 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGA-VLN: Geometry-Aware BEV Representation for Efficient Vision-Language Navigation
May 21, 2026Despite significant progress in Vision-Language Navigation (VLN), existing approaches still rely on dense RGB videos that produce excessive patch tokens and lack explicit spatial structure, resulting in substantial computational overhead and limited spatial reasoning. To address these issues, we introduce the Geometry-Aware BEV (GA-BEV) - a compact, 3D-grounded feature representation that integrates both explicit and implicit geometric cues into multimodal large language model (MLLM) - based navigation systems. We construct BEV spatial maps from RGB-D inputs by projecting visual features into 3D space and aggregating them into an agent-centric layout that preserves geometric consistency while reducing token redundancy. To further enrich geometric understanding, we incorporate features from a pretrained 3D foundation model into the BEV space, injecting structural priors learned from large-scale 3D reconstruction tasks. Together, these complementary cues - explicit depth-based projection and implicit learned priors - yield compact yet spatially expressive representations that substantially improve navigation efficiency and performance. Experiments show that our method achieves state-of-the-art results using only navigation data, without DAgger augmentation or mixed VQA training, demonstrating the robustness and data efficiency of the proposed GA-VLN framework.
TrajRAG: Retrieving Geometric-Semantic Experience for Zero-Shot Object Navigation
May 03, 2026Existing zero-shot Object Goal Navigation (ObjectNav) methods often exploit commonsense knowledge from large language or vision-language models to guide navigation. However, such knowledge arises from internet-scale text rather than embodied 3D experience, and episodic observations collected during navigation are typically discarded, preventing the accumulation of lifelong experience. To this end, we propose Trajectory RAG (TrajRAG), a retrieval-augmented generation framework that enhances large-model reasoning by retrieving geometric-semantic experiences. TrajRAG incrementally accumulates episodic observations from past navigation episodes. To structure these observations, we propose a topological-polar (topo-polar) trajectory representation that compactly encodes spatial layouts and semantic contexts, effectively removing redundancies in raw episodic observations. A hierarchical chunking structure further organizes similar topo-polar trajectories into unified summaries, enabling coarse-to-fine retrieval. During navigation, candidate frontiers generate multiple trajectory hypotheses that query TrajRAG for similar past trajectories, guiding large-model reasoning for waypoint selection. New experiences are continually consolidated into TrajRAG, enabling the accumulation of lifelong navigation experience. Experiments on MP3D, HM3D-v1, and HM3D-v2 show that TrajRAG effectively retrieves relevant geometric-semantic experiences and improves zero-shot ObjectNav performance.
Multi-Scale Gaussian-Language Map for Zero-shot Embodied Navigation and Reasoning
May 03, 2026Understanding the geometric and semantic structure of environments is essential for embodied navigation and reasoning. Existing semantic mapping methods trade off between explicit geometry and multi-scale semantics, and lack a native interface for large models, thus requiring additional training of feature projection for semantic alignment. To this end, we propose the multi-scale Gaussian-Language Map (GLMap), which introduces three key designs: (1) explicit geometry, (2) multi-scale semantics covering both instance and region concepts, and (3) a dual-modality interface where each semantic unit jointly stores a natural language description and a 3D Gaussian representation. The 3D Gaussians enable compact storage and fast rendering of task-relevant images via Gaussian splatting. To enable efficient incremental construction, we further propose a Gaussian Estimator that analytically derives Gaussian parameters from dense point clouds without gradient-based optimization. Experiments on ObjectNav, InstNav, and SQA tasks show that GLMap effectively enhances target navigation and contextual reasoning, while remaining compatible with large-model-based methods in a zero-shot manner. The code is available at https://github.com/sx-zhang/GLMap.
OmniFood8K: Single-Image Nutrition Estimation via Hierarchical Frequency-Aligned Fusion
Apr 14, 2026Accurate estimation of food nutrition plays a vital role in promoting healthy dietary habits and personalized diet management. Most existing food datasets primarily focus on Western cuisines and lack sufficient coverage of Chinese dishes, which restricts accurate nutritional estimation for Chinese meals. Moreover, many state-of-the-art nutrition prediction methods rely on depth sensors, restricting their applicability in daily scenarios. To address these limitations, we introduce OmniFood8K, a comprehensive multimodal dataset comprising 8,036 food samples, each with detailed nutritional annotations and multi-view images. In addition, to enhance models' capability in nutritional prediction, we construct NutritionSynth-115K, a large-scale synthetic dataset that introduces compositional variations while preserving precise nutritional labels. Moreover, we propose an end-to-end framework for nutritional prediction from a single RGB image. First, we predict a depth map from a single RGB image and design the Scale-Shift Residual Adapter (SSRA) to refine it for global scale consistency and local structural preservation. Second, we propose the Frequency-Aligned Fusion Module (FAFM) to hierarchically align and fuse RGB and depth features in the frequency domain. Finally, we design a Mask-based Prediction Head (MPH) to emphasize key ingredient regions via dynamic channel selection for more accurate prediction. Extensive experiments on multiple datasets demonstrate the superiority of our method over existing approaches. Project homepage: https://yudongjian.github.io/OmniFood8K-food/
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
Sim-to-Real Transfer via 3D Feature Fields for Vision-and-Language Navigation
Jun 14, 2024



Vision-and-language navigation (VLN) enables the agent to navigate to a remote location in 3D environments following the natural language instruction. In this field, the agent is usually trained and evaluated in the navigation simulators, lacking effective approaches for sim-to-real transfer. The VLN agents with only a monocular camera exhibit extremely limited performance, while the mainstream VLN models trained with panoramic observation, perform better but are difficult to deploy on most monocular robots. For this case, we propose a sim-to-real transfer approach to endow the monocular robots with panoramic traversability perception and panoramic semantic understanding, thus smoothly transferring the high-performance panoramic VLN models to the common monocular robots. In this work, the semantic traversable map is proposed to predict agent-centric navigable waypoints, and the novel view representations of these navigable waypoints are predicted through the 3D feature fields. These methods broaden the limited field of view of the monocular robots and significantly improve navigation performance in the real world. Our VLN system outperforms previous SOTA monocular VLN methods in R2R-CE and RxR-CE benchmarks within the simulation environments and is also validated in real-world environments, providing a practical and high-performance solution for real-world VLN.
