 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Visual-Inertial System: Analysis, Calibration and Estimation
Aug 18, 2023
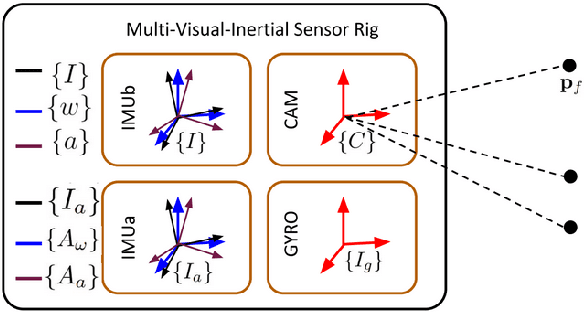



In this paper, we study state estimation of multi-visual-inertial systems (MVIS) and develop sensor fusion algorithms to optimally fuse an arbitrary number of asynchronous inertial measurement units (IMUs) or gyroscopes and global and(or) rolling shutter cameras. We are especially interested in the full calibration of the associated visual-inertial sensors, including the IMU or camera intrinsics and the IMU-IMU(or camera) spatiotemporal extrinsics as well as the image readout time of rolling-shutter cameras (if used). To this end, we develop a new analytic combined IMU integration with intrinsics-termed ACI3-to preintegrate IMU measurements, which is leveraged to fuse auxiliary IMUs and(or) gyroscopes alongside a base IMU. We model the multi-inertial measurements to include all the necessary inertial intrinsic and IMU-IMU spatiotemporal extrinsic parameters, while leveraging IMU-IMU rigid-body constraints to eliminate the necessity of auxiliary inertial poses and thus reducing computational complexity. By performing observability analysis of MVIS, we prove that the standard four unobservable directions remain - no matter how many inertial sensors are used, and also identify, for the first time, degenerate motions for IMU-IMU spatiotemporal extrinsics and auxiliary inertial intrinsics. In addition to the extensive simulations that validate our analysis and algorithms, we have built our own MVIS sensor rig and collected over 25 real-world datasets to experimentally verify the proposed calibration against the state-of-the-art calibration method such as Kalibr. We show that the proposed MVIS calibration is able to achieve competing accuracy with improved convergence and repeatability, which is open sourced to better benefit the community.
Causal Discovery from Subsampled Time Series with Proxy Variables
May 24, 2023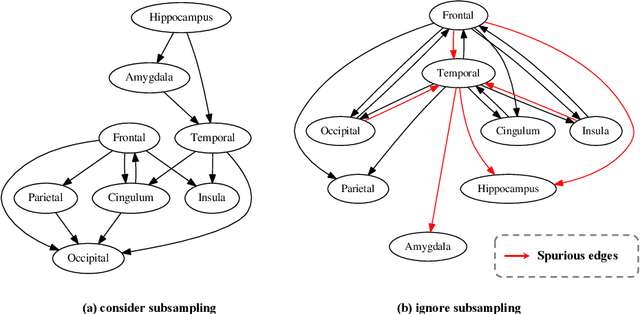

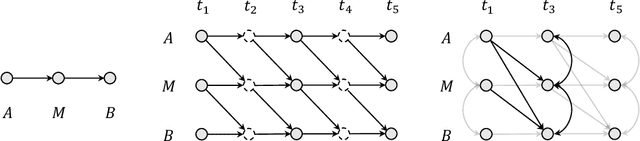
Inferring causal structures from time series data is the central interest of many scientific inquiries. A major barrier to such inference is the problem of subsampling, i.e., the frequency of measurement is much lower than that of causal influence. To overcome this problem, numerous methods have been proposed, yet either was limited to the linear case or failed to achieve identifiability. In this paper, we propose a constraint-based algorithm that can identify the entire causal structure from subsampled time series, without any parametric constraint. Our observation is that the challenge of subsampling arises mainly from hidden variables at the unobserved time steps. Meanwhile, every hidden variable has an observed proxy, which is essentially itself at some observable time in the future, benefiting from the temporal structure. Based on these, we can leverage the proxies to remove the bias induced by the hidden variables and hence achieve identifiability. Following this intuition, we propose a proxy-based causal discovery algorithm. Our algorithm is nonparametric and can achieve full causal identification. Theoretical advantages are reflected in synthetic and real-world experiments.
