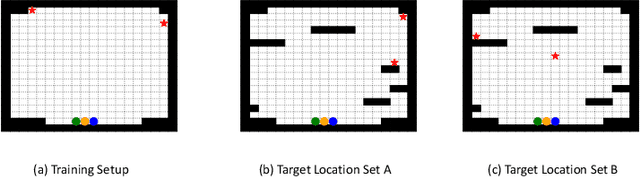
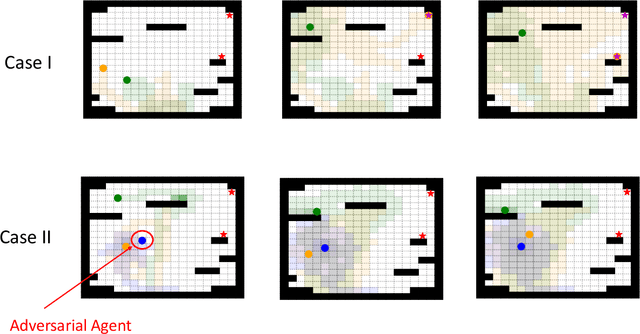
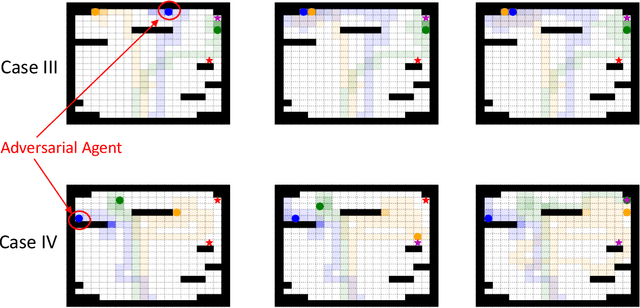
Search and Rescue (SAR) missions in remote environments often employ autonomous multi-robot systems that learn, plan, and execute a combination of local single-robot control actions, group primitives, and global mission-oriented coordination and collaboration. Often, SAR coordination strategies are manually designed by human experts who can remotely control the multi-robot system and enable semi-autonomous operations. However, in remote environments where connectivity is limited and human intervention is often not possible, decentralized collaboration strategies are needed for fully-autonomous operations. Nevertheless, decentralized coordination may be ineffective in adversarial environments due to sensor noise, actuation faults, or manipulation of inter-agent communication data. In this paper, we propose an algorithmic approach based on adversarial multi-agent reinforcement learning (MARL) that allows robots to efficiently coordinate their strategies in the presence of adversarial inter-agent communications. In our setup, the objective of the multi-robot team is to discover targets strategically in an obstacle-strewn geographical area by minimizing the average time needed to find the targets. It is assumed that the robots have no prior knowledge of the target locations, and they can interact with only a subset of neighboring robots at any time. Based on the centralized training with decentralized execution (CTDE) paradigm in MARL, we utilize a hierarchical meta-learning framework to learn dynamic team-coordination modalities and discover emergent team behavior under complex cooperative-competitive scenarios. The effectiveness of our approach is demonstrated on a collection of prototype grid-world environments with different specifications of benign and adversarial agents, target locations, and agent rewards.
