 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SODA10M: Towards Large-Scale Object Detection Benchmark for Autonomous Driving
Jun 22, 2021


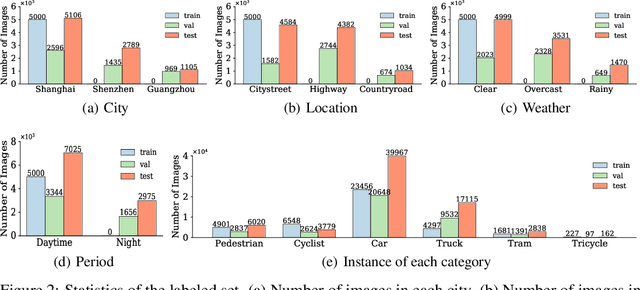
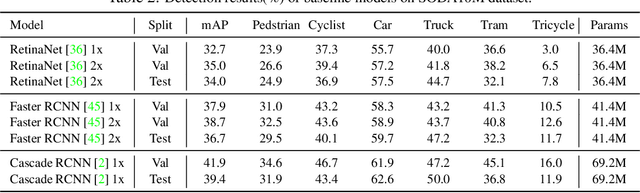
Aiming at facilitating a real-world, ever-evolving and scalable autonomous driving system, we present a large-scale benchmark for standardizing the evaluation of different self-supervised and semi-supervised approaches by learning from raw data, which is the first and largest benchmark to date. Existing autonomous driving systems heavily rely on `perfect' visual perception models (e.g., detection) trained using extensive annotated data to ensure the safety. However, it is unrealistic to elaborately label instances of all scenarios and circumstances (e.g., night, extreme weather, cities) when deploying a robust autonomous driving system. Motivated by recent powerful advances of self-supervised and semi-supervised learning, a promising direction is to learn a robust detection model by collaboratively exploiting large-scale unlabeled data and few labeled data. Existing dataset (e.g., KITTI, Waymo) either provides only a small amount of data or covers limited domains with full annotation, hindering the exploration of large-scale pre-trained models. Here, we release a Large-Scale Object Detection benchmark for Autonomous driving, named as SODA10M, containing 10 million unlabeled images and 20K images