 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MMSR: Symbolic Regression is a Multimodal Task
Mar 14, 2024
Mathematical formulas are the crystallization of human wisdom in exploring the laws of nature for thousands of years. Describing the complex laws of nature with a concise mathematical formula is a constant pursuit of scientists and a great challenge for artificial intelligence. This field is called symbolic regression. Symbolic regression was originally formulated as a combinatorial optimization problem, and GP and reinforcement learning algorithms were used to solve it. However, GP is sensitive to hyperparameters, and these two types of algorithms are inefficient. To solve this problem, researchers treat the mapping from data to expressions as a translation problem. And the corresponding large-scale pre-trained model is introduced. However, the data and expression skeletons do not have very clear word correspondences as the two languages do. Instead, they are more like two modalities (e.g., image and text). Therefore, in this paper, we proposed MMSR. The SR problem is solved as a pure multimodal problem, and contrastive learning is also introduced in the training process for modal alignment to facilitate later modal feature fusion. It is worth noting that in order to better promote the modal feature fusion, we adopt the strategy of training contrastive learning loss and other losses at the same time, which only needs one-step training, instead of training contrastive learning loss first and then training other losses. Because our experiments prove training together can make the feature extraction module and feature fusion module running-in better. Experimental results show that compared with multiple large-scale pre-training baselines, MMSR achieves the most advanced results on multiple mainstream datasets including SRBench.
A Survey of Vision Transformers in Autonomous Driving: Current Trends and Future Directions
Mar 12, 2024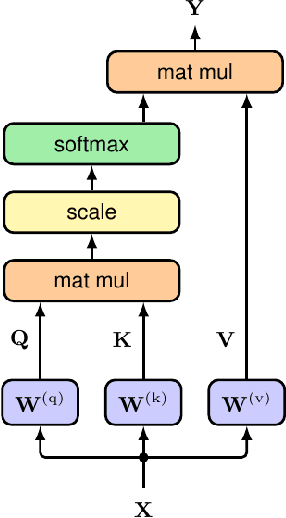
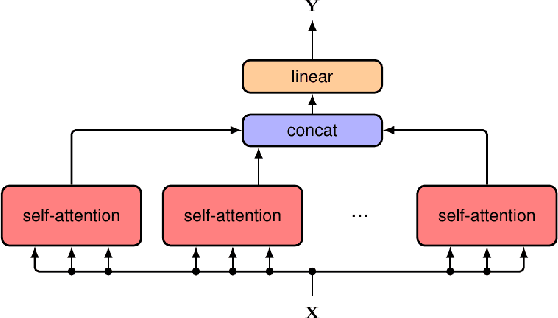
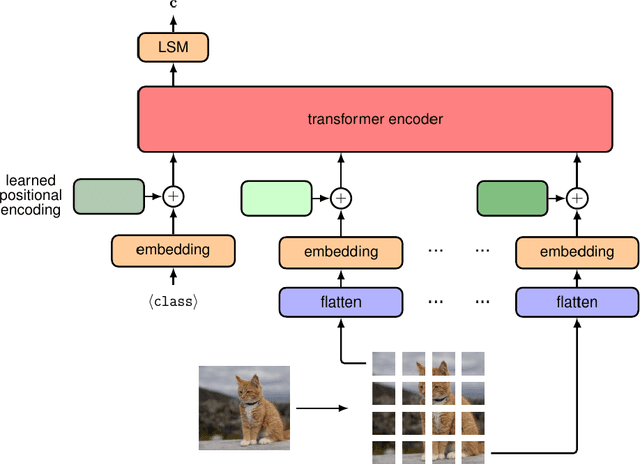
This survey explores the adaptation of visual transformer models in Autonomous Driving, a transition inspired by their success in Natural Language Processing. Surpassing traditional Recurrent Neural Networks in tasks like sequential image processing and outperforming Convolutional Neural Networks in global context capture, as evidenced in complex scene recognition, Transformers are gaining traction in computer vision. These capabilities are crucial in Autonomous Driving for real-time, dynamic visual scene processing. Our survey provides a comprehensive overview of Vision Transformer applications in Autonomous Driving, focusing on foundational concepts such as self-attention, multi-head attention, and encoder-decoder architecture. We cover applications in object detection, segmentation, pedestrian detection, lane detection, and more, comparing their architectural merits and limitations. The survey concludes with future research directions, highlighting the growing role of Vision Transformers in Autonomous Driving.
