 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bridging Expert Knowledge with Deep Learning Techniques for Just-In-Time Defect Prediction
Mar 17, 2024

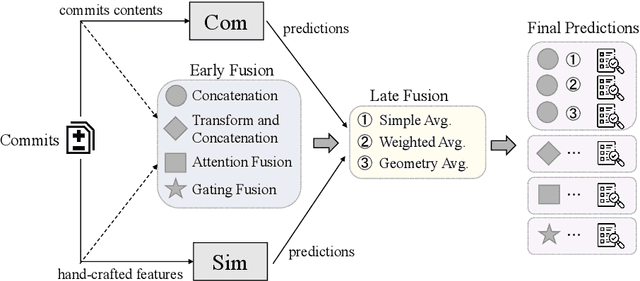
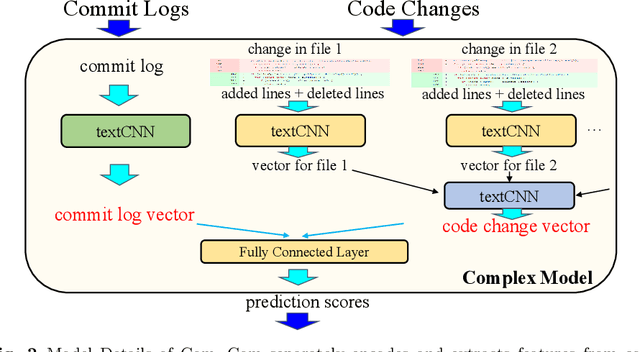
Just-In-Time (JIT) defect prediction aims to automatically predict whether a commit is defective or not, and has been widely studied in recent years. In general, most studies can be classified into two categories: 1) simple models using traditional machine learning classifiers with hand-crafted features, and 2) complex models using deep learning techniques to automatically extract features from commit contents. Hand-crafted features used by simple models are based on expert knowledge but may not fully represent the semantic meaning of the commits. On the other hand, deep learning-based features used by complex models represent the semantic meaning of commits but may not reflect useful expert knowledge. Simple models and complex models seem complementary to each other to some extent. To utilize the advantages of both simple and complex models, we propose a model fusion framework that adopts both early fusions on the feature level and late fusions on the decision level. We propose SimCom++ by adopting the best early and late fusion strategies. The experimental results show that SimCom++ can significantly outperform the baselines by 5.7--26.9\%. In addition, our experimental results confirm that the simple model and complex model are complementary to each other.
Isotropic Gaussian Splatting for Real-Time Radiance Field Rendering
Mar 21, 2024

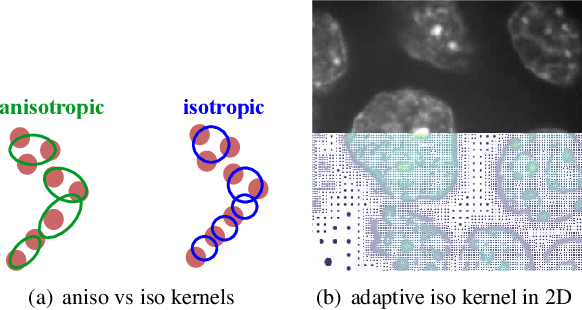

The 3D Gaussian splatting method has drawn a lot of attention, thanks to its high performance in training and high quality of the rendered image. However, it uses anisotropic Gaussian kernels to represent the scene. Although such anisotropic kernels have advantages in representing the geometry, they lead to difficulties in terms of computation, such as splitting or merging two kernels. In this paper, we propose to use isotropic Gaussian kernels to avoid such difficulties in the computation, leading to a higher performance method. The experiments confirm that the proposed method is about {\bf 100X} faster without losing the geometry representation accuracy. The proposed method can be applied in a large range applications where the radiance field is needed, such as 3D reconstruction, view synthesis, and dynamic object modeling.
Towards 3D Vision with Low-Cost Single-Photon Cameras
Mar 29, 2024We present a method for reconstructing 3D shape of arbitrary Lambertian objects based on measurements by miniature, energy-efficient, low-cost single-photon cameras. These cameras, operating as time resolved image sensors, illuminate the scene with a very fast pulse of diffuse light and record the shape of that pulse as it returns back from the scene at a high temporal resolution. We propose to model this image formation process, account for its non-idealities, and adapt neural rendering to reconstruct 3D geometry from a set of spatially distributed sensors with known poses. We show that our approach can successfully recover complex 3D shapes from simulated data. We further demonstrate 3D object reconstruction from real-world captures, utilizing measurements from a commodity proximity sensor. Our work draws a connection between image-based modeling and active range scanning and is a step towards 3D vision with single-photon cameras.
