 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Multimodal VAEs through Mutual Supervision
Jul 01, 2021


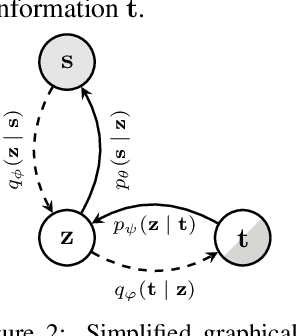

Multimodal VAEs seek to model the joint distribution over heterogeneous data (e.g.\ vision, language), whilst also capturing a shared representation across such modalities. Prior work has typically combined information from the modalities by reconciling idiosyncratic representations directly in the recognition model through explicit products, mixtures, or other such factorisations. Here we introduce a novel alternative, the MEME, that avoids such explicit combinations by repurposing semi-supervised VAEs to combine information between modalities implicitly through mutual supervision. This formulation naturally allows learning from partially-observed data where some modalities can be entirely missing -- something that most existing approaches either cannot handle, or do so to a limited extent. We demonstrate that MEME outperforms baselines on standard metrics across both partial and complete observation schemes on the MNIST-SVHN (image-image) and CUB (image-text) datasets. We also contrast the quality of the representations learnt by mutual supervision against standard approaches and observe interesting trends in its ability to capture relatedness between data.
Perceptual Learned Video Compression with Recurrent Conditional GAN
Sep 13, 2021

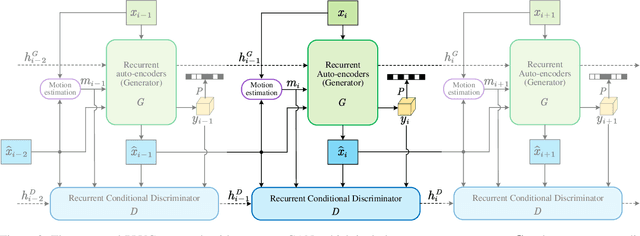
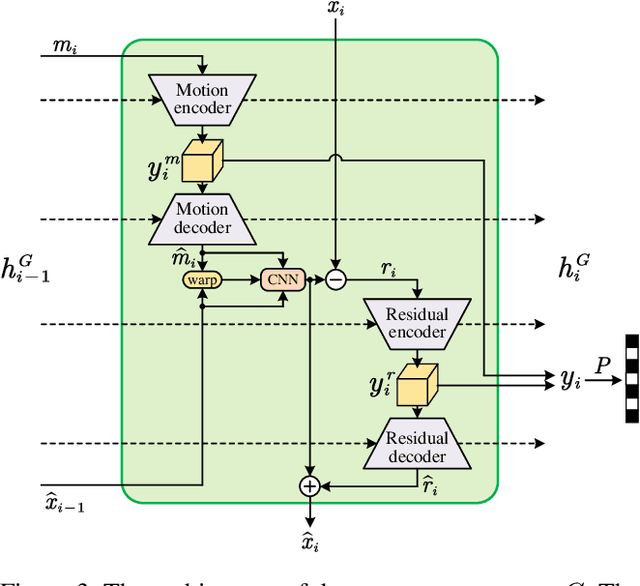
This paper proposes a Perceptual Learned Video Compression (PLVC) approach with recurrent conditional generative adversarial network. In our approach, the recurrent auto-encoder-based generator learns to fully explore the temporal correlation for compressing video. More importantly, we propose a recurrent conditional discriminator, which judges raw and compressed video conditioned on both spatial and temporal information, including the latent representation, temporal motion and hidden states in recurrent cells. This way, in the adversarial training, it pushes the generated video to be not only spatially photo-realistic but also temporally consistent with groundtruth and coherent among video frames. The experimental results show that the proposed PLVC model learns to compress video towards good perceptual quality at low bit-rate, and outperforms the previous traditional and learned approaches on several perceptual quality metrics. The user study further validates the outstanding perceptual performance of PLVC in comparison with the latest learned video compression approaches and the official HEVC test model (HM 16.20). The codes will be released at https://github.com/RenYang-home/PLVC.
