 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Building a Food Knowledge Graph for Internet of Food
Jul 13, 2021
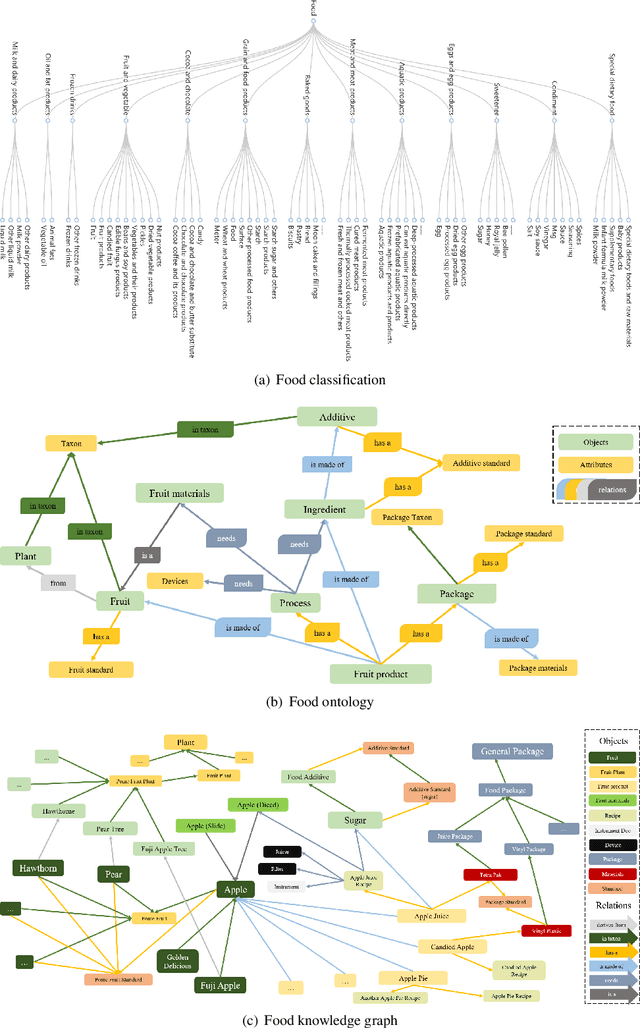
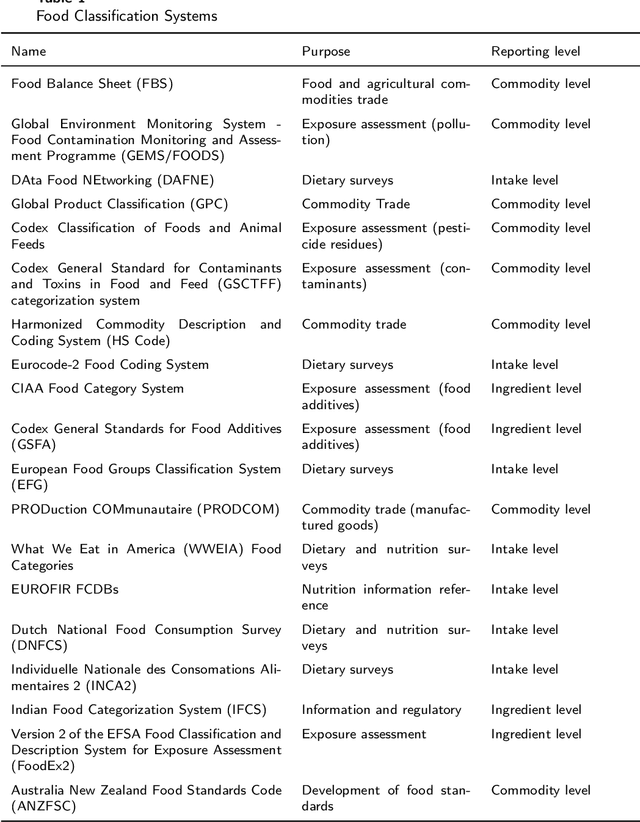
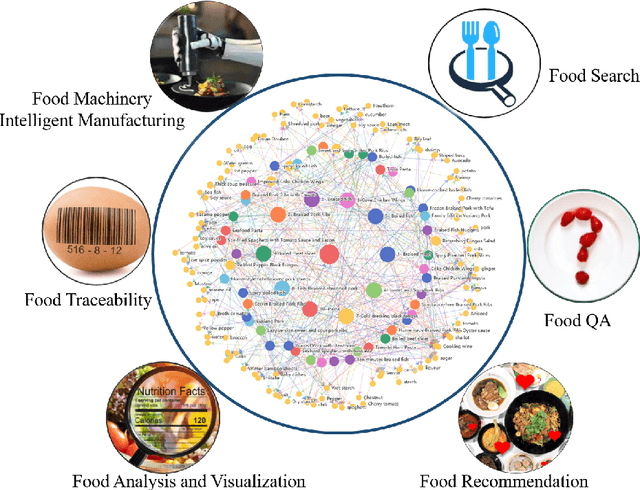
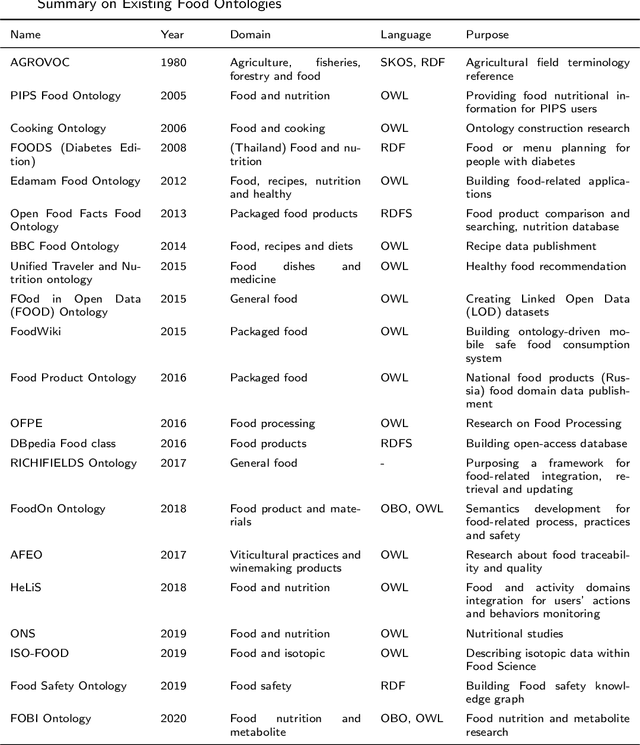
Background: The deployment of various networks (e.g., Internet of Things (IoT) and mobile networks) and databases (e.g., nutrition tables and food compositional databases) in the food system generates massive information silos due to the well-known data harmonization problem. The food knowledge graph provides a unified and standardized conceptual terminology and their relationships in a structured form and thus can transform these information silos across the whole food system to a more reusable globally digitally connected Internet of Food, enabling every stage of the food system from farm-to-fork. Scope and approach: We review the evolution of food knowledge organization, from food classification, food ontology to food knowledge graphs. We then discuss the progress in food knowledge graphs from several representative applications. We finally discuss the main challenges and future directions. Key findings and conclusions: Our comprehensive summary of current research on food knowledge graphs shows that food knowledge graphs play an important role in food-oriented applications, including food search and Question Answering (QA), personalized dietary recommendation, food analysis and visualization, food traceability, and food machinery intelligent manufacturing. Future directions for food knowledge graphs cover several fields such as multimodal food knowledge graphs and food intelligence.