Neural Networks Optimizations Against Concept and Data Drift in Malware Detection
Aug 21, 2023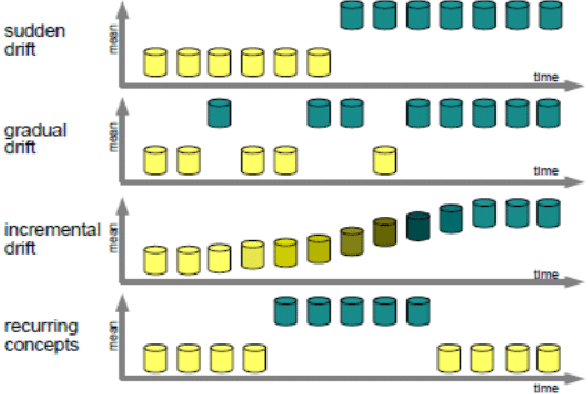
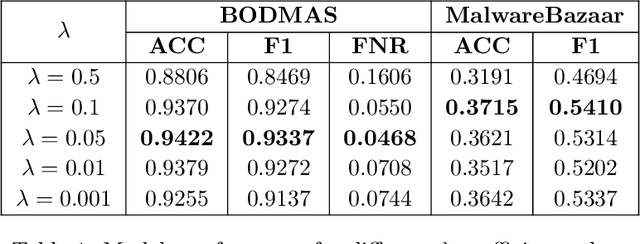
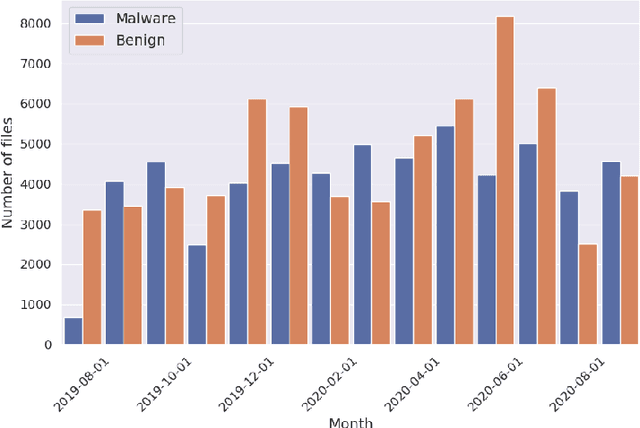
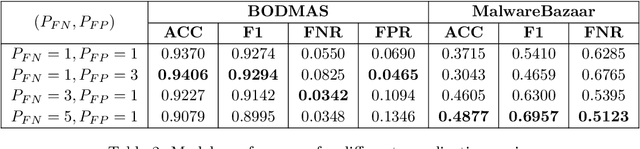
Despite the promising results of machine learning models in malware detection, they face the problem of concept drift due to malware constant evolution. This leads to a decline in performance over time, as the data distribution of the new files differs from the training one, requiring regular model update. In this work, we propose a model-agnostic protocol to improve a baseline neural network to handle with the drift problem. We show the importance of feature reduction and training with the most recent validation set possible, and propose a loss function named Drift-Resilient Binary Cross-Entropy, an improvement to the classical Binary Cross-Entropy more effective against drift. We train our model on the EMBER dataset (2018) and evaluate it on a dataset of recent malicious files, collected between 2020 and 2023. Our improved model shows promising results, detecting 15.2% more malware than a baseline model.
