 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
M3D-VTON: A Monocular-to-3D Virtual Try-On Network
Aug 11, 2021
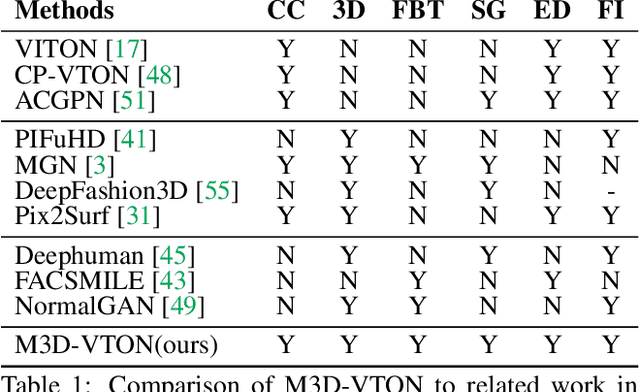
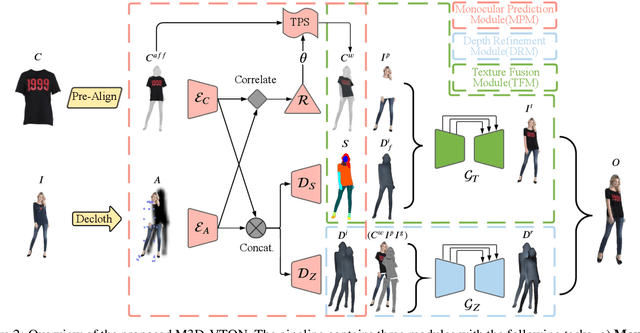
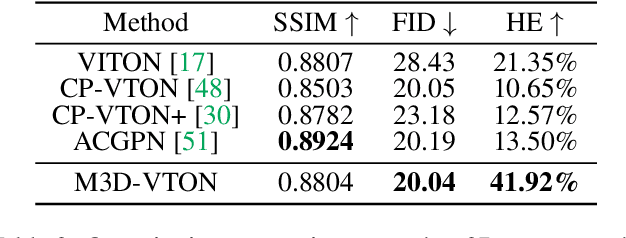
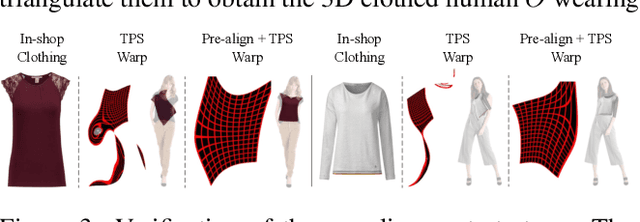
Virtual 3D try-on can provide an intuitive and realistic view for online shopping and has a huge potential commercial value. However, existing 3D virtual try-on methods mainly rely on annotated 3D human shapes and garment templates, which hinders their applications in practical scenarios. 2D virtual try-on approaches provide a faster alternative to manipulate clothed humans, but lack the rich and realistic 3D representation. In this paper, we propose a novel Monocular-to-3D Virtual Try-On Network (M3D-VTON) that builds on the merits of both 2D and 3D approaches. By integrating 2D information efficiently and learning a mapping that lifts the 2D representation to 3D, we make the first attempt to reconstruct a 3D try-on mesh only taking the target clothing and a person image as inputs. The proposed M3D-VTON includes three modules: 1) The Monocular Prediction Module (MPM) that estimates an initial full-body depth map and accomplishes 2D clothes-person alignment through a novel two-stage warping procedure; 2) The Depth Refinement Module (DRM) that refines the initial body depth to produce more detailed pleat and face characteristics; 3) The Texture Fusion Module (TFM) that fuses the warped clothing with the non-target body part to refine the results. We also construct a high-quality synthesized Monocular-to-3D virtual try-on dataset, in which each person image is associated with a front and a back depth map. Extensive experiments demonstrate that the proposed M3D-VTON can manipulate and reconstruct the 3D human body wearing the given clothing with compelling details and is more efficient than other 3D approaches.
