 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Power efficient analog features for audio recognition
Oct 07, 2021
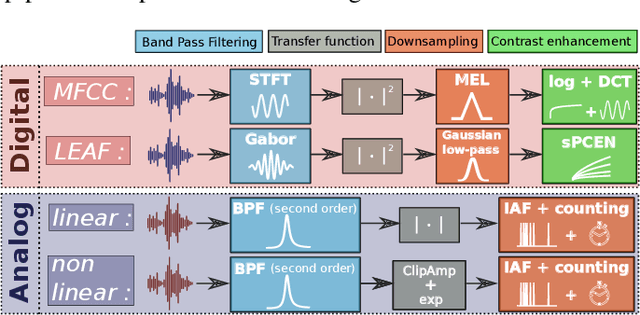
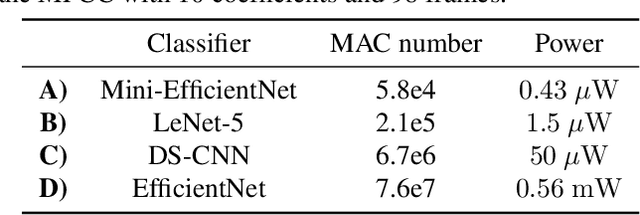
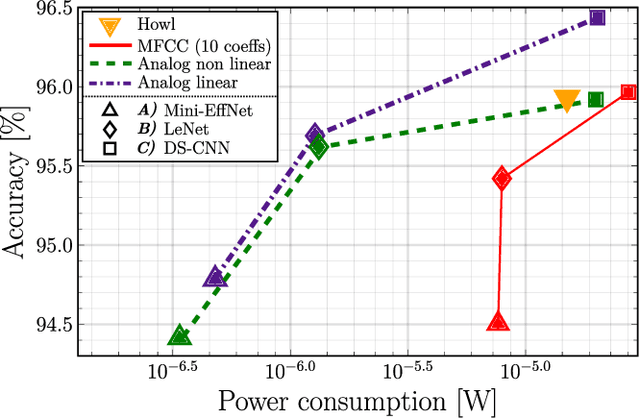
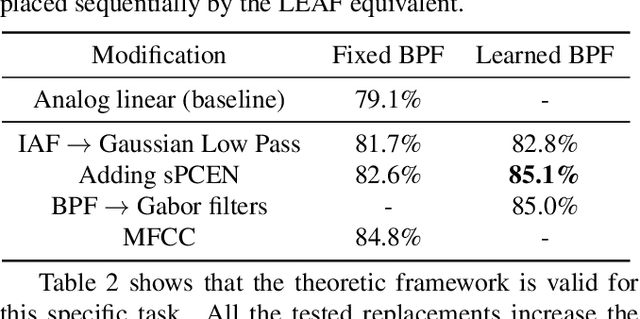
The digital signal processing-based representations like the Mel-Frequency Cepstral Coefficient are well known to be a solid basis for various audio processing tasks. Alternatively, analog feature representations, relying on analog-electronics-feasible bandpass filtering, allow much lower system power consumption compared with the digital counterpart, while parity performance on traditional tasks like voice activity detection can be achieved. This work explores the possibility of using analog features on multiple speech processing tasks that vary in time dependencies: wake word detection, keyword spotting, and speaker identification. The results of this evaluation show that the analog features are still more power-efficient and competitive on simpler tasks than digital features but yield an increasing performance drop on more complex tasks when long-time correlations are present. We also introduce a novel theoretical framework based on information theory to understand this performance drop by quantifying information flow in feature calculation which helps identify the performance bottlenecks. The theoretical claims are experimentally validated, leading to a maximum of 6% increase of keyword spotting accuracy, even surpassing the digital baseline features. The proposed analog-feature-based systems could pave the way to achieving best-in-class accuracy and power consumption simultaneously.