Hybrid-Layers Neural Network Architectures for Modeling the Self-Interference in Full-Duplex Systems
Oct 18, 2021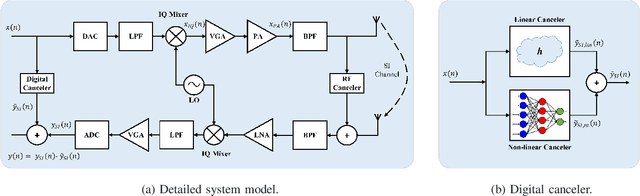
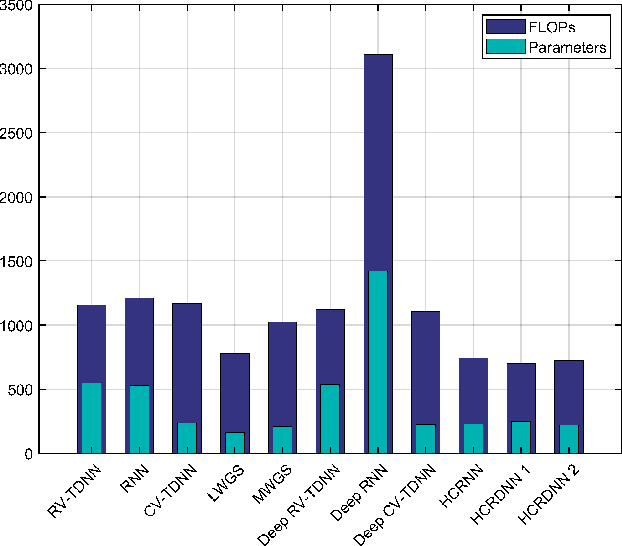
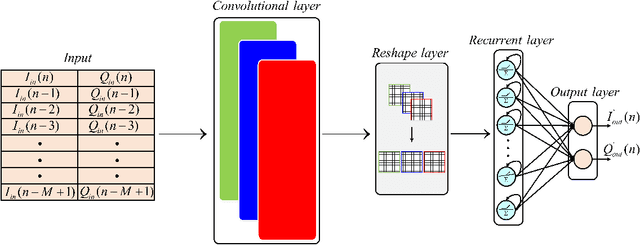
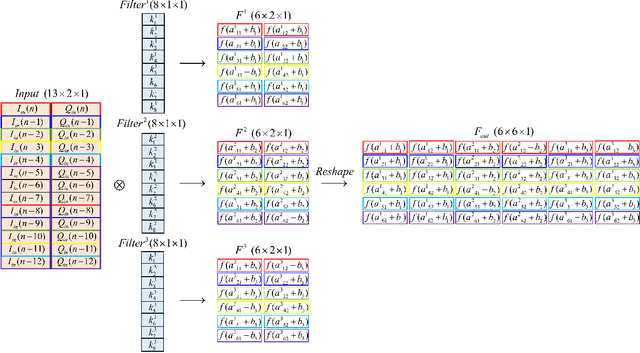
Full-duplex (FD) systems have been introduced to provide high data rates for beyond fifth-generation wireless networks through simultaneous transmission of information over the same frequency resources. However, the operation of FD systems is practically limited by the self-interference (SI), and efficient SI cancelers are sought to make the FD systems realizable. Typically, polynomial-based cancelers are employed to mitigate the SI; nevertheless, they suffer from high complexity. This article proposes two novel hybrid-layers neural network (NN) architectures to cancel the SI with low complexity. The first architecture is referred to as hybrid-convolutional recurrent NN (HCRNN), whereas the second is termed as hybrid-convolutional recurrent dense NN (HCRDNN). In contrast to the state-of-the-art NNs that employ dense or recurrent layers for SI modeling, the proposed NNs exploit, in a novel manner, a combination of different hidden layers (e.g., convolutional, recurrent, and/or dense) in order to model the SI with lower computational complexity than the polynomial and the state-of-the-art NN-based cancelers. The key idea behind using hybrid layers is to build an NN model, which makes use of the characteristics of the different layers employed in its architecture. More specifically, in the HCRNN, a convolutional layer is employed to extract the input data features using a reduced network scale. Moreover, a recurrent layer is then applied to assist in learning the temporal behavior of the input signal from the localized feature map of the convolutional layer. In the HCRDNN, an additional dense layer is exploited to add another degree of freedom for adapting the NN settings in order to achieve the best compromise between the cancellation performance and computational complexity. Complexity analysis and numerical simulations are provided to prove the superiority of the proposed architectures.
