 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Clustering Propagation for Universal Medical Image Segmentation
Mar 25, 2024
Prominent solutions for medical image segmentation are typically tailored for automatic or interactive setups, posing challenges in facilitating progress achieved in one task to another.$_{\!}$ This$_{\!}$ also$_{\!}$ necessitates$_{\!}$ separate$_{\!}$ models for each task, duplicating both training time and parameters.$_{\!}$ To$_{\!}$ address$_{\!}$ above$_{\!}$ issues,$_{\!}$ we$_{\!}$ introduce$_{\!}$ S2VNet,$_{\!}$ a$_{\!}$ universal$_{\!}$ framework$_{\!}$ that$_{\!}$ leverages$_{\!}$ Slice-to-Volume$_{\!}$ propagation$_{\!}$ to$_{\!}$ unify automatic/interactive segmentation within a single model and one training session. Inspired by clustering-based segmentation techniques, S2VNet makes full use of the slice-wise structure of volumetric data by initializing cluster centers from the cluster$_{\!}$ results$_{\!}$ of$_{\!}$ previous$_{\!}$ slice.$_{\!}$ This enables knowledge acquired from prior slices to assist in the segmentation of the current slice, further efficiently bridging the communication between remote slices using mere 2D networks. Moreover, such a framework readily accommodates interactive segmentation with no architectural change, simply by initializing centroids from user inputs. S2VNet distinguishes itself by swift inference speeds and reduced memory consumption compared to prevailing 3D solutions. It can also handle multi-class interactions with each of them serving to initialize different centroids. Experiments on three benchmarks demonstrate S2VNet surpasses task-specified solutions on both automatic/interactive setups.
Developing Federated Time-to-Event Scores Using Heterogeneous Real-World Survival Data
Mar 08, 2024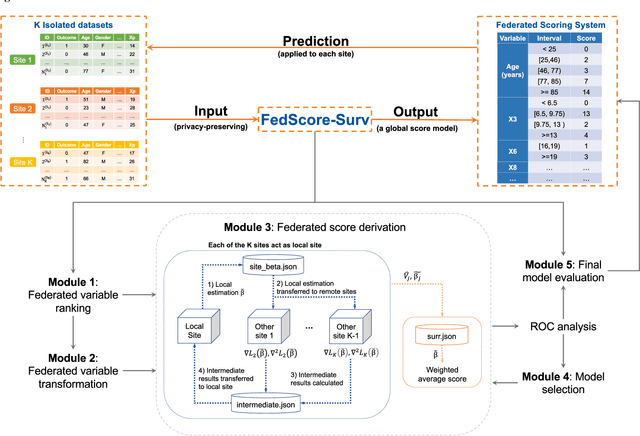
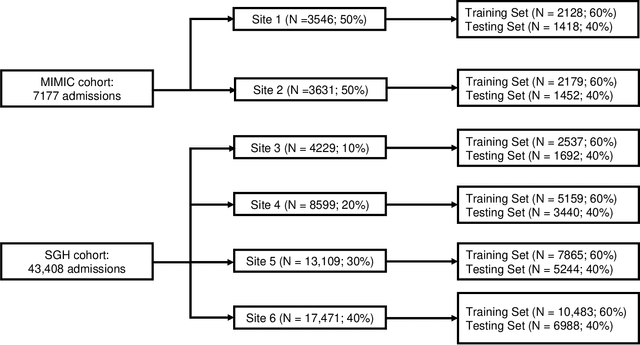
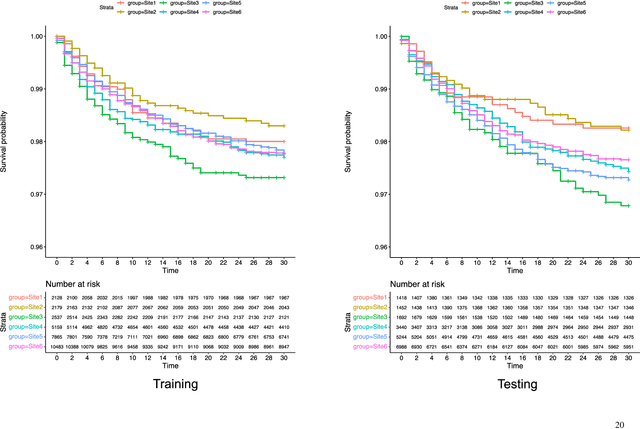
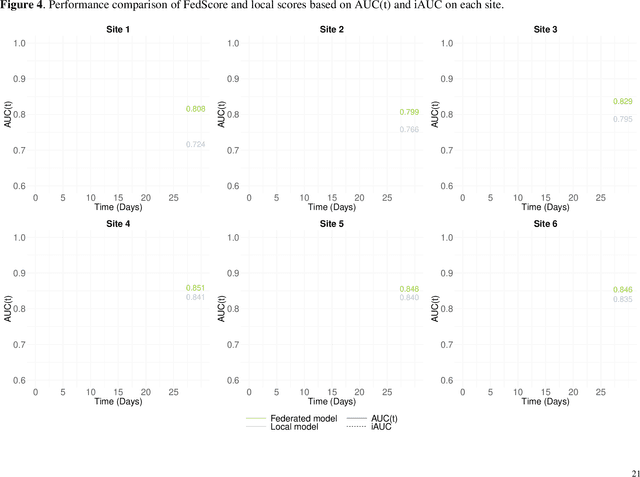
Survival analysis serves as a fundamental component in numerous healthcare applications, where the determination of the time to specific events (such as the onset of a certain disease or death) for patients is crucial for clinical decision-making. Scoring systems are widely used for swift and efficient risk prediction. However, existing methods for constructing survival scores presume that data originates from a single source, posing privacy challenges in collaborations with multiple data owners. We propose a novel framework for building federated scoring systems for multi-site survival outcomes, ensuring both privacy and communication efficiency. We applied our approach to sites with heterogeneous survival data originating from emergency departments in Singapore and the United States. Additionally, we independently developed local scores at each site. In testing datasets from each participant