 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tool Dependency Retrieval for Efficient Function Calling
Dec 23, 2025



Function calling agents powered by Large Language Models (LLMs) select external tools to automate complex tasks. On-device agents typically use a retrieval module to select relevant tools, improving performance and reducing context length. However, existing retrieval methods rely on static and limited inputs, failing to capture multi-step tool dependencies and evolving task context. This limitation often introduces irrelevant tools that mislead the agent, degrading efficiency and accuracy. We propose Dynamic Tool Dependency Retrieval (DTDR), a lightweight retrieval method that conditions on both the initial query and the evolving execution context. DTDR models tool dependencies from function calling demonstrations, enabling adaptive retrieval as plans unfold. We benchmark DTDR against state-of-the-art retrieval methods across multiple datasets and LLM backbones, evaluating retrieval precision, downstream task accuracy, and computational efficiency. Additionally, we explore strategies to integrate retrieved tools into prompts. Our results show that dynamic tool retrieval improves function calling success rates between $23\%$ and $104\%$ compared to state-of-the-art static retrievers.
Learning API Functionality from Demonstrations for Tool-based Agents
May 30, 2025Digital tool-based agents that invoke external Application Programming Interfaces (APIs) often rely on documentation to understand API functionality. However, such documentation is frequently missing, outdated, privatized, or inconsistent-hindering the development of reliable, general-purpose agents. In this work, we propose learning API functionality directly from demonstrations as a new paradigm applicable in scenarios without documentation. Using existing API benchmarks, we collect demonstrations from both expert API-based agents and from self-exploration. To understand what information demonstrations must convey for successful task completion, we extensively study how the number of demonstrations and the use of LLM-generated summaries and evaluations affect the task success rate of the API-based agent. Our experiments across 3 datasets and 5 models show that learning functionality from demonstrations remains a non-trivial challenge, even for state-of-the-art LLMs. We find that providing explicit function calls and natural language critiques significantly improves the agent's task success rate due to more accurate parameter filling. We analyze failure modes, identify sources of error, and highlight key open challenges for future work in documentation-free, self-improving, API-based agents.
AIME: AI System Optimization via Multiple LLM Evaluators
Oct 04, 2024Text-based AI system optimization typically involves a feedback loop scheme where a single LLM generates an evaluation in natural language of the current output to improve the next iteration's output. However, in this work, we empirically demonstrate that for a practical and complex task (code generation) with multiple criteria to evaluate, utilizing only one LLM evaluator tends to let errors in generated code go undetected, thus leading to incorrect evaluations and ultimately suboptimal test case performance. Motivated by this failure case, we assume there exists an optimal evaluation policy that samples an evaluation between response and ground truth. We then theoretically prove that a linear combination of multiple evaluators can approximate this optimal policy. From this insight, we propose AI system optimization via Multiple LLM Evaluators (AIME). AIME is an evaluation protocol that utilizes multiple LLMs that each independently generate an evaluation on separate criteria and then combine them via concatenation. We provide an extensive empirical study showing AIME outperforming baseline methods in code generation tasks, with up to $62\%$ higher error detection rate and up to $16\%$ higher success rate than a single LLM evaluation protocol on LeetCodeHard and HumanEval datasets. We also show that the selection of the number of evaluators and which criteria to utilize is non-trivial as it can impact pact success rate by up to $12\%$.
Embodied Question Answering via Multi-LLM Systems
Jun 18, 2024