Smooth Computation without Input Delay: Robust Tube-Based Model Predictive Control for Robot Manipulator Planning
Mar 09, 2024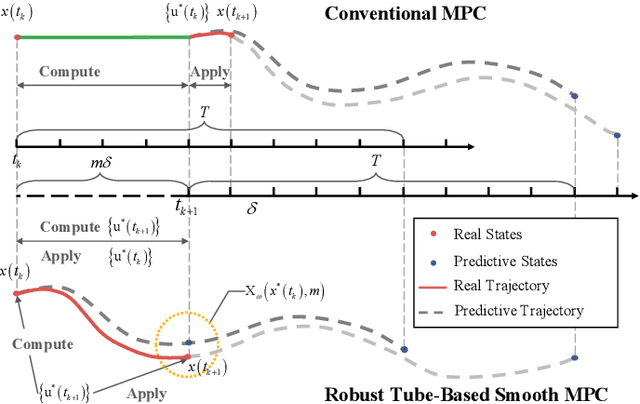
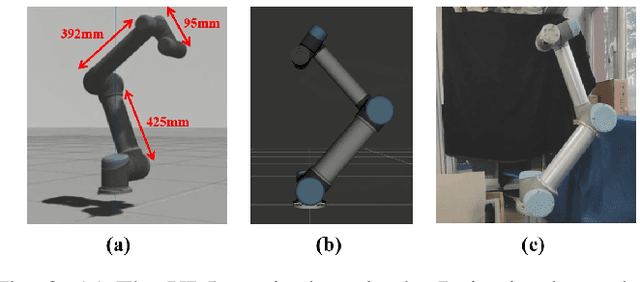
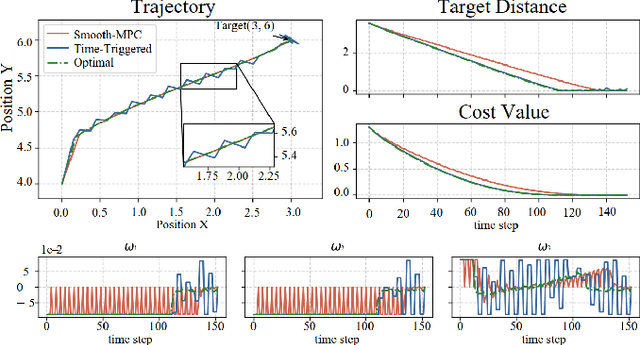
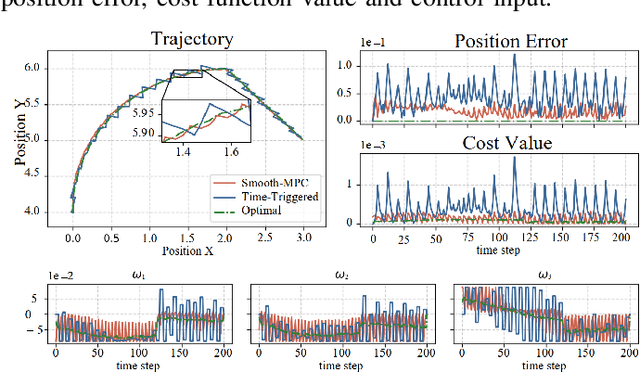
Model Predictive Control (MPC) has exhibited remarkable capabilities in optimizing objectives and meeting constraints. However, the substantial computational burden associated with solving the Optimal Control Problem (OCP) at each triggering instant introduces significant delays between state sampling and control application. These delays limit the practicality of MPC in resource-constrained systems when engaging in complex tasks. The intuition to address this issue in this paper is that by predicting the successor state, the controller can solve the OCP one time step ahead of time thus avoiding the delay of the next action. To this end, we compute deviations between real and nominal system states, predicting forthcoming real states as initial conditions for the imminent OCP solution. Anticipatory computation stores optimal control based on current nominal states, thus mitigating the delay effects. Additionally, we establish an upper bound for linearization error, effectively linearizing the nonlinear system, reducing OCP complexity, and enhancing response speed. We provide empirical validation through two numerical simulations and corresponding real-world robot tasks, demonstrating significant performance improvements and augmented response speed (up to $90\%$) resulting from the seamless integration of our proposed approach compared to conventional time-triggered MPC strategies.