Computing an Optimal Pitching Strategy in a Baseball At-Bat
Oct 08, 2021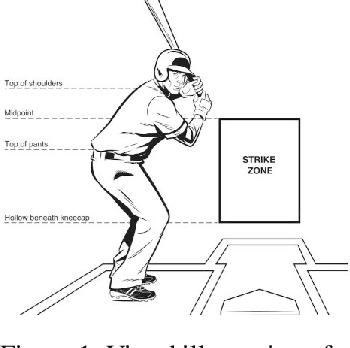
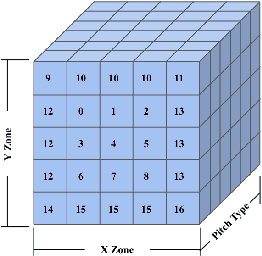
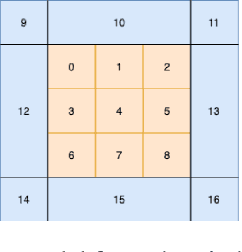
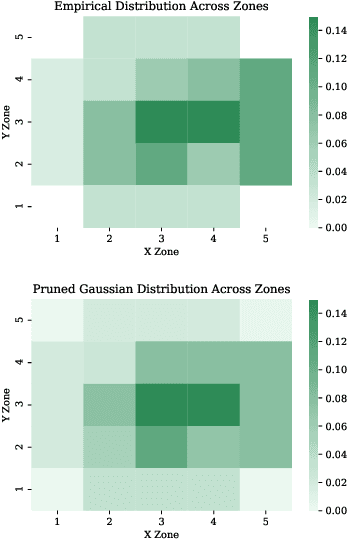
The field of quantitative analytics has transformed the world of sports over the last decade. To date, these analytic approaches are statistical at their core, characterizing what is and what was, while using this information to drive decisions about what to do in the future. However, as we often view team sports, such as soccer, hockey, and baseball, as pairwise win-lose encounters, it seems natural to model these as zero-sum games. We propose such a model for one important class of sports encounters: a baseball at-bat, which is a matchup between a pitcher and a batter. Specifically, we propose a novel model of this encounter as a zero-sum stochastic game, in which the goal of the batter is to get on base, an outcome the pitcher aims to prevent. The value of this game is the on-base percentage (i.e., the probability that the batter gets on base). In principle, this stochastic game can be solved using classical approaches. The main technical challenges lie in predicting the distribution of pitch locations as a function of pitcher intention, predicting the distribution of outcomes if the batter decides to swing at a pitch, and characterizing the level of patience of a particular batter. We address these challenges by proposing novel pitcher and batter representations as well as a novel deep neural network architecture for outcome prediction. Our experiments using Kaggle data from the 2015 to 2018 Major League Baseball seasons demonstrate the efficacy of the proposed approach.
Modeling Dynamic Attributes for Next Basket Recommendation
Sep 23, 2021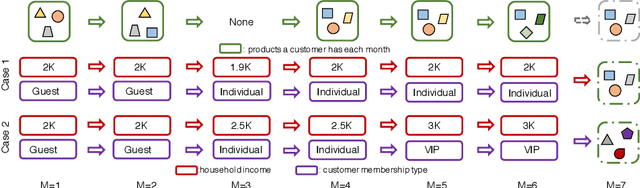

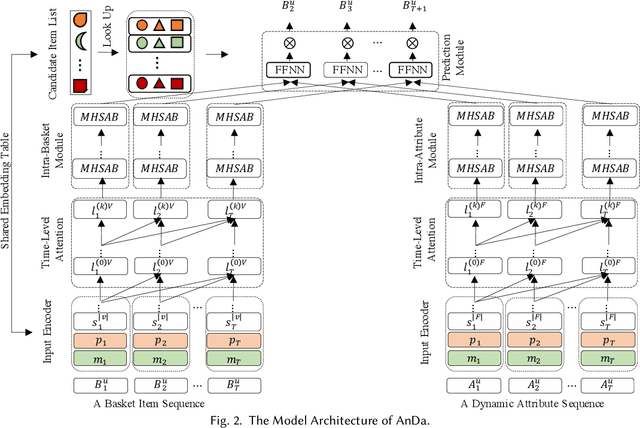

Traditional approaches to next item and next basket recommendation typically extract users' interests based on their past interactions and associated static contextual information (e.g. a user id or item category). However, extracted interests can be inaccurate and become obsolete. Dynamic attributes, such as user income changes, item price changes (etc.), change over time. Such dynamics can intrinsically reflect the evolution of users' interests. We argue that modeling such dynamic attributes can boost recommendation performance. However, properly integrating them into user interest models is challenging since attribute dynamics can be diverse such as time-interval aware, periodic patterns (etc.), and they represent users' behaviors from different perspectives, which can happen asynchronously with interactions. Besides dynamic attributes, items in each basket contain complex interdependencies which might be beneficial but nontrivial to effectively capture. To address these challenges, we propose a novel Attentive network to model Dynamic attributes (named AnDa). AnDa separately encodes dynamic attributes and basket item sequences. We design a periodic aware encoder to allow the model to capture various temporal patterns from dynamic attributes. To effectively learn useful item relationships, intra-basket attention module is proposed. Experimental results on three real-world datasets demonstrate that our method consistently outperforms the state-of-the-art.
