 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuleFlow : Generating Reusable Program Optimizations with LLMs
Feb 06, 2026Optimizing Pandas programs is a challenging problem. Existing systems and compiler-based approaches offer reliability but are either heavyweight or support only a limited set of optimizations. Conversely, using LLMs in a per-program optimization methodology can synthesize nontrivial optimizations, but is unreliable, expensive, and offers a low yield. In this work, we introduce a hybrid approach that works in a 3-stage manner that decouples discovery from deployment and connects them via a novel bridge. First, it discovers per-program optimizations (discovery). Second, they are converted into generalised rewrite rules (bridge). Finally, these rules are incorporated into a compiler that can automatically apply them wherever applicable, eliminating repeated reliance on LLMs (deployment). We demonstrate that RuleFlow is the new state-of-the-art (SOTA) Pandas optimization framework on PandasBench, a challenging Pandas benchmark consisting of Python notebooks. Across these notebooks, we achieve a speedup of up to 4.3x over Dias, the previous compiler-based SOTA, and 1914.9x over Modin, the previous systems-based SOTA. Our code is available at https://github.com/ADAPT-uiuc/RuleFlow.
A Tensor-Based Compiler and a Runtime for Neuron-Level DNN Certifier Specifications
Jul 26, 2025



The uninterpretability of DNNs has led to the adoption of abstract interpretation-based certification as a practical means to establish trust in real-world systems that rely on DNNs. However, the current landscape supports only a limited set of certifiers, and developing new ones or modifying existing ones for different applications remains difficult. This is because the mathematical design of certifiers is expressed at the neuron level, while their implementations are optimized and executed at the tensor level. This mismatch creates a semantic gap between design and implementation, making manual bridging both complex and expertise-intensive -- requiring deep knowledge in formal methods, high-performance computing, etc. We propose a compiler framework that automatically translates neuron-level specifications of DNN certifiers into tensor-based, layer-level implementations. This is enabled by two key innovations: a novel stack-based intermediate representation (IR) and a shape analysis that infers the implicit tensor operations needed to simulate the neuron-level semantics. During lifting, the shape analysis creates tensors in the minimal shape required to perform the corresponding operations. The IR also enables domain-specific optimizations as rewrites. At runtime, the resulting tensor computations exhibit sparsity tied to the DNN architecture. This sparsity does not align well with existing formats. To address this, we introduce g-BCSR, a double-compression format that represents tensors as collections of blocks of varying sizes, each possibly internally sparse. Using our compiler and g-BCSR, we make it easy to develop new certifiers and analyze their utility across diverse DNNs. Despite its flexibility, the compiler achieves performance comparable to hand-optimized implementations.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024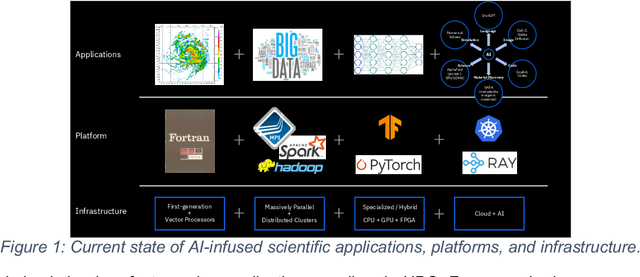
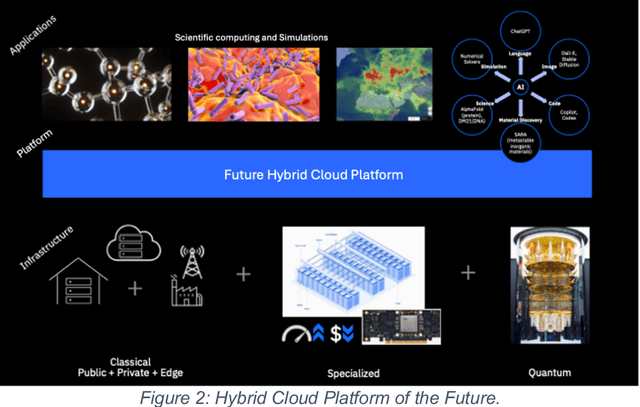
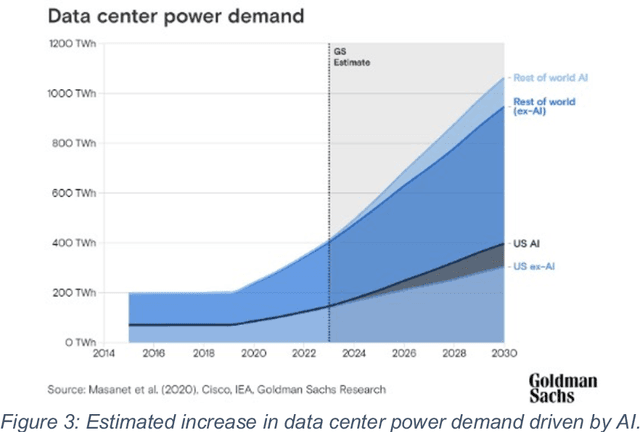
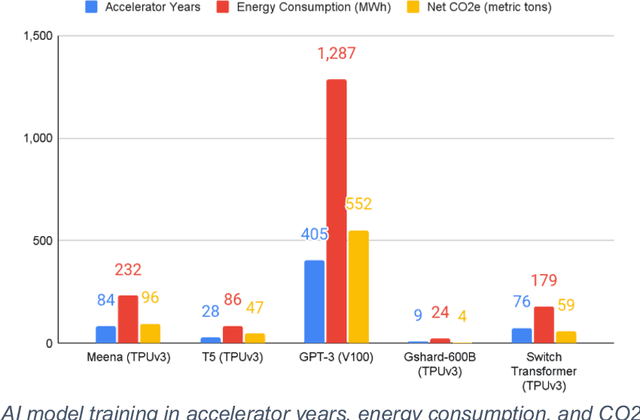
This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
SPLAT: A framework for optimised GPU code-generation for SParse reguLar ATtention
Jul 23, 2024