CaSP: Class-agnostic Semi-Supervised Pretraining for Detection and Segmentation
Dec 09, 2021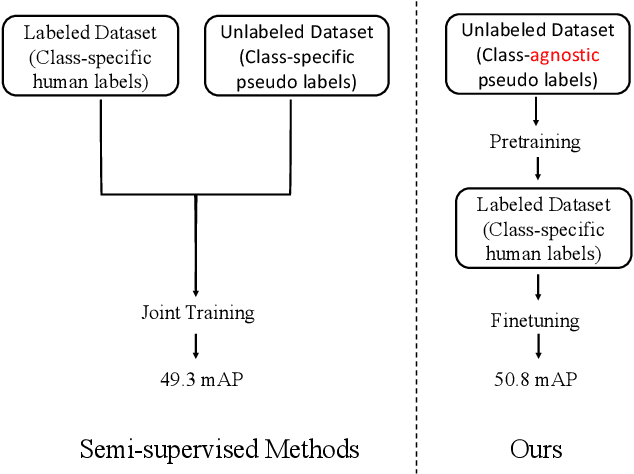
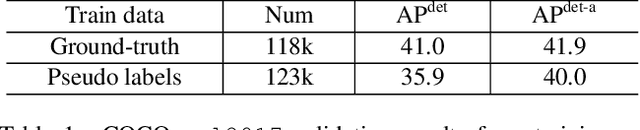
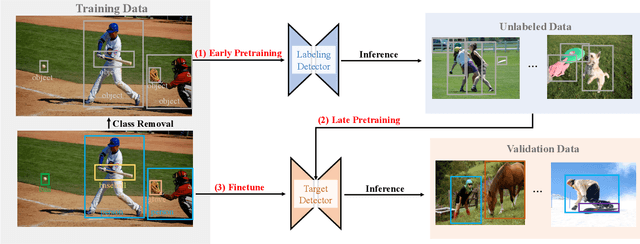
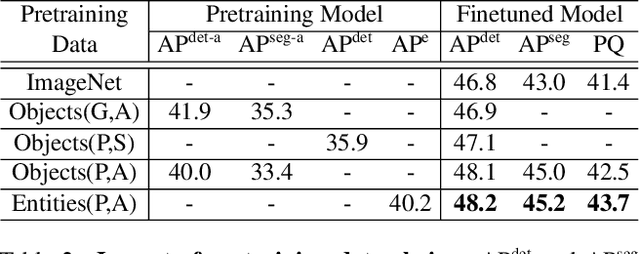
To improve instance-level detection/segmentation performance, existing self-supervised and semi-supervised methods extract either very task-unrelated or very task-specific training signals from unlabeled data. We argue that these two approaches, at the two extreme ends of the task-specificity spectrum, are suboptimal for the task performance. Utilizing too little task-specific training signals causes underfitting to the ground-truth labels of downstream tasks, while the opposite causes overfitting to the ground-truth labels. To this end, we propose a novel Class-agnostic Semi-supervised Pretraining (CaSP) framework to achieve a more favorable task-specificity balance in extracting training signals from unlabeled data. Compared to semi-supervised learning, CaSP reduces the task specificity in training signals by ignoring class information in the pseudo labels and having a separate pretraining stage that uses only task-unrelated unlabeled data. On the other hand, CaSP preserves the right amount of task specificity by leveraging box/mask-level pseudo labels. As a result, our pretrained model can better avoid underfitting/overfitting to ground-truth labels when finetuned on the downstream task. Using 3.6M unlabeled data, we achieve a remarkable performance gain of 4.7% over ImageNet-pretrained baseline on object detection. Our pretrained model also demonstrates excellent transferability to other detection and segmentation tasks/frameworks.
