 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfSeg: A Self-supervised Sub-word Segmentation Method for Neural Machine Translation
Jul 31, 2023



Sub-word segmentation is an essential pre-processing step for Neural Machine Translation (NMT). Existing work has shown that neural sub-word segmenters are better than Byte-Pair Encoding (BPE), however, they are inefficient as they require parallel corpora, days to train and hours to decode. This paper introduces SelfSeg, a self-supervised neural sub-word segmentation method that is much faster to train/decode and requires only monolingual dictionaries instead of parallel corpora. SelfSeg takes as input a word in the form of a partially masked character sequence, optimizes the word generation probability and generates the segmentation with the maximum posterior probability, which is calculated using a dynamic programming algorithm. The training time of SelfSeg depends on word frequencies, and we explore several word frequency normalization strategies to accelerate the training phase. Additionally, we propose a regularization mechanism that allows the segmenter to generate various segmentations for one word. To show the effectiveness of our approach, we conduct MT experiments in low-, middle- and high-resource scenarios, where we compare the performance of using different segmentation methods. The experimental results demonstrate that on the low-resource ALT dataset, our method achieves more than 1.2 BLEU score improvement compared with BPE and SentencePiece, and a 1.1 score improvement over Dynamic Programming Encoding (DPE) and Vocabulary Learning via Optimal Transport (VOLT) on average. The regularization method achieves approximately a 4.3 BLEU score improvement over BPE and a 1.2 BLEU score improvement over BPE-dropout, the regularized version of BPE. We also observed significant improvements on IWSLT15 Vi->En, WMT16 Ro->En and WMT15 Fi->En datasets, and competitive results on the WMT14 De->En and WMT14 Fr->En datasets.
Universal Multimodal Representation for Language Understanding
Jan 09, 2023



Representation learning is the foundation of natural language processing (NLP). This work presents new methods to employ visual information as assistant signals to general NLP tasks. For each sentence, we first retrieve a flexible number of images either from a light topic-image lookup table extracted over the existing sentence-image pairs or a shared cross-modal embedding space that is pre-trained on out-of-shelf text-image pairs. Then, the text and images are encoded by a Transformer encoder and convolutional neural network, respectively. The two sequences of representations are further fused by an attention layer for the interaction of the two modalities. In this study, the retrieval process is controllable and flexible. The universal visual representation overcomes the lack of large-scale bilingual sentence-image pairs. Our method can be easily applied to text-only tasks without manually annotated multimodal parallel corpora. We apply the proposed method to a wide range of natural language generation and understanding tasks, including neural machine translation, natural language inference, and semantic similarity. Experimental results show that our method is generally effective for different tasks and languages. Analysis indicates that the visual signals enrich textual representations of content words, provide fine-grained grounding information about the relationship between concepts and events, and potentially conduce to disambiguation.
Language Model Pre-training on True Negatives
Dec 01, 2022



Discriminative pre-trained language models (PLMs) learn to predict original texts from intentionally corrupted ones. Taking the former text as positive and the latter as negative samples, the PLM can be trained effectively for contextualized representation. However, the training of such a type of PLMs highly relies on the quality of the automatically constructed samples. Existing PLMs simply treat all corrupted texts as equal negative without any examination, which actually lets the resulting model inevitably suffer from the false negative issue where training is carried out on pseudo-negative data and leads to less efficiency and less robustness in the resulting PLMs. In this work, on the basis of defining the false negative issue in discriminative PLMs that has been ignored for a long time, we design enhanced pre-training methods to counteract false negative predictions and encourage pre-training language models on true negatives by correcting the harmful gradient updates subject to false negative predictions. Experimental results on GLUE and SQuAD benchmarks show that our counter-false-negative pre-training methods indeed bring about better performance together with stronger robustness.
