 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Extractive Summarization of Emotion Triggers
Jun 02, 2023

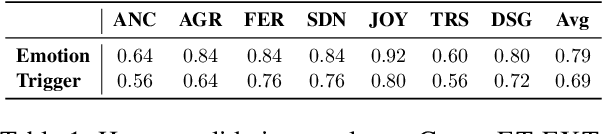
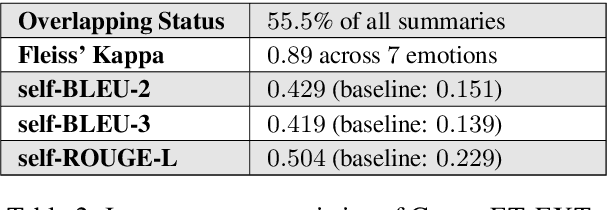
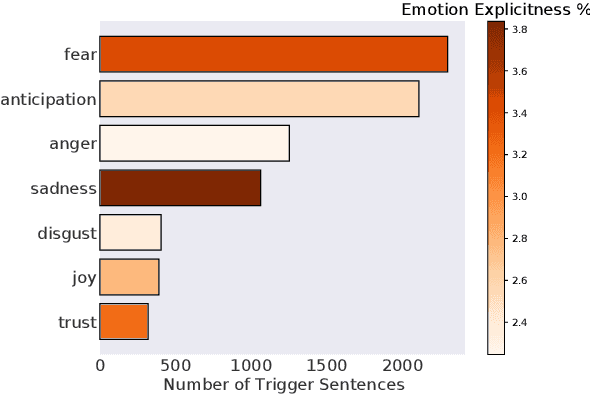
Understanding what leads to emotions during large-scale crises is important as it can provide groundings for expressed emotions and subsequently improve the understanding of ongoing disasters. Recent approaches trained supervised models to both detect emotions and explain emotion triggers (events and appraisals) via abstractive summarization. However, obtaining timely and qualitative abstractive summaries is expensive and extremely time-consuming, requiring highly-trained expert annotators. In time-sensitive, high-stake contexts, this can block necessary responses. We instead pursue unsupervised systems that extract triggers from text. First, we introduce CovidET-EXT, augmenting (Zhan et al. 2022)'s abstractive dataset (in the context of the COVID-19 crisis) with extractive triggers. Second, we develop new unsupervised learning models that can jointly detect emotions and summarize their triggers. Our best approach, entitled Emotion-Aware Pagerank, incorporates emotion information from external sources combined with a language understanding module, and outperforms strong baselines. We release our data and code at https://github.com/tsosea2/CovidET-EXT.
Système de recommandations basé sur les contraintes pour les simulations de gestion de crise
Jun 02, 2023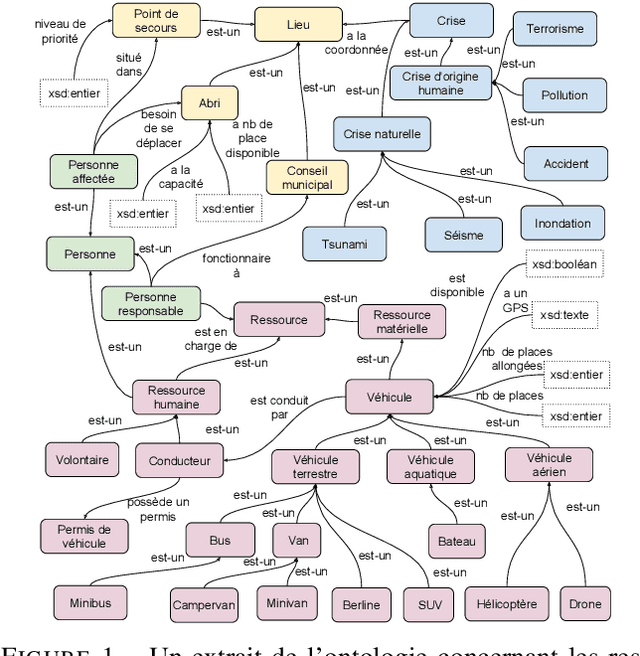
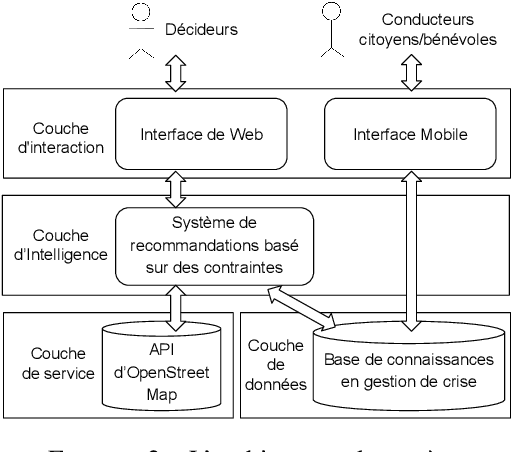
In the context of the evacuation of populations, some citizens/volunteers may want and be able to participate in the evacuation of populations in difficulty by coming to lend a hand to emergency/evacuation vehicles with their own vehicles. One way of framing these impulses of solidarity would be to be able to list in real-time the citizens/volunteers available with their vehicles (land, sea, air, etc.), to be able to geolocate them according to the