IR-Net: Forward and Backward Information Retention for Highly Accurate Binary Neural Networks
Sep 25, 2019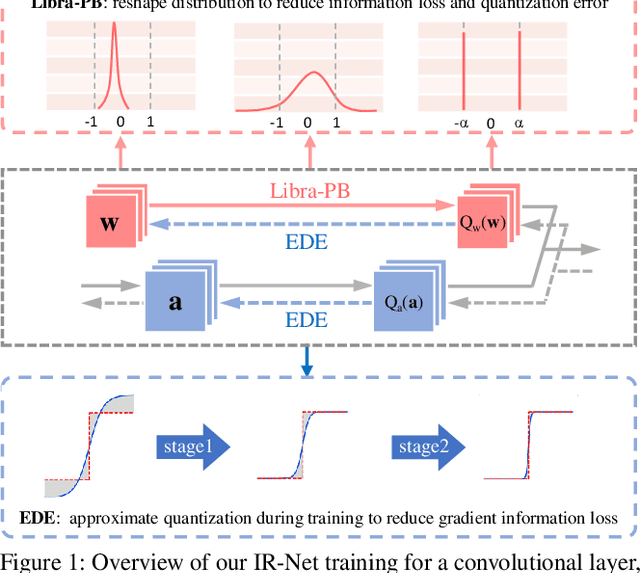

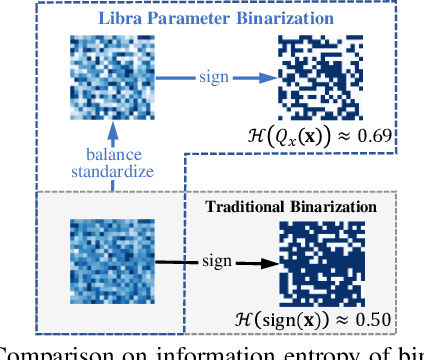
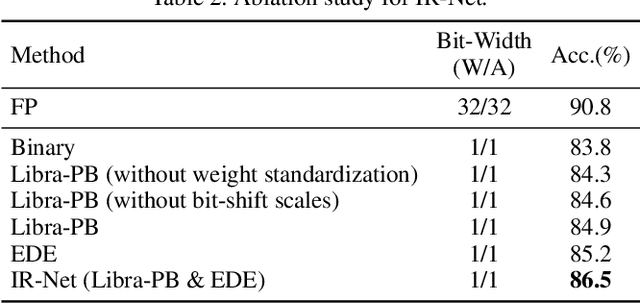
Weight and activation binarization is an effective approach to deep neural network compression and can accelerate the inference by leveraging bitwise operations. Although many binarization methods have improved the accuracy of the model by minimizing the quantization error in forward propagation, there remains a noticeable performance gap between the binarized model and the full-precision one. Our empirical study indicates that the quantization brings information loss in both forward and backward propagation, which is the bottleneck of training highly accurate binary neural networks. To address these issues, we propose an Information Retention Network (IR-Net) to retain the information that consists in the forward activations and backward gradients. IR-Net mainly relies on two technical contributions: (1) Libra Parameter Binarization (Libra-PB): minimize both quantization error and information loss of parameters by balanced and standardized weights in forward propagation; (2) Error Decay Estimator (EDE): minimize the information loss of gradients by gradually approximating the sign function in backward propagation, jointly considering the updating ability and accurate gradients. Comprehensive experiments with various network structures on CIFAR-10 and ImageNet datasets manifest that the proposed IR-Net can consistently outperform state-of-the-art quantization methods.
A Variational U-Net for Weather Forecasting
Nov 05, 2021

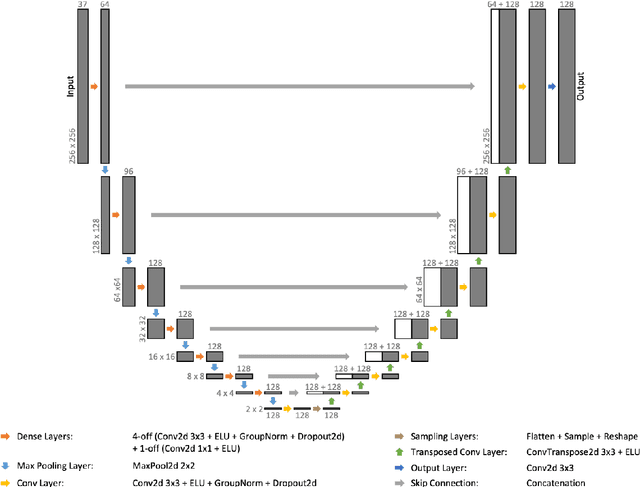

Not only can discovering patterns and insights from atmospheric data enable more accurate weather predictions, but it may also provide valuable information to help tackle climate change. Weather4cast is an open competition that aims to evaluate machine learning algorithms' capability to predict future atmospheric states. Here, we describe our third-place solution to Weather4cast. We present a novel Variational U-Net that combines a Variational Autoencoder's ability to consider the probabilistic nature of data with a U-Net's ability to recover fine-grained details. This solution is an evolution from our fourth-place solution to Traffic4cast 2020 with many commonalities, suggesting its applicability to vastly different domains, such as weather and traffic.