Distributed Expectation Propagation Detection for Cell-Free Massive MIMO
Aug 17, 2021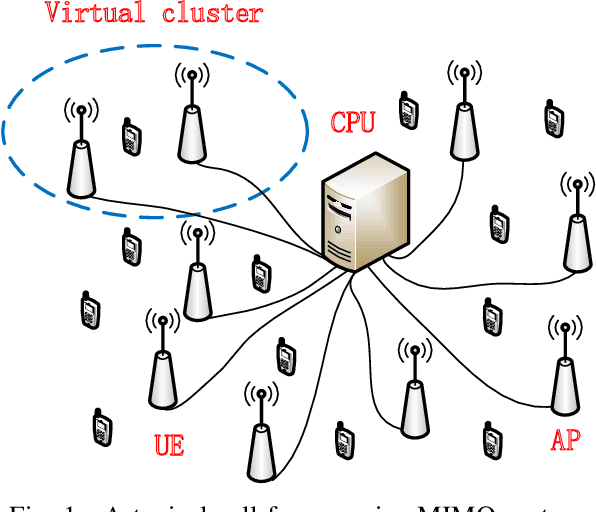
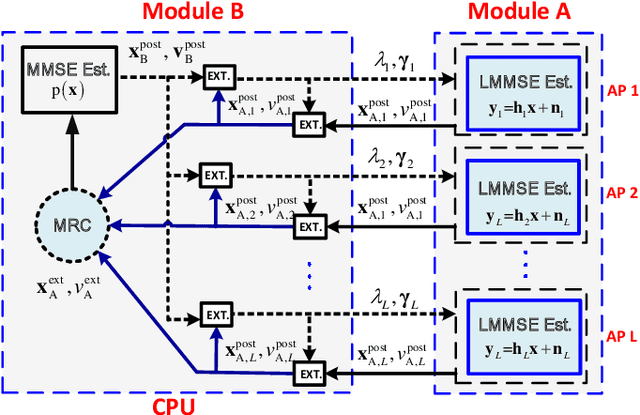
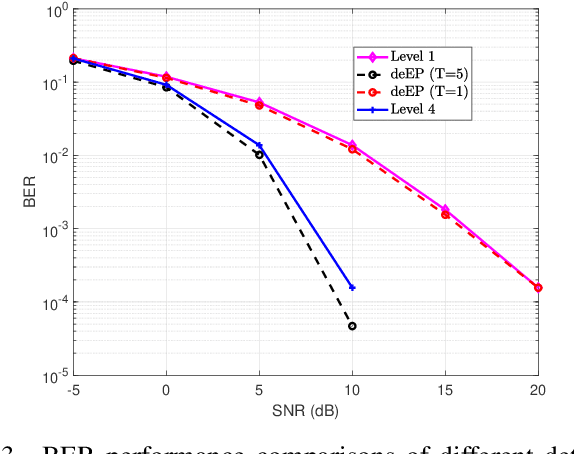
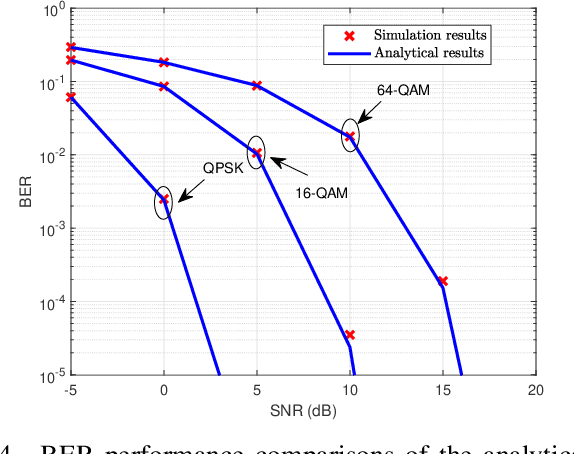
In cell-free massive MIMO networks, an efficient distributed detection algorithm is of significant importance. In this paper, we propose a distributed expectation propagation (EP) detector for cell-free massive MIMO. The detector is composed of two modules, a nonlinear module at the central processing unit (CPU) and a linear module at the access point (AP). The turbo principle in iterative decoding is utilized to compute and pass the extrinsic information between modules. An analytical framework is then provided to characterize the asymptotic performance of the proposed EP detector with a large number of antennas. Simulation results will show that the proposed method outperforms the distributed detectors in terms of bit-error-rate.