risk areas to be evacuated, and adding them to the evacuation/rescue vehicles. Because it is difficult to propose an effective real-time operational system on the field in a real crisis situation, in this work, we propose to add a module for recommending driver/vehicle pairs (with their specificities) to a system of crisis management simulation. To do that, we chose to model and develop an ontology-supported constraint-based recommender system for crisis management simulations.
MOSPC: MOS Prediction Based on Pairwise Comparison
Jun 18, 2023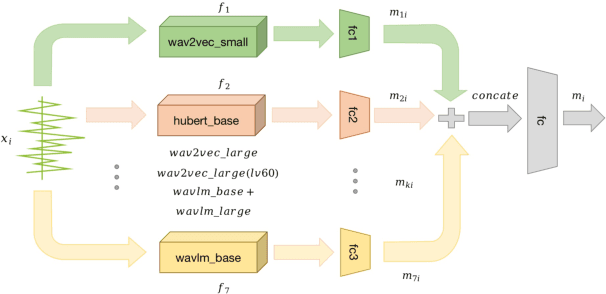

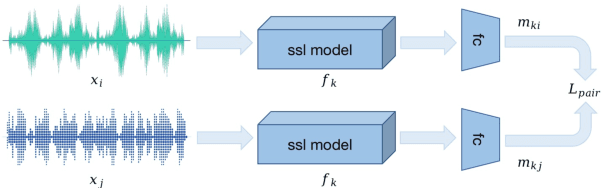
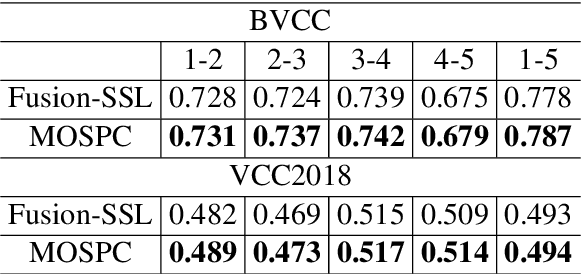
As a subjective metric to evaluate the quality of synthesized speech, Mean opinion score~(MOS) usually requires multiple annotators to score the same speech. Such an annotation approach requires a lot of manpower and is also time-consuming. MOS prediction model for automatic evaluation can significantly reduce labor cost. In previous works, it is difficult to accurately rank the quality of speech when the MOS scores are close. However, in practical applications, it is more important to correctly rank the quality of synthesis systems or sentences than simply predicting MOS scores. Meanwhile, as each annotator scores multiple audios during annotation, the score is probably a relative value based on the first or the first few speech scores given by the annotator. Motivated by the above two points, we propose a general framework for MOS prediction based on pair comparison (MOSPC), and we utilize C-Mixup algorithm to enhance the generalization performance of MOSPC. The experiments on BVCC and VCC2018 show that our framework outperforms the baselines on most of the correlation coefficient metrics, especially on the metric KTAU related to quality ranking. And our framework also surpasses the strong baseline in ranking accuracy on each fine-grained segment. These results indicate that our framework contributes to improving the ranking accuracy of speech quality.