Design, Fabrication and Evaluation of a Stretchable High-Density Electromyography Array
Mar 29, 2024

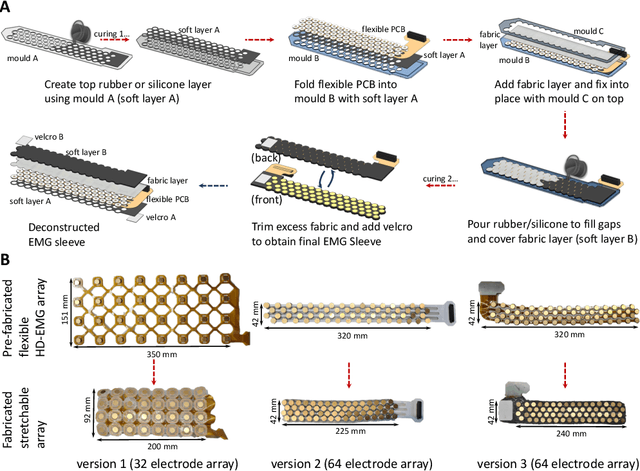

The adoption of high-density electrode systems for human-machine interfaces in real-life applications has been impeded by practical and technical challenges, including noise interference, motion artifacts and the lack of compact electrode interfaces. To overcome some of these challenges, we introduce a wearable and stretchable electromyography (EMG) array, and present its design, fabrication methodology, characterisation, and comprehensive evaluation. Our proposed solution comprises dry-electrodes on flexible printed circuit board (PCB) substrates, eliminating the need for time-consuming skin preparation. The proposed fabrication method allows the manufacturing of stretchable sleeves, with consistent and standardised coverage across subjects. We thoroughly tested our developed prototype, evaluating its potential for application in both research and real-world environments. The results of our study showed that the developed stretchable array matches or outperforms traditional EMG grids and holds promise in furthering the real-world translation of high-density EMG for human-machine interfaces.
* This is the author's version of the manuscript published in MDPI Sensors journal - https://www.mdpi.com/1424-8220/24/6/1810 , This manuscript is in IEEE format - 8 pages, 5 figures, 1 table
Cooperative Sensing and Communication for ISAC Networks: Performance Analysis and Optimization
Mar 29, 2024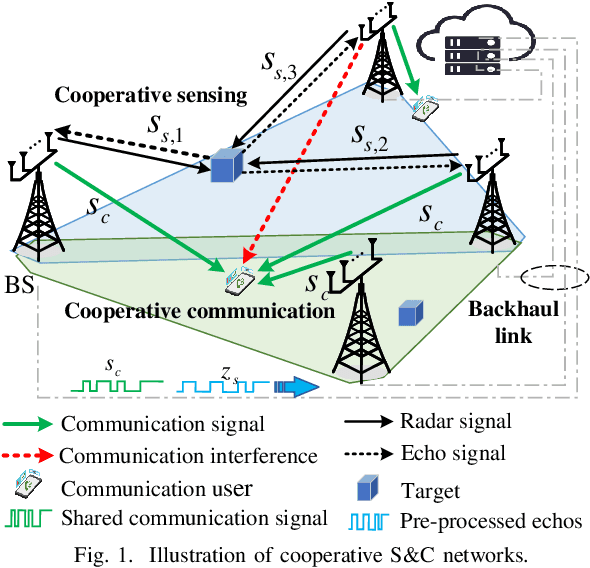
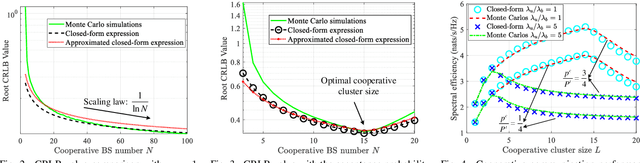
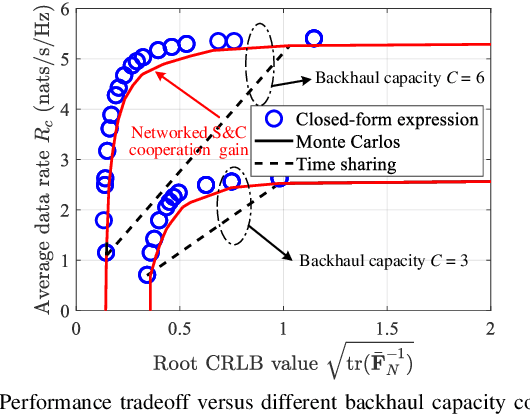
In this work, we study integrated sensing and communication (ISAC) networks intending to effectively balance sensing and communication (S&C) performance at the network level. Through the simultaneous utilization of multi-point (CoMP) coordinated joint transmission and distributed multiple-input multiple-output (MIMO) radar techniques, we propose a cooperative networked ISAC scheme to enhance both S&C services. Then, the tool of stochastic geometry is exploited to capture the S&C performance, which allows us to illuminate key cooperative dependencies in the ISAC network. Remarkably, the derived expression of the Cramer-Rao lower bound (CRLB) of the localization accuracy unveils a significant finding: Deploying $N$ ISAC transceivers yields an enhanced sensing performance across the entire network, in accordance with the $\ln^2N$ scaling law. Simulation results demonstrate that compared to the time-sharing scheme, the proposed cooperative ISAC scheme can effectively improve the average data rate and reduce the CRLB.