Multi-head-self-attention (MHSA) mechanisms achieve state-of-the-art (SOTA) performance across natural language processing and vision tasks. However, their quadratic dependence on sequence lengths has bottlenecked inference speeds. To circumvent this bottleneck, researchers have proposed various sparse-MHSA models, where a subset of full attention is computed. Despite their promise, current sparse libraries and compilers do not support high-performance implementations for diverse sparse-MHSA patterns due to the underlying sparse formats they operate on. These formats, which are typically designed for high-performance & scientific computing applications, are either curated for extreme amounts of random sparsity (<1% non-zero values), or specific sparsity patterns. However, the sparsity patterns in sparse-MHSA are moderately sparse (10-50% non-zero values) and varied, resulting in existing sparse-formats trading off generality for performance. We bridge this gap, achieving both generality and performance, by proposing a novel sparse format: affine-compressed-sparse-row (ACSR) and supporting code-generation scheme, SPLAT, that generates high-performance implementations for diverse sparse-MHSA patterns on GPUs. Core to our proposed format and code generation algorithm is the observation that common sparse-MHSA patterns have uniquely regular geometric properties. These properties, which can be analyzed just-in-time, expose novel optimizations and tiling strategies that SPLAT exploits to generate high-performance implementations for diverse patterns. To demonstrate SPLAT's efficacy, we use it to generate code for various sparse-MHSA models, achieving geomean speedups of 2.05x and 4.05x over hand-written kernels written in triton and TVM respectively on A100 GPUs. Moreover, its interfaces are intuitive and easy to use with existing implementations of MHSA in JAX.
TpuGraphs: A Performance Prediction Dataset on Large Tensor Computational Graphs
Aug 25, 2023



Precise hardware performance models play a crucial role in code optimizations. They can assist compilers in making heuristic decisions or aid autotuners in identifying the optimal configuration for a given program. For example, the autotuner for XLA, a machine learning compiler, discovered 10-20% speedup on state-of-the-art models serving substantial production traffic at Google. Although there exist a few datasets for program performance prediction, they target small sub-programs such as basic blocks or kernels. This paper introduces TpuGraphs, a performance prediction dataset on full tensor programs, represented as computational graphs, running on Tensor Processing Units (TPUs). Each graph in the dataset represents the main computation of a machine learning workload, e.g., a training epoch or an inference step. Each data sample contains a computational graph, a compilation configuration, and the execution time of the graph when compiled with the configuration. The graphs in the dataset are collected from open-source machine learning programs, featuring popular model architectures, e.g., ResNet, EfficientNet, Mask R-CNN, and Transformer. TpuGraphs provides 25x more graphs than the largest graph property prediction dataset (with comparable graph sizes), and 770x larger graphs on average compared to existing performance prediction datasets on machine learning programs. This graph-level prediction task on large graphs introduces new challenges in learning, ranging from scalability, training efficiency, to model quality.
Input-sensitive dense-sparse primitive compositions for GNN acceleration
Jun 27, 2023