Point-Cloud Completion with Pretrained Text-to-image Diffusion Models
Jun 18, 2023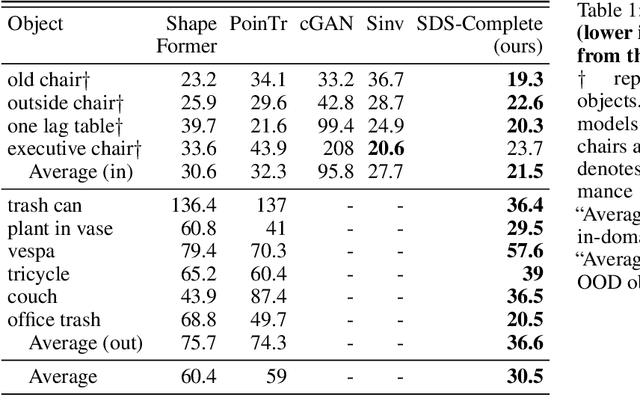
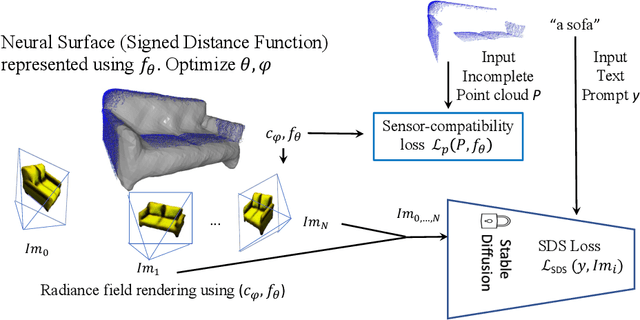
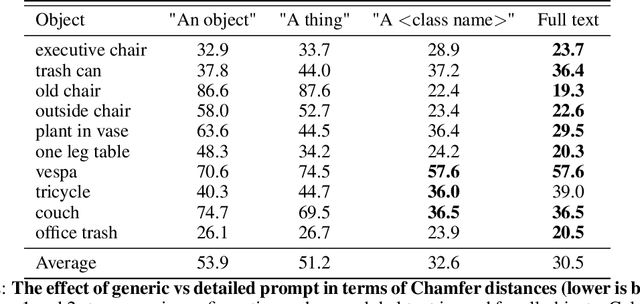

Point-cloud data collected in real-world applications are often incomplete. Data is typically missing due to objects being observed from partial viewpoints, which only capture a specific perspective or angle. Additionally, data can be incomplete due to occlusion and low-resolution sampling. Existing completion approaches rely on datasets of predefined objects to guide the completion of noisy and incomplete, point clouds. However, these approaches perform poorly when tested on Out-Of-Distribution (OOD) objects, that are poorly represented in the training dataset. Here we leverage recent advances in text-guided image generation, which lead to major breakthroughs in text-guided shape generation. We describe an approach called SDS-Complete that uses a pre-trained text-to-image diffusion model and leverages the text semantics of a given incomplete point cloud of an object, to obtain a complete surface representation. SDS-Complete can complete a variety of objects using test-time optimization without expensive collection of 3D information. We evaluate SDS Complete on incomplete scanned objects, captured by real-world depth sensors and LiDAR scanners. We find that it effectively reconstructs objects that are absent from common datasets, reducing Chamfer loss by 50% on average compared with current methods. Project page: https://sds-complete.github.io/
SRL-ORCA: A Socially Aware Multi-Agent Mapless Navigation Algorithm In Complex Dynamic Scenes
Jun 18, 2023For real-world navigation, it is important to endow robots with the capabilities to navigate safely and efficiently in a complex environment with both dynamic and non-convex static obstacles. However, achieving path-finding in non-convex complex environments without maps as well as enabling multiple robots to follow social rules for obstacle avoidance remains challenging problems. In this letter, we propose a socially aware robot mapless navigation algorithm, namely Safe Reinforcement Learning-Optimal Reciprocal Collision Avoidance (SRL-ORCA). This is a multi-agent safe reinforcement learning algorithm by using ORCA as an external knowledge to provide a safety guarantee. This algorithm further introduces traffic norms of human society to improve social comfort and achieve cooperative avoidance by following human social customs. The result of experiments shows that SRL-ORCA learns strategies to obey specific traffic rules. Compared to DRL, SRL-ORCA shows a significant improvement in navigation success rate in different complex scenarios mixed with the application of the same training network. SRL-ORCA is able to cope with non-convex obstacle environments without falling into local minimal regions and has a 14.1\% improvement in path quality (i.e., the average time to target) compared to ORCA. Videos are available at https://youtu.be/huhXfCDkGws.