FoodSky: A Food-oriented Large Language Model that Passes the Chef and Dietetic Examination
Jun 11, 2024



Food is foundational to human life, serving not only as a source of nourishment but also as a cornerstone of cultural identity and social interaction. As the complexity of global dietary needs and preferences grows, food intelligence is needed to enable food perception and reasoning for various tasks, ranging from recipe generation and dietary recommendation to diet-disease correlation discovery and understanding. Towards this goal, for powerful capabilities across various domains and tasks in Large Language Models (LLMs), we introduce Food-oriented LLM FoodSky to comprehend food data through perception and reasoning. Considering the complexity and typicality of Chinese cuisine, we first construct one comprehensive Chinese food corpus FoodEarth from various authoritative sources, which can be leveraged by FoodSky to achieve deep understanding of food-related data. We then propose Topic-based Selective State Space Model (TS3M) and the Hierarchical Topic Retrieval Augmented Generation (HTRAG) mechanism to enhance FoodSky in capturing fine-grained food semantics and generating context-aware food-relevant text, respectively. Our extensive evaluations demonstrate that FoodSky significantly outperforms general-purpose LLMs in both chef and dietetic examinations, with an accuracy of 67.2% and 66.4% on the Chinese National Chef Exam and the National Dietetic Exam, respectively. FoodSky not only promises to enhance culinary creativity and promote healthier eating patterns, but also sets a new standard for domain-specific LLMs that address complex real-world issues in the food domain. An online demonstration of FoodSky is available at http://222.92.101.211:8200.
DiffGen: Robot Demonstration Generation via Differentiable Physics Simulation, Differentiable Rendering, and Vision-Language Model
May 12, 2024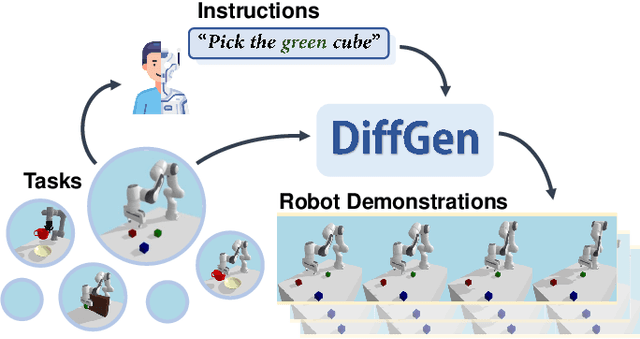
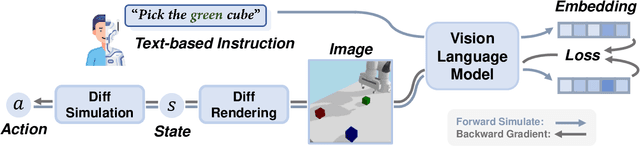
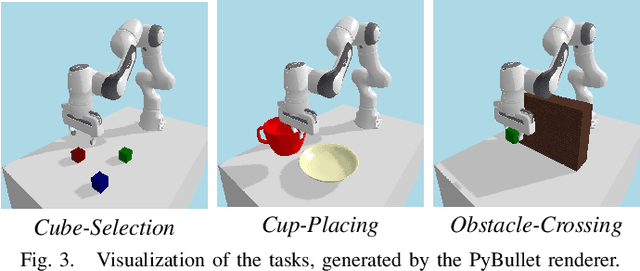
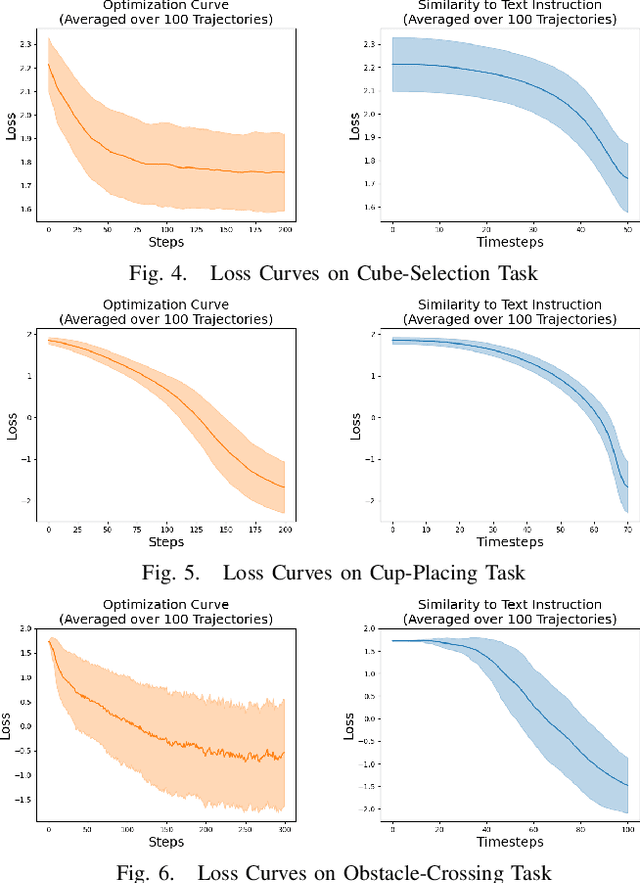
Generating robot demonstrations through simulation is widely recognized as an effective way to scale up robot data. Previous work often trained reinforcement learning agents to generate expert policies, but this approach lacks sample efficiency. Recently, a line of work has attempted to generate robot demonstrations via differentiable simulation, which is promising but heavily relies on reward design, a labor-intensive process. In this paper, we propose DiffGen, a novel framework that integrates differentiable physics simulation, differentiable rendering, and a vision-language model to enable automatic and efficient generation of robot demonstrations. Given a simulated robot manipulation scenario and a natural language instruction, DiffGen can generate realistic robot demonstrations by minimizing the distance between the embedding of the language instruction and the embedding of the simulated observation after manipulation. The embeddings are obtained from the vision-language model, and the optimization is achieved by calculating and descending gradients through the differentiable simulation, differentiable rendering, and vision-language model components, thereby accomplishing the specified task. Experiments demonstrate that with DiffGen, we could efficiently and effectively generate robot data with minimal human effort or training time.
