 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improved Long Short-Term Memory-based Wastewater Treatment Simulators for Deep Reinforcement Learning
Mar 22, 2024
Even though Deep Reinforcement Learning (DRL) showed outstanding results in the fields of Robotics and Games, it is still challenging to implement it in the optimization of industrial processes like wastewater treatment. One of the challenges is the lack of a simulation environment that will represent the actual plant as accurately as possible to train DRL policies. Stochasticity and non-linearity of wastewater treatment data lead to unstable and incorrect predictions of models over long time horizons. One possible reason for the models' incorrect simulation behavior can be related to the issue of compounding error, which is the accumulation of errors throughout the simulation. The compounding error occurs because the model utilizes its predictions as inputs at each time step. The error between the actual data and the prediction accumulates as the simulation continues. We implemented two methods to improve the trained models for wastewater treatment data, which resulted in more accurate simulators: 1- Using the model's prediction data as input in the training step as a tool of correction, and 2- Change in the loss function to consider the long-term predicted shape (dynamics). The experimental results showed that implementing these methods can improve the behavior of simulators in terms of Dynamic Time Warping throughout a year up to 98% compared to the base model. These improvements demonstrate significant promise in creating simulators for biological processes that do not need pre-existing knowledge of the process but instead depend exclusively on time series data obtained from the system.
Towards Trustworthy Automated Driving through Qualitative Scene Understanding and Explanations
Mar 25, 2024Understanding driving scenes and communicating automated vehicle decisions are key requirements for trustworthy automated driving. In this article, we introduce the Qualitative Explainable Graph (QXG), which is a unified symbolic and qualitative representation for scene understanding in urban mobility. The QXG enables interpreting an automated vehicle's environment using sensor data and machine learning models. It utilizes spatio-temporal graphs and qualitative constraints to extract scene semantics from raw sensor inputs, such as LiDAR and camera data, offering an interpretable scene model. A QXG can be incrementally constructed in real-time, making it a versatile tool for in-vehicle explanations across various sensor types. Our research showcases the potential of QXG, particularly in the context of automated driving, where it can rationalize decisions by linking the graph with observed actions. These explanations can serve diverse purposes, from informing passengers and alerting vulnerable road users to enabling post-hoc analysis of prior behaviors.
Learning from Reduced Labels for Long-Tailed Data
Mar 25, 2024Long-tailed data is prevalent in real-world classification tasks and heavily relies on supervised information, which makes the annotation process exceptionally labor-intensive and time-consuming. Unfortunately, despite being a common approach to mitigate labeling costs, existing weakly supervised learning methods struggle to adequately preserve supervised information for tail samples, resulting in a decline in accuracy for the tail classes. To alleviate this problem, we introduce a novel weakly supervised labeling setting called Reduced Label. The proposed labeling setting not only avoids the decline of supervised information for the tail samples, but also decreases the labeling costs associated with long-tailed data. Additionally, we propose an straightforward and highly efficient unbiased framework with strong theoretical guarantees to learn from these Reduced Labels. Extensive experiments conducted on benchmark datasets including ImageNet validate the effectiveness of our approach, surpassing the performance of state-of-the-art weakly supervised methods.
Step-Calibrated Diffusion for Biomedical Optical Image Restoration
Mar 26, 2024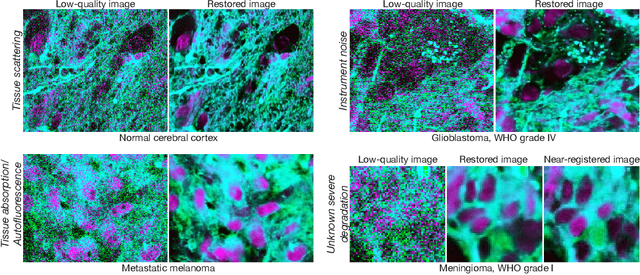

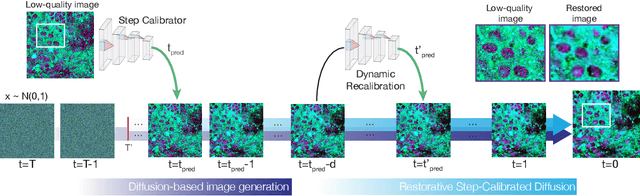
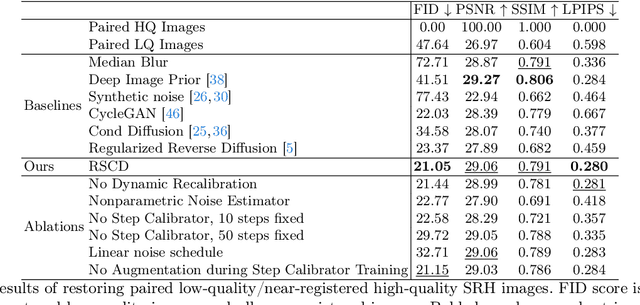
High-quality, high-resolution medical imaging is essential for clinical care. Raman-based biomedical optical imaging uses non-ionizing infrared radiation to evaluate human tissues in real time and is used for early cancer detection, brain tumor diagnosis, and intraoperative tissue analysis. Unfortunately, optical imaging is vulnerable to image degradation due to laser scattering and absorption, which can result in diagnostic errors and misguided treatment. Restoration of optical images is a challenging computer vision task because the sources of image degradation are multi-factorial, stochastic, and tissue-dependent, preventing a straightforward method to obtain paired low-quality/high-quality data. Here, we present Restorative Step-Calibrated Diffusion (RSCD), an unpaired image restoration method that views the image restoration problem as completing the finishing steps of a diffusion-based image generation task. RSCD uses a step calibrator model to dynamically determine the severity of image degradation and the number of steps required to complete the reverse diffusion process for image restoration. RSCD outperforms other widely used unpaired image restoration methods on both image quality and perceptual evaluation metrics for restoring optical images. Medical imaging experts consistently prefer images restored using RSCD in blinded comparison experiments and report minimal to no hallucinations. Finally, we show that RSCD improves performance on downstream clinical imaging tasks, including automated brain tumor diagnosis and deep tissue imaging. Our code is available at https://github.com/MLNeurosurg/restorative_step-calibrated_diffusion.
