 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying & Interactively Refining Ambiguous User Goals for Data Visualization Code Generation
Oct 10, 2025Establishing shared goals is a fundamental step in human-AI communication. However, ambiguities can lead to outputs that seem correct but fail to reflect the speaker's intent. In this paper, we explore this issue with a focus on the data visualization domain, where ambiguities in natural language impact the generation of code that visualizes data. The availability of multiple views on the contextual (e.g., the intended plot and the code rendering the plot) allows for a unique and comprehensive analysis of diverse ambiguity types. We develop a taxonomy of types of ambiguity that arise in this task and propose metrics to quantify them. Using Matplotlib problems from the DS-1000 dataset, we demonstrate that our ambiguity metrics better correlate with human annotations than uncertainty baselines. Our work also explores how multi-turn dialogue can reduce ambiguity, therefore, improve code accuracy by better matching user goals. We evaluate three pragmatic models to inform our dialogue strategies: Gricean Cooperativity, Discourse Representation Theory, and Questions under Discussion. A simulated user study reveals how pragmatic dialogues reduce ambiguity and enhance code accuracy, highlighting the value of multi-turn exchanges in code generation.
Measuring How (Not Just Whether) VLMs Build Common Ground
Sep 04, 2025Large vision language models (VLMs) increasingly claim reasoning skills, yet current benchmarks evaluate them in single-turn or question answering settings. However, grounding is an interactive process in which people gradually develop shared understanding through ongoing communication. We introduce a four-metric suite (grounding efficiency, content alignment, lexical adaptation, and human-likeness) to systematically evaluate VLM performance in interactive grounding contexts. We deploy the suite on 150 self-play sessions of interactive referential games between three proprietary VLMs and compare them with human dyads. All three models diverge from human patterns on at least three metrics, while GPT4o-mini is the closest overall. We find that (i) task success scores do not indicate successful grounding and (ii) high image-utterance alignment does not necessarily predict task success. Our metric suite and findings offer a framework for future research on VLM grounding.
SiLVERScore: Semantically-Aware Embeddings for Sign Language Generation Evaluation
Sep 04, 2025Evaluating sign language generation is often done through back-translation, where generated signs are first recognized back to text and then compared to a reference using text-based metrics. However, this two-step evaluation pipeline introduces ambiguity: it not only fails to capture the multimodal nature of sign language-such as facial expressions, spatial grammar, and prosody-but also makes it hard to pinpoint whether evaluation errors come from sign generation model or the translation system used to assess it. In this work, we propose SiLVERScore, a novel semantically-aware embedding-based evaluation metric that assesses sign language generation in a joint embedding space. Our contributions include: (1) identifying limitations of existing metrics, (2) introducing SiLVERScore for semantically-aware evaluation, (3) demonstrating its robustness to semantic and prosodic variations, and (4) exploring generalization challenges across datasets. On PHOENIX-14T and CSL-Daily datasets, SiLVERScore achieves near-perfect discrimination between correct and random pairs (ROC AUC = 0.99, overlap < 7%), substantially outperforming traditional metrics.
Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems
Jan 31, 2025



While theories of discourse and cognitive science have long recognized the value of unhurried pacing, recent dialogue research tends to minimize friction in conversational systems. Yet, frictionless dialogue risks fostering uncritical reliance on AI outputs, which can obscure implicit assumptions and lead to unintended consequences. To meet this challenge, we propose integrating positive friction into conversational AI, which promotes user reflection on goals, critical thinking on system response, and subsequent re-conditioning of AI systems. We hypothesize systems can improve goal alignment, modeling of user mental states, and task success by deliberately slowing down conversations in strategic moments to ask questions, reveal assumptions, or pause. We present an ontology of positive friction and collect expert human annotations on multi-domain and embodied goal-oriented corpora. Experiments on these corpora, along with simulated interactions using state-of-the-art systems, suggest incorporating friction not only fosters accountable decision-making, but also enhances machine understanding of user beliefs and goals, and increases task success rates.
Generating Signed Language Instructions in Large-Scale Dialogue Systems
Oct 17, 2024