site, our proposed federated scoring system consistently outperformed all local models, evidenced by higher integrated area under the receiver operating characteristic curve (iAUC) values, with a maximum improvement of 11.6%. Additionally, the federated score's time-dependent AUC(t) values showed advantages over local scores, exhibiting narrower confidence intervals (CIs) across most time points. The model developed through our proposed method exhibits effective performance on each local site, signifying noteworthy implications for healthcare research. Sites participating in our proposed federated scoring model training gained benefits by acquiring survival models with enhanced prediction accuracy and efficiency. This study demonstrates the effectiveness of our privacy-preserving federated survival score generation framework and its applicability to real-world heterogeneous survival data.
Masked Multi-Domain Network: Multi-Type and Multi-Scenario Conversion Rate Prediction with a Single Model
Mar 26, 2024In real-world advertising systems, conversions have different types in nature and ads can be shown in different display scenarios, both of which highly impact the actual conversion rate (CVR). This results in the multi-type and multi-scenario CVR prediction problem. A desired model for this problem should satisfy the following requirements: 1) Accuracy: the model should achieve fine-grained accuracy with respect to any conversion type in any display scenario. 2) Scalability: the model parameter size should be affordable. 3) Convenience: the model should not require a large amount of effort in data partitioning, subset processing and separate storage. Existing approaches cannot simultaneously satisfy these requirements. For example, building a separate model for each (conversion type, display scenario) pair is neither scalable nor convenient. Building a unified model trained on all the data with conversion type and display scenario included as two features is not accurate enough. In this paper, we propose the Masked Multi-domain Network (MMN) to solve this problem. To achieve the accuracy requirement, we model domain-specific parameters and propose a dynamically weighted loss to account for the loss scale imbalance issue within each mini-batch. To achieve the scalability requirement, we propose a parameter sharing and composition strategy to reduce model parameters from a product space to a sum space. To achieve the convenience requirement, we propose an auto-masking strategy which can take mixed data from all the domains as input. It avoids the overhead caused by data partitioning, individual processing and separate storage. Both offline and online experimental results validate the superiority of MMN for multi-type and multi-scenario CVR prediction. MMN is now the serving model for real-time CVR prediction in UC Toutiao.