Learning to Perform Downlink Channel Estimation in Massive MIMO Systems
Sep 06, 2021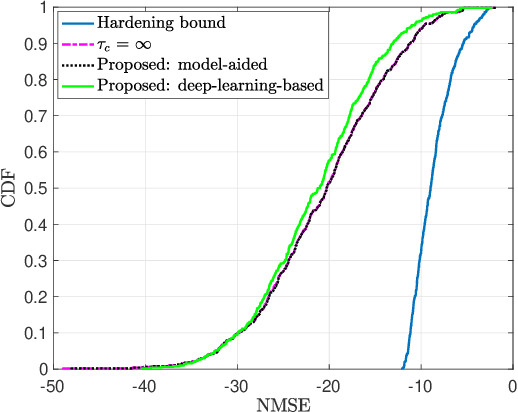
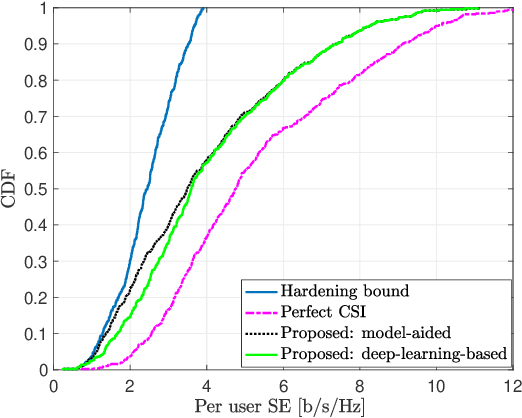
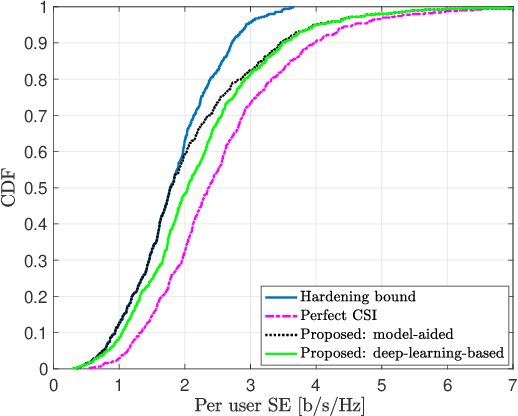

We study downlink (DL) channel estimation in a multi-cell Massive multiple-input multiple-output (MIMO) system operating in a time-division duplex. The users must know their effective channel gains to decode their received DL data signals. A common approach is to use the mean value as the estimate, motivated by channel hardening, but this is associated with a substantial performance loss in non-isotropic scattering environments. We propose two novel estimation methods. The first method is model-aided and utilizes asymptotic arguments to identify a connection between the effective channel gain and the average received power during a coherence block. The second one is a deep-learning-based approach that uses a neural network to identify a mapping between the available information and the effective channel gain. We compare the proposed methods against other benchmarks in terms of normalized mean-squared error and spectral efficiency (SE). The proposed methods provide substantial improvements, with the learning-based solution being the best of the considered estimators.