An Anchor-Point Based Image-Model for Room Impulse Response Simulation with Directional Source Radiation and Sensor Directivity Patterns
Aug 21, 2023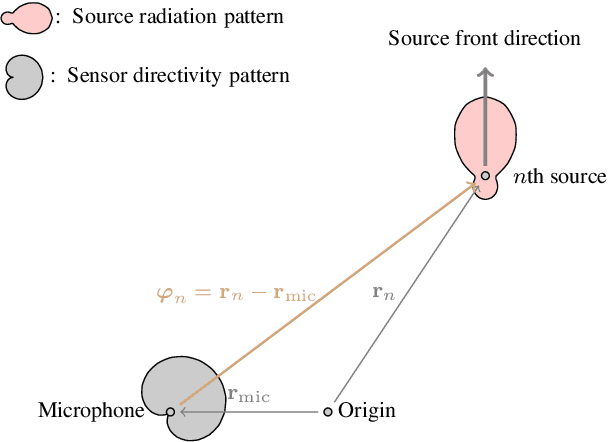

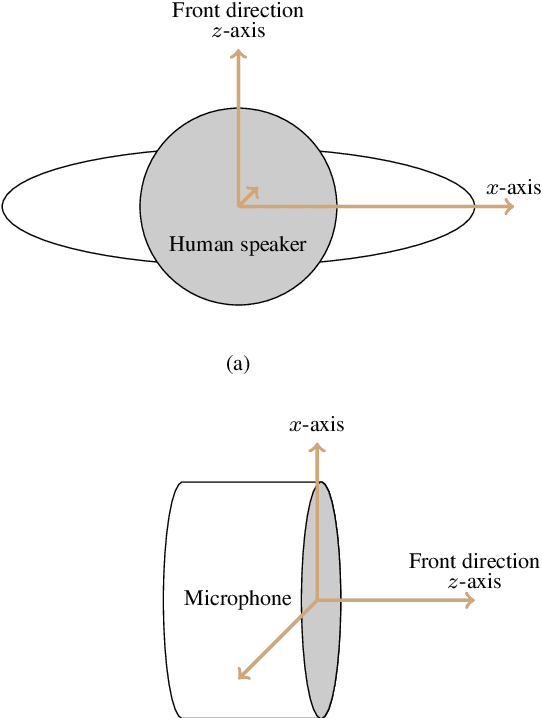
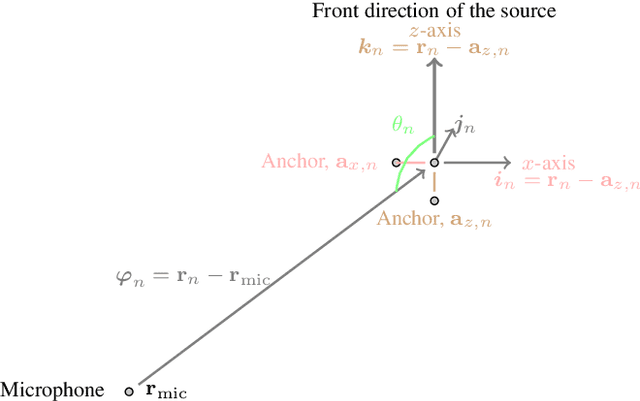
The image model method has been widely used to simulate room impulse responses and the endeavor to adapt this method to different applications has also piqued great interest over the last few decades. This paper attempts to extend the image model method and develops an anchor-point-image-model (APIM) approach as a solution for simulating impulse responses by including both the source radiation and sensor directivity patterns. To determine the orientations of all the virtual sources, anchor points are introduced to real sources, which subsequently lead to the determination of the orientations of the virtual sources. An algorithm is developed to generate room impulse responses with APIM by taking into account the directional pattern functions, factional time delays, as well as the computational complexity. The developed model and algorithms can be used in various acoustic problems to simulate room acoustics and improve and evaluate processing algorithms.