A TDD Distributed MIMO Testbed Using a 1-Bit Radio-Over-Fiber Fronthaul Architecture
Mar 26, 2024We present the uplink and downlink of a time-division duplex distributed multiple-input multiple-output (D-MIMO) testbed, based on a 1-bit radio-over-fiber architecture, which is low-cost and scalable. The proposed architecture involves a central unit (CU) that is equipped with 1-bit digital-to-analog and analog-to-digital converters, operating at 10 GS/s. The CU is connected to multiple single-antenna remote radio heads (RRHs) via optical fibers, over which a binary RF waveform is transmitted. In the uplink, a binary RF waveform is generated at the RRHs by a comparator, whose inputs are the received RF signal and a suitably designed dither signal. In the downlink, a binary RF waveform is generated at the CU via bandpass sigma-delta modulation. Our measurement results show that low error-vector magnitude (EVM) can be achieved in both the uplink and the downlink, despite 1-bit sampling at the CU. Specifically, for point-to-point over-cable transmission between a single user equipment (UE) and a CU equipped with a single RRH, we report, for a 10 MBd signal using single-carrier 16QAM modulation, an EVM of 3.3% in the downlink, and of 4.5% in the uplink. We then consider a CU connected to 3 RRHs serving over the air 2 UEs, and show that, after over-the-air reciprocity calibration, a downlink zero-forcing precoder designed on the basis of uplink channel estimates at the CU, achieves an EVM of 6.4% and 10.9% at UE 1 and UE 2, respectively. Finally, we investigate the ability of the proposed architecture to support orthogonal frequency-division multiplexing (OFDM) waveforms, and its robustness against both in-band and out-of-band interference.
Discrete Semantic Tokenization for Deep CTR Prediction
Mar 21, 2024Incorporating item content information into click-through rate (CTR) prediction models remains a challenge, especially with the time and space constraints of industrial scenarios. The content-encoding paradigm, which integrates user and item encoders directly into CTR models, prioritizes space over time. In contrast, the embedding-based paradigm transforms item and user semantics into latent embeddings, subsequently caching them to optimize processing time at the expense of space. In this paper, we introduce a new semantic-token paradigm and propose a discrete semantic tokenization approach, namely UIST, for user and item representation. UIST facilitates swift training and inference while maintaining a conservative memory footprint. Specifically, UIST quantizes dense embedding vectors into discrete tokens with shorter lengths and employs a hierarchical mixture inference module to weigh the contribution of each user--item token pair. Our experimental results on news recommendation showcase the effectiveness and efficiency (about 200-fold space compression) of UIST for CTR prediction.
Learning to Change: Choreographing Mixed Traffic Through Lateral Control and Hierarchical Reinforcement Learning
Mar 21, 2024The management of mixed traffic that consists of robot vehicles (RVs) and human-driven vehicles (HVs) at complex intersections presents a multifaceted challenge. Traditional signal controls often struggle to adapt to dynamic traffic conditions and heterogeneous vehicle types. Recent advancements have turned to strategies based on reinforcement learning (RL), leveraging its model-free nature, real-time operation, and generalizability over different scenarios. We introduce a hierarchical RL framework to manage mixed traffic through precise longitudinal and lateral control of RVs. Our proposed hierarchical framework combines the state-of-the-art mixed traffic control algorithm as a high level decision maker to improve the performance and robustness of the whole system. Our experiments demonstrate that the framework can reduce the average waiting time by up to 54% compared to the state-of-the-art mixed traffic control method. When the RV penetration rate exceeds 60%, our technique consistently outperforms conventional traffic signal control programs in terms of the average waiting time for all vehicles at the intersection.