RL-MSA: a Reinforcement Learning-based Multi-line bus Scheduling Approach
Mar 11, 2024Multiple Line Bus Scheduling Problem (MLBSP) is vital to save operational cost of bus company and guarantee service quality for passengers. Existing approaches typically generate a bus scheduling scheme in an offline manner and then schedule buses according to the scheme. In practice, uncertain events such as traffic congestion occur frequently, which may make the pre-determined bus scheduling scheme infeasible. In this paper, MLBSP is modeled as a Markov Decision Process (MDP). A Reinforcement Learning-based Multi-line bus Scheduling Approach (RL-MSA) is proposed for bus scheduling at both the offline and online phases. At the offline phase, deadhead decision is integrated into bus selection decision for the first time to simplify the learning problem. At the online phase, deadhead decision is made through a time window mechanism based on the policy learned at the offline phase. We develop several new and useful state features including the features for control points, bus lines and buses. A bus priority screening mechanism is invented to construct bus-related features. Considering the interests of both the bus company and passengers, a reward function combining the final reward and the step-wise reward is devised. Experiments at the offline phase demonstrate that the number of buses used of RL-MSA is decreased compared with offline optimization approaches. At the online phase, RL-MSA can cover all departure times in a timetable (i.e., service quality) without increasing the number of buses used (i.e., operational cost).
Pfeed: Generating near real-time personalized feeds using precomputed embedding similarities
Feb 25, 2024In personalized recommender systems, embeddings are often used to encode customer actions and items, and retrieval is then performed in the embedding space using approximate nearest neighbor search. However, this approach can lead to two challenges: 1) user embeddings can restrict the diversity of interests captured and 2) the need to keep them up-to-date requires an expensive, real-time infrastructure. In this paper, we propose a method that overcomes these challenges in a practical, industrial setting. The method dynamically updates customer profiles and composes a feed every two minutes, employing precomputed embeddings and their respective similarities. We tested and deployed this method to personalise promotional items at Bol, one of the largest e-commerce platforms of the Netherlands and Belgium. The method enhanced customer engagement and experience, leading to a significant 4.9% uplift in conversions.