Extending the Subwording Model of Multilingual Pretrained Models for New Languages
Nov 29, 2022Multilingual pretrained models are effective for machine translation and cross-lingual processing because they contain multiple languages in one model. However, they are pretrained after their tokenizers are fixed; therefore it is difficult to change the vocabulary after pretraining. When we extend the pretrained models to new languages, we must modify the tokenizers simultaneously. In this paper, we add new subwords to the SentencePiece tokenizer to apply a multilingual pretrained model to new languages (Inuktitut in this paper). In our experiments, we segmented Inuktitut sentences into subwords without changing the segmentation of already pretrained languages, and applied the mBART-50 pretrained model to English-Inuktitut translation.
Smoothing Dialogue States for Open Conversational Machine Reading
Sep 02, 2021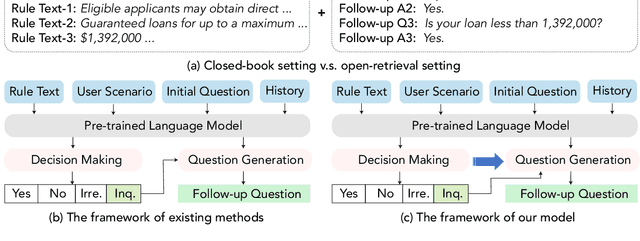
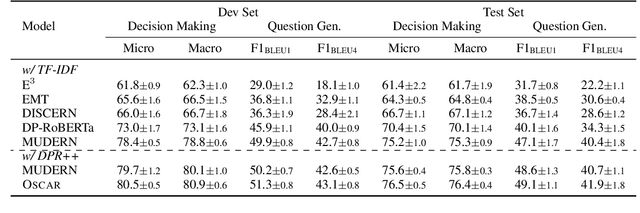
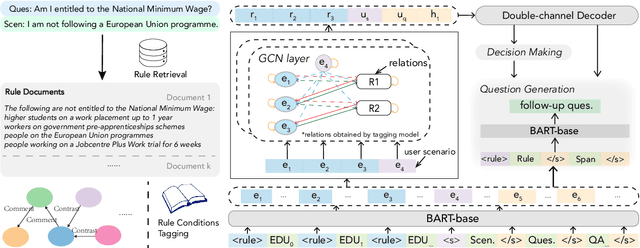
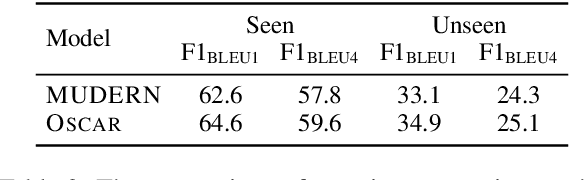
Conversational machine reading (CMR) requires machines to communicate with humans through multi-turn interactions between two salient dialogue states of decision making and question generation processes. In open CMR settings, as the more realistic scenario, the retrieved background knowledge would be noisy, which results in severe challenges in the information transmission. Existing studies commonly train independent or pipeline systems for the two subtasks. However, those methods are trivial by using hard-label decisions to activate question generation, which eventually hinders the model performance. In this work, we propose an effective gating strategy by smoothing the two dialogue states in only one decoder and bridge decision making and question generation to provide a richer dialogue state reference. Experiments on the OR-ShARC dataset show the effectiveness of our method, which achieves new state-of-the-art results.