Smoothing Dialogue States for Open Conversational Machine Reading
Aug 28, 2021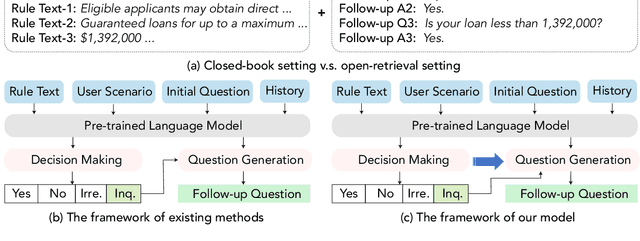
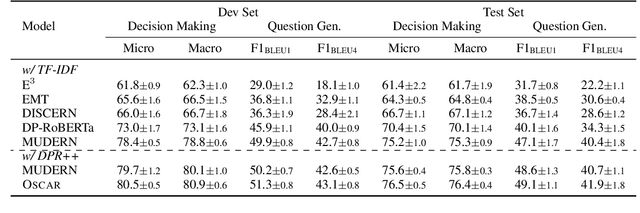
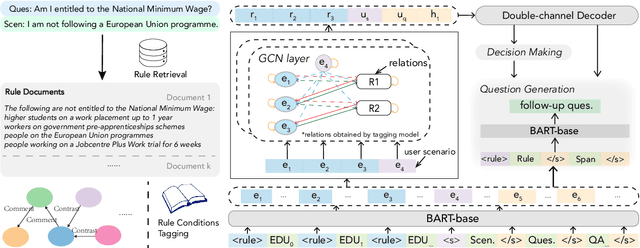
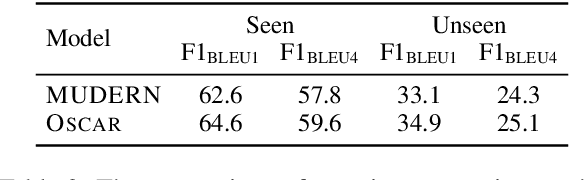
Conversational machine reading (CMR) requires machines to communicate with humans through multi-turn interactions between two salient dialogue states of decision making and question generation processes. In open CMR settings, as the more realistic scenario, the retrieved background knowledge would be noisy, which results in severe challenges in the information transmission. Existing studies commonly train independent or pipeline systems for the two subtasks. However, those methods are trivial by using hard-label decisions to activate question generation, which eventually hinders the model performance. In this work, we propose an effective gating strategy by smoothing the two dialogue states in only one decoder and bridge decision making and question generation to provide a richer dialogue state reference. Experiments on the OR-ShARC dataset show the effectiveness of our method, which achieves new state-of-the-art results.