Graph-Aware Evolutionary Algorithms for Influence Maximization
Apr 30, 2021
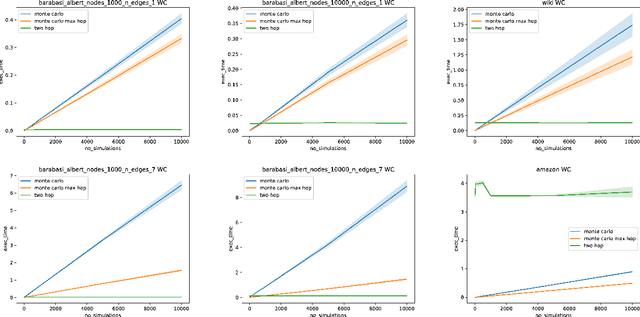
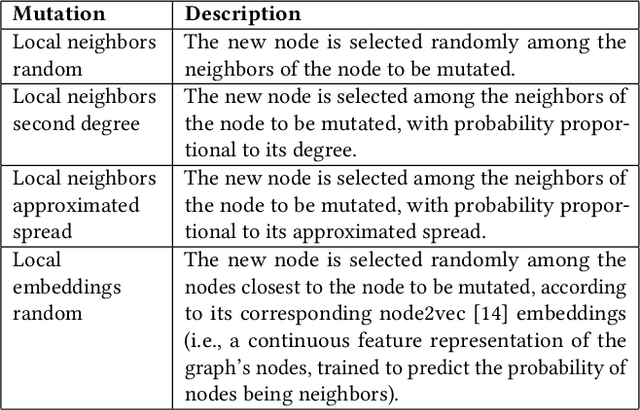
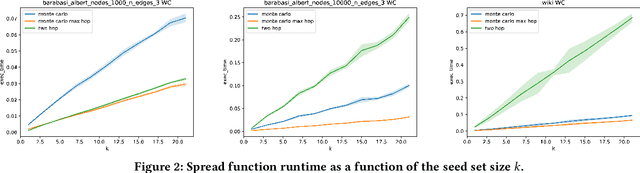
Social networks represent nowadays in many contexts the main source of information transmission and the way opinions and actions are influenced. For instance, generic advertisements are way less powerful than suggestions from our contacts. However, this process hugely depends on the influence of people who disseminate these suggestions. Therefore modern marketing often involves paying some targeted users, or influencers, for advertising products or ideas. Finding the set of nodes in a social network that lead to the highest information spread -- the so-called Influence Maximization (IM) problem -- is therefore a pressing question and as such it has recently attracted a great research interest. In particular, several approaches based on Evolutionary Algorithms (EAs) have been proposed, although they are known to scale poorly with the graph size. In this paper, we tackle this limitation in two ways. Firstly, we use approximate fitness functions to speed up the EA. Secondly, we include into the EA various graph-aware mechanisms, such as smart initialization, custom mutations and node filtering, to facilitate the EA convergence. Our experiments show that the proposed modifications allow to obtain a relevant runtime gain and also improve, in some cases, the spread results.
Improving Conversational Recommendation System by Pretraining on Billions Scale of Knowledge Graph
Apr 30, 2021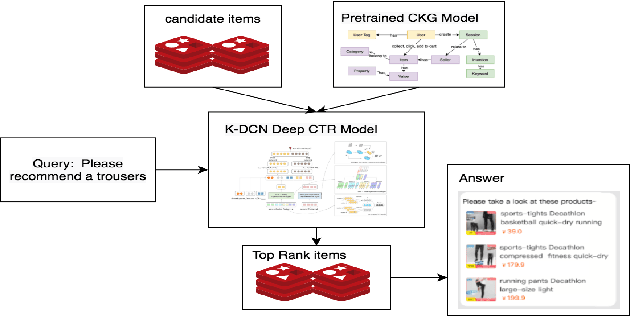
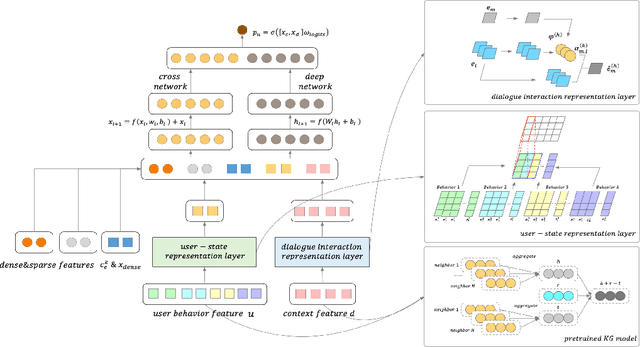
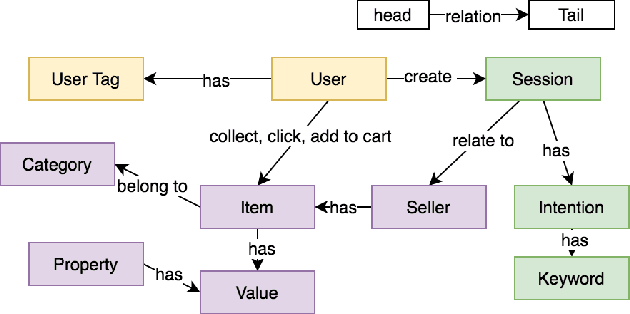
Conversational Recommender Systems (CRSs) in E-commerce platforms aim to recommend items to users via multiple conversational interactions. Click-through rate (CTR) prediction models are commonly used for ranking candidate items. However, most CRSs are suffer from the problem of data scarcity and sparseness. To