Guessing human intentions to avoid dangerous situations in caregiving robots
Mar 26, 2024For robots to interact socially, they must interpret human intentions and anticipate their potential outcomes accurately. This is particularly important for social robots designed for human care, which may face potentially dangerous situations for people, such as unseen obstacles in their way, that should be avoided. This paper explores the Artificial Theory of Mind (ATM) approach to inferring and interpreting human intentions. We propose an algorithm that detects risky situations for humans, selecting a robot action that removes the danger in real time. We use the simulation-based approach to ATM and adopt the 'like-me' policy to assign intentions and actions to people. Using this strategy, the robot can detect and act with a high rate of success under time-constrained situations. The algorithm has been implemented as part of an existing robotics cognitive architecture and tested in simulation scenarios. Three experiments have been conducted to test the implementation's robustness, precision and real-time response, including a simulated scenario, a human-in-the-loop hybrid configuration and a real-world scenario.
Track Everything Everywhere Fast and Robustly
Mar 26, 2024We propose a novel test-time optimization approach for efficiently and robustly tracking any pixel at any time in a video. The latest state-of-the-art optimization-based tracking technique, OmniMotion, requires a prohibitively long optimization time, rendering it impractical for downstream applications. OmniMotion is sensitive to the choice of random seeds, leading to unstable convergence. To improve efficiency and robustness, we introduce a novel invertible deformation network, CaDeX++, which factorizes the function representation into a local spatial-temporal feature grid and enhances the expressivity of the coupling blocks with non-linear functions. While CaDeX++ incorporates a stronger geometric bias within its architectural design, it also takes advantage of the inductive bias provided by the vision foundation models. Our system utilizes monocular depth estimation to represent scene geometry and enhances the objective by incorporating DINOv2 long-term semantics to regulate the optimization process. Our experiments demonstrate a substantial improvement in training speed (more than \textbf{10 times} faster), robustness, and accuracy in tracking over the SoTA optimization-based method OmniMotion.
Long-form factuality in large language models
Mar 27, 2024Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can achieve superhuman rating performance - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.
