 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGO: Adaptive Grounding for Open World 3D Occupancy Prediction
Apr 14, 2025Open-world 3D semantic occupancy prediction aims to generate a voxelized 3D representation from sensor inputs while recognizing both known and unknown objects. Transferring open-vocabulary knowledge from vision-language models (VLMs) offers a promising direction but remains challenging. However, methods based on VLM-derived 2D pseudo-labels with traditional supervision are limited by a predefined label space and lack general prediction capabilities. Direct alignment with pretrained image embeddings, on the other hand, fails to achieve reliable performance due to often inconsistent image and text representations in VLMs. To address these challenges, we propose AGO, a novel 3D occupancy prediction framework with adaptive grounding to handle diverse open-world scenarios. AGO first encodes surrounding images and class prompts into 3D and text embeddings, respectively, leveraging similarity-based grounding training with 3D pseudo-labels. Additionally, a modality adapter maps 3D embeddings into a space aligned with VLM-derived image embeddings, reducing modality gaps. Experiments on Occ3D-nuScenes show that AGO improves unknown object prediction in zero-shot and few-shot transfer while achieving state-of-the-art closed-world self-supervised performance, surpassing prior methods by 4.09 mIoU.
TQD-Track: Temporal Query Denoising for 3D Multi-Object Tracking
Apr 04, 2025Query denoising has become a standard training strategy for DETR-based detectors by addressing the slow convergence issue. Besides that, query denoising can be used to increase the diversity of training samples for modeling complex scenarios which is critical for Multi-Object Tracking (MOT), showing its potential in MOT application. Existing approaches integrate query denoising within the tracking-by-attention paradigm. However, as the denoising process only happens within the single frame, it cannot benefit the tracker to learn temporal-related information. In addition, the attention mask in query denoising prevents information exchange between denoising and object queries, limiting its potential in improving association using self-attention. To address these issues, we propose TQD-Track, which introduces Temporal Query Denoising (TQD) tailored for MOT, enabling denoising queries to carry temporal information and instance-specific feature representation. We introduce diverse noise types onto denoising queries that simulate real-world challenges in MOT. We analyze our proposed TQD for different tracking paradigms, and find out the paradigm with explicit learned data association module, e.g. tracking-by-detection or alternating detection and association, benefit from TQD by a larger margin. For these paradigms, we further design an association mask in the association module to ensure the consistent interaction between track and detection queries as during inference. Extensive experiments on the nuScenes dataset demonstrate that our approach consistently enhances different tracking methods by only changing the training process, especially the paradigms with explicit association module.
ADA-Track: End-to-End Multi-Camera 3D Multi-Object Tracking with Alternating Detection and Association
May 14, 2024Many query-based approaches for 3D Multi-Object Tracking (MOT) adopt the tracking-by-attention paradigm, utilizing track queries for identity-consistent detection and object queries for identity-agnostic track spawning. Tracking-by-attention, however, entangles detection and tracking queries in one embedding for both the detection and tracking task, which is sub-optimal. Other approaches resemble the tracking-by-detection paradigm, detecting objects using decoupled track and detection queries followed by a subsequent association. These methods, however, do not leverage synergies between the detection and association task. Combining the strengths of both paradigms, we introduce ADA-Track, a novel end-to-end framework for 3D MOT from multi-view cameras. We introduce a learnable data association module based on edge-augmented cross-attention, leveraging appearance and geometric features. Furthermore, we integrate this association module into the decoder layer of a DETR-based 3D detector, enabling simultaneous DETR-like query-to-image cross-attention for detection and query-to-query cross-attention for data association. By stacking these decoder layers, queries are refined for the detection and association task alternately, effectively harnessing the task dependencies. We evaluate our method on the nuScenes dataset and demonstrate the advantage of our approach compared to the two previous paradigms. Code is available at https://github.com/dsx0511/ADA-Track.
3DMOTFormer: Graph Transformer for Online 3D Multi-Object Tracking
Aug 12, 2023Tracking 3D objects accurately and consistently is crucial for autonomous vehicles, enabling more reliable downstream tasks such as trajectory prediction and motion planning. Based on the substantial progress in object detection in recent years, the tracking-by-detection paradigm has become a popular choice due to its simplicity and efficiency. State-of-the-art 3D multi-object tracking (MOT) approaches typically rely on non-learned model-based algorithms such as Kalman Filter but require many manually tuned parameters. On the other hand, learning-based approaches face the problem of adapting the training to the online setting, leading to inevitable distribution mismatch between training and inference as well as suboptimal performance. In this work, we propose 3DMOTFormer, a learned geometry-based 3D MOT framework building upon the transformer architecture. We use an Edge-Augmented Graph Transformer to reason on the track-detection bipartite graph frame-by-frame and conduct data association via edge classification. To reduce the distribution mismatch between training and inference, we propose a novel online training strategy with an autoregressive and recurrent forward pass as well as sequential batch optimization. Using CenterPoint detections, our approach achieves 71.2% and 68.2% AMOTA on the nuScenes validation and test split, respectively. In addition, a trained 3DMOTFormer model generalizes well across different object detectors. Code is available at: https://github.com/dsx0511/3DMOTFormer.