Online Tree Reconstruction and Forest Inventory on a Mobile Robotic System
Mar 26, 2024Terrestrial laser scanning (TLS) is the standard technique used to create accurate point clouds for digital forest inventories. However, the measurement process is demanding, requiring up to two days per hectare for data collection, significant data storage, as well as resource-heavy post-processing of 3D data. In this work, we present a real-time mapping and analysis system that enables online generation of forest inventories using mobile laser scanners that can be mounted e.g. on mobile robots. Given incrementally created and locally accurate submaps-data payloads-our approach extracts tree candidates using a custom, Voronoi-inspired clustering algorithm. Tree candidates are reconstructed using an adapted Hough algorithm, which enables robust modeling of the tree stem. Further, we explicitly incorporate the incremental nature of the data collection by consistently updating the database using a pose graph LiDAR SLAM system. This enables us to refine our estimates of the tree traits if an area is revisited later during a mission. We demonstrate competitive accuracy to TLS or manual measurements using laser scanners that we mounted on backpacks or mobile robots operating in conifer, broad-leaf and mixed forests. Our results achieve RMSE of 1.93 cm, a bias of 0.65 cm and a standard deviation of 1.81 cm (averaged across these sequences)-with no post-processing required after the mission is complete.
AMP: Autoregressive Motion Prediction Revisited with Next Token Prediction for Autonomous Driving
Mar 21, 2024
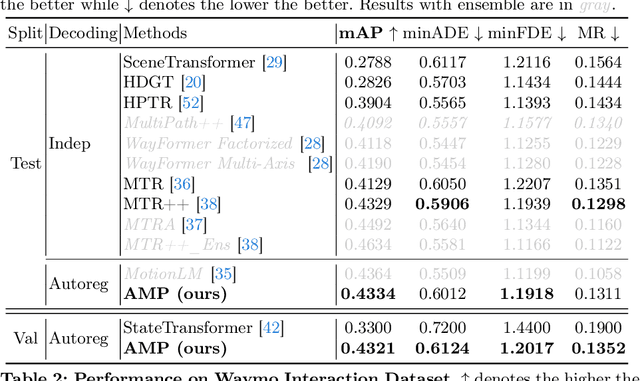
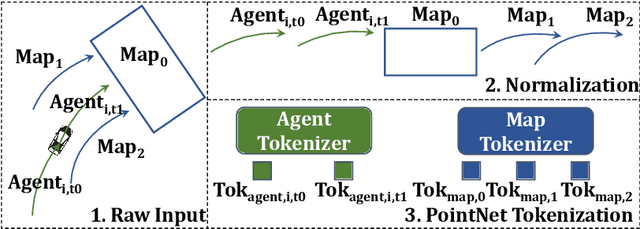
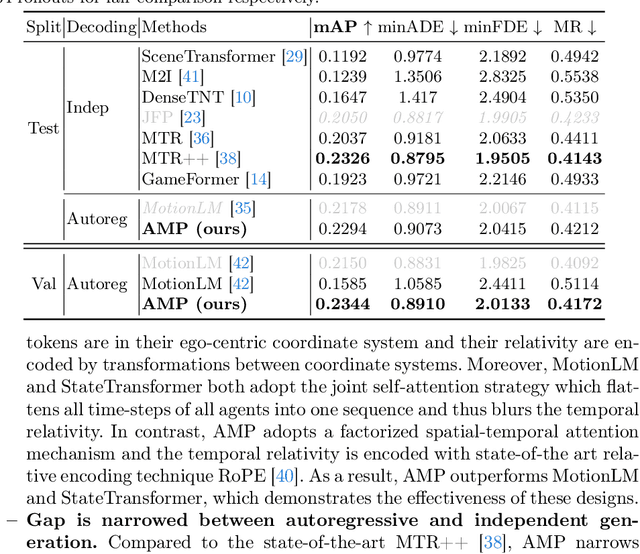
As an essential task in autonomous driving (AD), motion prediction aims to predict the future states of surround objects for navigation. One natural solution is to estimate the position of other agents in a step-by-step manner where each predicted time-step is conditioned on both observed time-steps and previously predicted time-steps, i.e., autoregressive prediction. Pioneering works like SocialLSTM and MFP design their decoders based on this intuition. However, almost all state-of-the-art works assume that all predicted time-steps are independent conditioned on observed time-steps, where they use a single linear layer to generate positions of all time-steps simultaneously. They dominate most motion prediction leaderboards due to the simplicity of training MLPs compared to autoregressive networks. In this paper, we introduce the GPT style next token prediction into motion forecasting. In this way, the input and output could be represented in a unified space and thus the autoregressive prediction becomes more feasible. However, different from language data which is composed of homogeneous units -words, the elements in the driving scene could have complex spatial-temporal and semantic relations. To this end, we propose to adopt three factorized attention modules with different neighbors for information aggregation and different position encoding styles to capture their relations, e.g., encoding the transformation between coordinate systems for spatial relativity while adopting RoPE for temporal relativity. Empirically, by equipping with the aforementioned tailored designs, the proposed method achieves state-of-the-art performance in the Waymo Open Motion and Waymo Interaction datasets. Notably, AMP outperforms other recent autoregressive motion prediction methods: MotionLM and StateTransformer, which demonstrates the effectiveness of the proposed designs.
Runtime Monitoring and Fault Detection for Neural Network-Controlled Systems
Mar 24, 2024There is an emerging trend in applying deep learning methods to control complex nonlinear systems. This paper considers enhancing the runtime safety of nonlinear systems controlled by neural networks in the presence of disturbance and measurement noise. A robustly stable interval observer is designed to generate sound and precise lower and upper bounds for the neural network, nonlinear function, and system state. The obtained interval is utilised to monitor the real-time system safety and detect faults in the system outputs or actuators. An adaptive cruise control vehicular system is simulated to demonstrate effectiveness of the proposed design.