Right Place, Right Time! Towards ObjectNav for Non-Stationary Goals
Mar 14, 2024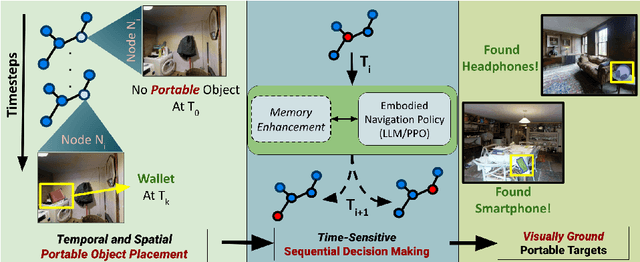
We present a novel approach to tackle the ObjectNav task for non-stationary and potentially occluded targets in an indoor environment. We refer to this task Portable ObjectNav (or P-ObjectNav), and in this work, present its formulation, feasibility, and a navigation benchmark using a novel memory-enhanced LLM-based policy. In contrast to ObjNav where target object locations are fixed for each episode, P-ObjectNav tackles the challenging case where the target objects move during the episode. This adds a layer of time-sensitivity to navigation, and is particularly relevant in scenarios where the agent needs to find portable targets (e.g. misplaced wallets) in human-centric environments. The agent needs to estimate not just the correct location of the target, but also the time at which the target is at that location for visual grounding -- raising the question about the feasibility of the task. We address this concern by inferring results on two cases for object placement: one where the objects placed follow a routine or a path, and the other where they are placed at random. We dynamize Matterport3D for these experiments, and modify PPO and LLM-based navigation policies for evaluation. Using PPO, we observe that agent performance in the random case stagnates, while the agent in the routine-following environment continues to improve, allowing us to infer that P-ObjectNav is solvable in environments with routine-following object placement. Using memory-enhancement on an LLM-based policy, we set a benchmark for P-ObjectNav. Our memory-enhanced agent significantly outperforms their non-memory-based counterparts across object placement scenarios by 71.76% and 74.68% on average when measured by Success Rate (SR) and Success Rate weighted by Path Length (SRPL), showing the influence of memory on improving P-ObjectNav performance. Our code and dataset will be made publicly available.
Towards Controllable Time Series Generation
Mar 06, 2024
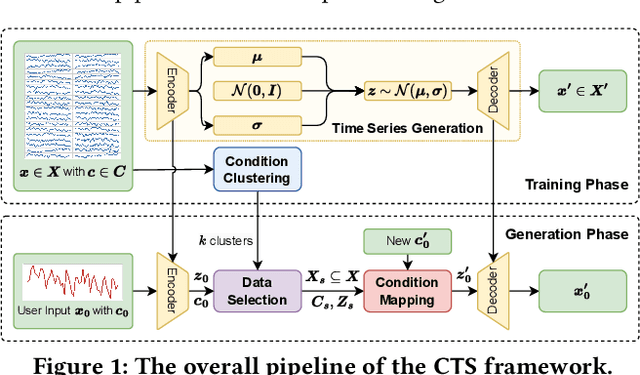
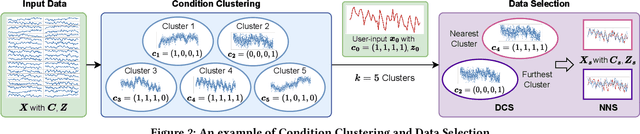
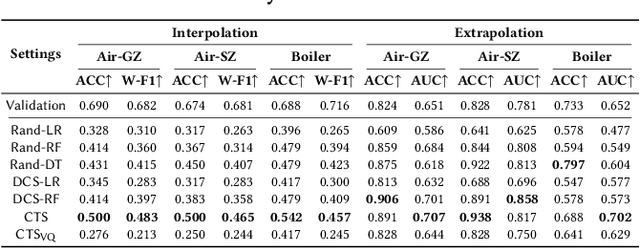
Time Series Generation (TSG) has emerged as a pivotal technique in synthesizing data that accurately mirrors real-world time series, becoming indispensable in numerous applications. Despite significant advancements in TSG, its efficacy frequently hinges on having large training datasets. This dependency presents a substantial challenge in data-scarce scenarios, especially when dealing with rare or unique conditions. To confront these challenges, we explore a new problem of Controllable Time Series Generation (CTSG), aiming to produce synthetic time series that can adapt to various external conditions, thereby tackling the data scarcity issue. In this paper, we propose \textbf{C}ontrollable \textbf{T}ime \textbf{S}eries (\textsf{CTS}), an innovative VAE-agnostic framework tailored for CTSG. A key feature of \textsf{CTS} is that it decouples the mapping process from standard VAE training, enabling precise learning of a complex interplay between latent features and external conditions. Moreover, we develop a comprehensive evaluation scheme for CTSG. Extensive experiments across three real-world time series datasets showcase \textsf{CTS}'s exceptional capabilities in generating high-quality, controllable outputs. This underscores its adeptness in seamlessly integrating latent features with external conditions. Extending \textsf{CTS} to the image domain highlights its remarkable potential for explainability and further reinforces its versatility across different modalities.