Optimal Power Allocation for Rate Splitting Communications with Deep Reinforcement Learning
Jul 01, 2021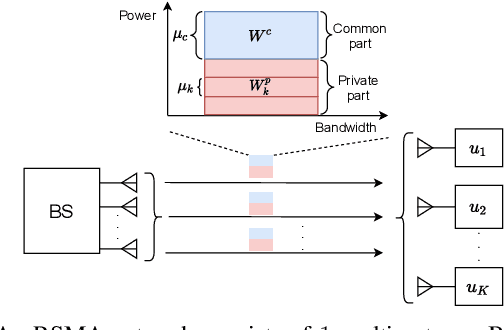
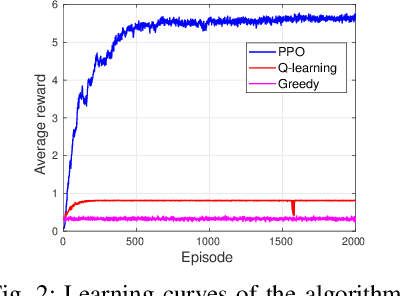
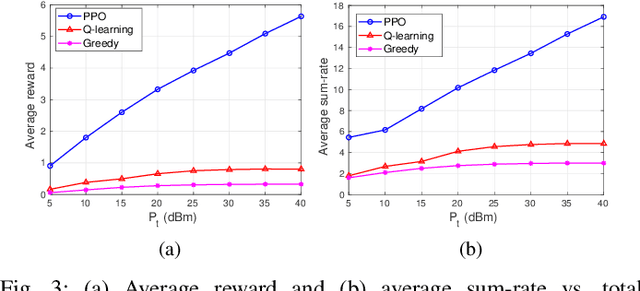
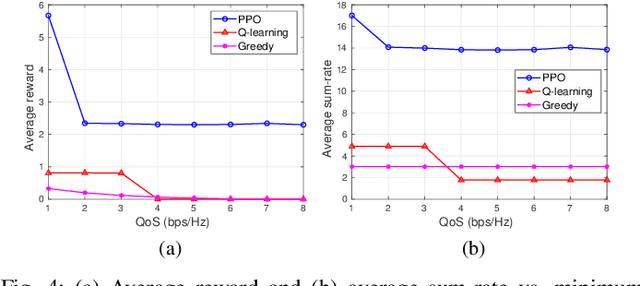
This letter introduces a novel framework to optimize the power allocation for users in a Rate Splitting Multiple Access (RSMA) network. In the network, messages intended for users are split into different parts that are a single common part and respective private parts. This mechanism enables RSMA to flexibly manage interference and thus enhance energy and spectral efficiency. Although possessing outstanding advantages, optimizing power allocation in RSMA is very challenging under the uncertainty of the communication channel and the transmitter has limited knowledge of the channel information. To solve the problem, we first develop a Markov Decision Process framework to model the dynamic of the communication channel. The deep reinforcement algorithm is then proposed to find the optimal power allocation policy for the transmitter without requiring any prior information of the channel. The simulation results show that the proposed scheme can outperform baseline schemes in terms of average sum-rate under different power and QoS requirements.
Predicting survival of glioblastoma from automatic whole-brain and tumor segmentation of MR images
Sep 25, 2021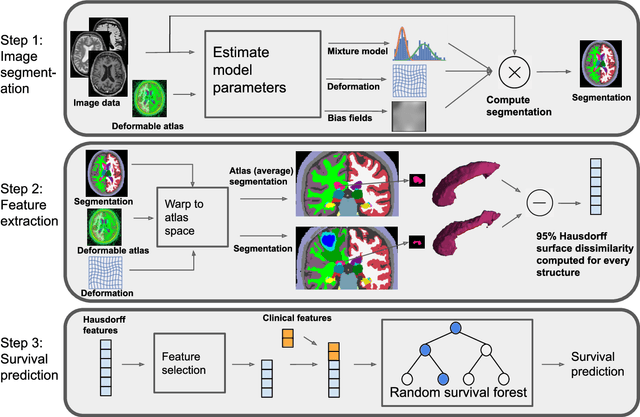

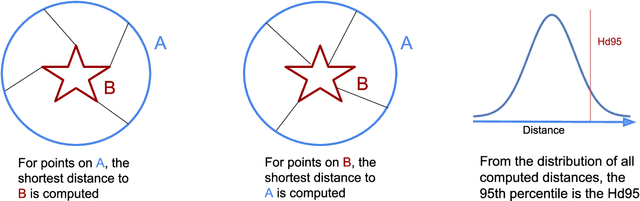
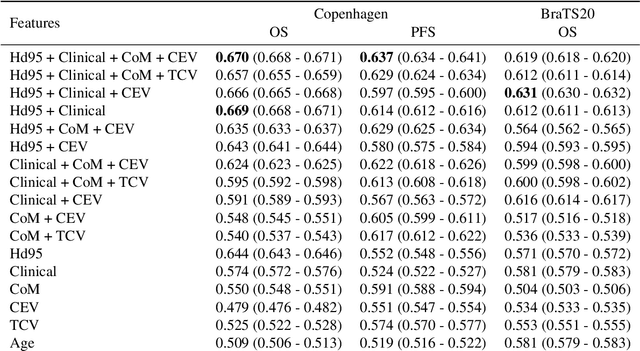
Survival prediction models can potentially be used to guide treatment of glioblastoma patients. However, currently available MR imaging biomarkers holding prognostic information are often challenging to interpret, have difficulties generalizing across data acquisitions, or are only applicable to pre-operative MR data. In this paper we aim to address these issues by introducing novel imaging features that can be automatically computed from MR images and fed into machine learning models to predict patient survival. The features we propose have a direct biological interpretation: They measure the deformation caused by the tumor on the surrounding brain structures, comparing the shape of various structures in the patient's brain to their expected shape in healthy individuals. To obtain the required segmentations, we use an automatic method that is contrast-adaptive and robust to missing modalities, making the features generalizable across scanners and imaging protocols. Since the features we propose do not depend on characteristics of the tumor region itself, they are also applicable to post-operative images, which have been much less studied in the context of survival prediction. Using experiments involving both pre- and post-operative data, we show that the proposed features carry prognostic value in terms of overall- and progression-free survival, over and above that of conventional non-imaging features.