Graph neural networks (GNN) have become an important class of neural network models that have gained popularity in domains such as social and financial network analysis. Different phases of GNN computations can be modeled using both dense and sparse matrix operations. There have been many frameworks and optimization techniques proposed in the literature to accelerate GNNs. However, getting consistently high performance across many input graphs with different sparsity patterns and GNN embedding sizes has remained difficult. In this paper, we propose different algebraic reassociations of GNN computations that lead to novel dense and sparse matrix primitive selections and compositions. We show that the profitability of these compositions depends on the input graph, embedding size, and the target hardware. We developed SENSEi, a system that uses a data-driven adaptive strategy to select the best composition given the input graph and GNN embedding sizes. Our evaluations on a wide range of graphs and embedding sizes show that SENSEi achieves geomean speedups of $1.105\times$ (up to $2.959\times$) and $1.187\times$ (up to $1.99\times$) on graph convolutional networks and geomean speedups of $2.307\times$ (up to $35.866\times$) and $1.44\times$ (up to $5.69\times$) on graph attention networks on CPUs and GPUs respectively over the widely used Deep Graph Library. Further, we show that the compositions yield notable synergistic performance benefits on top of other established sparse optimizations such as sparse matrix tiling by evaluating against a well-tuned baseline.
FLuRKA: Fast fused Low-Rank & Kernel Attention
Jun 27, 2023



Many efficient approximate self-attention techniques have become prevalent since the inception of the transformer architecture. Two popular classes of these techniques are low-rank and kernel methods. Each of these methods has its own strengths. We observe these strengths synergistically complement each other and exploit these synergies to fuse low-rank and kernel methods, producing a new class of transformers: FLuRKA (Fast Low-Rank and Kernel Attention). FLuRKA provide sizable performance gains over these approximate techniques and are of high quality. We theoretically and empirically evaluate both the runtime performance and quality of FLuRKA. Our runtime analysis posits a variety of parameter configurations where FLuRKA exhibit speedups and our accuracy analysis bounds the error of FLuRKA with respect to full-attention. We instantiate three FLuRKA variants which experience empirical speedups of up to 3.3x and 1.7x over low-rank and kernel methods respectively. This translates to speedups of up to 30x over models with full-attention. With respect to model quality, FLuRKA can match the accuracy of low-rank and kernel methods on GLUE after pre-training on wiki-text 103. When pre-training on a fixed time budget, FLuRKA yield better perplexity scores than models with full-attention.
Learning Large Graph Property Prediction via Graph Segment Training
May 21, 2023



Learning to predict properties of large graphs is challenging because each prediction requires the knowledge of an entire graph, while the amount of memory available during training is bounded. Here we propose Graph Segment Training (GST), a general framework that utilizes a divide-and-conquer approach to allow learning large graph property prediction with a constant memory footprint. GST first divides a large graph into segments and then backpropagates through only a few segments sampled per training iteration. We refine the GST paradigm by introducing a historical embedding table to efficiently obtain embeddings for segments not sampled for backpropagation. To mitigate the staleness of historical embeddings, we design two novel techniques. First, we finetune the prediction head to fix the input distribution shift. Second, we introduce Stale Embedding Dropout to drop some stale embeddings during training to reduce bias. We evaluate our complete method GST-EFD (with all the techniques together) on two large graph property prediction benchmarks: MalNet and TpuGraphs. Our experiments show that GST-EFD is both memory-efficient and fast, while offering a slight boost on test accuracy over a typical full graph training regime.
CoMEt: x86 Cost Model Explanation Framework
Feb 14, 2023