Model-Constrained Deep Learning Approaches for Inverse Problems
May 25, 2021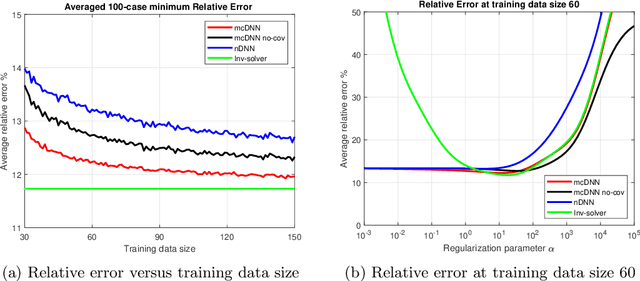
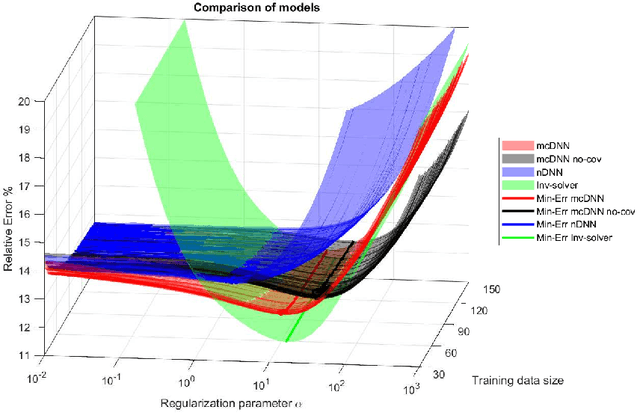
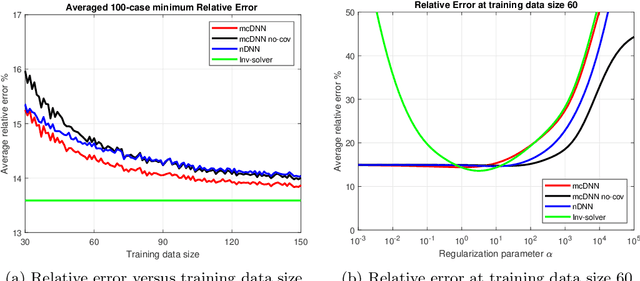
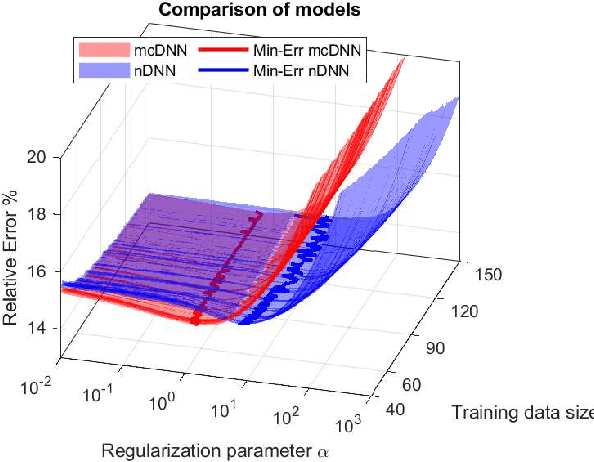
Deep Learning (DL), in particular deep neural networks (DNN), by design is purely data-driven and in general does not require physics. This is the strength of DL but also one of its key limitations when applied to science and engineering problems in which underlying physical properties (such as stability, conservation, and positivity) and desired accuracy need to be achieved. DL methods in their original forms are not capable of respecting the underlying mathematical models or achieving desired accuracy even in big-data regimes. On the other hand, many data-driven science and engineering problems, such as inverse problems, typically have limited experimental or observational data, and DL would overfit the data in this case. Leveraging information encoded in the underlying mathematical models, we argue, not only compensates missing information in low data regimes but also provides opportunities to equip DL methods with the underlying physics and hence obtaining higher accuracy. This short communication introduces several model-constrained DL approaches (including both feed-forward DNN and autoencoders) that are capable of learning not only information hidden in the training data but also in the underlying mathematical models to solve inverse problems. We present and provide intuitions for our formulations for general nonlinear problems. For linear inverse problems and linear networks, the first order optimality conditions show that our model-constrained DL approaches can learn information encoded in the underlying mathematical models, and thus can produce consistent or equivalent inverse solutions, while naive purely data-based counterparts cannot.