address this issue, we propose a novel knowledge-enhanced deep cross network (K-DCN), a two-step (pretrain and fine-tune) CTR prediction model to recommend items. We first construct a billion-scale conversation knowledge graph (CKG) from information about users, items and conversations, and then pretrain CKG by introducing knowledge graph embedding method and graph convolution network to encode semantic and structural information respectively.To make the CTR prediction model sensible of current state of users and the relationship between dialogues and items, we introduce user-state and dialogue-interaction representations based on pre-trained CKG and propose K-DCN.In K-DCN, we fuse the user-state representation, dialogue-interaction representation and other normal feature representations via deep cross network, which will give the rank of candidate items to be recommended.We experimentally prove that our proposal significantly outperforms baselines and show it's real application in Alime.
A^2-FPN: Attention Aggregation based Feature Pyramid Network for Instance Segmentation
May 07, 2021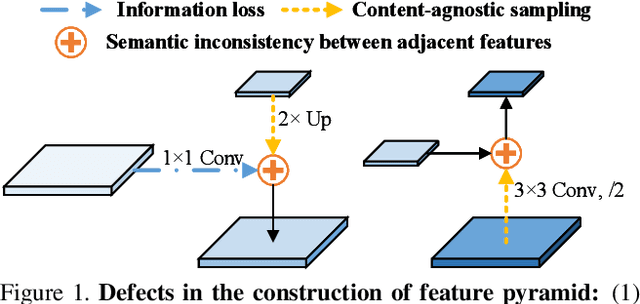
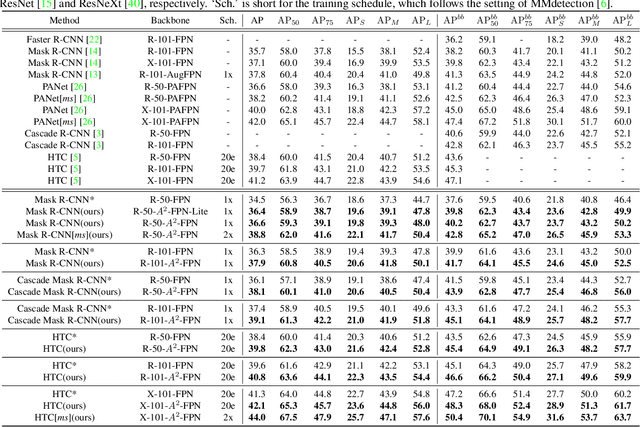
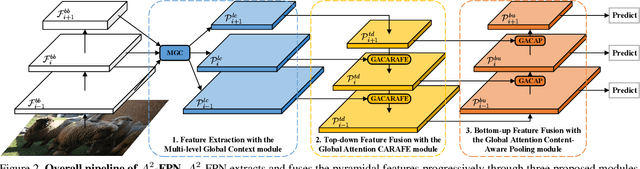
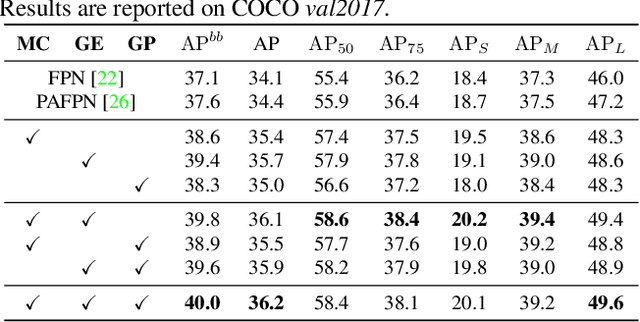
Learning pyramidal feature representations is crucial for recognizing object instances at different scales. Feature Pyramid Network (FPN) is the classic architecture to build a feature pyramid with high-level semantics throughout. However, intrinsic defects in feature extraction and fusion inhibit FPN from further aggregating more discriminative features. In this work, we propose Attention Aggregation based Feature Pyramid Network (A^2-FPN), to improve multi-scale feature learning through attention-guided feature aggregation. In feature extraction, it extracts discriminative features by collecting-distributing multi-level global context features, and mitigates the semantic information loss due to drastically reduced channels. In feature fusion, it aggregates