UniMS: A Unified Framework for Multimodal Summarization with Knowledge Distillation
Sep 13, 2021
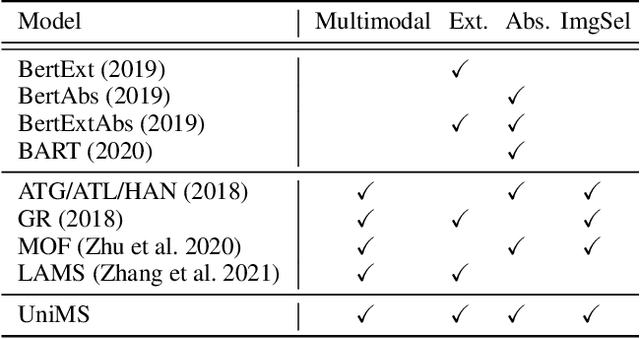
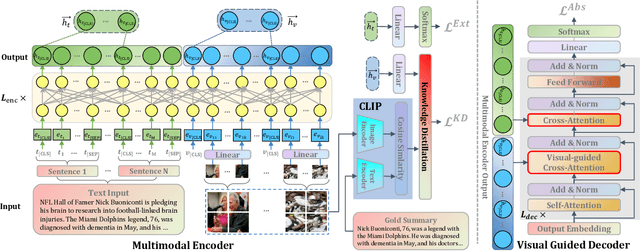
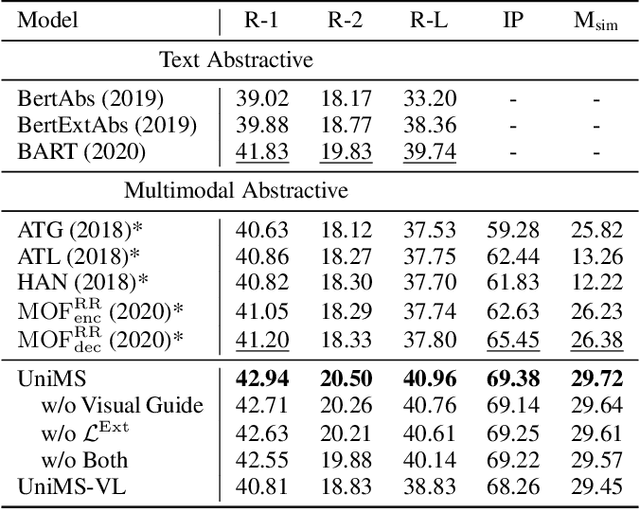
With the rapid increase of multimedia data, a large body of literature has emerged to work on multimodal summarization, the majority of which target at refining salient information from textual and visual modalities to output a pictorial summary with the most relevant images. Existing methods mostly focus on either extractive or abstractive summarization and rely on qualified image captions to build image references. We are the first to propose a Unified framework for Multimodal Summarization grounding on BART, UniMS, that integrates extractive and abstractive objectives, as well as selecting the image output. Specially, we adopt knowledge distillation from a vision-language pretrained model to improve image selection, which avoids any requirement on the existence and quality of image captions. Besides, we introduce a visual guided decoder to better integrate textual and visual modalities in guiding abstractive text generation. Results show that our best model achieves a new state-of-the-art result on a large-scale benchmark dataset. The newly involved extractive objective as well as the knowledge distillation technique are proven to bring a noticeable improvement to the multimodal summarization task.