Predicting Generalization of AI Colonoscopy Models to Unseen Data
Mar 14, 2024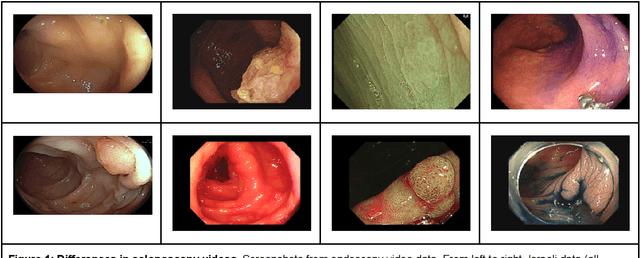
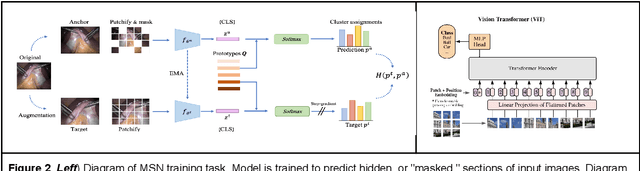
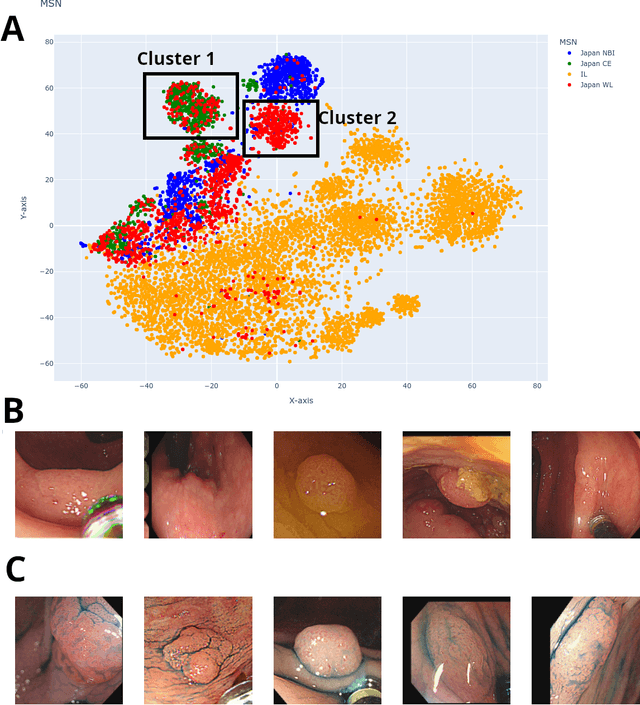
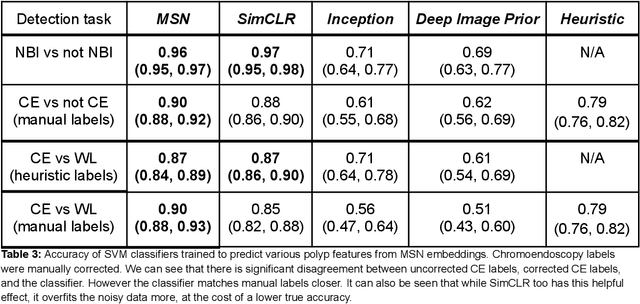
Background and aims Generalizability of AI colonoscopy algorithms is important for wider adoption in clinical practice. However, current techniques for evaluating performance on unseen data require expensive and time-intensive labels. Methods We use a "Masked Siamese Network" (MSN) to identify novel phenomena in unseen data and predict polyp detector performance. MSN is trained to predict masked out regions of polyp images, without any labels. We test MSN's ability to be trained on data only from Israel and detect unseen techniques, narrow-band imaging (NBI) and chromendoscoy (CE), on colonoscopes from Japan (354 videos, 128 hours). We also test MSN's ability to predict performance of Computer Aided Detection (CADe) of polyps on colonoscopies from both countries, even though MSN is not trained on data from Japan. Results MSN correctly identifies NBI and CE as less similar to Israel whitelight than Japan whitelight (bootstrapped z-test, |z| > 496, p < 10-8 for both) using the label-free Frechet distance. MSN detects NBI with 99% accuracy, predicts CE better than our heuristic (90% vs 79% accuracy) despite being trained only on whitelight, and is the only method that is robust to noisy labels. MSN predicts CADe polyp detector performance on in-domain Israel and out-of-domain Japan colonoscopies (r=0.79, 0.37 respectively). With few examples of Japan detector performance to train on, MSN prediction of Japan performance improves (r=0.56). Conclusion Our technique can identify distribution shifts in clinical data and can predict CADe detector performance on unseen data, without labels. Our self-supervised approach can aid in detecting when data in practice is different from training, such as between hospitals or data has meaningfully shifted from training. MSN has potential for application to medical image domains beyond colonoscopy.