Federated Learning for Big Data: A Survey on Opportunities, Applications, and Future Directions
Oct 08, 2021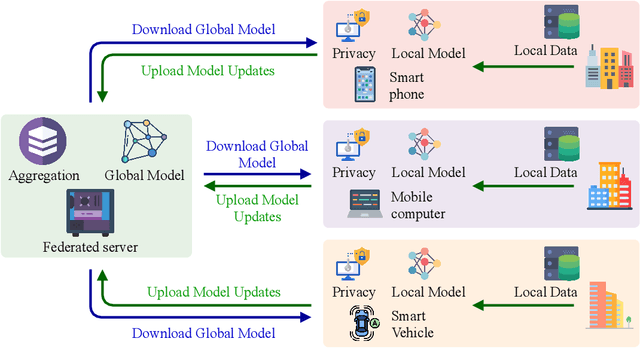
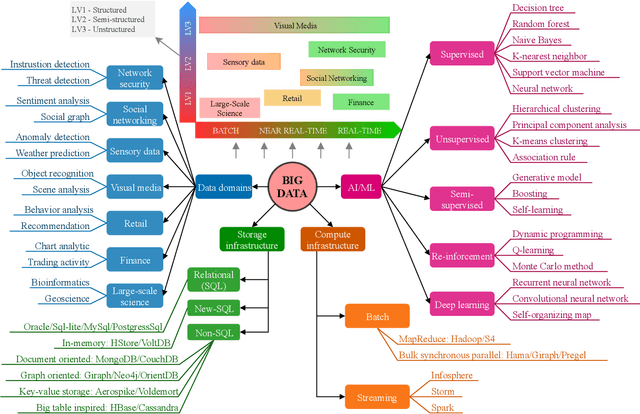
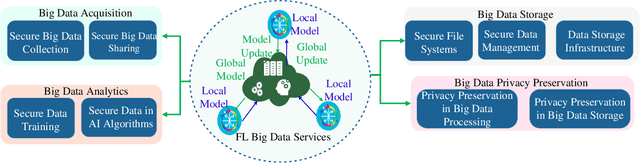
Big data has remarkably evolved over the last few years to realize an enormous volume of data generated from newly emerging services and applications and a massive number of Internet-of-Things (IoT) devices. The potential of big data can be realized via analytic and learning techniques, in which the data from various sources is transferred to a central cloud for central storage, processing, and training. However, this conventional approach faces critical issues in terms of data privacy as the data may include sensitive data such as personal information, governments, banking accounts. To overcome this challenge, federated learning (FL) appeared to be a promising learning technique. However, a gap exists in the literature that a comprehensive survey on FL for big data services and applications is yet to be conducted. In this article, we present a survey on the use of FL for big data services and applications, aiming to provide general readers with an overview of FL, big data, and the motivations behind the use of FL for big data. In particular, we extensively review the use of FL for key big data services, including big data acquisition, big data storage, big data analytics, and big data privacy preservation. Subsequently, we review the potential of FL for big data applications, such as smart city, smart healthcare, smart transportation, smart grid, and social media. Further, we summarize a number of important projects on FL-big data and discuss key challenges of this interesting topic along with several promising solutions and directions.
A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]
Jul 19, 2021![Figure 1 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for A Queueing-Theoretic Framework for Vehicle Dispatching in Dynamic Car-Hailing [technical report]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Ffc232beef2f64fd18a8e781332d3e64520fe1361%2F10-Table2-1.png&w=640&q=75)
With the rapid development of smart mobile devices, the car-hailing platforms (e.g., Uber or Lyft) have attracted much attention from both the academia and the industry. In this paper, we consider an important dynamic car-hailing problem, namely \textit{maximum revenue vehicle dispatching} (MRVD), in which rider requests dynamically arrive and drivers need to serve as many riders as possible such that the entire revenue of the platform is maximized. We prove that the MRVD problem is NP-hard and intractable. In addition, the dynamic car-hailing platforms have no information of the future riders, which makes the problem even harder. To handle the MRVD problem, we propose a queueing-based vehicle dispatching framework, which first uses existing machine learning algorithms to predict the future vehicle demand of each region, then estimates the idle time periods of drivers through a queueing model for each region. With the information of the predicted vehicle demands and estimated idle time periods of drivers, we propose two batch-based vehicle dispatching algorithms to efficiently assign suitable drivers to riders such that the expected overall revenue of the platform is maximized during each batch processing. Through extensive experiments, we demonstrate the efficiency and effectiveness of our proposed approaches over both real and synthetic datasets.