labeled with 6 representative object categories. To improve diversity, the images are collected every ten seconds per frame within 32 different cities under different weather conditions, periods and location scenes. We provide extensive experiments and deep analyses of existing supervised state-of-the-art detection models, popular self-supervised and semi-supervised approaches, and some insights about how to develop future models. The data and more up-to-date information have been released at https://soda-2d.github.io.
Model selection by minimum description length: Lower-bound sample sizes for the Fisher information approximation
Aug 01, 2018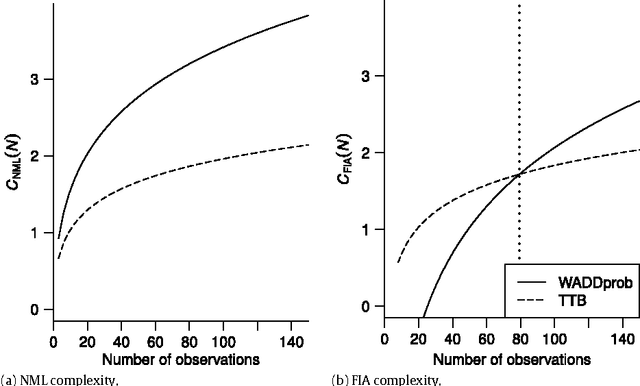
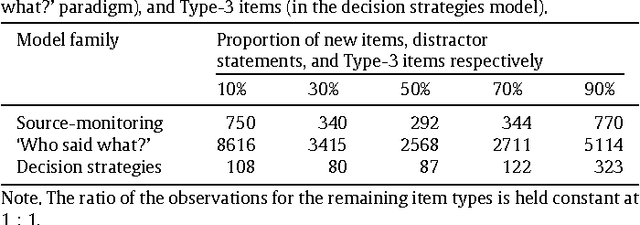
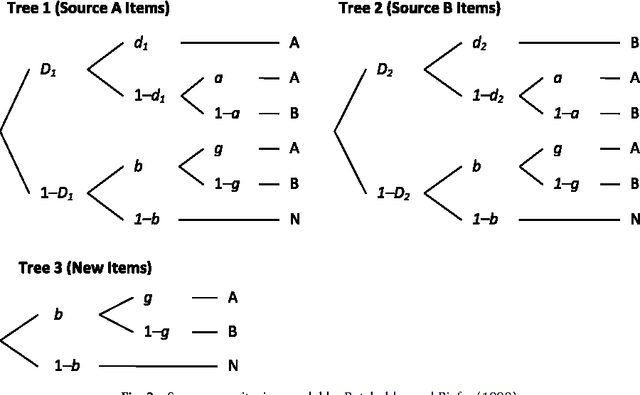
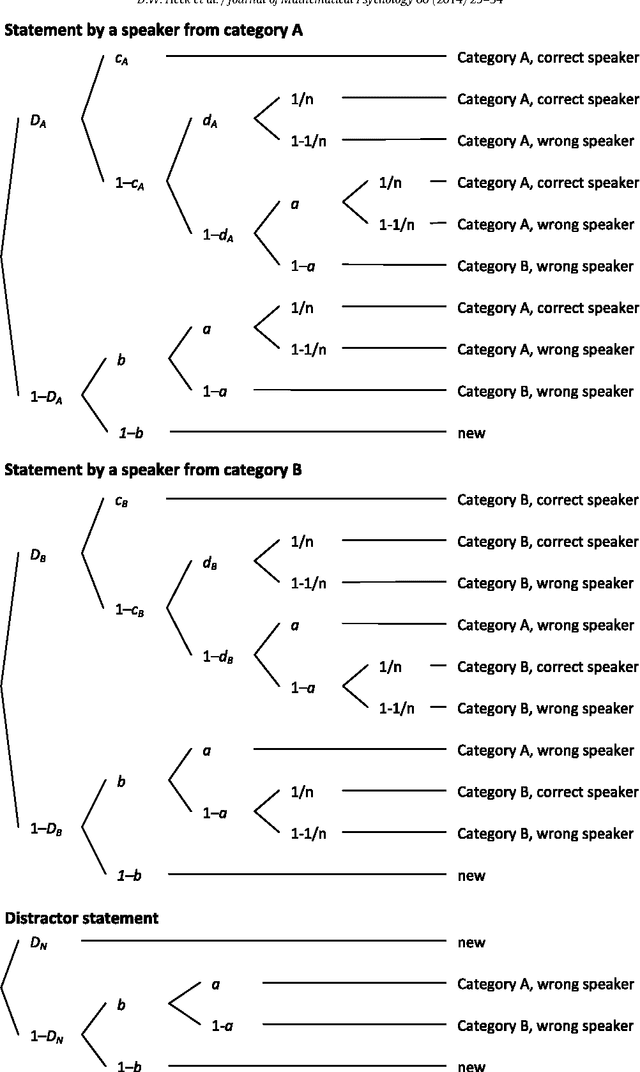
The Fisher information approximation (FIA) is an implementation of the minimum description length principle for model selection. Unlike information criteria such as AIC or BIC, it has the advantage of taking the functional form of a model into account. Unfortunately, FIA can be misleading in finite samples, resulting in an inversion of the correct rank order of complexity terms for competing models in the worst case. As a remedy, we propose a lower-bound $N'$ for the sample size that suffices to preclude such errors. We illustrate the approach using three examples from the family of multinomial processing tree models.