CLIP is Also an Efficient Segmenter: A Text-Driven Approach for Weakly Supervised Semantic Segmentation
Dec 20, 2022
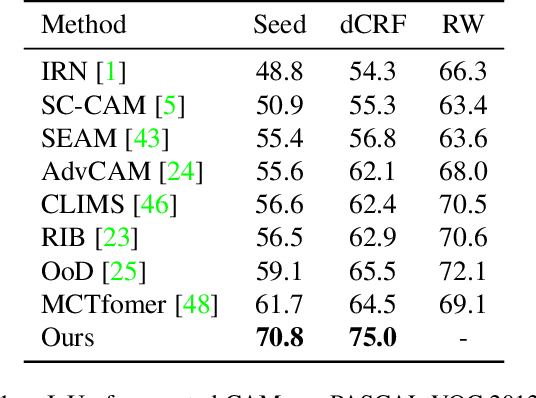
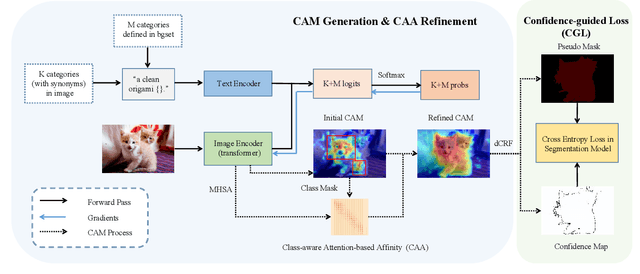
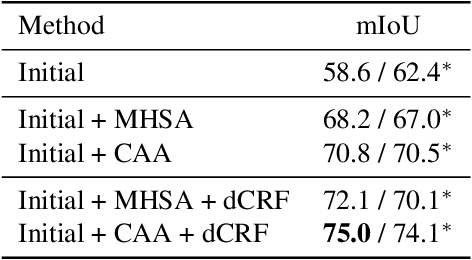
Weakly supervised semantic segmentation (WSSS) with image-level labels is a challenging task in computer vision. Mainstream approaches follow a multi-stage framework and suffer from high training costs. In this paper, we explore the potential of Contrastive Language-Image Pre-training models (CLIP) to localize different categories with only image-level labels and without any further training. To efficiently generate high-quality segmentation masks from CLIP, we propose a novel framework called CLIP-ES for WSSS. Our framework improves all three stages of WSSS with special designs for CLIP: 1) We introduce the softmax function into GradCAM and exploit the zero-shot ability of CLIP to suppress the confusion caused by non-target classes and backgrounds. Meanwhile, to take full advantage of CLIP, we re-explore text inputs under the WSSS setting and customize two text-driven strategies: sharpness-based prompt selection and synonym fusion. 2) To simplify the stage of CAM refinement, we propose a real-time class-aware attention-based affinity (CAA) module based on the inherent multi-head self-attention (MHSA) in CLIP-ViTs. 3) When training the final segmentation model with the masks generated by CLIP, we introduced a confidence-guided loss (CGL) to mitigate noise and focus on confident regions. Our proposed framework dramatically reduces the cost of training for WSSS and shows the capability of localizing objects in CLIP. Our CLIP-ES achieves SOTA performance on Pascal VOC 2012 and MS COCO 2014 while only taking 10% time of previous methods for the pseudo mask generation. Code is available at https://github.com/linyq2117/CLIP-ES.
Revisiting Realistic Test-Time Training: Sequential Inference and Adaptation by Anchored Clustering
Jun 06, 2022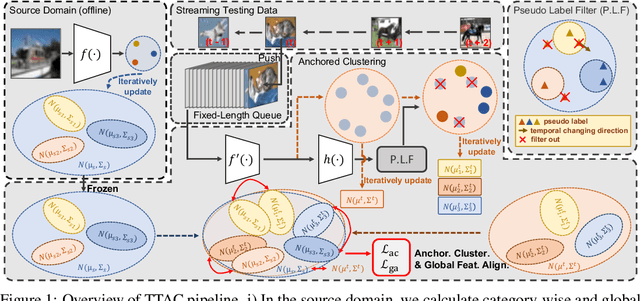
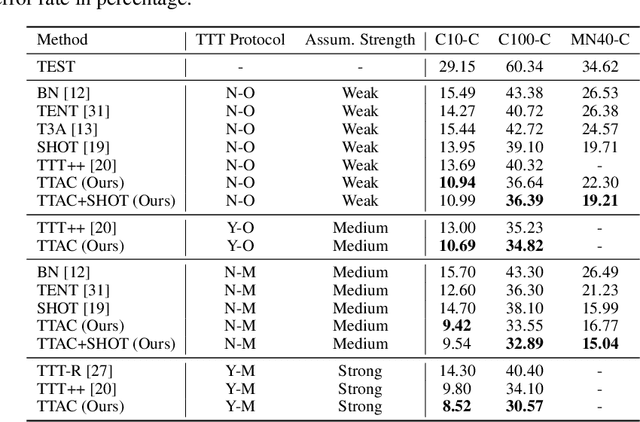
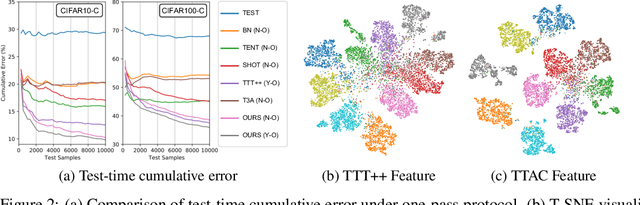
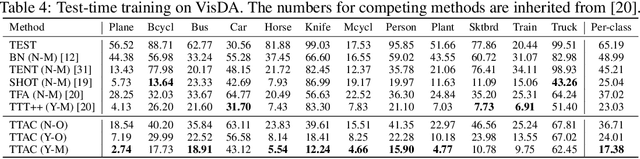
Deploying models on target domain data subject to distribution shift requires adaptation. Test-time training (TTT) emerges as a solution to this adaptation under a realistic scenario where access to full source domain data is not available and instant inference on target domain is required. Despite many efforts into TTT, there is a confusion over the experimental settings, thus leading to unfair comparisons. In this work, we first revisit TTT assumptions and categorize TTT protocols by two key factors. Among the multiple protocols, we