ML-based program cost models have been shown to yield highly accurate predictions. They have the capability to replace heavily-engineered analytical program cost models in mainstream compilers, but their black-box nature discourages their adoption. In this work, we propose the first method for obtaining faithful and intuitive explanations for the throughput predictions made by ML-based cost models. We demonstrate our explanations for the state-of-the-art ML-based cost model, Ithemal. We compare the explanations for Ithemal with the explanations for a hand-crafted, accurate analytical model, uiCA. Our empirical findings show that high similarity between explanations for Ithemal and uiCA usually corresponds to high similarity between their predictions.
GRANITE: A Graph Neural Network Model for Basic Block Throughput Estimation
Oct 11, 2022
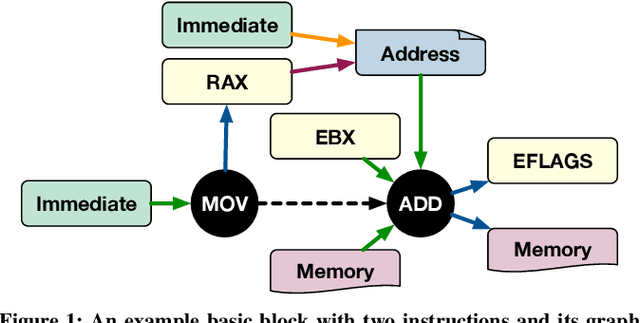
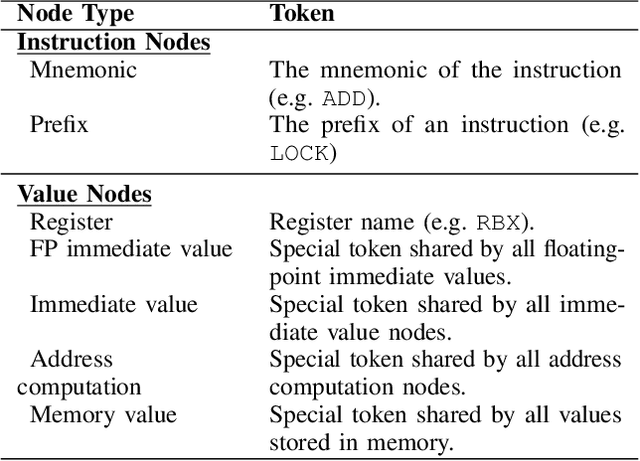
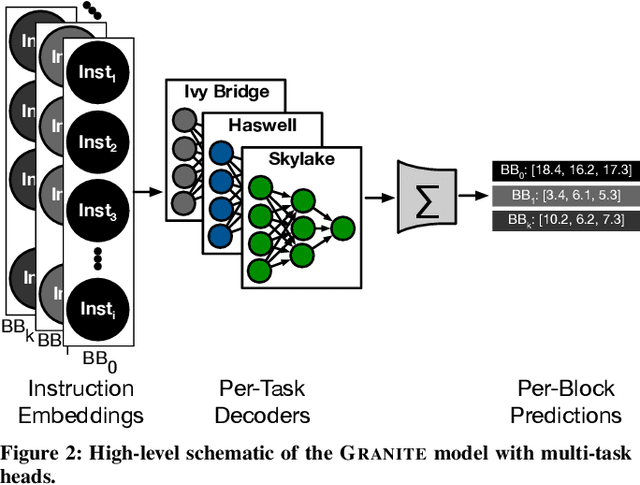
Analytical hardware performance models yield swift estimation of desired hardware performance metrics. However, developing these analytical models for modern processors with sophisticated microarchitectures is an extremely laborious task and requires a firm understanding of target microarchitecture's internal structure. In this paper, we introduce GRANITE, a new machine learning model that estimates the throughput of basic blocks across different microarchitectures. GRANITE uses a graph representation of basic blocks that captures both structural and data dependencies between instructions. This representation is processed using a graph neural network that takes advantage of the relational information captured in the graph and learns a rich neural representation of the basic block that allows more precise throughput estimation. Our results establish a new state-of-the-art for basic block performance estimation with an average test error of 6.9% across a wide range of basic blocks and microarchitectures for the x86-64 target. Compared to recent work, this reduced the error by 1.7% while improving training and inference throughput by approximately 3.0x. In addition, we propose the use of multi-task learning with independent multi-layer feed forward decoder networks. Our results show that this technique further improves precision of all learned models while significantly reducing per-microarchitecture training costs. We perform an extensive set of ablation studies and comparisons with prior work, concluding a set of methods to achieve high accuracy for basic block performance estimation.