SRLM: Human-in-Loop Interactive Social Robot Navigation with Large Language Model and Deep Reinforcement Learning
Mar 22, 2024An interactive social robotic assistant must provide services in complex and crowded spaces while adapting its behavior based on real-time human language commands or feedback. In this paper, we propose a novel hybrid approach called Social Robot Planner (SRLM), which integrates Large Language Models (LLM) and Deep Reinforcement Learning (DRL) to navigate through human-filled public spaces and provide multiple social services. SRLM infers global planning from human-in-loop commands in real-time, and encodes social information into a LLM-based large navigation model (LNM) for low-level motion execution. Moreover, a DRL-based planner is designed to maintain benchmarking performance, which is blended with LNM by a large feedback model (LFM) to address the instability of current text and LLM-driven LNM. Finally, SRLM demonstrates outstanding performance in extensive experiments. More details about this work are available at: https://sites.google.com/view/navi-srlm
OceanPlan: Hierarchical Planning and Replanning for Natural Language AUV Piloting in Large-scale Unexplored Ocean Environments
Mar 22, 2024We develop a hierarchical LLM-task-motion planning and replanning framework to efficiently ground an abstracted human command into tangible Autonomous Underwater Vehicle (AUV) control through enhanced representations of the world. We also incorporate a holistic replanner to provide real-world feedback with all planners for robust AUV operation. While there has been extensive research in bridging the gap between LLMs and robotic missions, they are unable to guarantee success of AUV applications in the vast and unknown ocean environment. To tackle specific challenges in marine robotics, we design a hierarchical planner to compose executable motion plans, which achieves planning efficiency and solution quality by decomposing long-horizon missions into sub-tasks. At the same time, real-time data stream is obtained by a replanner to address environmental uncertainties during plan execution. Experiments validate that our proposed framework delivers successful AUV performance of long-duration missions through natural language piloting.
Conformal prediction for multi-dimensional time series by ellipsoidal sets
Mar 06, 2024
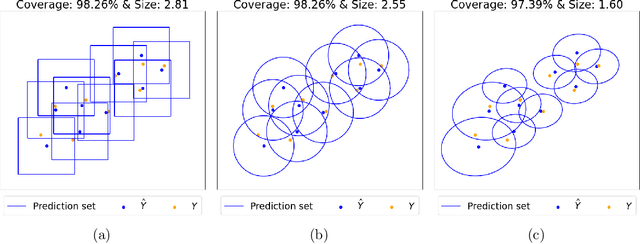
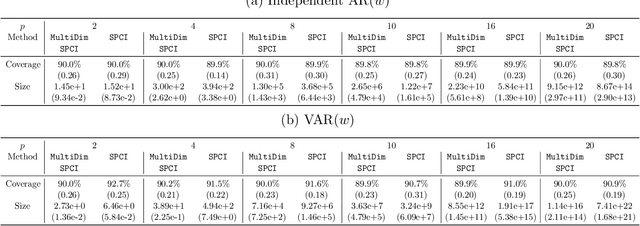