EVE: Efficient zero-shot text-based Video Editing with Depth Map Guidance and Temporal Consistency Constraints
Aug 21, 2023
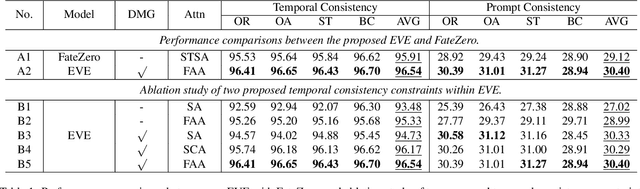
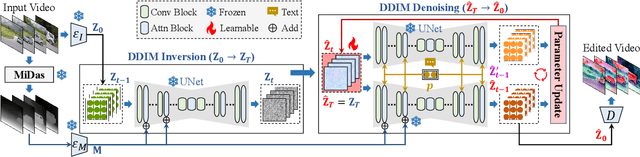

Motivated by the superior performance of image diffusion models, more and more researchers strive to extend these models to the text-based video editing task. Nevertheless, current video editing tasks mainly suffer from the dilemma between the high fine-tuning cost and the limited generation capacity. Compared with images, we conjecture that videos necessitate more constraints to preserve the temporal consistency during editing. Towards this end, we propose EVE, a robust and efficient zero-shot video editing method. Under the guidance of depth maps and temporal consistency constraints, EVE derives satisfactory video editing results with an affordable computational and time cost. Moreover, recognizing the absence of a publicly available video editing dataset for fair comparisons, we construct a new benchmark ZVE-50 dataset. Through comprehensive experimentation, we validate that EVE could achieve a satisfactory trade-off between performance and efficiency. We will release our dataset and codebase to facilitate future researchers.
An Improved Best-of-both-worlds Algorithm for Bandits with Delayed Feedback
Aug 21, 2023We propose a new best-of-both-worlds algorithm for bandits with variably delayed feedback. The algorithm improves on prior work by Masoudian et al. [2022] by eliminating the need in prior knowledge of the maximal delay $d_{\mathrm{max}}$ and providing tighter regret bounds in both regimes. The algorithm and its regret bounds are based on counts of outstanding observations (a quantity that is observed at action time) rather than delays or the maximal delay (quantities that are only observed when feedback arrives). One major contribution is a novel control of distribution drift, which is based on biased loss estimators and skipping of observations with excessively large delays. Another major contribution is demonstrating that the complexity of best-of-both-worlds bandits with delayed feedback is characterized by the cumulative count of outstanding observations after skipping of observations with excessively large delays, rather than the delays or the maximal delay.
TpuGraphs: A Performance Prediction Dataset on Large Tensor Computational Graphs
Aug 25, 2023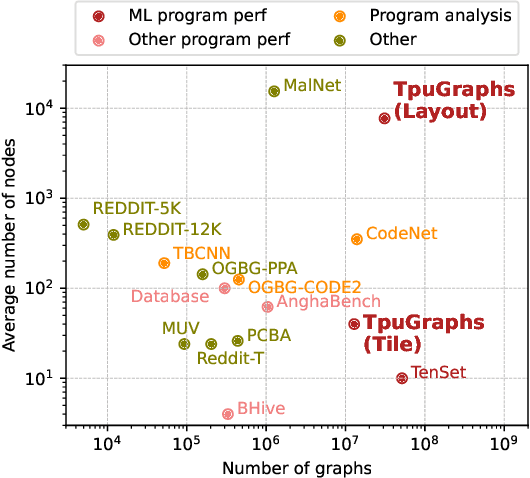

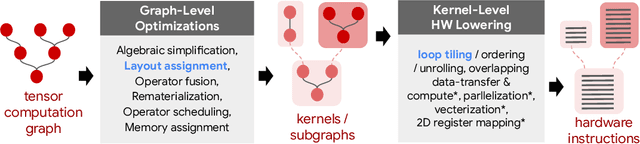
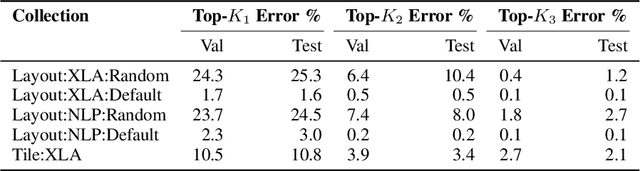
Precise hardware performance models play a crucial role in code optimizations. They can assist compilers in making heuristic decisions or aid autotuners in identifying the optimal configuration for a given program. For example, the autotuner for XLA, a machine learning compiler, discovered 10-20% speedup on state-of-the-art models serving substantial production traffic at Google. Although there exist a few datasets for program performance prediction, they target small sub-programs such as basic blocks or kernels. This paper introduces TpuGraphs, a performance prediction dataset on full tensor programs, represented as computational graphs, running on Tensor Processing Units (TPUs). Each graph in the dataset represents the main computation of a machine learning workload, e.g., a training epoch or an inference step. Each data sample contains a computational graph, a compilation configuration, and the execution time of the graph when compiled with the configuration. The graphs in the dataset are collected from open-source machine learning programs, featuring popular model architectures, e.g., ResNet, EfficientNet, Mask R-CNN, and Transformer. TpuGraphs provides 25x more graphs than the largest graph property prediction dataset (with comparable graph sizes), and 770x larger graphs on average compared to existing performance prediction datasets on machine learning programs. This graph-level prediction task on large graphs introduces new challenges in learning, ranging from scalability, training efficiency, to model quality.