PowerBEV: A Powerful Yet Lightweight Framework for Instance Prediction in Bird's-Eye View
Jun 19, 2023Accurately perceiving instances and predicting their future motion are key tasks for autonomous vehicles, enabling them to navigate safely in complex urban traffic. While bird's-eye view (BEV) representations are commonplace in perception for autonomous driving, their potential in a motion prediction setting is less explored. Existing approaches for BEV instance prediction from surround cameras rely on a multi-task auto-regressive setup coupled with complex post-processing to predict future instances in a spatio-temporally consistent manner. In this paper, we depart from this paradigm and propose an efficient novel end-to-end framework named POWERBEV, which differs in several design choices aimed at reducing the inherent redundancy in previous methods. First, rather than predicting the future in an auto-regressive fashion, POWERBEV uses a parallel, multi-scale module built from lightweight 2D convolutional networks. Second, we show that segmentation and centripetal backward flow are sufficient for prediction, simplifying previous multi-task objectives by eliminating redundant output modalities. Building on this output representation, we propose a simple, flow warping-based post-processing approach which produces more stable instance associations across time. Through this lightweight yet powerful design, POWERBEV outperforms state-of-the-art baselines on the NuScenes Dataset and poses an alternative paradigm for BEV instance prediction. We made our code publicly available at: https://github.com/EdwardLeeLPZ/PowerBEV.
Single-Stage Object Detection from Top-View Grid Maps on Custom Sensor Setups
Feb 03, 2020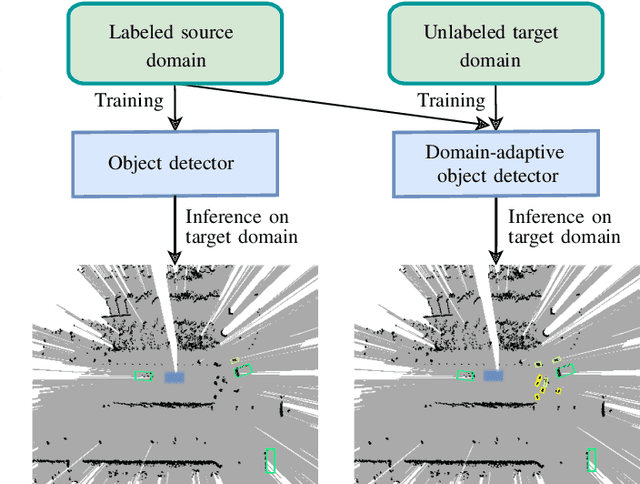
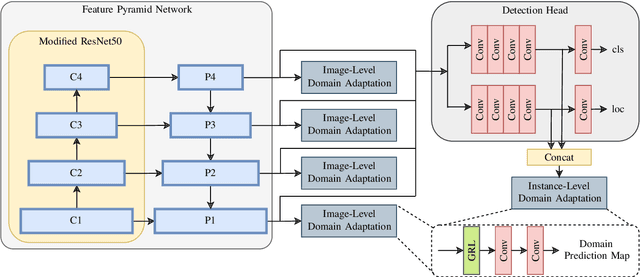
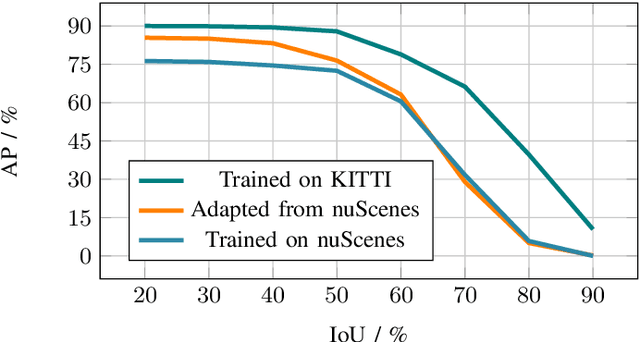
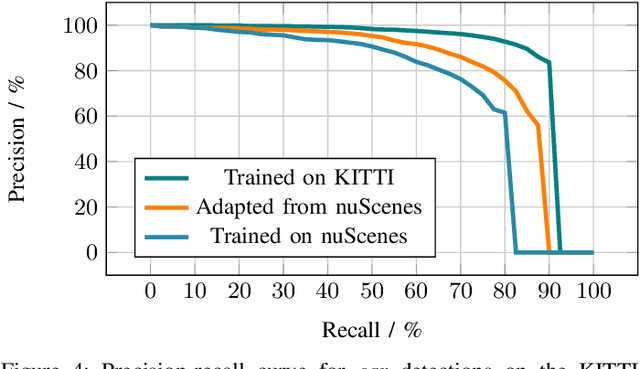
We present our approach to unsupervised domain adaptation for single-stage object detectors on top-view grid maps in automated driving scenarios. Our goal is to train a robust object detector on grid maps generated from custom sensor data and setups. We first introduce a single-stage object detector for grid maps based on RetinaNet. We then extend our model by image- and instance-level domain classifiers at different feature pyramid levels which are trained in an adversarial manner. This allows us to train robust object detectors for unlabeled domains. We evaluate our approach quantitatively on the nuScenes and KITTI benchmarks and present qualitative domain adaptation results for unlabeled measurements recorded by our experimental vehicle. Our results demonstrate that object detection accuracy for unlabeled domains can be improved by applying our domain adaptation strategy.