We introduce a goal-oriented conversational AI system enhanced with American Sign Language (ASL) instructions, presenting the first implementation of such a system on a worldwide multimodal conversational AI platform. Accessible through a touch-based interface, our system receives input from users and seamlessly generates ASL instructions by leveraging retrieval methods and cognitively based gloss translations. Central to our design is a sign translation module powered by Large Language Models, alongside a token-based video retrieval system for delivering instructional content from recipes and wikiHow guides. Our development process is deeply rooted in a commitment to community engagement, incorporating insights from the Deaf and Hard-of-Hearing community, as well as experts in cognitive and ASL learning sciences. The effectiveness of our signing instructions is validated by user feedback, achieving ratings on par with those of the system in its non-signing variant. Additionally, our system demonstrates exceptional performance in retrieval accuracy and text-generation quality, measured by metrics such as BERTScore. We have made our codebase and datasets publicly accessible at https://github.com/Merterm/signed-dialogue, and a demo of our signed instruction video retrieval system is available at https://huggingface.co/spaces/merterm/signed-instructions.
Learning Multimodal Cues of Children's Uncertainty
Oct 17, 2024



Understanding uncertainty plays a critical role in achieving common ground (Clark et al.,1983). This is especially important for multimodal AI systems that collaborate with users to solve a problem or guide the user through a challenging concept. In this work, for the first time, we present a dataset annotated in collaboration with developmental and cognitive psychologists for the purpose of studying nonverbal cues of uncertainty. We then present an analysis of the data, studying different roles of uncertainty and its relationship with task difficulty and performance. Lastly, we present a multimodal machine learning model that can predict uncertainty given a real-time video clip of a participant, which we find improves upon a baseline multimodal transformer model. This work informs research on cognitive coordination between human-human and human-AI and has broad implications for gesture understanding and generation. The anonymized version of our data and code will be publicly available upon the completion of the required consent forms and data sheets.
Multimodal Contextualized Plan Prediction for Embodied Task Completion
May 10, 2023Task planning is an important component of traditional robotics systems enabling robots to compose fine grained skills to perform more complex tasks. Recent work building systems for translating natural language to executable actions for task completion in simulated embodied agents is focused on directly predicting low level action sequences that would be expected to be directly executable by a physical robot. In this work, we instead focus on predicting a higher level plan representation for one such embodied task completion dataset - TEACh, under the assumption that techniques for high-level plan prediction from natural language are expected to be more transferable to physical robot systems. We demonstrate that better plans can be predicted using multimodal context, and that plan prediction and plan execution modules are likely dependent on each other and hence it may not be ideal to fully decouple them. Further, we benchmark execution of oracle plans to quantify the scope for improvement in plan prediction models.
Modeling Intensification for Sign Language Generation: A Computational Approach
Mar 18, 2022
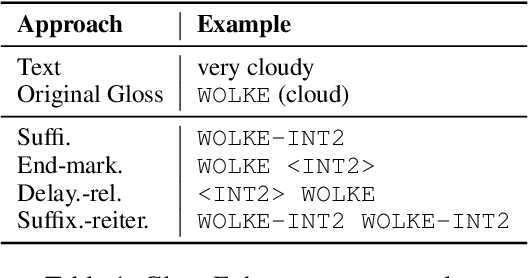
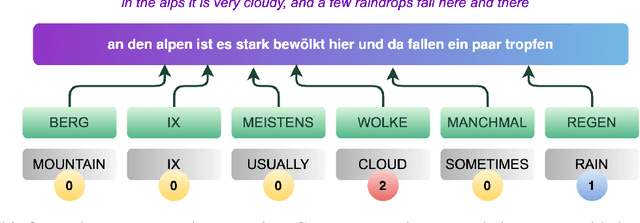
End-to-end sign language generation models do not accurately represent the prosody in sign language. A lack of temporal and spatial variations leads to poor-quality generated presentations that confuse human interpreters. In this paper, we aim to improve the prosody in generated sign languages by modeling intensification in a data-driven manner. We present different strategies grounded in linguistics of sign language that inform how intensity modifiers can be represented in gloss annotations. To employ our strategies, we first annotate a subset of the benchmark PHOENIX-14T, a German Sign Language dataset, with different levels of intensification. We then use a supervised intensity tagger to extend the annotated dataset and obtain labels for the remaining portion of it. This enhanced dataset is then used to train state-of-the-art transformer models for sign language generation. We find that our efforts in intensification modeling yield better results when evaluated with automatic metrics. Human evaluation also indicates a higher preference of the videos generated using our model.
Including Facial Expressions in Contextual Embeddings for Sign Language Generation
Feb 11, 2022