complementary information from adjacent features to generate location-wise reassembly kernels for content-aware sampling, and employs channel-wise reweighting to enhance the semantic consistency before element-wise addition. A^2-FPN shows consistent gains on different instance segmentation frameworks. By replacing FPN with A^2-FPN in Mask R-CNN, our model boosts the performance by 2.1% and 1.6% mask AP when using ResNet-50 and ResNet-101 as backbone, respectively. Moreover, A^2-FPN achieves an improvement of 2.0% and 1.4% mask AP when integrated into the strong baselines such as Cascade Mask R-CNN and Hybrid Task Cascade.
Deep Video Matting via Spatio-Temporal Alignment and Aggregation
Apr 22, 2021
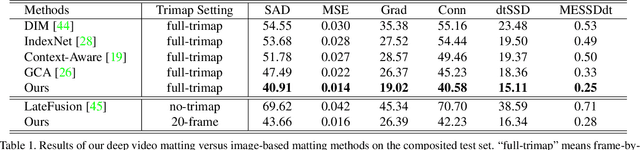
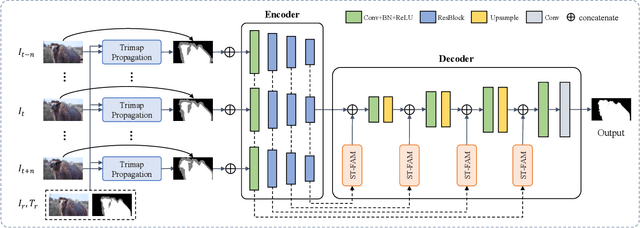
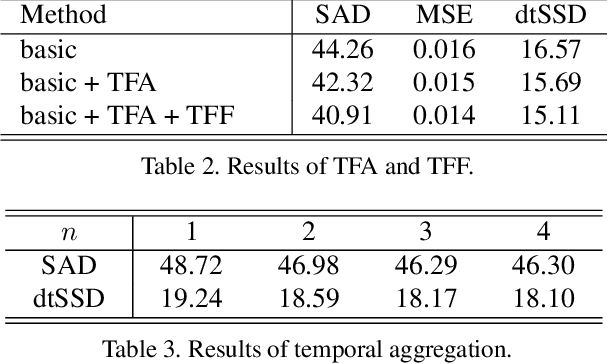
Despite the significant progress made by deep learning in natural image matting, there has been so far no representative work on deep learning for video matting due to the inherent technical challenges in reasoning temporal domain and lack of large-scale video matting datasets. In this paper, we propose a deep learning-based video matting framework which employs a novel and effective spatio-temporal feature aggregation module (ST-FAM). As optical flow estimation can be very unreliable within matting regions, ST-FAM is designed to effectively align and aggregate information across different spatial scales and temporal frames within the network decoder. To eliminate frame-by-frame trimap annotations, a lightweight interactive trimap propagation network is also introduced. The other contribution consists of a large-scale video matting dataset with groundtruth alpha mattes for quantitative evaluation and real-world high-resolution videos with trimaps for qualitative evaluation. Quantitative and qualitative experimental results show that our framework significantly outperforms conventional video matting and deep image matting methods applied to video in presence of multi-frame temporal information.