A Survey of Lottery Ticket Hypothesis
Mar 12, 2024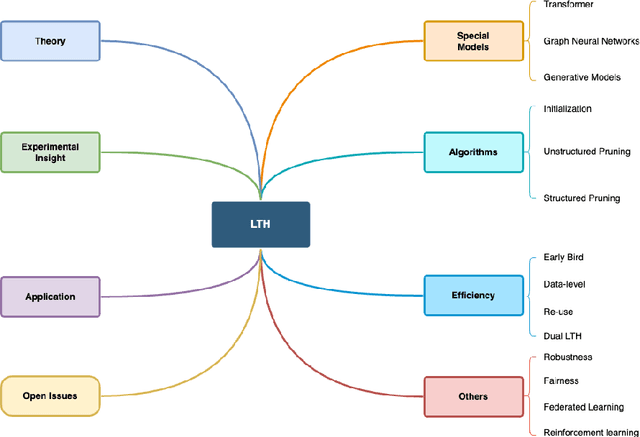
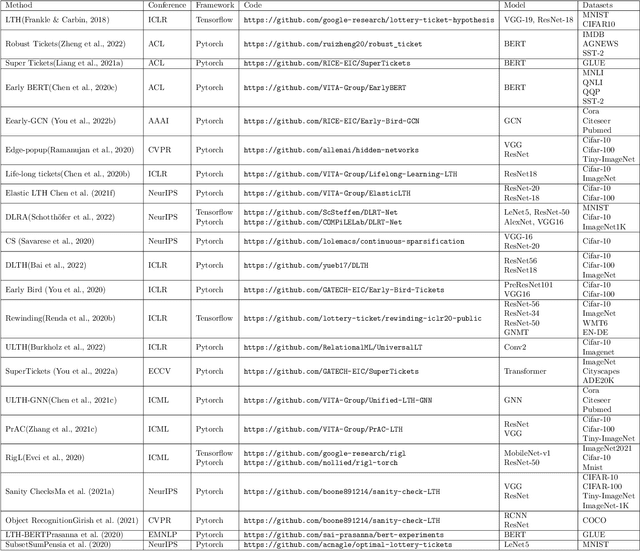
The Lottery Ticket Hypothesis (LTH) states that a dense neural network model contains a highly sparse subnetwork (i.e., winning tickets) that can achieve even better performance than the original model when trained in isolation. While LTH has been proved both empirically and theoretically in many works, there still are some open issues, such as efficiency and scalability, to be addressed. Also, the lack of open-source frameworks and consensual experimental setting poses a challenge to future research on LTH. We, for the first time, examine previous research and studies on LTH from different perspectives. We also discuss issues in existing works and list potential directions for further exploration. This survey aims to provide an in-depth look at the state of LTH and develop a duly maintained platform to conduct experiments and compare with the most updated baselines.
General surgery vision transformer: A video pre-trained foundation model for general surgery
Mar 12, 2024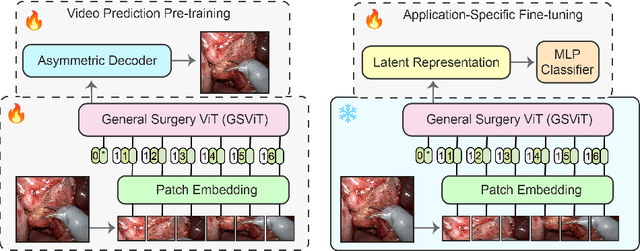
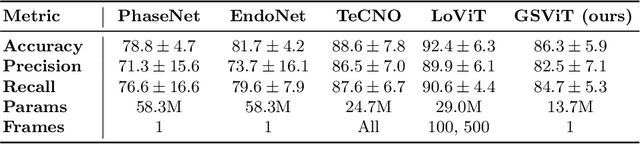
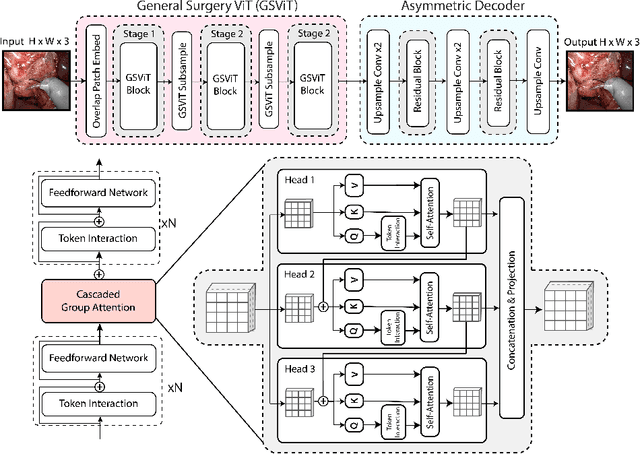
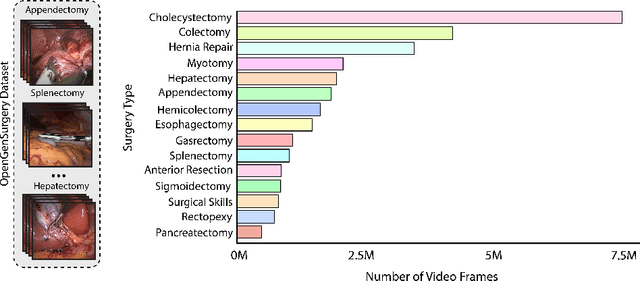
The absence of openly accessible data and specialized foundation models is a major barrier for computational research in surgery. Toward this, (i) we open-source the largest dataset of general surgery videos to-date, consisting of 680 hours of surgical videos, including data from robotic and laparoscopic techniques across 28 procedures; (ii) we propose a technique for video pre-training a general surgery vision transformer (GSViT) on surgical videos based on