In-Process Global Interpretation for Graph Learning via Distribution Matching
Jun 18, 2023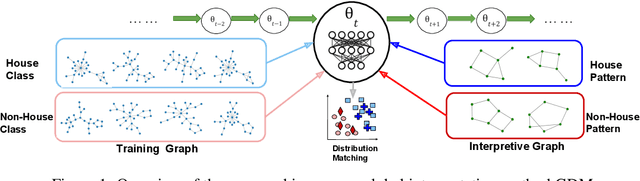
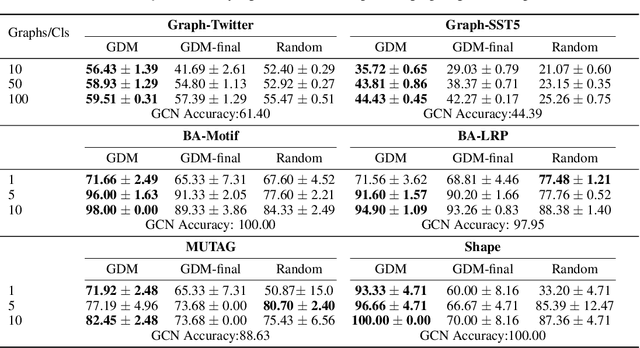

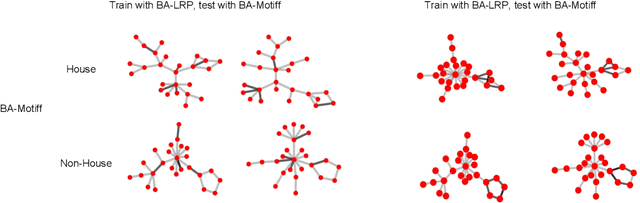
Graphs neural networks (GNNs) have emerged as a powerful graph learning model due to their superior capacity in capturing critical graph patterns. To gain insights about the model mechanism for interpretable graph learning, previous efforts focus on post-hoc local interpretation by extracting the data pattern that a pre-trained GNN model uses to make an individual prediction. However, recent works show that post-hoc methods are highly sensitive to model initialization and local interpretation can only explain the model prediction specific to a particular instance. In this work, we address these limitations by answering an important question that is not yet studied: how to provide global interpretation of the model training procedure? We formulate this problem as in-process global interpretation, which targets on distilling high-level and human-intelligible patterns that dominate the training procedure of GNNs. We further propose Graph Distribution Matching (GDM) to synthesize interpretive graphs by matching the distribution of the original and interpretive graphs in the feature space of the GNN as its training proceeds. These few interpretive graphs demonstrate the most informative patterns the model captures during training. Extensive experiments on graph classification datasets demonstrate multiple advantages of the proposed method, including high explanation accuracy, time efficiency and the ability to reveal class-relevant structure.