YANMTT: Yet Another Neural Machine Translation Toolkit
Aug 25, 2021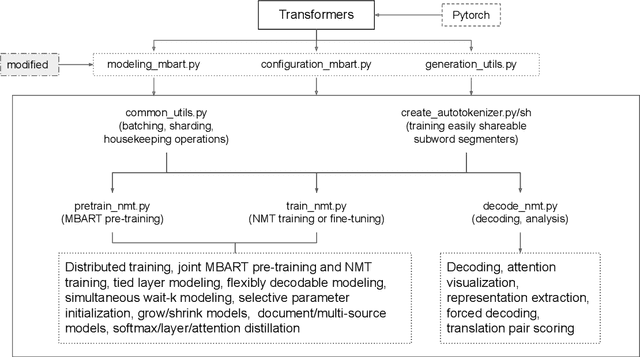
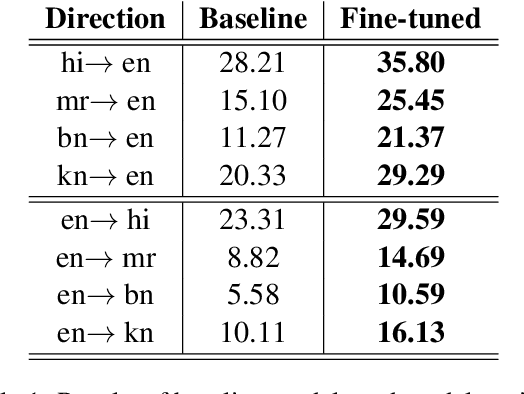
In this paper we present our open-source neural machine translation (NMT) toolkit called "Yet Another Neural Machine Translation Toolkit" abbreviated as YANMTT which is built on top of the Transformers library. Despite the growing importance of sequence to sequence pre-training there surprisingly few, if not none, well established toolkits that allow users to easily do pre-training. Toolkits such as Fairseq which do allow pre-training, have very large codebases and thus they are not beginner friendly. With regards to transfer learning via fine-tuning most toolkits do not explicitly allow the user to have control over what parts of the pre-trained models can be transferred. YANMTT aims to address these issues via the minimum amount of code to pre-train large scale NMT models, selectively transfer pre-trained parameters and fine-tune them, perform translation as well as extract representations and attentions for visualization and analyses. Apart from these core features our toolkit also provides other advanced functionalities such as but not limited to document/multi-source NMT, simultaneous NMT and model compression via distillation which we believe are relevant to the purpose behind our toolkit.
Cross-lingual Transferring of Pre-trained Contextualized Language Models
Jul 27, 2021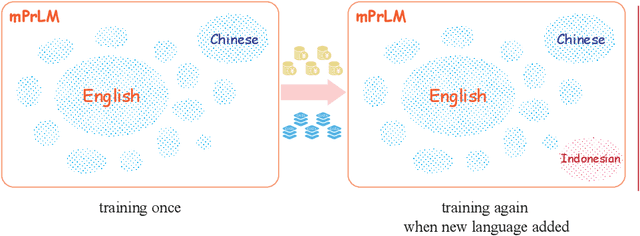
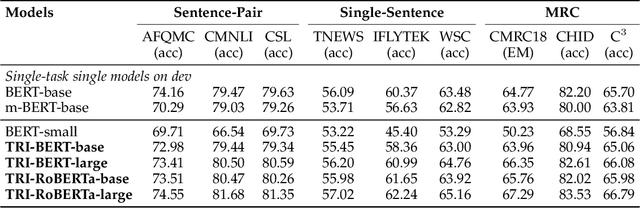
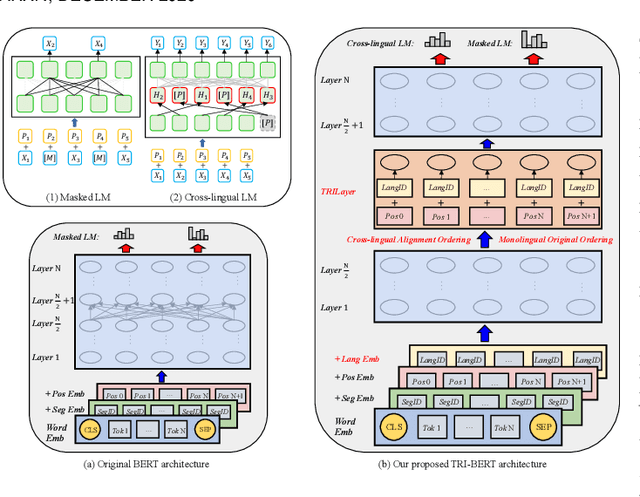
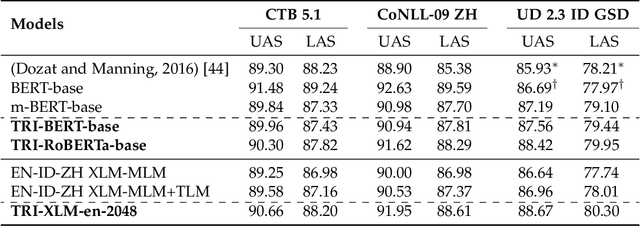
Though the pre-trained contextualized language model (PrLM) has made a significant impact on NLP, training PrLMs in languages other than English can be impractical for two reasons: other languages often lack corpora sufficient for training powerful PrLMs, and because of the commonalities among human languages, computationally expensive PrLM training for different languages is somewhat redundant. In this work, building upon