Supporting verification of news articles with automated search for semantically similar articles
Mar 29, 2021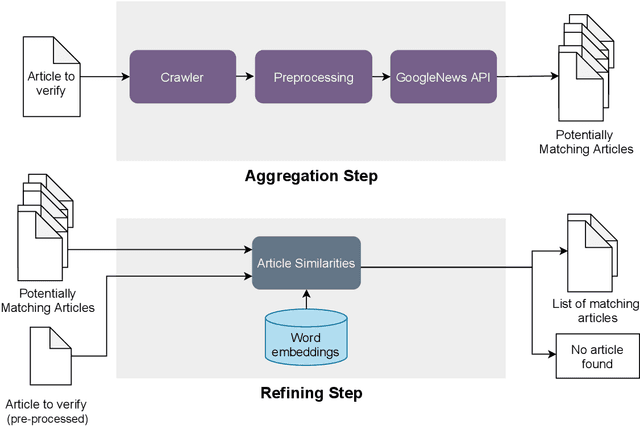
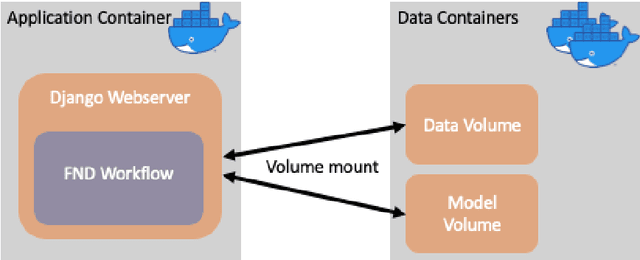

Fake information poses one of the major threats for society in the 21st century. Identifying misinformation has become a key challenge due to the amount of fake news that is published daily. Yet, no approach is established that addresses the dynamics and versatility of fake news editorials. Instead of classifying content, we propose an evidence retrieval approach to handle fake news. The learning task is formulated as an unsupervised machine learning problem. For validation purpose, we provide the user with a set of news articles from reliable news sources supporting the hypothesis of the news article in query and the final decision is left to the user. Technically we propose a two-step process: (i) Aggregation-step: With information extracted from the given text we query for similar content from reliable news sources. (ii) Refining-step: We narrow the supporting evidence down by measuring the semantic distance of the text with the collection from step (i). The distance is calculated based on Word2Vec and the Word Mover's Distance. In our experiments, only content that is below a certain distance threshold is considered as supporting evidence. We find that our approach is agnostic to concept drifts, i.e. the machine learning task is independent of the hypotheses in a text. This makes it highly adaptable in times where fake news is as diverse as classical news is. Our pipeline offers the possibility for further analysis in the future, such as investigating bias and differences in news reporting.
Design principles for a hybrid intelligence decision support system for business model validation
May 07, 2021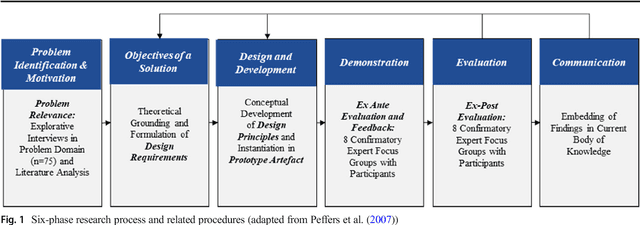
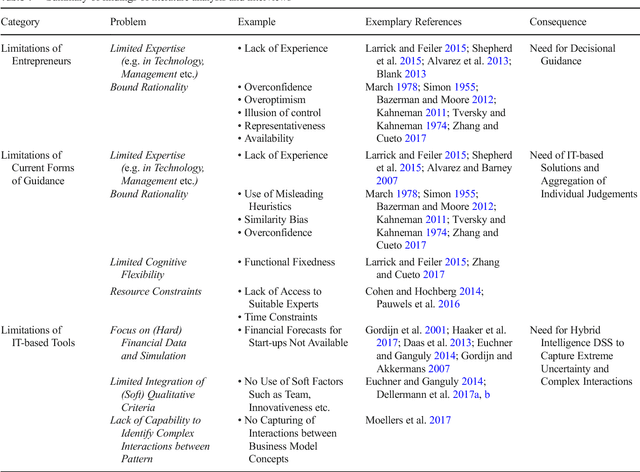
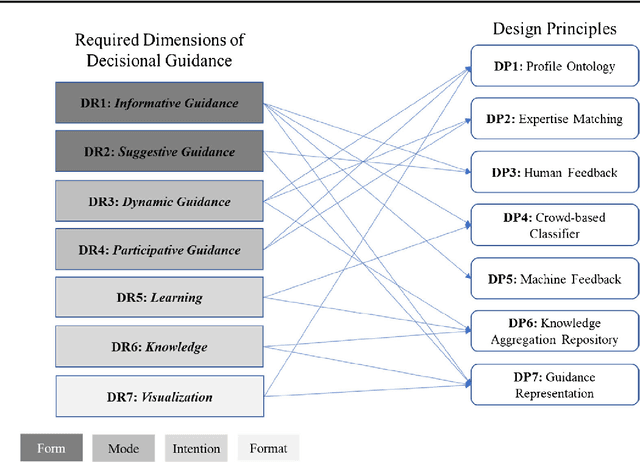
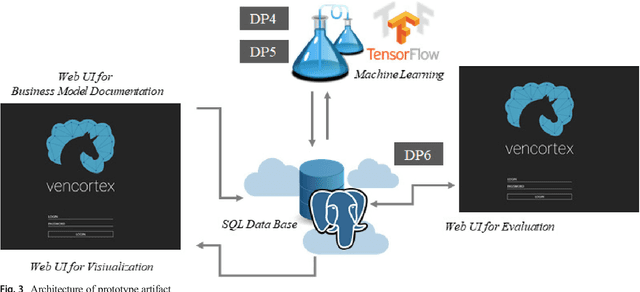
One of the most critical tasks for startups is to validate their business model. Therefore, entrepreneurs try to collect information such as feedback from other actors to assess the validity of their assumptions and make decisions. However, previous work on decisional guidance for business model validation provides no solution for the highly uncertain and complex context of earlystage startups. The purpose of this paper is, thus, to develop design principles for a Hybrid Intelligence decision support system (HI-DSS) that combines the complementary capabilities of human and machine intelligence. We follow a design science research approach to design a prototype artifact and a set of design principles. Our study provides prescriptive knowledge for HI-DSS and contributes to previous work on decision support for business models, the applications of complementary strengths of humans and machines for making decisions, and support systems for extremely uncertain decision-making problems.