The Psychophysics of Human Three-Dimensional Active Visuospatial Problem-Solving
Jun 19, 2023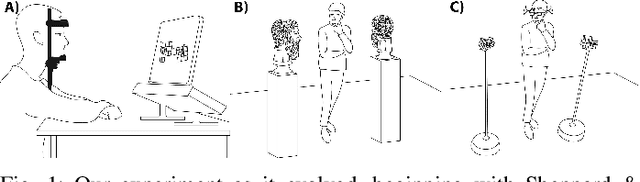
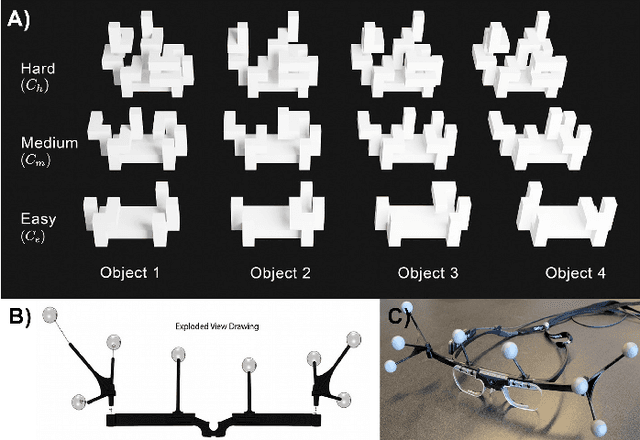
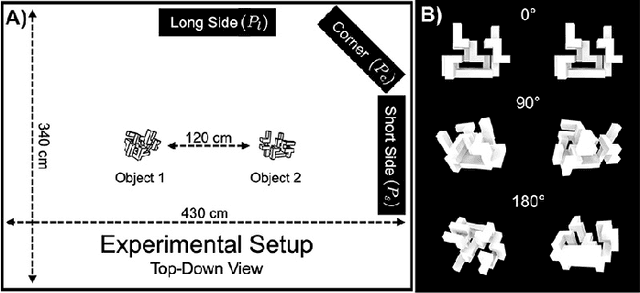
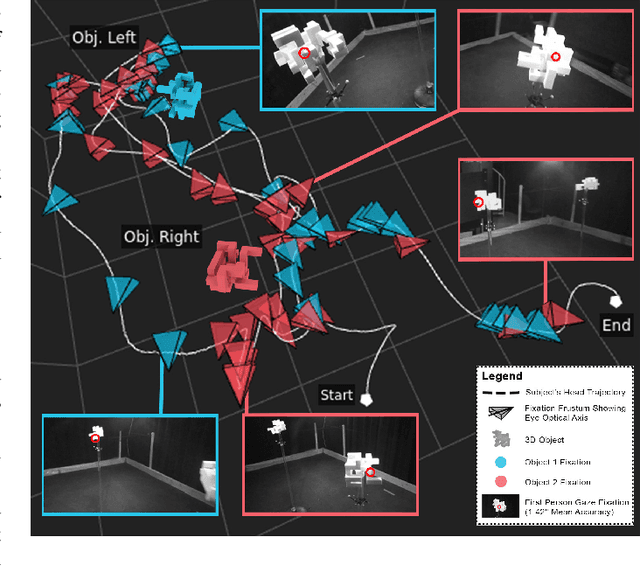
Our understanding of how visual systems detect, analyze and interpret visual stimuli has advanced greatly. However, the visual systems of all animals do much more; they enable visual behaviours. How well the visual system performs while interacting with the visual environment and how vision is used in the real world have not been well studied, especially in humans. It has been suggested that comparison is the most primitive of psychophysical tasks. Thus, as a probe into these active visual behaviours, we use a same-different task: are two physical 3D objects visually the same? This task seems to be a fundamental cognitive ability. We pose this question to human subjects who are free to move about and examine two real objects in an actual 3D space. Past work has dealt solely with a 2D static version of this problem. We have collected detailed, first-of-its-kind data of humans performing a visuospatial task in hundreds of trials. Strikingly, humans are remarkably good at this task without any training, with a mean accuracy of 93.82%. No learning effect was observed on accuracy after many trials, but some effect was seen for response time, number of fixations and extent of head movement. Subjects demonstrated a variety of complex strategies involving a range of movement and eye fixation changes, suggesting that solutions were developed dynamically and tailored to the specific task.
