 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanFlow -- Diffusion-Driven MAV Navigation Among Humans via Tightly-Coupled Motion Tracking, Forecasting, and Control
May 25, 2026Robust and accurate perception of humans in their 3D scene context is essential for integrating robots into everyday environments. Existing approaches, however, often fail to predict plausible and accurate human motion estimates that are consistent with the surrounding scene, especially in the presence of heavy occlusions or partial visibility. This can limit both safety and efficiency for robotic operations. We introduce HumanFlow, a latent diffusion model that unifies human motion tracking and forecasting, conditioned on the 3D scene context. We show that our human motion model produces smooth and accurate predictions under challenging conditions, including heavy occlusions, and outperforms state-of-the-art methods in tracking accuracy while being significantly more efficient. Furthermore, we show how HumanFlow's latent space can be tightly coupled with control by conditioning a flow-matching-based, approximate MPC policy on these representations. We validate our policy in simulation with real human trajectories for MAV social navigation, demonstrating superior navigation performance and remaining collision-free, even under partial observability of the human.
OpenSGA: Efficient 3D Scene Graph Alignment in the Open World
May 11, 2026Scene graph alignment establishes object correspondences between two 3D scene graphs constructed from partially overlapping observations. This enables efficient scene understanding and object-level relocalization when a robot revisits a place, as well as global map fusion across multiple agents. Such capabilities are essential for robots that require long-term memory for long-horizon tasks involving interactions with the environment. Existing approaches mainly focus on subscan-to-subscan (S2S) alignment and depend heavily on geometric point-cloud features, leaving frame-to-scan (F2S) alignment and open-set vision-language features underexplored. In addition, existing datasets for scene graph alignment remain small-scale with limited object diversity, constraining systematic training and evaluation. We present a unified and efficient scene graph alignment framework that predicts object correspondences by fusing vision-language, textual, and geometric features with spatial context. The framework comprises modules such as a distance-gated spatial attention encoder, a minimum-cost-flow-based allocator, and a global scene embedding generator to achieve accurate alignment even under large coordinate discrepancies. We further introduce ScanNet-SG, a large-scale dataset generated via an automated annotation pipeline with over 700k samples, covering 509 object categories from ScanNet labels and over 3k categories from GPT-4o-based tagging. Experiments show that our method achieves the best overall performance on both F2S and S2S tasks, substantially outperforming existing scene graph alignment methods. Our code and dataset are released at: https://autonomousrobots.nl/paper_websites/opensga.
DigiForest: Digital Analytics and Robotics for Sustainable Forestry
Apr 16, 2026Covering one third of Earth's land surface, forests are vital to global biodiversity, climate regulation, and human well-being. In Europe, forests and woodlands reach approximately 40% of land area, and the forestry sector is central to achieving the EU's climate neutrality and biodiversity goals; these emphasize sustainable forest management, increased use of long-lived wood products, and resilient forest ecosystems. To meet these goals and properly address their inherent challenges, current practices require further innovation. This chapter introduces DigiForest, a novel, large-scale precision forestry approach leveraging digital technologies and autonomous robotics. DigiForest is structured around four main components: (1) autonomous, heterogeneous mobile robots (aerial, legged, and marsupial) for tree-level data collection; (2) automated extraction of tree traits to build forest inventories; (3) a Decision Support System (DSS) for forecasting forest growth and supporting decision-making; and (4) low-impact selective logging using purpose-built autonomous harvesters. These technologies have been extensively validated in real-world conditions in several locations, including forests in Finland, the UK, and Switzerland.
OKVIS2-X: Open Keyframe-based Visual-Inertial SLAM Configurable with Dense Depth or LiDAR, and GNSS
Oct 06, 2025To empower mobile robots with usable maps as well as highest state estimation accuracy and robustness, we present OKVIS2-X: a state-of-the-art multi-sensor Simultaneous Localization and Mapping (SLAM) system building dense volumetric occupancy maps, while scalable to large environments and operating in realtime. Our unified SLAM framework seamlessly integrates different sensor modalities: visual, inertial, measured or learned depth, LiDAR and Global Navigation Satellite System (GNSS) measurements. Unlike most state-of-the-art SLAM systems, we advocate using dense volumetric map representations when leveraging depth or range-sensing capabilities. We employ an efficient submapping strategy that allows our system to scale to large environments, showcased in sequences of up to 9 kilometers. OKVIS2-X enhances its accuracy and robustness by tightly-coupling the estimator and submaps through map alignment factors. Our system provides globally consistent maps, directly usable for autonomous navigation. To further improve the accuracy of OKVIS2-X, we also incorporate the option of performing online calibration of camera extrinsics. Our system achieves the highest trajectory accuracy in EuRoC against state-of-the-art alternatives, outperforms all competitors in the Hilti22 VI-only benchmark, while also proving competitive in the LiDAR version, and showcases state of the art accuracy in the diverse and large-scale sequences from the VBR dataset.