the recent works connecting cross-lingual model transferring and neural machine translation, we thus propose a novel cross-lingual model transferring framework for PrLMs: TreLM. To handle the symbol order and sequence length differences between languages, we propose an intermediate ``TRILayer" structure that learns from these differences and creates a better transfer in our primary translation direction, as well as a new cross-lingual language modeling objective for transfer training. Additionally, we showcase an embedding aligning that adversarially adapts a PrLM's non-contextualized embedding space and the TRILayer structure to learn a text transformation network across languages, which addresses the vocabulary difference between languages. Experiments on both language understanding and structure parsing tasks show the proposed framework significantly outperforms language models trained from scratch with limited data in both performance and efficiency. Moreover, despite an insignificant performance loss compared to pre-training from scratch in resource-rich scenarios, our cross-lingual model transferring framework is significantly more economical.
User-Generated Text Corpus for Evaluating Japanese Morphological Analysis and Lexical Normalization
Apr 08, 2021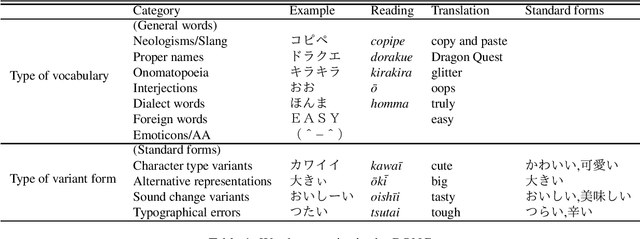
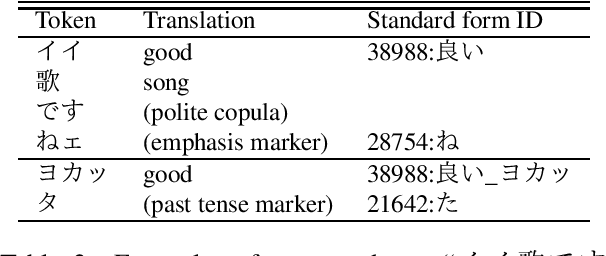

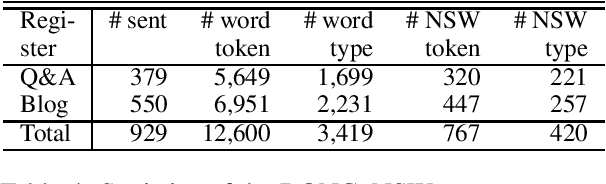
Morphological analysis (MA) and lexical normalization (LN) are both important tasks for Japanese user-generated text (UGT). To evaluate and compare different MA/LN systems, we have constructed a publicly available Japanese UGT corpus. Our corpus comprises 929 sentences annotated with morphological and normalization information, along with category information we classified for frequent UGT-specific phenomena. Experiments on the corpus demonstrated the low performance of existing MA/LN methods for non-general words and non-standard forms, indicating that the corpus would be a challenging benchmark for further research on UGT.