A Fast Minimization Algorithm for the Euler Elastica Model Based on a Bilinear Decomposition
Aug 25, 2023
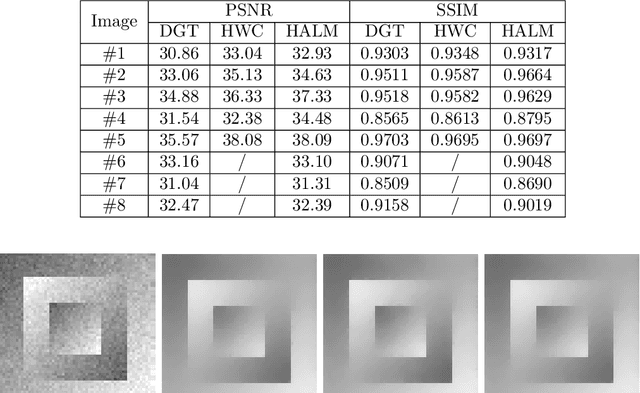

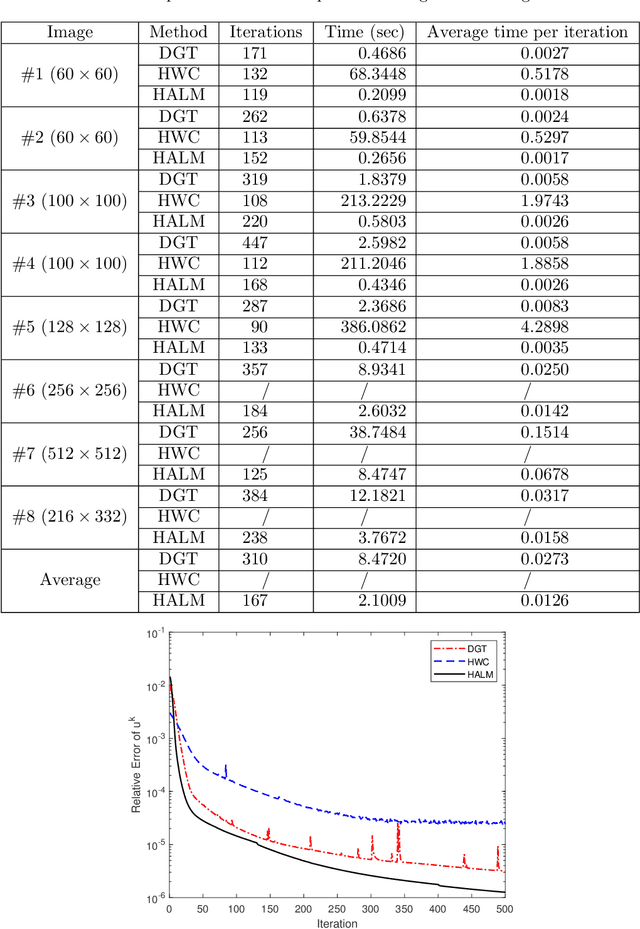
The Euler Elastica (EE) model with surface curvature can generate artifact-free results compared with the traditional total variation regularization model in image processing. However, strong nonlinearity and singularity due to the curvature term in the EE model pose a great challenge for one to design fast and stable algorithms for the EE model. In this paper, we propose a new, fast, hybrid alternating minimization (HALM) algorithm for the EE model based on a bilinear decomposition of the gradient of the underlying image and prove the global convergence of the minimizing sequence generated by the algorithm under mild conditions. The HALM algorithm comprises three sub-minimization problems and each is either solved in the closed form or approximated by fast solvers making the new algorithm highly accurate and efficient. We also discuss the extension of the HALM strategy to deal with general curvature-based variational models, especially with a Lipschitz smooth functional of the curvature. A host of numerical experiments are conducted to show that the new algorithm produces good results with much-improved efficiency compared to other state-of-the-art algorithms for the EE model. As one of the benchmarks, we show that the average running time of the HALM algorithm is at most one-quarter of that of the fast operator-splitting-based Deng-Glowinski-Tai algorithm.