Embodied Question Answering (EQA) is an important problem, which involves an agent exploring the environment to answer user queries. In the existing literature, EQA has exclusively been studied in single-agent scenarios, where exploration can be time-consuming and costly. In this work, we consider EQA in a multi-agent framework involving multiple large language models (LLM) based agents independently answering queries about a household environment. To generate one answer for each query, we use the individual responses to train a Central Answer Model (CAM) that aggregates responses for a robust answer. Using CAM, we observe a $50\%$ higher EQA accuracy when compared against aggregation methods for ensemble LLM, such as voting schemes and debates. CAM does not require any form of agent communication, alleviating it from the associated costs. We ablate CAM with various nonlinear (neural network, random forest, decision tree, XGBoost) and linear (logistic regression classifier, SVM) algorithms. Finally, we present a feature importance analysis for CAM via permutation feature importance (PFI), quantifying CAMs reliance on each independent agent and query context.
Global Optimality without Mixing Time Oracles in Average-reward RL via Multi-level Actor-Critic
Mar 18, 2024In the context of average-reward reinforcement learning, the requirement for oracle knowledge of the mixing time, a measure of the duration a Markov chain under a fixed policy needs to achieve its stationary distribution-poses a significant challenge for the global convergence of policy gradient methods. This requirement is particularly problematic due to the difficulty and expense of estimating mixing time in environments with large state spaces, leading to the necessity of impractically long trajectories for effective gradient estimation in practical applications. To address this limitation, we consider the Multi-level Actor-Critic (MAC) framework, which incorporates a Multi-level Monte Carlo (MLMC) gradient estimator. With our approach, we effectively alleviate the dependency on mixing time knowledge, a first for average-reward MDPs global convergence. Furthermore, our approach exhibits the tightest-available dependence of $\mathcal{O}\left( \sqrt{\tau_{mix}} \right)$ relative to prior work. With a 2D gridworld goal-reaching navigation experiment, we demonstrate that MAC achieves higher reward than a previous PG-based method for average reward, Parameterized Policy Gradient with Advantage Estimation (PPGAE), especially in cases with relatively small training sample budget restricting trajectory length.
Right Place, Right Time! Towards ObjectNav for Non-Stationary Goals
Mar 14, 2024



We present a novel approach to tackle the ObjectNav task for non-stationary and potentially occluded targets in an indoor environment. We refer to this task Portable ObjectNav (or P-ObjectNav), and in this work, present its formulation, feasibility, and a navigation benchmark using a novel memory-enhanced LLM-based policy. In contrast to ObjNav where target object locations are fixed for each episode, P-ObjectNav tackles the challenging case where the target objects move during the episode. This adds a layer of time-sensitivity to navigation, and is particularly relevant in scenarios where the agent needs to find portable targets (e.g. misplaced wallets) in human-centric environments. The agent needs to estimate not just the correct location of the target, but also the time at which the target is at that location for visual grounding -- raising the question about the feasibility of the task. We address this concern by inferring results on two cases for object placement: one where the objects placed follow a routine or a path, and the other where they are placed at random. We dynamize Matterport3D for these experiments, and modify PPO and LLM-based navigation policies for evaluation. Using PPO, we observe that agent performance in the random case stagnates, while the agent in the routine-following environment continues to improve, allowing us to infer that P-ObjectNav is solvable in environments with routine-following object placement. Using memory-enhancement on an LLM-based policy, we set a benchmark for P-ObjectNav. Our memory-enhanced agent significantly outperforms their non-memory-based counterparts across object placement scenarios by 71.76% and 74.68% on average when measured by Success Rate (SR) and Success Rate weighted by Path Length (SRPL), showing the influence of memory on improving P-ObjectNav performance. Our code and dataset will be made publicly available.
Ada-NAV: Adaptive Trajectory-Based Sample Efficient Policy Learning for Robotic Navigation
Jun 09, 2023Reinforcement learning methods, while effective for learning robotic navigation strategies, are known to be highly sample inefficient. This sample inefficiency comes in part from not suitably balancing the explore-exploit dilemma, especially in the presence of non-stationarity, during policy optimization. To incorporate a balance of exploration-exploitation for sample efficiency, we propose Ada-NAV, an adaptive trajectory length scheme where the length grows as a policy's randomness, represented by its Shannon or differential entropy, decreases. Our adaptive trajectory length scheme emphasizes exploration at the beginning of training due to more frequent gradient updates and emphasizes exploitation later on with longer trajectories. In gridworld, simulated robotic environments, and real-world robotic experiments, we demonstrate the merits of the approach over constant and randomly sampled trajectory lengths in terms of performance and sample efficiency. For a fixed sample budget, Ada-NAV results in an 18% increase in navigation success rate, a 20-38% decrease in the navigation path length, and 9.32% decrease in the elevation cost compared to the policies obtained by the other methods. We also demonstrate that Ada-NAV can be transferred and integrated into a Clearpath Husky robot without significant performance degradation.
Beyond Exponentially Fast Mixing in Average-Reward Reinforcement Learning via Multi-Level Monte Carlo Actor-Critic
Feb 01, 2023