Text Compression-aided Transformer Encoding
Feb 11, 2021
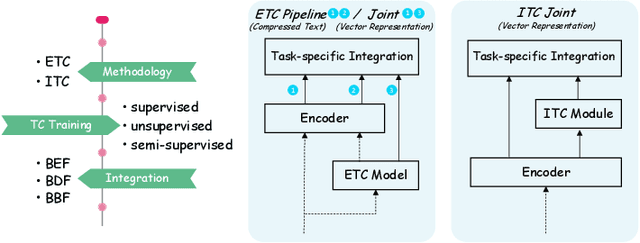
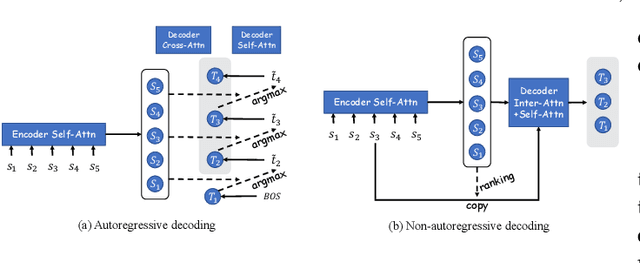
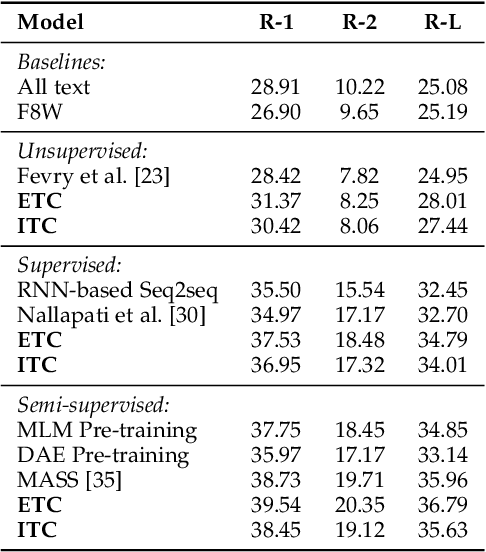
Text encoding is one of the most important steps in Natural Language Processing (NLP). It has been done well by the self-attention mechanism in the current state-of-the-art Transformer encoder, which has brought about significant improvements in the performance of many NLP tasks. Though the Transformer encoder may effectively capture general information in its resulting representations, the backbone information, meaning the gist of the input text, is not specifically focused on. In this paper, we propose explicit and implicit text compression approaches to enhance the Transformer encoding and evaluate models using this approach on several typical downstream tasks that rely on the encoding heavily. Our explicit text compression approaches use dedicated models to compress text, while our implicit text compression approach simply adds an additional module to the main model to handle text compression. We propose three ways of integration, namely backbone source-side fusion, target-side fusion, and both-side fusion, to integrate the backbone information into Transformer-based models for various downstream tasks. Our evaluation on benchmark datasets shows that the proposed explicit and implicit text compression approaches improve results in comparison to strong baselines. We therefore conclude, when comparing the encodings to the baseline models, text compression helps the encoders to learn better language representations.