FrFT based estimation of linear and nonlinear impairments using Vision Transformer
Aug 25, 2023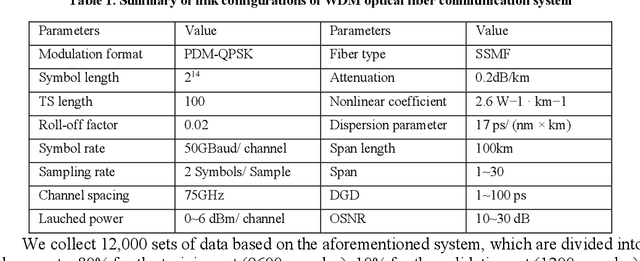
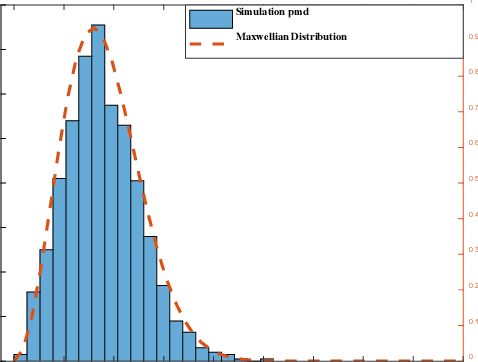
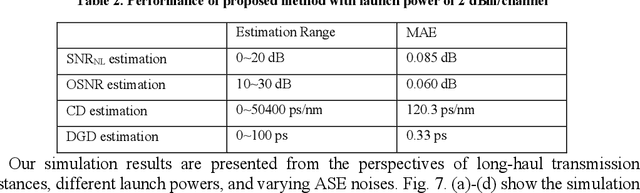
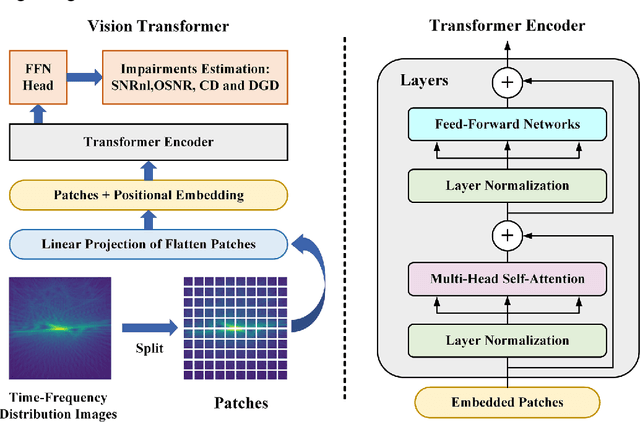
To comprehensively assess optical fiber communication system conditions, it is essential to implement joint estimation of the following four critical impairments: nonlinear signal-to-noise ratio (SNRNL), optical signal-to-noise ratio (OSNR), chromatic dispersion (CD) and differential group delay (DGD). However, current studies only achieve identifying a limited number of impairments within a narrow range, due to limitations in network capabilities and lack of unified representation of impairments. To address these challenges, we adopt time-frequency signal processing based on fractional Fourier transform (FrFT) to achieve the unified representation of impairments, while employing a Transformer based neural networks (NN) to break through network performance limitations. To verify the effectiveness of the proposed estimation method, the numerical simulation is carried on a 5-channel polarization-division-multiplexed quadrature phase shift keying (PDM-QPSK) long haul optical transmission system with the symbol rate of 50 GBaud per channel, the mean absolute error (MAE) for SNRNL, OSNR, CD, and DGD estimation is 0.091 dB, 0.058 dB, 117 ps/nm, and 0.38 ps, and the monitoring window ranges from 0~20 dB, 10~30 dB, 0~51000 ps/nm, and 0~100 ps, respectively. Our proposed method achieves accurate estimation of linear and nonlinear impairments over a broad range, representing a significant advancement in the field of optical performance monitoring (OPM).