Cloth-Changing Person Re-identification from A Single Image with Gait Prediction and Regularization
Mar 29, 2021
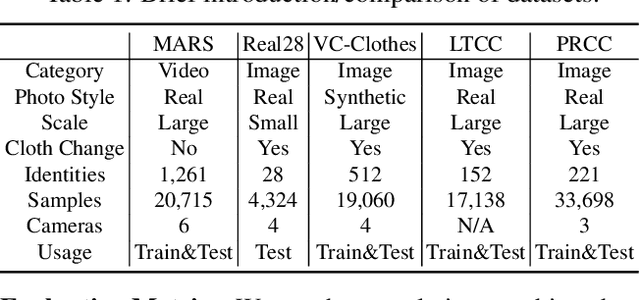
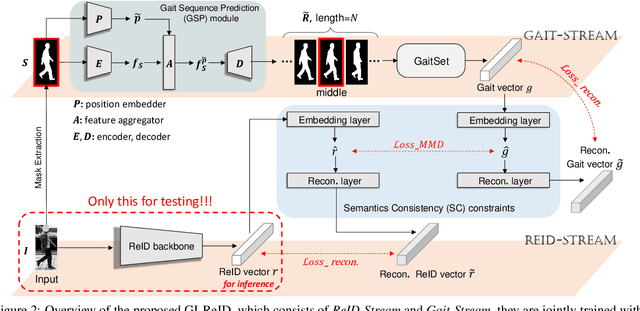
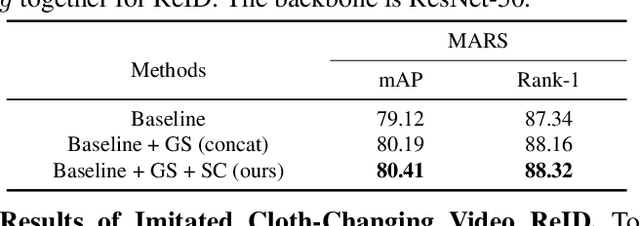
Cloth-Changing person re-identification (CC-ReID) aims at matching the same person across different locations over a long-duration, e.g., over days, and therefore inevitably meets challenge of changing clothing. In this paper, we focus on handling well the CC-ReID problem under a more challenging setting, i.e., just from a single image, which enables high-efficiency and latency-free pedestrian identify for real-time surveillance applications. Specifically, we introduce Gait recognition as an auxiliary task to drive the Image ReID model to learn cloth-agnostic representations by leveraging personal unique and cloth-independent gait information, we name this framework as GI-ReID. GI-ReID adopts a two-stream architecture that consists of a image ReID-Stream and an auxiliary gait recognition stream (Gait-Stream). The Gait-Stream, that is discarded in the inference for high computational efficiency, acts as a regulator to encourage the ReID-Stream to capture cloth-invariant biometric motion features during the training. To get temporal continuous motion cues from a single image, we design a Gait Sequence Prediction (GSP) module for Gait-Stream to enrich gait information. Finally, a high-level semantics consistency over two streams is enforced for effective knowledge regularization. Experiments on multiple image-based Cloth-Changing ReID benchmarks, e.g., LTCC, PRCC, Real28, and VC-Clothes, demonstrate that GI-ReID performs favorably against the state-of-the-arts. Codes are available at https://github.com/jinx-USTC/GI-ReID.