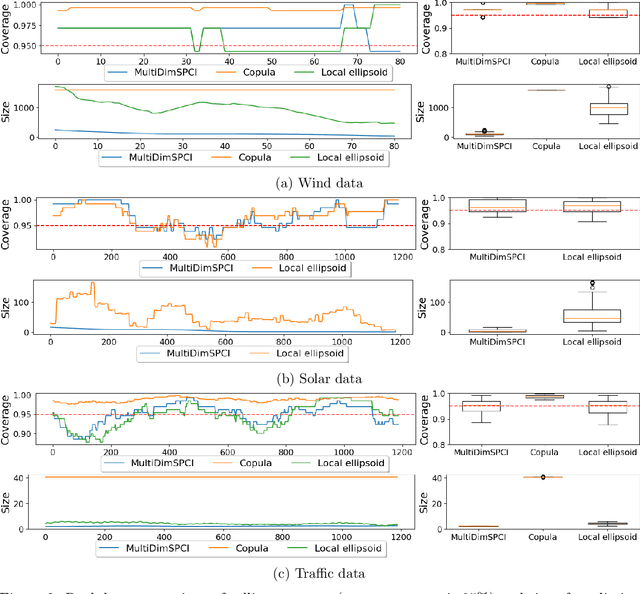
Conformal prediction (CP) has been a popular method for uncertainty quantification because it is distribution-free, model-agnostic, and theoretically sound. For forecasting problems in supervised learning, most CP methods focus on building prediction intervals for univariate responses. In this work, we develop a sequential CP method called $\texttt{MultiDimSPCI}$ that builds prediction regions for a multivariate response, especially in the context of multivariate time series, which are not exchangeable. Theoretically, we estimate finite-sample high-probability bounds on the conditional coverage gap. Empirically, we demonstrate that $\texttt{MultiDimSPCI}$ maintains valid coverage on a wide range of multivariate time series while producing smaller prediction regions than CP and non-CP baselines.
Test-time Distribution Learning Adapter for Cross-modal Visual Reasoning
Mar 10, 2024
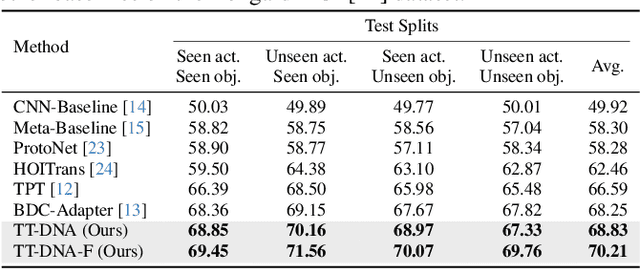
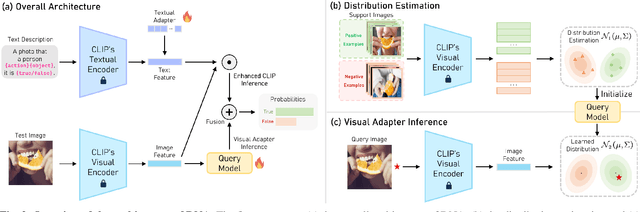
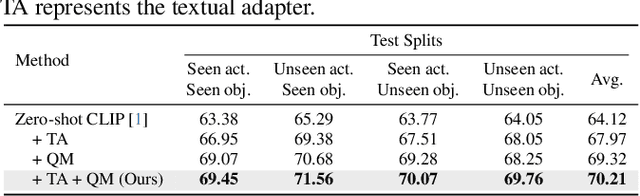
Vision-Language Pre-Trained (VLP) models, such as CLIP, have demonstrated remarkable effectiveness in learning generic visual representations. Several approaches aim to efficiently adapt VLP models to downstream tasks with limited supervision, aiming to leverage the acquired knowledge from VLP models. However, these methods suffer from either introducing biased representations or requiring high computational complexity, which hinders their effectiveness in fine-tuning the CLIP model. Moreover, when a model is trained on data specific to a particular domain, its ability to generalize to uncharted domains diminishes. In this work, we propose Test-Time Distribution LearNing Adapter (TT-DNA) which directly works during the testing period. Specifically, we estimate Gaussian distributions to model visual features of the few-shot support images to capture the knowledge from the support set. The cosine similarity between query image and the feature distribution of support images is used as the prediction of visual adapter. Subsequently, the visual adapter's prediction merges with the original CLIP prediction via a residual connection, resulting in the final prediction. Our extensive experimental results on visual reasoning for human object interaction demonstrate that our proposed TT-DNA outperforms existing state-of-the-art methods by large margins.