Learning to Discriminate Noises for Incorporating External Information in Neural Machine Translation
Oct 24, 2018
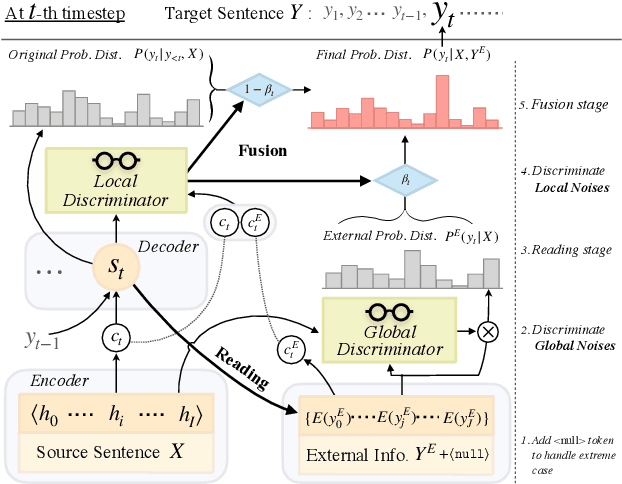
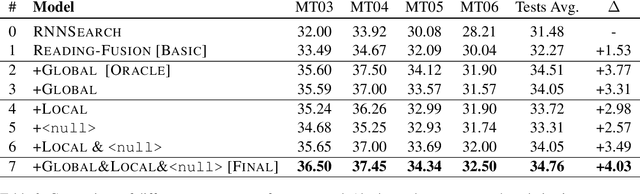
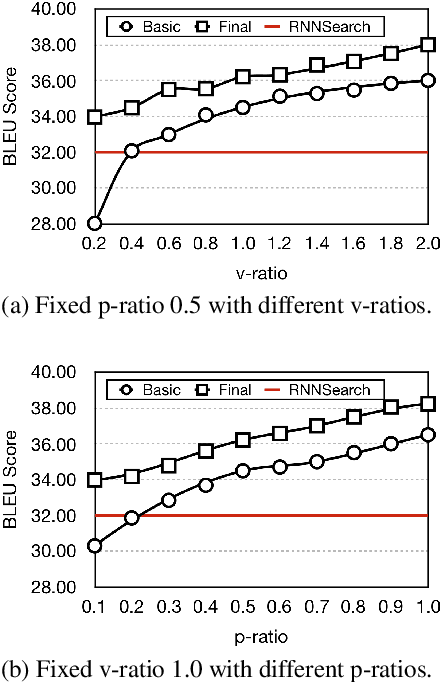
Previous studies show that incorporating external information could improve the translation quality of Neural Machine Translation (NMT) systems. However, these methods will inevitably suffer from the noises in the external information, which may severely reduce the benefit. We argue that there exist two kinds of noise in this external information, i.e. global noise and local noise, which affect the translation of the whole sentence and for some specific words, respectively. To tackle the problem, this study pays special attention to the discrimination of noises during the incorporation. We propose a general framework with two separate word discriminators for the global and local noises, respectively, so that the external information could be better leveraged. Empirical evaluation shows that being trained by the dataset sampled from the original parallel corpus without any extra labeled data or annotation, our model could make better use of external information in different real-world scenarios, language pairs, and neural architectures, leading to significant improvements over the original translation.