PowerBEV: A Powerful Yet Lightweight Framework for Instance Prediction in Bird's-Eye View
Jun 19, 2023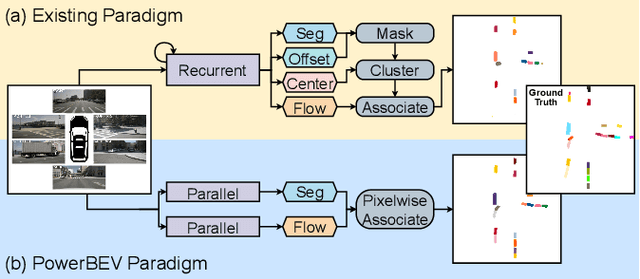
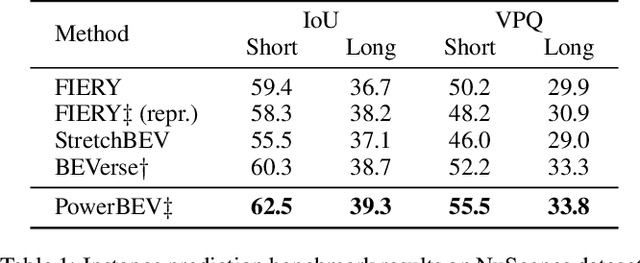
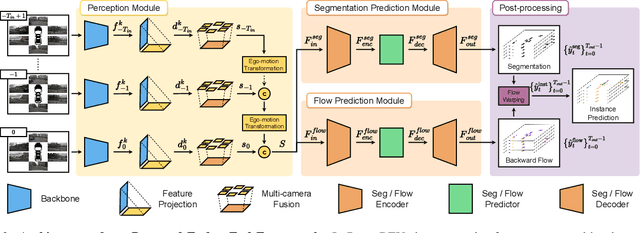

Accurately perceiving instances and predicting their future motion are key tasks for autonomous vehicles, enabling them to navigate safely in complex urban traffic. While bird's-eye view (BEV) representations are commonplace in perception for autonomous driving, their potential in a motion prediction setting is less explored. Existing approaches for BEV instance prediction from surround cameras rely on a multi-task auto-regressive setup coupled with complex post-processing to predict future instances in a spatio-temporally consistent manner. In this paper, we depart from this paradigm and propose an efficient novel end-to-end framework named POWERBEV, which differs in several design choices aimed at reducing the inherent redundancy in previous methods. First, rather than predicting the future in an auto-regressive fashion, POWERBEV uses a parallel, multi-scale module built from lightweight 2D convolutional networks. Second, we show that segmentation and centripetal backward flow are sufficient for prediction, simplifying previous multi-task objectives by eliminating redundant output modalities. Building on this output representation, we propose a simple, flow warping-based post-processing approach which produces more stable instance associations across time. Through this lightweight yet powerful design, POWERBEV outperforms state-of-the-art baselines on the NuScenes Dataset and poses an alternative paradigm for BEV instance prediction. We made our code publicly available at: https://github.com/EdwardLeeLPZ/PowerBEV.
Confidence-Based Model Selection: When to Take Shortcuts for Subpopulation Shifts
Jun 19, 2023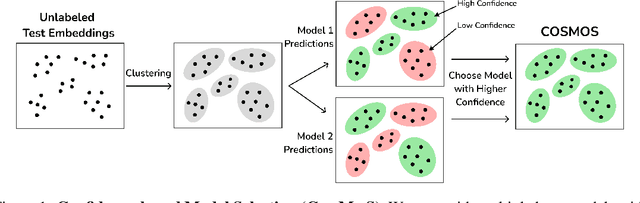

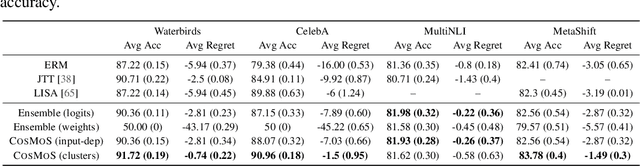
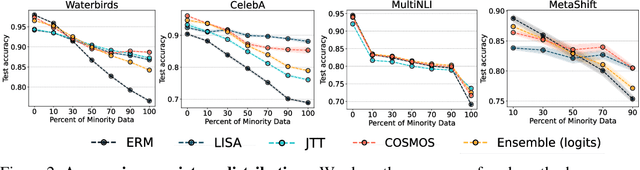
Effective machine learning models learn both robust features that directly determine the outcome of interest (e.g., an object with wheels is more likely to be a car), and shortcut features (e.g., an object on a road is more likely to be a car). The latter can be a source of error under distributional shift, when the correlations change at test-time. The prevailing sentiment in the robustness literature is to avoid such correlative shortcut features and learn robust predictors. However, while robust predictors perform better on worst-case distributional shifts, they often sacrifice accuracy on majority subpopulations. In this paper, we argue that shortcut features should not be entirely discarded. Instead, if we can identify the subpopulation to which an input belongs, we can adaptively choose among models with different strengths to achieve high performance on both majority and minority subpopulations. We propose COnfidence-baSed MOdel Selection (CosMoS), where we observe that model confidence can effectively guide model selection. Notably, CosMoS does not require any target labels or group annotations, either of which may be difficult to obtain or unavailable. We evaluate CosMoS on four datasets with spurious correlations, each with multiple test sets with varying levels of data distribution shift. We find that CosMoS achieves 2-5% lower average regret across all subpopulations, compared to using only robust predictors or other model aggregation methods.