forward video prediction that can run in real-time for surgical applications, toward which we open-source the code and weights of GSViT; (iii) we also release code and weights for procedure-specific fine-tuned versions of GSViT across 10 procedures; (iv) we demonstrate the performance of GSViT on the Cholec80 phase annotation task, displaying improved performance over state-of-the-art single frame predictors.
Polynormer: Polynomial-Expressive Graph Transformer in Linear Time
Mar 02, 2024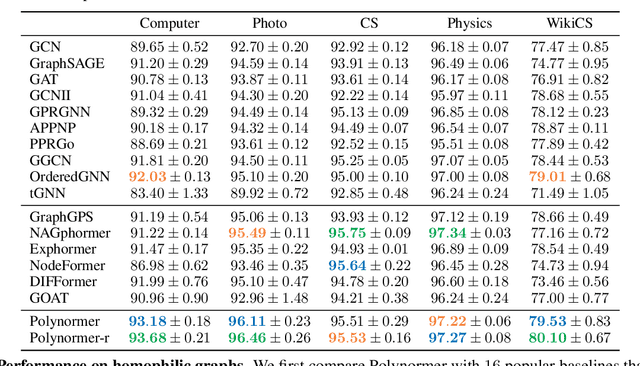
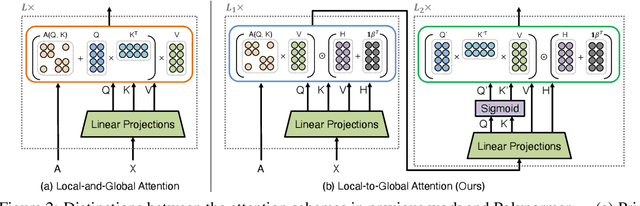
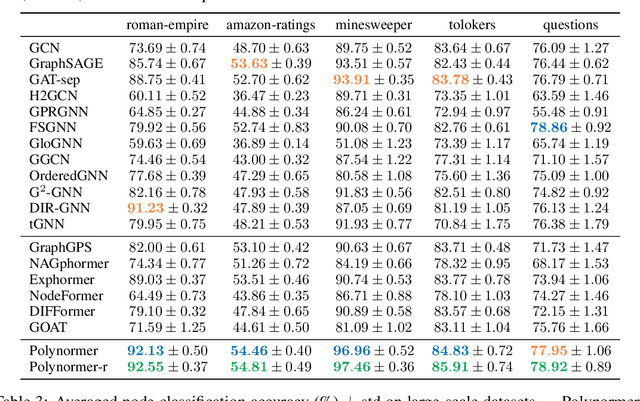
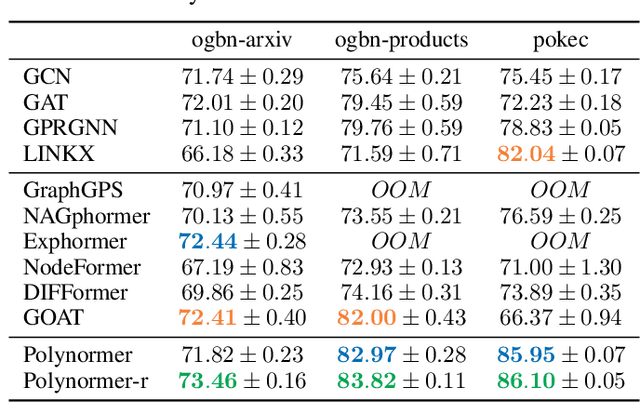
Graph transformers (GTs) have emerged as a promising architecture that is theoretically more expressive than message-passing graph neural networks (GNNs). However, typical GT models have at least quadratic complexity and thus cannot scale to large graphs. While there are several linear GTs recently proposed, they still lag behind GNN counterparts on several popular graph datasets, which poses a critical concern on their practical expressivity. To balance the trade-off between expressivity and scalability of GTs, we propose Polynormer, a polynomial-expressive GT model with linear complexity. Polynormer is built upon a novel base model that learns a high-degree polynomial on input features. To enable the base model permutation equivariant, we integrate it with graph topology and node features separately, resulting in local and global equivariant attention models. Consequently, Polynormer adopts a linear local-to-global attention scheme to learn high-degree equivariant polynomials whose coefficients are controlled by attention scores. Polynormer has been evaluated on $13$ homophilic and heterophilic datasets, including large graphs with millions of nodes. Our extensive experiment results show that Polynormer outperforms state-of-the-art GNN and GT baselines on most datasets, even without the use of nonlinear activation functions.