Spatiotemporal Spike-Pattern Selectivity in Single Mixed-Signal Neurons with Balanced Synapses
Jun 10, 2021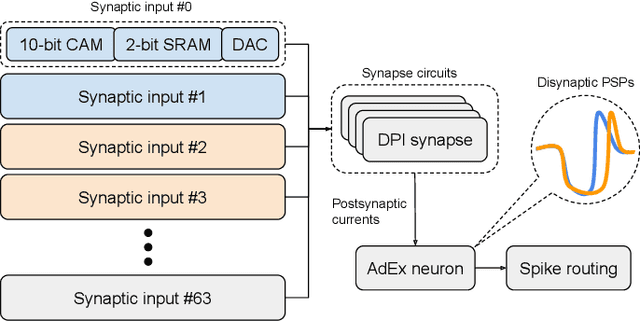
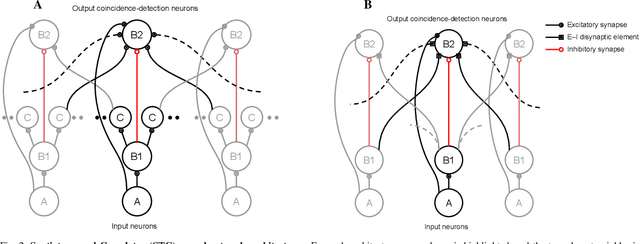
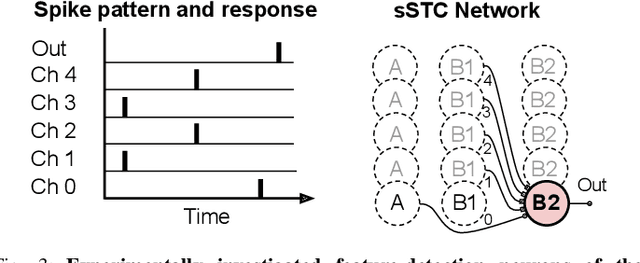
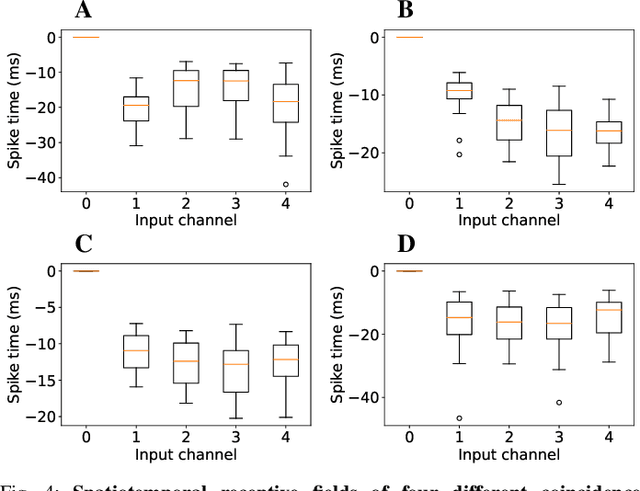
Realizing the potential of mixed-signal neuromorphic processors for ultra-low-power inference and learning requires efficient use of their inhomogeneous analog circuitry as well as sparse, time-based information encoding and processing. Here, we investigate spike-timing-based spatiotemporal receptive fields of output-neurons in the Spatiotemporal Correlator (STC) network, for which we used excitatory-inhibitory balanced disynaptic inputs instead of dedicated axonal or neuronal delays. We present hardware-in-the-loop experiments with a mixed-signal DYNAP-SE neuromorphic processor, in which five-dimensional receptive fields of hardware neurons were mapped by randomly sampling input spike-patterns from a uniform distribution. We find that, when the balanced disynaptic elements are randomly programmed, some of the neurons display distinct receptive fields. Furthermore, we demonstrate how a neuron was tuned to detect a particular spatiotemporal feature, to which it initially was non-selective, by activating a different subset of the inhomogeneous analog synaptic circuits. The energy dissipation of the balanced synaptic elements is one order of magnitude lower per lateral connection (0.65 nJ vs 9.3 nJ per spike) than former delay-based neuromorphic hardware implementations. Thus, we show how the inhomogeneous synaptic circuits could be utilized for resource-efficient implementation of STC network layers, in a way that enables synapse-address reprogramming as a discrete mechanism for feature tuning.