LaDe: The First Comprehensive Last-mile Delivery Dataset from Industry
Jun 19, 2023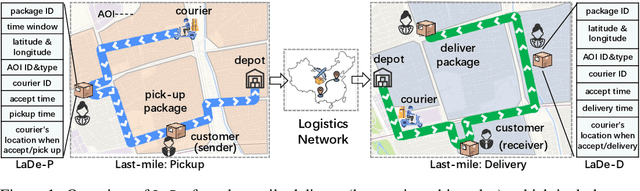

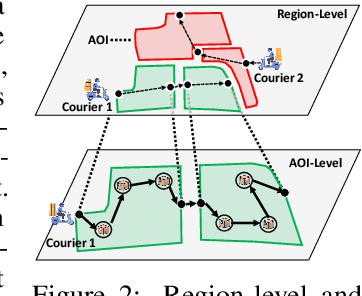
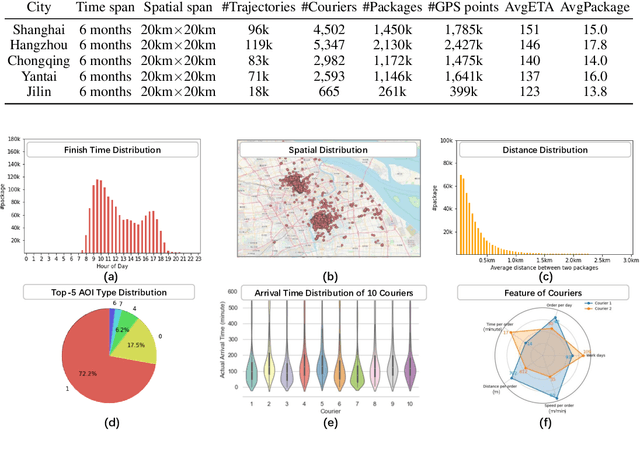
Real-world last-mile delivery datasets are crucial for research in logistics, supply chain management, and spatio-temporal data mining. Despite a plethora of algorithms developed to date, no widely accepted, publicly available last-mile delivery dataset exists to support research in this field. In this paper, we introduce \texttt{LaDe}, the first publicly available last-mile delivery dataset with millions of packages from the industry. LaDe has three unique characteristics: (1) Large-scale. It involves 10,677k packages of 21k couriers over 6 months of real-world operation. (2) Comprehensive information. It offers original package information, such as its location and time requirements, as well as task-event information, which records when and where the courier is while events such as task-accept and task-finish events happen. (3) Diversity. The dataset includes data from various scenarios, including package pick-up and delivery, and from multiple cities, each with its unique spatio-temporal patterns due to their distinct characteristics such as populations. We verify LaDe on three tasks by running several classical baseline models per task. We believe that the large-scale, comprehensive, diverse feature of LaDe can offer unparalleled opportunities to researchers in the supply chain community, data mining community, and beyond. The dataset homepage is publicly available at https://huggingface.co/datasets/Cainiao-AI/LaDe.