SWAP-NAS: Sample-Wise Activation Patterns for Ultra-fast NAS
Mar 13, 2024
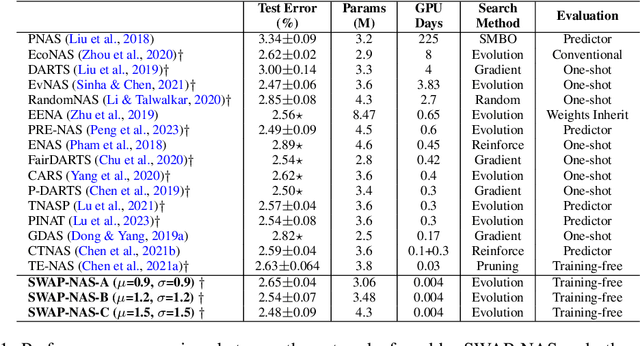

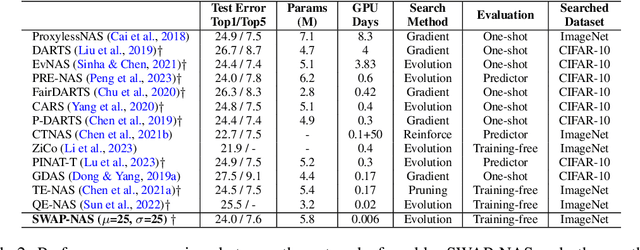
Training-free metrics (a.k.a. zero-cost proxies) are widely used to avoid resource-intensive neural network training, especially in Neural Architecture Search (NAS). Recent studies show that existing training-free metrics have several limitations, such as limited correlation and poor generalisation across different search spaces and tasks. Hence, we propose Sample-Wise Activation Patterns and its derivative, SWAP-Score, a novel high-performance training-free metric. It measures the expressivity of networks over a batch of input samples. The SWAP-Score is strongly correlated with ground-truth performance across various search spaces and tasks, outperforming 15 existing training-free metrics on NAS-Bench-101/201/301 and TransNAS-Bench-101. The SWAP-Score can be further enhanced by regularisation, which leads to even higher correlations in cell-based search space and enables model size control during the search. For example, Spearman's rank correlation coefficient between regularised SWAP-Score and CIFAR-100 validation accuracies on NAS-Bench-201 networks is 0.90, significantly higher than 0.80 from the second-best metric, NWOT. When integrated with an evolutionary algorithm for NAS, our SWAP-NAS achieves competitive performance on CIFAR-10 and ImageNet in approximately 6 minutes and 9 minutes of GPU time respectively.