SphereSR: 360° Image Super-Resolution with Arbitrary Projection via Continuous Spherical Image Representation
Dec 14, 2021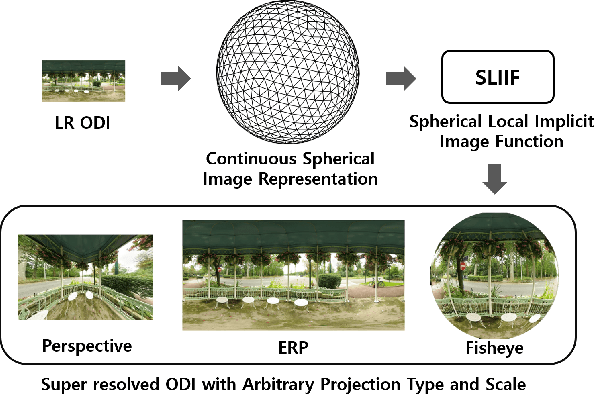
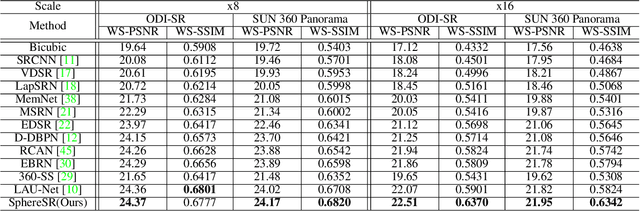
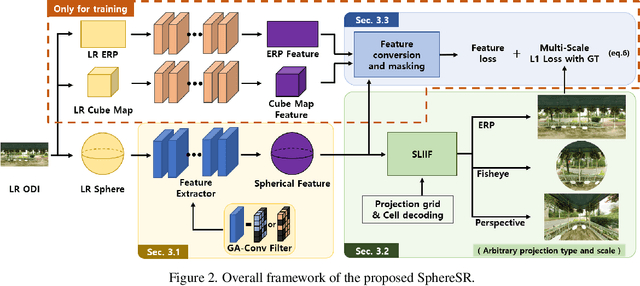
The 360{\deg}imaging has recently gained great attention; however, its angular resolution is relatively lower than that of a narrow field-of-view (FOV) perspective image as it is captured by using fisheye lenses with the same sensor size. Therefore, it is beneficial to super-resolve a 360{\deg}image. Some attempts have been made but mostly considered the equirectangular projection (ERP) as one of the way for 360{\deg}image representation despite of latitude-dependent distortions. In that case, as the output high-resolution(HR) image is always in the same ERP format as the low-resolution (LR) input, another information loss may occur when transforming the HR image to other projection types. In this paper, we propose SphereSR, a novel framework to generate a continuous spherical image representation from an LR 360{\deg}image, aiming at predicting the RGB values at given spherical coordinates for super-resolution with an arbitrary 360{\deg}image projection. Specifically, we first propose a feature extraction module that represents the spherical data based on icosahedron and efficiently extracts features on the spherical surface. We then propose a spherical local implicit image function (SLIIF) to predict RGB values at the spherical coordinates. As such, SphereSR flexibly reconstructs an HR image under an arbitrary projection type. Experiments on various benchmark datasets show that our method significantly surpasses existing methods.