A Good Representation Detects Noisy Labels
Oct 12, 2021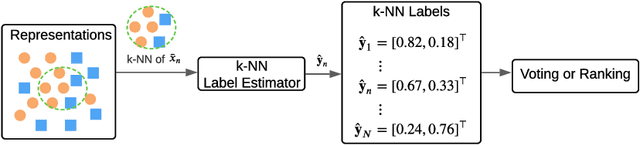
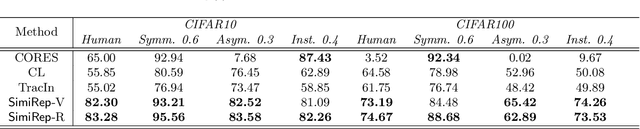
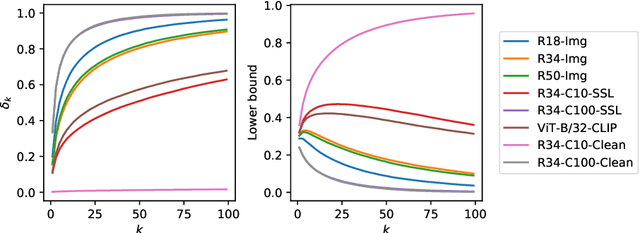

Label noise is pervasive in real-world datasets, which encodes wrong correlation patterns and impairs the generalization of deep neural networks (DNNs). It is critical to find efficient ways to detect the corrupted patterns. Current methods primarily focus on designing robust training techniques to prevent DNNs from memorizing corrupted patterns. This approach has two outstanding caveats: 1) applying this approach to each individual dataset would often require customized training processes; 2) as long as the model is trained with noisy supervisions, overfitting to corrupted patterns is often hard to avoid, leading to performance drop in detection. In this paper, given good representations, we propose a universally applicable and training-free solution to detect noisy labels. Intuitively, good representations help define ``neighbors'' of each training instance, and closer instances are more likely to share the same clean label. Based on the neighborhood information, we propose two methods: the first one uses ``local voting" via checking the noisy label consensuses of nearby representations. The second one is a ranking-based approach that scores each instance and filters out a guaranteed number of instances that are likely to be corrupted, again using only representations. Given good (but possibly imperfect) representations that are commonly available in practice, we theoretically analyze how they affect the local voting and provide guidelines for tuning neighborhood size. We also prove the worst-case error bound for the ranking-based method. Experiments with both synthetic and real-world label noise demonstrate our training-free solutions are consistently and significantly improving over most of the training-based baselines. Code is available at github.com/UCSC-REAL/SimiRep.
COSMic: A Coherence-Aware Generation Metric for Image Descriptions
Sep 11, 2021
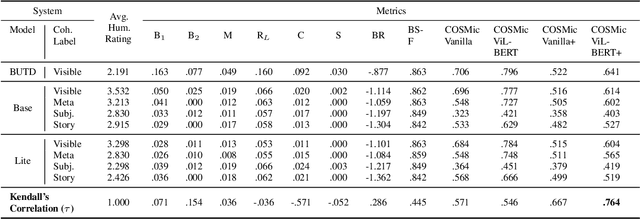

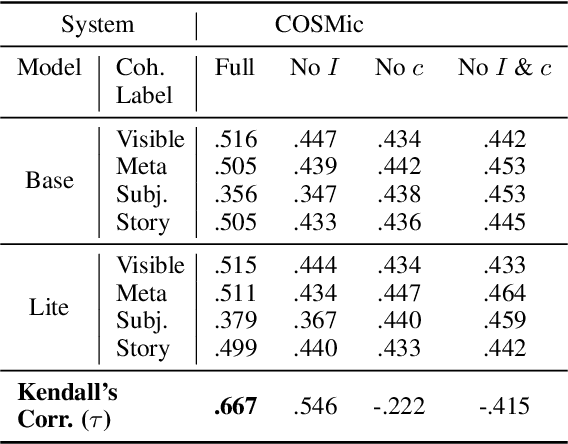
Developers of text generation models rely on automated evaluation metrics as a stand-in for slow and expensive manual evaluations. However, image captioning metrics have struggled to give accurate learned estimates of the semantic and pragmatic success of output text. We address this weakness by introducing the first discourse-aware learned generation metric for evaluating image descriptions. Our approach is inspired by computational theories of discourse for capturing information goals using coherence. We present a dataset of image$\unicode{x2013}$description pairs annotated with coherence relations. We then train a coherence-aware metric on a subset of the Conceptual Captions dataset and measure its effectiveness$\unicode{x2014}$its ability to predict human ratings of output captions$\unicode{x2014}$on a test set composed of out-of-domain images. We demonstrate a higher Kendall Correlation Coefficient for our proposed metric with the human judgments for the results of a number of state-of-the-art coherence-aware caption generation models when compared to several other metrics including recently proposed learned metrics such as BLEURT and BERTScore.