Android Security using NLP Techniques: A Review
Jul 07, 2021
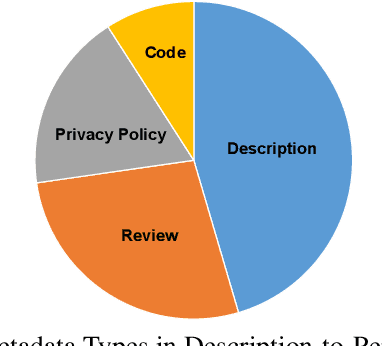
Android is among the most targeted platform by attackers. While attackers are improving their techniques, traditional solutions based on static and dynamic analysis have been also evolving. In addition to the application code, Android applications have some metadata that could be useful for security analysis of applications. Unlike traditional application distribution mechanisms, Android applications are distributed centrally in mobile markets. Therefore, beside application packages, such markets contain app information provided by app developers and app users. The availability of such useful textual data together with the advancement in Natural Language Processing (NLP) that is used to process and understand textual data has encouraged researchers to investigate the use of NLP techniques in Android security. Especially, security solutions based on NLP have accelerated in the last 5 years and proven to be useful. This study reviews these proposals and aim to explore possible research directions for future studies by presenting state-of-the-art in this domain. We mainly focus on NLP-based solutions under four categories: description-to-behaviour fidelity, description generation, privacy and malware detection.
Maintaining a Reliable World Model using Action-aware Perceptual Anchoring
Jul 07, 2021
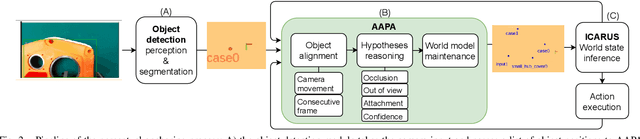
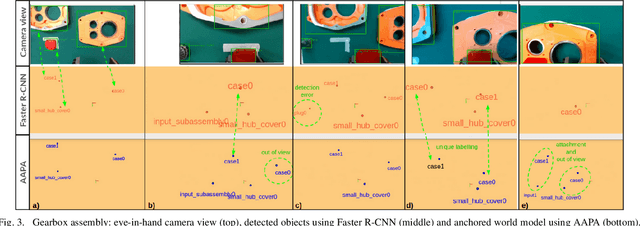
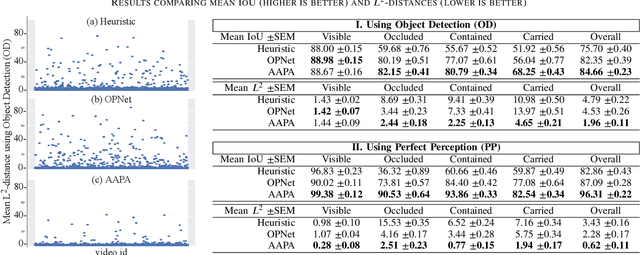
Reliable perception is essential for robots that interact with the world. But sensors alone are often insufficient to provide this capability, and they are prone to errors due to various conditions in the environment. Furthermore, there is a need for robots to maintain a model of its surroundings even when objects go out of view and are no longer visible. This requires anchoring perceptual information onto symbols that represent the objects in the environment. In this paper, we present a model for action-aware perceptual anchoring that enables robots to track objects in a persistent manner. Our rule-based approach considers inductive biases to perform high-level reasoning over the results from low-level object detection, and it improves the robot's perceptual capability for complex tasks. We evaluate our model against existing baseline models for object permanence and show that it outperforms these on a snitch localisation task using a dataset of 1,371 videos. We also integrate our action-aware perceptual anchoring in the context of a cognitive architecture and demonstrate its benefits in a realistic gearbox assembly task on a Universal Robot.
