 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA data-driven personalized smart lighting recommender system
Apr 05, 2021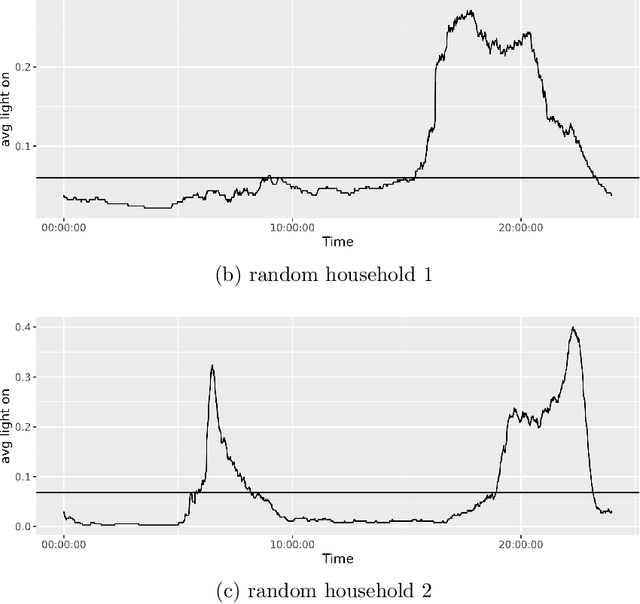
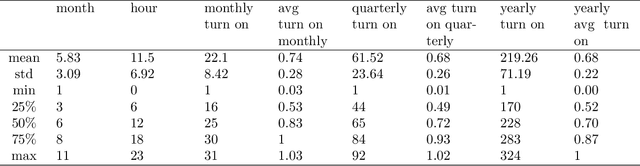
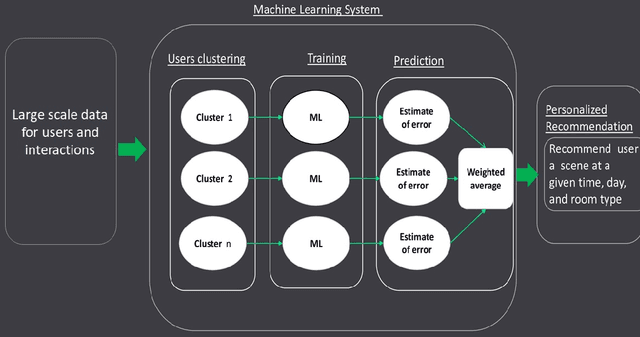
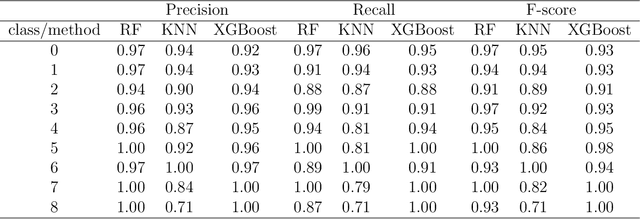
Recommender systems attempts to identify and recommend the most preferable item (product-service) to an individual user. These systems predict user interest in items based on related items, users, and the interactions between items and users. We aim to build an auto-routine and color scheme recommender system that leverages a wealth of historical data and machine learning methods. We introduce an unsupervised method to recommend a routine for lighting. Moreover, by analyzing users' daily logs, geographical location, temporal and usage information we understand user preference and predict their preferred color for lights. To do so, we cluster users based on their geographical information and usage distribution. We then build and train a predictive model within each cluster and aggregate the results. Results indicate that models based on similar users increases the prediction accuracy, with and without prior knowledge about user preferences.
Big Data application in congestion detection and classification using Apache spark
Jan 16, 2021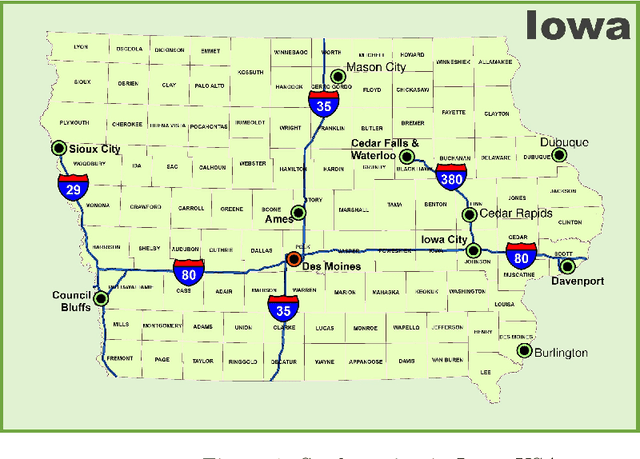

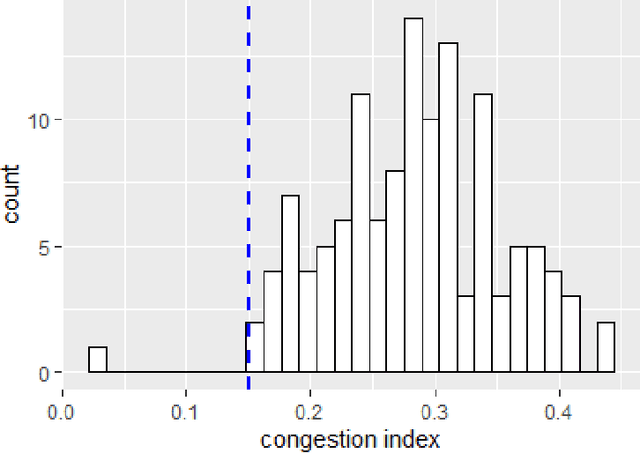
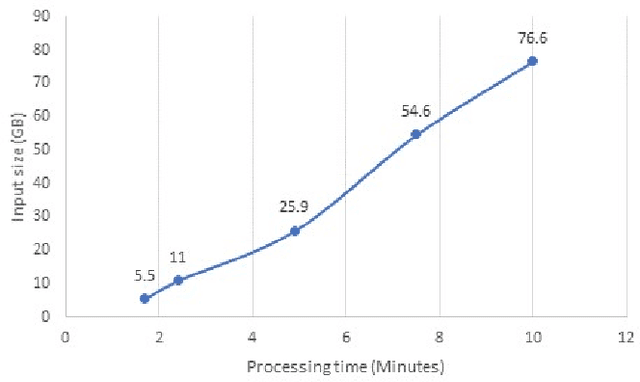
With the era of big data, an explosive amount of information is now available. This enormous increase of Big Data in both academia and industry requires large-scale data processing systems. A large body of research is behind optimizing Spark's performance to make it state of the art, a fast and general data processing system. Many science and engineering fields have advanced with Big Data analytics, such as Biology, finance, and transportation. Intelligent transportation systems (ITS) gain popularity and direct benefit from the richness of information. The objective is to improve the safety and management of transportation networks by reducing congestion and incidents. The first step toward the goal is better understanding, modeling, and detecting congestion across a network efficiently and effectively. In this study, we introduce an efficient congestion detection model. The underlying network consists of 3017 segments in I-35, I-80, I-29, and I-380 freeways with an overall length of 1570 miles and averaged (0.4-0.6) miles per segment. The result of congestion detection shows the proposed method is 90% accurate while has reduced computation time by 99.88%.