Exploring Instance Relations for Unsupervised Feature Embedding
May 07, 2021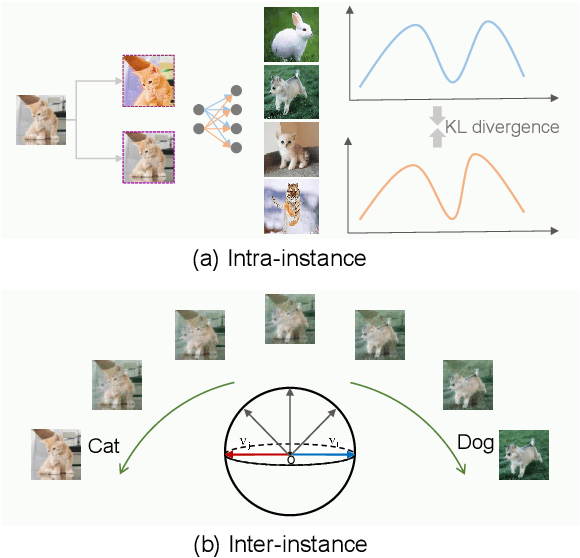
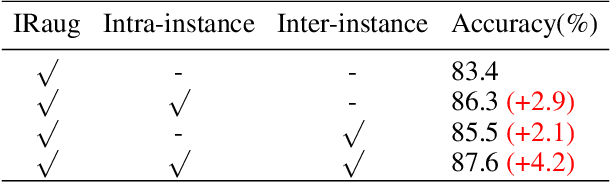
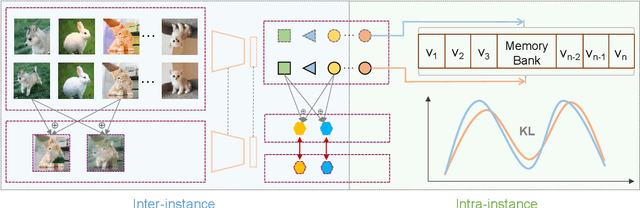
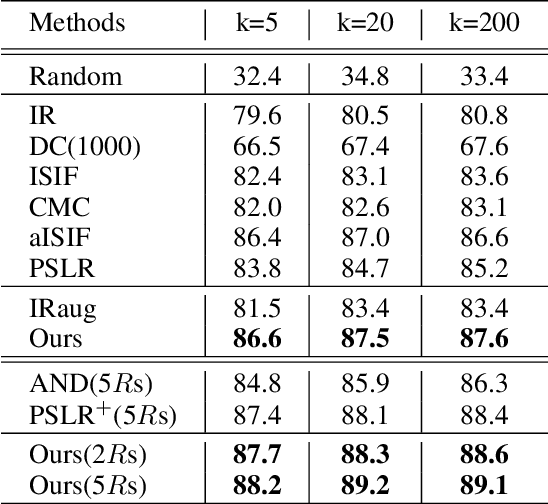
Despite the great progress achieved in unsupervised feature embedding, existing contrastive learning methods typically pursue view-invariant representations through attracting positive sample pairs and repelling negative sample pairs in the embedding space, while neglecting to systematically explore instance relations. In this paper, we explore instance relations including intra-instance multi-view relation and inter-instance interpolation relation for unsupervised feature embedding. Specifically, we embed intra-instance multi-view relation by aligning the distribution of the distance between an instance's different augmented samples and negative samples. We explore inter-instance interpolation relation by transferring the ratio of information for image sample interpolation from pixel space to feature embedding space. The proposed approach, referred to as EIR, is simple-yet-effective and can be easily inserted into existing view-invariant contrastive learning based methods. Experiments conducted on public benchmarks for image classification and retrieval report state-of-the-art or comparable performance.
Double Articulation Analyzer with Prosody for Unsupervised Word and Phoneme Discovery
Mar 15, 2021Infants acquire words and phonemes from unsegmented speech signals using segmentation cues, such as distributional, prosodic, and co-occurrence cues. Many pre-existing computational models that represent the process tend to focus on distributional or prosodic cues. This paper proposes a nonparametric Bayesian probabilistic generative model called the prosodic hierarchical Dirichlet process-hidden language model (Prosodic HDP-HLM). Prosodic HDP-HLM, an extension of HDP-HLM, considers both prosodic and distributional cues within a single integrative generative model. We conducted three experiments on different types of datasets, and demonstrate the validity of the proposed method. The results show that the Prosodic DAA successfully uses prosodic cues and outperforms a method that solely uses distributional cues. The main contributions of this study are as follows: 1) We develop a probabilistic generative model for time series data including prosody that potentially has a double articulation structure; 2) We propose the Prosodic DAA by deriving the inference procedure for Prosodic HDP-HLM and show that Prosodic DAA can discover words directly from continuous human speech signals using statistical information and prosodic information in an unsupervised manner; 3) We show that prosodic cues contribute to word segmentation more in naturally distributed case words, i.e., they follow Zipf's law.