* 7 pages, 3 figures
Comparison of Outlier Detection Techniques for Structured Data
Jun 16, 2021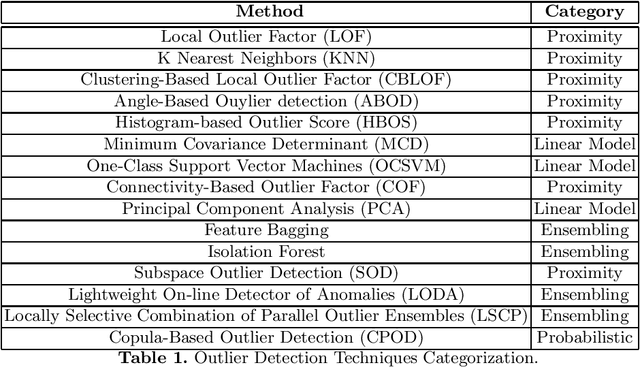
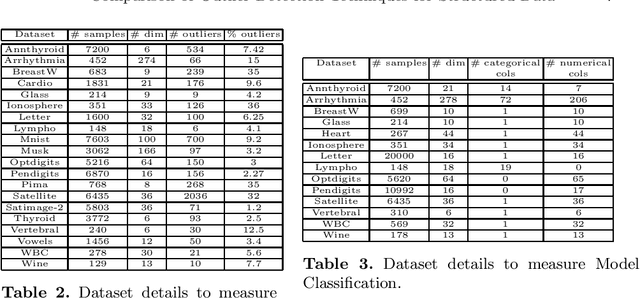
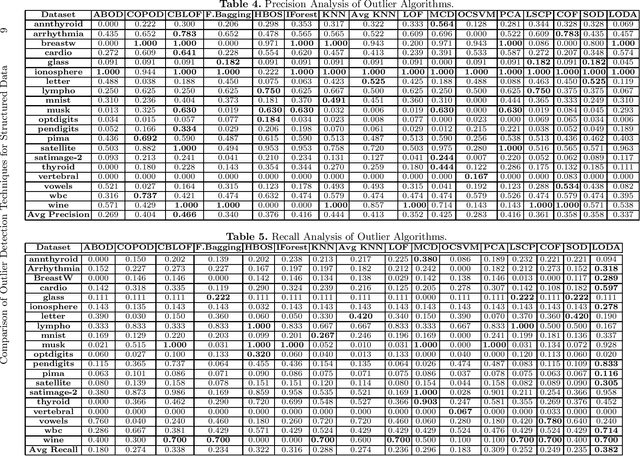

An outlier is an observation or a data point that is far from rest of the data points in a given dataset or we can be said that an outlier is away from the center of mass of observations. Presence of outliers can skew statistical measures and data distributions which can lead to misleading representation of the underlying data and relationships. It is seen that the removal of outliers from the training dataset before modeling can give better predictions. With the advancement of machine learning, the outlier detection models are also advancing at a good pace. The goal of this work is to highlight and compare some of the existing outlier detection techniques for the data scientists to use that information for outlier algorithm selection while building a machine learning model.
Interactive query expansion for professional search applications
Jun 25, 2021
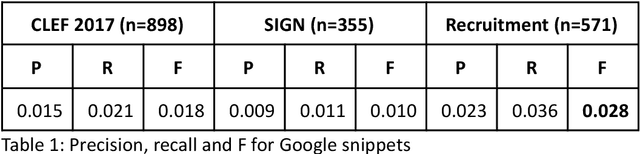
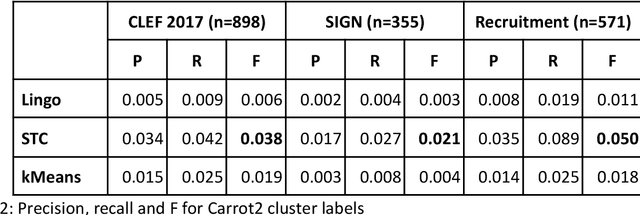
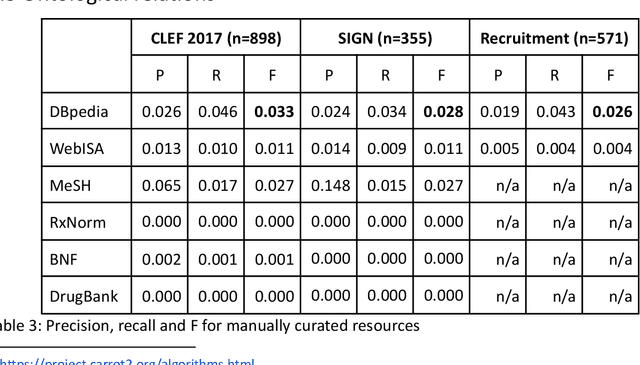
Knowledge workers (such as healthcare information professionals, patent agents and recruitment professionals) undertake work tasks where search forms a core part of their duties. In these instances, the search task is often complex and time-consuming and requires specialist expert knowledge to formulate accurate search strategies. Interactive features such as query expansion can play a key role in supporting these tasks. However, generating query suggestions within a professional search context requires that consideration be given to the specialist, structured nature of the search strategies they employ. In this paper, we investigate a variety of query expansion methods applied to a collection of Boolean search strategies used in a variety of real-world professional search tasks. The results demonstrate the utility of context-free distributional language models and the value of using linguistic cues such as ngram order to optimise the balance between precision and recall.