Robust High-Resolution Video Matting with Temporal Guidance
Aug 25, 2021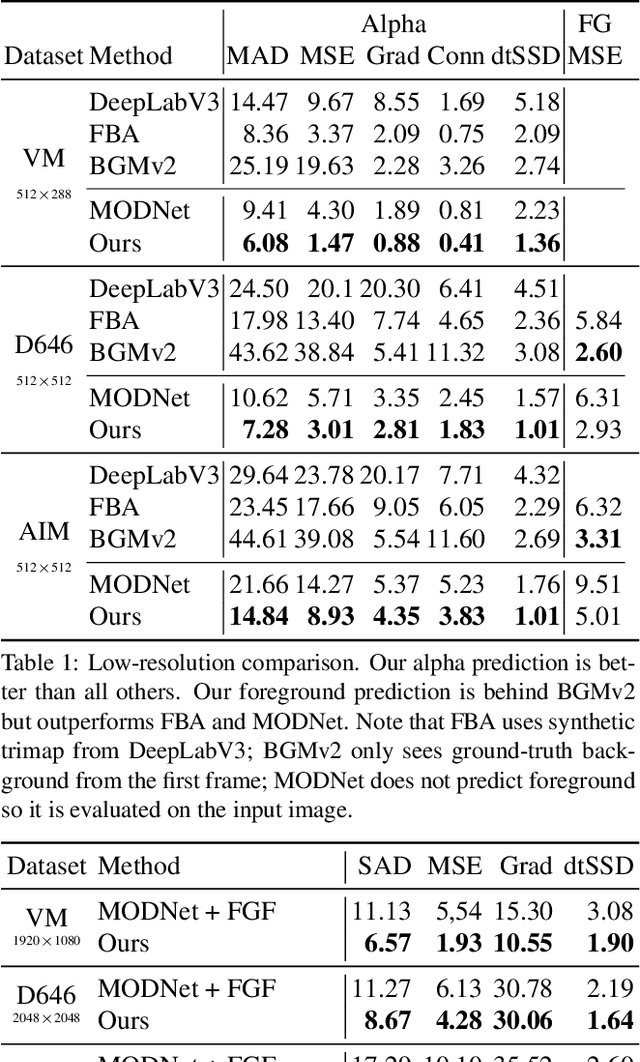
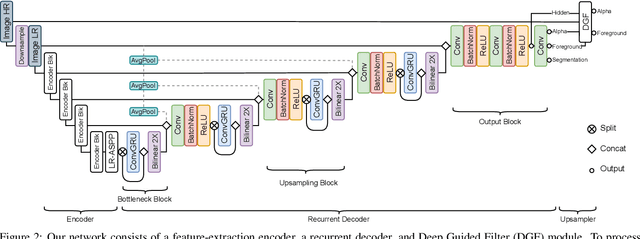
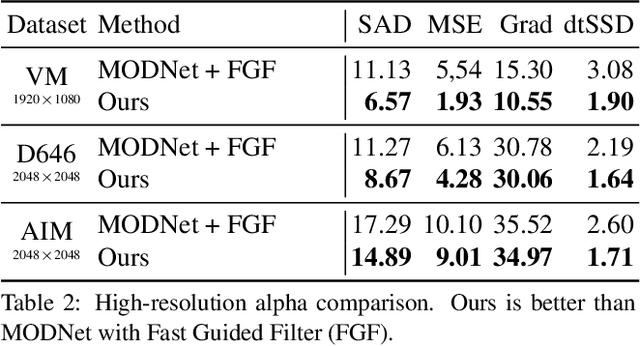
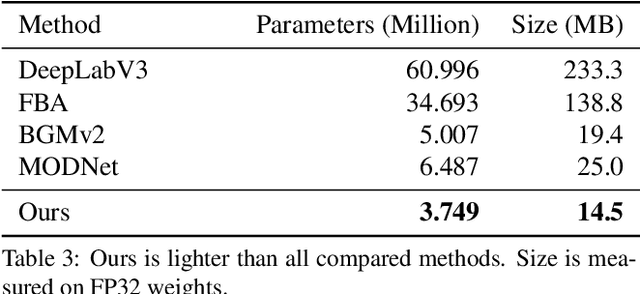
We introduce a robust, real-time, high-resolution human video matting method that achieves new state-of-the-art performance. Our method is much lighter than previous approaches and can process 4K at 76 FPS and HD at 104 FPS on an Nvidia GTX 1080Ti GPU. Unlike most existing methods that perform video matting frame-by-frame as independent images, our method uses a recurrent architecture to exploit temporal information in videos and achieves significant improvements in temporal coherence and matting quality. Furthermore, we propose a novel training strategy that enforces our network on both matting and segmentation objectives. This significantly improves our model's robustness. Our method does not require any auxiliary inputs such as a trimap or a pre-captured background image, so it can be widely applied to existing human matting applications.