SJTU-NICT's Supervised and Unsupervised Neural Machine Translation Systems for the WMT20 News Translation Task
Oct 11, 2020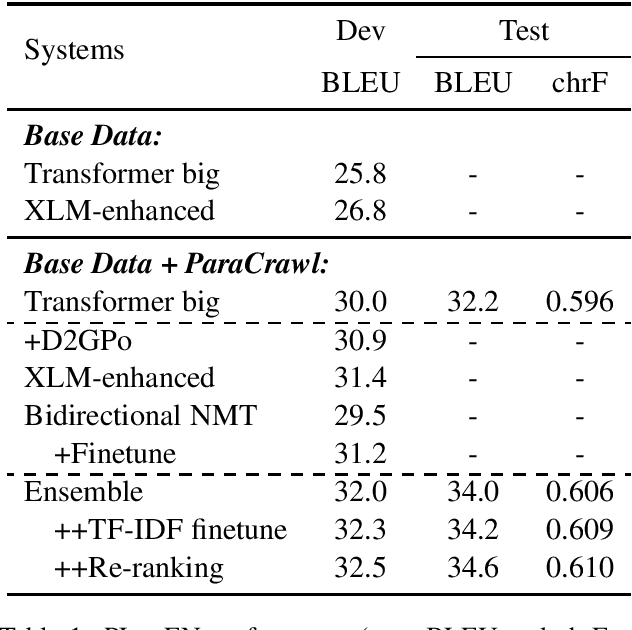
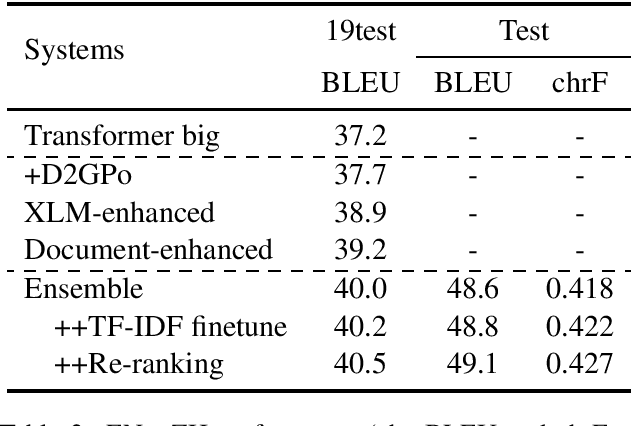
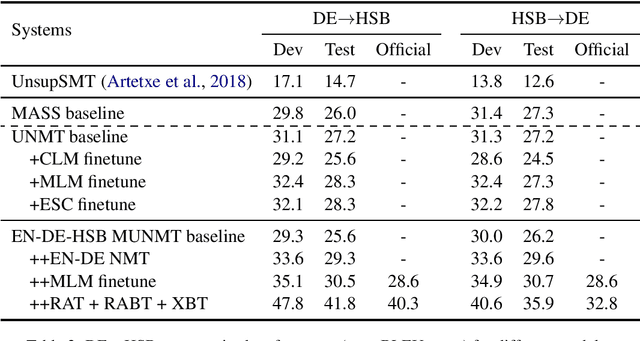
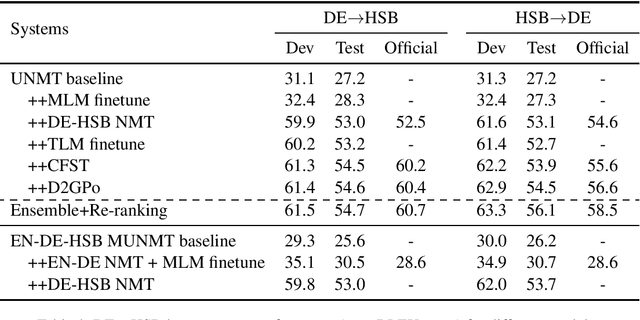
In this paper, we introduced our joint team SJTU-NICT 's participation in the WMT 2020 machine translation shared task. In this shared task, we participated in four translation directions of three language pairs: English-Chinese, English-Polish on supervised machine translation track, German-Upper Sorbian on low-resource and unsupervised machine translation tracks. Based on different conditions of language pairs, we have experimented with diverse neural machine translation (NMT) techniques: document-enhanced NMT, XLM pre-trained language model enhanced NMT, bidirectional translation as a pre-training, reference language based UNMT, data-dependent gaussian prior objective, and BT-BLEU collaborative filtering self-training. We also used the TF-IDF algorithm to filter the training set to obtain a domain more similar set with the test set for finetuning. In our submissions, the primary systems won the first place on English to Chinese, Polish to English, and German to Upper Sorbian translation directions.