A data-driven personalized smart lighting recommender system
Apr 05, 2021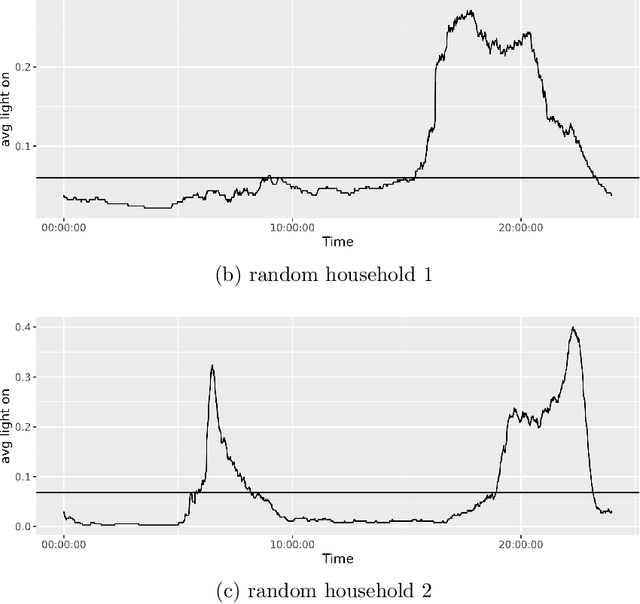
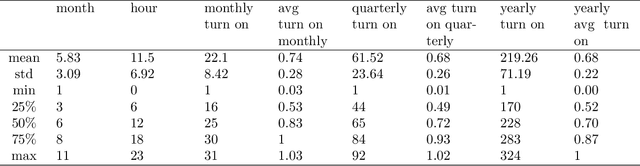
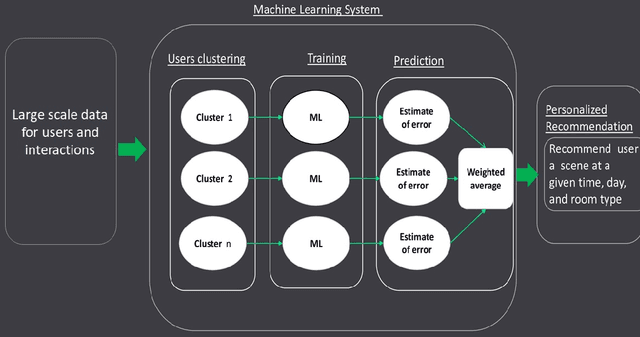
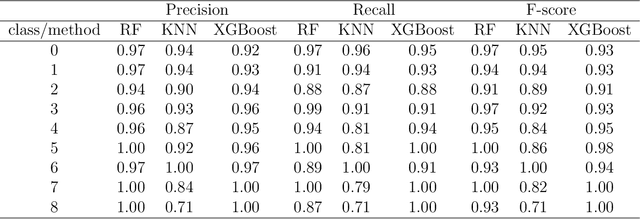
Recommender systems attempts to identify and recommend the most preferable item (product-service) to an individual user. These systems predict user interest in items based on related items, users, and the interactions between items and users. We aim to build an auto-routine and color scheme recommender system that leverages a wealth of historical data and machine learning methods. We introduce an unsupervised method to recommend a routine for lighting. Moreover, by analyzing users' daily logs, geographical location, temporal and usage information we understand user preference and predict their preferred color for lights. To do so, we cluster users based on their geographical information and usage distribution. We then build and train a predictive model within each cluster and aggregate the results. Results indicate that models based on similar users increases the prediction accuracy, with and without prior knowledge about user preferences.