Lookahead Exploration with Neural Radiance Representation for Continuous Vision-Language Navigation
Apr 02, 2024



Vision-and-language navigation (VLN) enables the agent to navigate to a remote location following the natural language instruction in 3D environments. At each navigation step, the agent selects from possible candidate locations and then makes the move. For better navigation planning, the lookahead exploration strategy aims to effectively evaluate the agent's next action by accurately anticipating the future environment of candidate locations. To this end, some existing works predict RGB images for future environments, while this strategy suffers from image distortion and high computational cost. To address these issues, we propose the pre-trained hierarchical neural radiance representation model (HNR) to produce multi-level semantic features for future environments, which are more robust and efficient than pixel-wise RGB reconstruction. Furthermore, with the predicted future environmental representations, our lookahead VLN model is able to construct the navigable future path tree and select the optimal path via efficient parallel evaluation. Extensive experiments on the VLN-CE datasets confirm the effectiveness of our method.
Synthesizing Knowledge-enhanced Features for Real-world Zero-shot Food Detection
Feb 14, 2024Food computing brings various perspectives to computer vision like vision-based food analysis for nutrition and health. As a fundamental task in food computing, food detection needs Zero-Shot Detection (ZSD) on novel unseen food objects to support real-world scenarios, such as intelligent kitchens and smart restaurants. Therefore, we first benchmark the task of Zero-Shot Food Detection (ZSFD) by introducing FOWA dataset with rich attribute annotations. Unlike ZSD, fine-grained problems in ZSFD like inter-class similarity make synthesized features inseparable. The complexity of food semantic attributes further makes it more difficult for current ZSD methods to distinguish various food categories. To address these problems, we propose a novel framework ZSFDet to tackle fine-grained problems by exploiting the interaction between complex attributes. Specifically, we model the correlation between food categories and attributes in ZSFDet by multi-source graphs to provide prior knowledge for distinguishing fine-grained features. Within ZSFDet, Knowledge-Enhanced Feature Synthesizer (KEFS) learns knowledge representation from multiple sources (e.g., ingredients correlation from knowledge graph) via the multi-source graph fusion. Conditioned on the fusion of semantic knowledge representation, the region feature diffusion model in KEFS can generate fine-grained features for training the effective zero-shot detector. Extensive evaluations demonstrate the superior performance of our method ZSFDet on FOWA and the widely-used food dataset UECFOOD-256, with significant improvements by 1.8% and 3.7% ZSD mAP compared with the strong baseline RRFS. Further experiments on PASCAL VOC and MS COCO prove that enhancement of the semantic knowledge can also improve the performance on general ZSD. Code and dataset are available at https://github.com/LanceZPF/KEFS.