Detection of Clouds in Multiple Wind Velocity Fields using Ground-based Infrared Sky Images
Jun 03, 2021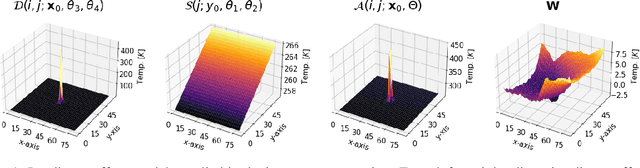
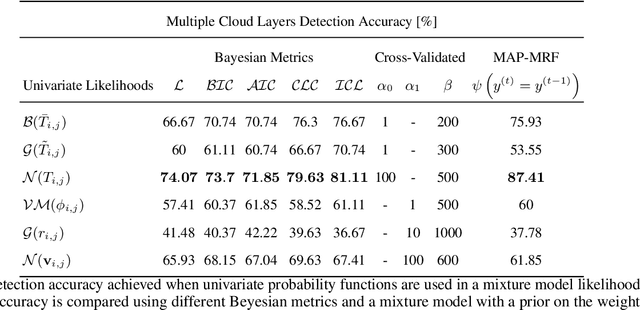
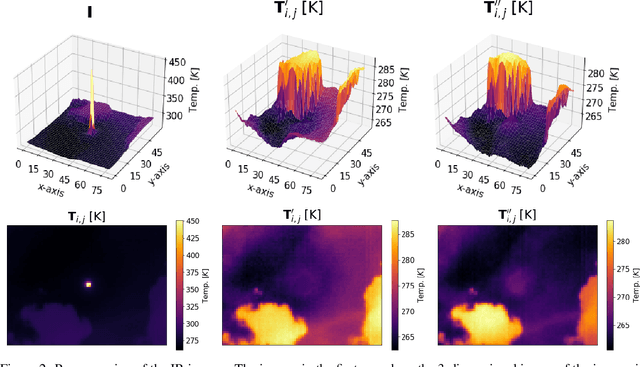
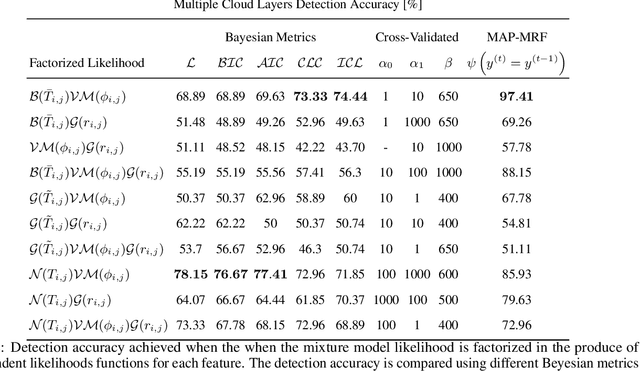
Horizontal atmospheric wind shear causes wind velocity fields to have different directions and speeds. In images of clouds acquired using ground-based sky imagers, clouds may be moving in different wind layers. To increase the performance of an intra-hour global solar irradiance forecasting algorithm, it is important to detect multiple layers of clouds. The information provided by a solar forecasting algorithm is necessary to optimize and schedule the solar generation resources and storage devices in a smart grid. This investigation studies the performance of unsupervised learning techniques when detecting the number of cloud layers in infrared sky images. The images are acquired using an innovative infrared sky imager mounted on a solar tracker. Different mixture models are used to infer the distribution of the cloud features. The optimal decision criterion to find the number of clusters in the mixture models is analyzed and compared between different Bayesian metrics and a sequential hidden Markov model. The motion vectors are computed using a weighted implementation of the Lucas-Kanade algorithm. The correlations between the cloud velocity vectors and temperatures are analyzed to find the method that leads to the most accurate results. We have found that the sequential hidden Markov model outperformed the detection accuracy of the Bayesian metrics.