MultiCapCLIP: Auto-Encoding Prompts for Zero-Shot Multilingual Visual Captioning
Aug 25, 2023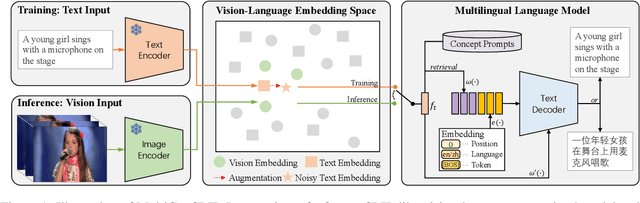
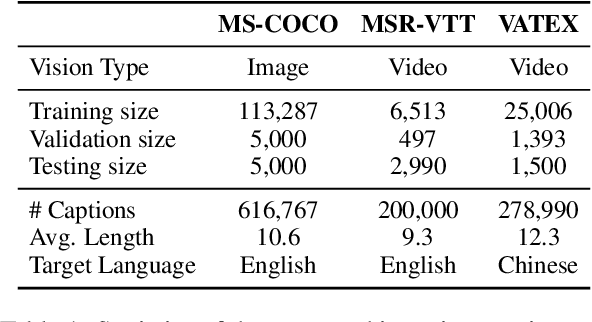
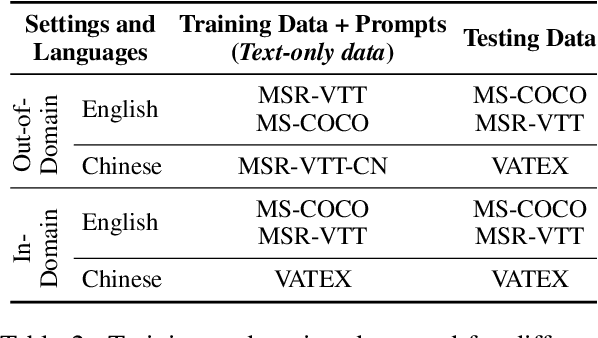
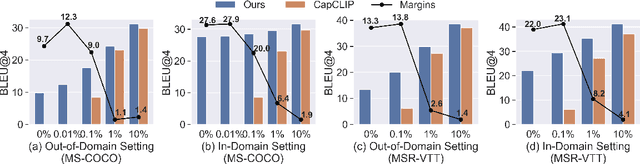
Supervised visual captioning models typically require a large scale of images or videos paired with descriptions in a specific language (i.e., the vision-caption pairs) for training. However, collecting and labeling large-scale datasets is time-consuming and expensive for many scenarios and languages. Therefore, sufficient labeled pairs are usually not available. To deal with the label shortage problem, we present a simple yet effective zero-shot approach MultiCapCLIP that can generate visual captions for different scenarios and languages without any labeled vision-caption pairs of downstream datasets. In the training stage, MultiCapCLIP only requires text data for input. Then it conducts two main steps: 1) retrieving concept prompts that preserve the corresponding domain knowledge of new scenarios; 2) auto-encoding the prompts to learn writing styles to output captions in a desired language. In the testing stage, MultiCapCLIP instead takes visual data as input directly to retrieve the concept prompts to generate the final visual descriptions. The extensive experiments on image and video captioning across four benchmarks and four languages (i.e., English, Chinese, German, and French) confirm the effectiveness of our approach. Compared with state-of-the-art zero-shot and weakly-supervised methods, our method achieves 4.8% and 21.5% absolute improvements in terms of BLEU@4 and CIDEr metrics. Our code is available at https://github.com/yangbang18/MultiCapCLIP.