Many existing reinforcement learning (RL) methods employ stochastic gradient iteration on the back end, whose stability hinges upon a hypothesis that the data-generating process mixes exponentially fast with a rate parameter that appears in the step-size selection. Unfortunately, this assumption is violated for large state spaces or settings with sparse rewards, and the mixing time is unknown, making the step size inoperable. In this work, we propose an RL methodology attuned to the mixing time by employing a multi-level Monte Carlo estimator for the critic, the actor, and the average reward embedded within an actor-critic (AC) algorithm. This method, which we call \textbf{M}ulti-level \textbf{A}ctor-\textbf{C}ritic (MAC), is developed especially for infinite-horizon average-reward settings and neither relies on oracle knowledge of the mixing time in its parameter selection nor assumes its exponential decay; it, therefore, is readily applicable to applications with slower mixing times. Nonetheless, it achieves a convergence rate comparable to the state-of-the-art AC algorithms. We experimentally show that these alleviated restrictions on the technical conditions required for stability translate to superior performance in practice for RL problems with sparse rewards.
In Pursuit of Interpretable, Fair and Accurate Machine Learning for Criminal Recidivism Prediction
May 08, 2020

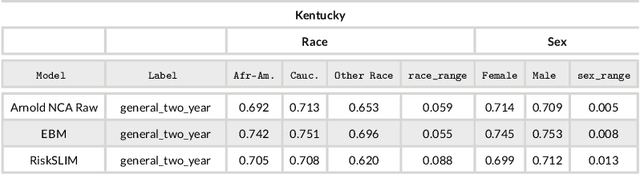
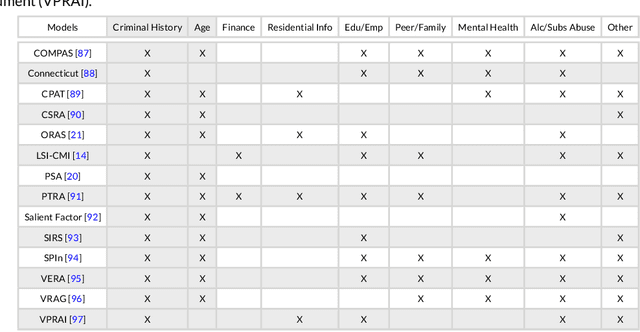
In recent years, academics and investigative journalists have criticized certain commercial risk assessments for their black-box nature and failure to satisfy competing notions of fairness. Since then, the field of interpretable machine learning has created simple yet effective algorithms, while the field of fair machine learning has proposed various mathematical definitions of fairness. However, studies from these fields are largely independent, despite the fact that many applications of machine learning to social issues require both fairness and interpretability. We explore the intersection by revisiting the recidivism prediction problem using state-of-the-art tools from interpretable machine learning, and assessing the models for performance, interpretability, and fairness. Unlike previous works, we compare against two existing risk assessments (COMPAS and the Arnold Public Safety Assessment) and train models that output probabilities rather than binary predictions. We present multiple models that beat these risk assessments in performance, and provide a fairness analysis of these models. Our results imply that machine learning models should be trained separately for separate locations, and updated over time.