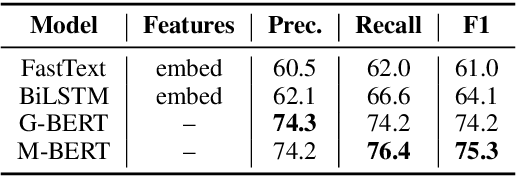
State-of-the-art sign language generation frameworks lack expressivity and naturalness which is the result of only focusing manual signs, neglecting the affective, grammatical and semantic functions of facial expressions. The purpose of this work is to augment semantic representation of sign language through grounding facial expressions. We study the effect of modeling the relationship between text, gloss, and facial expressions on the performance of the sign generation systems. In particular, we propose a Dual Encoder Transformer able to generate manual signs as well as facial expressions by capturing the similarities and differences found in text and sign gloss annotation. We take into consideration the role of facial muscle activity to express intensities of manual signs by being the first to employ facial action units in sign language generation. We perform a series of experiments showing that our proposed model improves the quality of automatically generated sign language.
COSMic: A Coherence-Aware Generation Metric for Image Descriptions
Sep 11, 2021
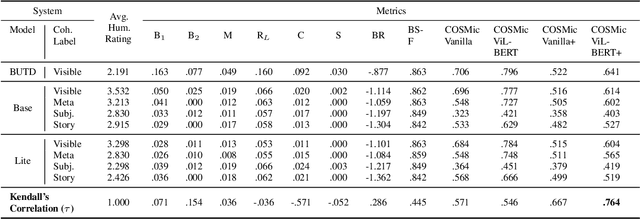

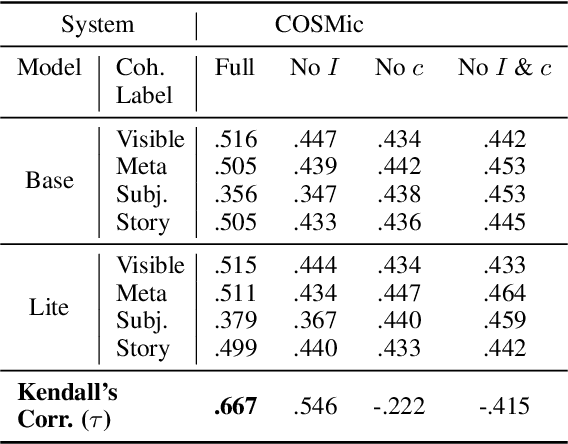
Developers of text generation models rely on automated evaluation metrics as a stand-in for slow and expensive manual evaluations. However, image captioning metrics have struggled to give accurate learned estimates of the semantic and pragmatic success of output text. We address this weakness by introducing the first discourse-aware learned generation metric for evaluating image descriptions. Our approach is inspired by computational theories of discourse for capturing information goals using coherence. We present a dataset of image$\unicode{x2013}$description pairs annotated with coherence relations. We then train a coherence-aware metric on a subset of the Conceptual Captions dataset and measure its effectiveness$\unicode{x2014}$its ability to predict human ratings of output captions$\unicode{x2014}$on a test set composed of out-of-domain images. We demonstrate a higher Kendall Correlation Coefficient for our proposed metric with the human judgments for the results of a number of state-of-the-art coherence-aware caption generation models when compared to several other metrics including recently proposed learned metrics such as BLEURT and BERTScore.