Neural Image Compression with Quantization Rectifier
Mar 25, 2024Neural image compression has been shown to outperform traditional image codecs in terms of rate-distortion performance. However, quantization introduces errors in the compression process, which can degrade the quality of the compressed image. Existing approaches address the train-test mismatch problem incurred during quantization, the random impact of quantization on the expressiveness of image features is still unsolved. This paper presents a novel quantization rectifier (QR) method for image compression that leverages image feature correlation to mitigate the impact of quantization. Our method designs a neural network architecture that predicts unquantized features from the quantized ones, preserving feature expressiveness for better image reconstruction quality. We develop a soft-to-predictive training technique to integrate QR into existing neural image codecs. In evaluation, we integrate QR into state-of-the-art neural image codecs and compare enhanced models and baselines on the widely-used Kodak benchmark. The results show consistent coding efficiency improvement by QR with a negligible increase in the running time.
Adaptive Step Duration for Precise Foot Placement: Achieving Robust Bipedal Locomotion on Terrains with Restricted Footholds
Mar 25, 2024This paper introduces a novel multi-step preview foot placement planning algorithm designed to enhance the robustness of bipedal robotic walking across challenging terrains with restricted footholds. Traditional one-step preview planning struggles to maintain stability when stepping areas are severely limited, such as with random stepping stones. In this work, we developed a discrete-time Model Predictive Control (MPC) based on the step-to-step discrete evolution of the Divergent Component of Motion (DCM) of bipedal locomotion. This approach adaptively changes the step duration for optimal foot placement under constraints, thereby ensuring the robot's operational viability over multiple future steps and significantly improving its ability to navigate through environments with tight constraints on possible footholds. The effectiveness of this planning algorithm is demonstrated through simulations that include a variety of complex stepping-stone configurations and external perturbations. These tests underscore the algorithm's improved performance for navigating foothold-restricted environments, even with the presence of external disturbances.
SynFog: A Photo-realistic Synthetic Fog Dataset based on End-to-end Imaging Simulation for Advancing Real-World Defogging in Autonomous Driving
Mar 25, 2024To advance research in learning-based defogging algorithms, various synthetic fog datasets have been developed. However, existing datasets created using the Atmospheric Scattering Model (ASM) or real-time rendering engines often struggle to produce photo-realistic foggy images that accurately mimic the actual imaging process. This limitation hinders the effective generalization of models from synthetic to real data. In this paper, we introduce an end-to-end simulation pipeline designed to generate photo-realistic foggy images. This pipeline comprehensively considers the entire physically-based foggy scene imaging process, closely aligning with real-world image capture methods. Based on this pipeline, we present a new synthetic fog dataset named SynFog, which features both sky light and active lighting conditions, as well as three levels of fog density. Experimental results demonstrate that models trained on SynFog exhibit superior performance in visual perception and detection accuracy compared to others when applied to real-world foggy images.