Deep Microlocal Reconstruction for Limited-Angle Tomography
Aug 12, 2021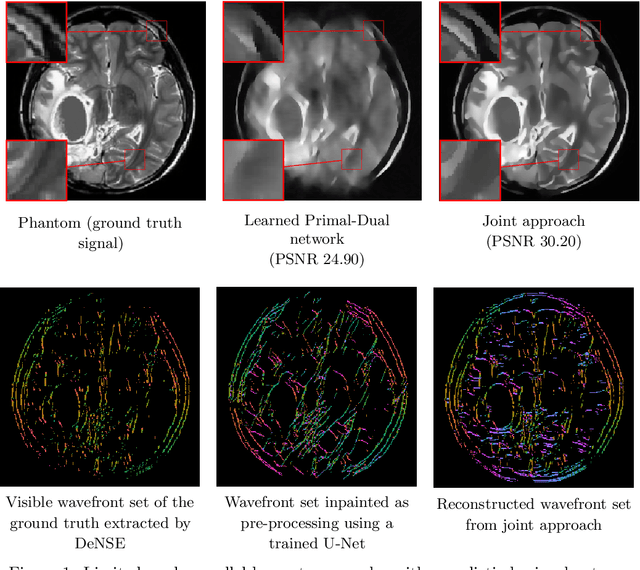
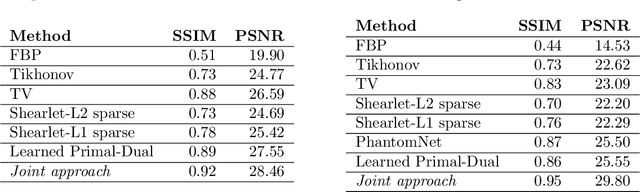

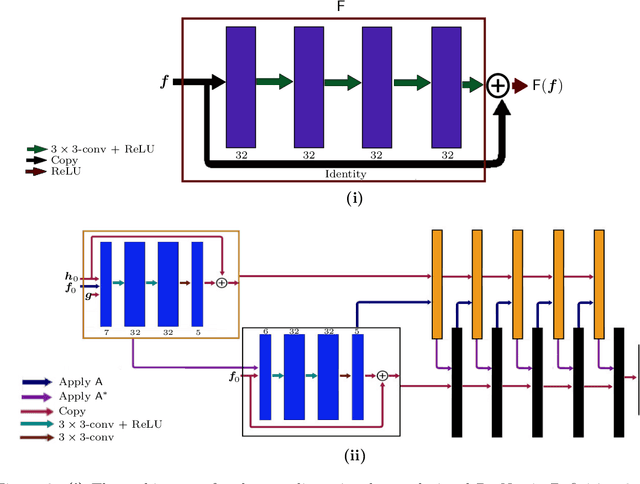
We present a deep learning-based algorithm to jointly solve a reconstruction problem and a wavefront set extraction problem in tomographic imaging. The algorithm is based on a recently developed digital wavefront set extractor as well as the well-known microlocal canonical relation for the Radon transform. We use the wavefront set information about x-ray data to improve the reconstruction by requiring that the underlying neural networks simultaneously extract the correct ground truth wavefront set and ground truth image. As a necessary theoretical step, we identify the digital microlocal canonical relations for deep convolutional residual neural networks. We find strong numerical evidence for the effectiveness of this approach.