SVMA: A GAN-based model for Monocular 3D Human Pose Estimation
Jun 10, 2021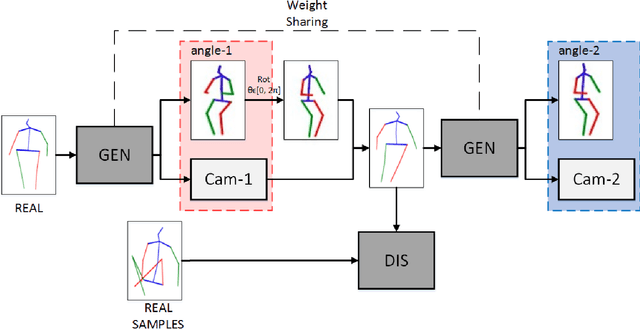
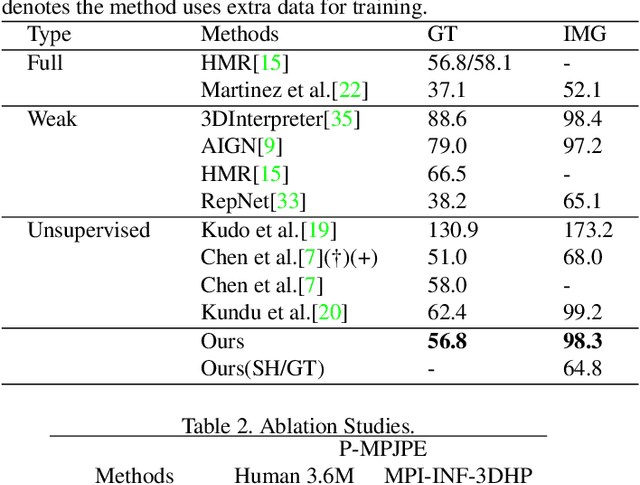
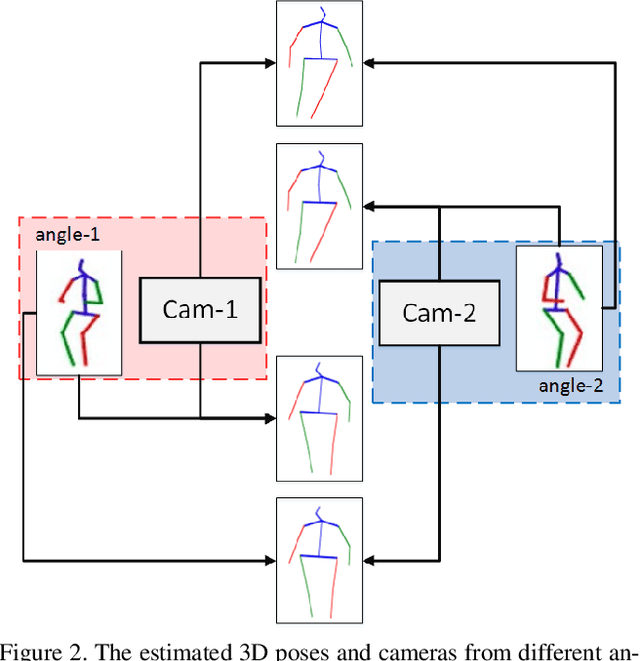
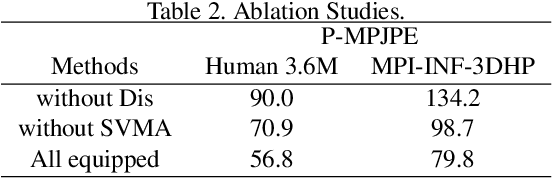
Recovering 3D human pose from 2D joints is a highly unconstrained problem, especially without any video or multi-view information. We present an unsupervised GAN-based model to recover 3D human pose from 2D joint locations extracted from a single image. Our model uses a GAN to learn the mapping of distribution from 2D poses to 3D poses, not the simple 2D-3D correspondence. Considering the reprojection constraint, our model can estimate the camera so that we can reproject the estimated 3D pose to the original 2D pose. Based on this reprojection method, we can rotate and reproject the generated pose to get our "new" 2D pose and then use a weight sharing generator to estimate the "new" 3D pose and a "new" camera. Through the above estimation process, we can define the single-view-multi-angle consistency loss during training to simulate multi-view consistency, which means the 3D poses and cameras estimated from two angles of a single view should be able to be mixed to generate rich 2D reprojections, and the 2D reprojections reprojected from the same 3D pose should be consistent. The experimental results on Human3.6M show that our method outperforms all the state-of-the-art methods, and results on MPI-INF-3DHP show that our method outperforms state-of-the-art by approximately 15.0%.