CoRe-GS: Coarse-to-Refined Gaussian Splatting with Semantic Object Focus
Sep 05, 2025Mobile reconstruction for autonomous aerial robotics holds strong potential for critical applications such as tele-guidance and disaster response. These tasks demand both accurate 3D reconstruction and fast scene processing. Instead of reconstructing the entire scene in detail, it is often more efficient to focus on specific objects, i.e., points of interest (PoIs). Mobile robots equipped with advanced sensing can usually detect these early during data acquisition or preliminary analysis, reducing the need for full-scene optimization. Gaussian Splatting (GS) has recently shown promise in delivering high-quality novel view synthesis and 3D representation by an incremental learning process. Extending GS with scene editing, semantics adds useful per-splat features to isolate objects effectively. Semantic 3D Gaussian editing can already be achieved before the full training cycle is completed, reducing the overall training time. Moreover, the semantically relevant area, the PoI, is usually already known during capturing. To balance high-quality reconstruction with reduced training time, we propose CoRe-GS. We first generate a coarse segmentation-ready scene with semantic GS and then refine it for the semantic object using our novel color-based effective filtering for effective object isolation. This is speeding up the training process to be about a quarter less than a full training cycle for semantic GS. We evaluate our approach on two datasets, SCRREAM (real-world, outdoor) and NeRDS 360 (synthetic, indoor), showing reduced runtime and higher novel-view-synthesis quality.
GSFix3D: Diffusion-Guided Repair of Novel Views in Gaussian Splatting
Aug 20, 2025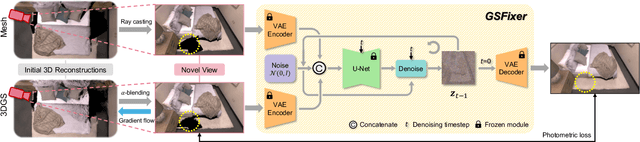
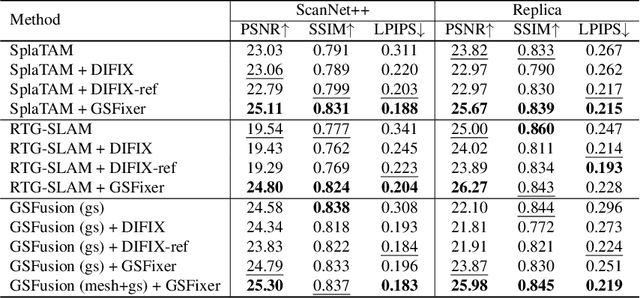
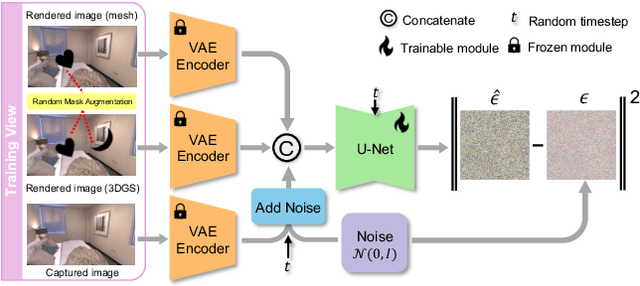

Recent developments in 3D Gaussian Splatting have significantly enhanced novel view synthesis, yet generating high-quality renderings from extreme novel viewpoints or partially observed regions remains challenging. Meanwhile, diffusion models exhibit strong generative capabilities, but their reliance on text prompts and lack of awareness of specific scene information hinder accurate 3D reconstruction tasks. To address these limitations, we introduce GSFix3D, a novel framework that improves the visual fidelity in under-constrained regions by distilling prior knowledge from diffusion models into 3D representations, while preserving consistency with observed scene details. At its core is GSFixer, a latent diffusion model obtained via our customized fine-tuning protocol that can leverage both mesh and 3D Gaussians to adapt pretrained generative models to a variety of environments and artifact types from different reconstruction methods, enabling robust novel view repair for unseen camera poses. Moreover, we propose a random mask augmentation strategy that empowers GSFixer to plausibly inpaint missing regions. Experiments on challenging benchmarks demonstrate that our GSFix3D and GSFixer achieve state-of-the-art performance, requiring only minimal scene-specific fine-tuning on captured data. Real-world test further confirms its resilience to potential pose errors. Our code and data will be made publicly available. Project page: https://gsfix3d.github.io.