adopt a realistic sequential test-time training (sTTT) protocol, under which we further develop a test-time anchored clustering (TTAC) approach to enable stronger test-time feature learning. TTAC discovers clusters in both source and target domain and match the target clusters to the source ones to improve generalization. Pseudo label filtering and iterative updating are developed to improve the effectiveness and efficiency of anchored clustering. We demonstrate that under all TTT protocols TTAC consistently outperforms the state-of-the-art methods on five TTT datasets. We hope this work will provide a fair benchmarking of TTT methods and future research should be compared within respective protocols. A demo code is available at https://github.com/Gorilla-Lab-SCUT/TTAC.
Learning State Transition Rules from Hidden Layers of Restricted Boltzmann Machines
Dec 07, 2022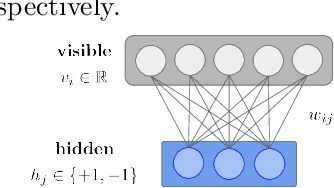
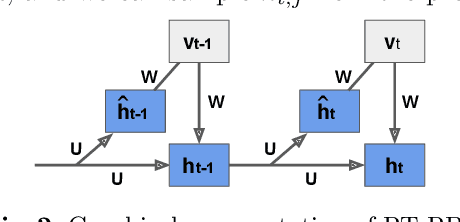

Understanding the dynamics of a system is important in many scientific and engineering domains. This problem can be approached by learning state transition rules from observations using machine learning techniques. Such observed time-series data often consist of sequences of many continuous variables with noise and ambiguity, but we often need rules of dynamics that can be modeled with a few essential variables. In this work, we propose a method for extracting a small number of essential hidden variables from high-dimensional time-series data and for learning state transition rules between these hidden variables. The proposed method is based on the Restricted Boltzmann Machine (RBM), which treats observable data in the visible layer and latent features in the hidden layer. However, real-world data, such as video and audio, include both discrete and continuous variables, and these variables have temporal relationships. Therefore, we propose Recurrent Temporal GaussianBernoulli Restricted Boltzmann Machine (RTGB-RBM), which combines Gaussian-Bernoulli Restricted Boltzmann Machine (GB-RBM) to handle continuous visible variables, and Recurrent Temporal Restricted Boltzmann Machine (RT-RBM) to capture time dependence between discrete hidden variables. We also propose a rule-based method that extracts essential information as hidden variables and represents state transition rules in interpretable form. We conduct experiments on Bouncing Ball and Moving MNIST datasets to evaluate our proposed method. Experimental results show that our method can learn the dynamics of those physical systems as state transition rules between hidden variables and can predict unobserved future states from observed state transitions.