FindAnything: Open-Vocabulary and Object-Centric Mapping for Robot Exploration in Any Environment
Apr 11, 2025Geometrically accurate and semantically expressive map representations have proven invaluable to facilitate robust and safe mobile robot navigation and task planning. Nevertheless, real-time, open-vocabulary semantic understanding of large-scale unknown environments is still an open problem. In this paper we present FindAnything, an open-world mapping and exploration framework that incorporates vision-language information into dense volumetric submaps. Thanks to the use of vision-language features, FindAnything bridges the gap between pure geometric and open-vocabulary semantic information for a higher level of understanding while allowing to explore any environment without the help of any external source of ground-truth pose information. We represent the environment as a series of volumetric occupancy submaps, resulting in a robust and accurate map representation that deforms upon pose updates when the underlying SLAM system corrects its drift, allowing for a locally consistent representation between submaps. Pixel-wise vision-language features are aggregated from efficient SAM (eSAM)-generated segments, which are in turn integrated into object-centric volumetric submaps, providing a mapping from open-vocabulary queries to 3D geometry that is scalable also in terms of memory usage. The open-vocabulary map representation of FindAnything achieves state-of-the-art semantic accuracy in closed-set evaluations on the Replica dataset. This level of scene understanding allows a robot to explore environments based on objects or areas of interest selected via natural language queries. Our system is the first of its kind to be deployed on resource-constrained devices, such as MAVs, leveraging vision-language information for real-world robotic tasks.
SuperEvent: Cross-Modal Learning of Event-based Keypoint Detection
Mar 31, 2025



Event-based keypoint detection and matching holds significant potential, enabling the integration of event sensors into highly optimized Visual SLAM systems developed for frame cameras over decades of research. Unfortunately, existing approaches struggle with the motion-dependent appearance of keypoints and the complex noise prevalent in event streams, resulting in severely limited feature matching capabilities and poor performance on downstream tasks. To mitigate this problem, we propose SuperEvent, a data-driven approach to predict stable keypoints with expressive descriptors. Due to the absence of event datasets with ground truth keypoint labels, we leverage existing frame-based keypoint detectors on readily available event-aligned and synchronized gray-scale frames for self-supervision: we generate temporally sparse keypoint pseudo-labels considering that events are a product of both scene appearance and camera motion. Combined with our novel, information-rich event representation, we enable SuperEvent to effectively learn robust keypoint detection and description in event streams. Finally, we demonstrate the usefulness of SuperEvent by its integration into a modern sparse keypoint and descriptor-based SLAM framework originally developed for traditional cameras, surpassing the state-of-the-art in event-based SLAM by a wide margin. Source code and multimedia material are available at smartroboticslab.github.io/SuperEvent.
VidBot: Learning Generalizable 3D Actions from In-the-Wild 2D Human Videos for Zero-Shot Robotic Manipulation
Mar 10, 2025



Future robots are envisioned as versatile systems capable of performing a variety of household tasks. The big question remains, how can we bridge the embodiment gap while minimizing physical robot learning, which fundamentally does not scale well. We argue that learning from in-the-wild human videos offers a promising solution for robotic manipulation tasks, as vast amounts of relevant data already exist on the internet. In this work, we present VidBot, a framework enabling zero-shot robotic manipulation using learned 3D affordance from in-the-wild monocular RGB-only human videos. VidBot leverages a pipeline to extract explicit representations from them, namely 3D hand trajectories from videos, combining a depth foundation model with structure-from-motion techniques to reconstruct temporally consistent, metric-scale 3D affordance representations agnostic to embodiments. We introduce a coarse-to-fine affordance learning model that first identifies coarse actions from the pixel space and then generates fine-grained interaction trajectories with a diffusion model, conditioned on coarse actions and guided by test-time constraints for context-aware interaction planning, enabling substantial generalization to novel scenes and embodiments. Extensive experiments demonstrate the efficacy of VidBot, which significantly outperforms counterparts across 13 manipulation tasks in zero-shot settings and can be seamlessly deployed across robot systems in real-world environments. VidBot paves the way for leveraging everyday human videos to make robot learning more scalable.
REGRACE: A Robust and Efficient Graph-based Re-localization Algorithm using Consistency Evaluation
Mar 05, 2025



Loop closures are essential for correcting odometry drift and creating consistent maps, especially in the context of large-scale navigation. Current methods using dense point clouds for accurate place recognition do not scale well due to computationally expensive scan-to-scan comparisons. Alternative object-centric approaches are more efficient but often struggle with sensitivity to viewpoint variation. In this work, we introduce REGRACE, a novel approach that addresses these challenges of scalability and perspective difference in re-localization by using LiDAR-based submaps. We introduce rotation-invariant features for each labeled object and enhance them with neighborhood context through a graph neural network. To identify potential revisits, we employ a scalable bag-of-words approach, pooling one learned global feature per submap. Additionally, we define a revisit with geometrical consistency cues rather than embedding distance, allowing us to recognize far-away loop closures. Our evaluations demonstrate that REGRACE achieves similar results compared to state-of-the-art place recognition and registration baselines while being twice as fast.