Progressive Graph Convolution Network for EEG Emotion Recognition
Dec 14, 2021
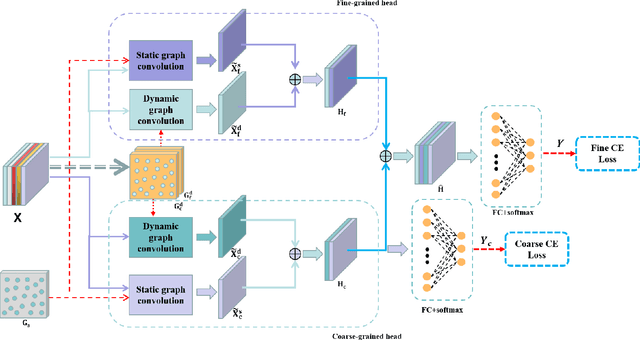
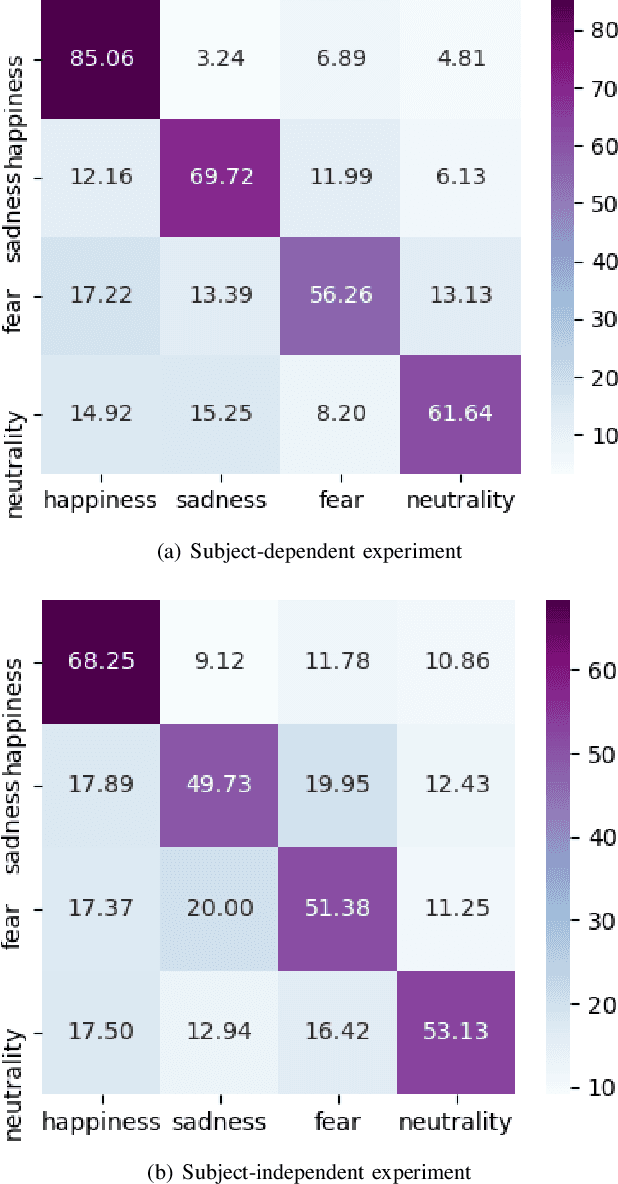
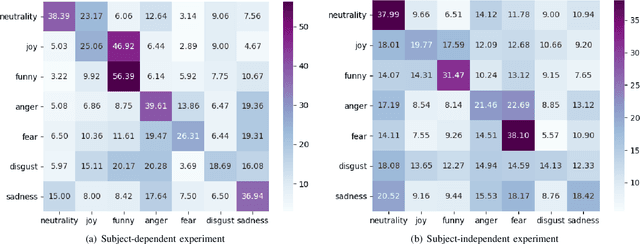
Studies in the area of neuroscience have revealed the relationship between emotional patterns and brain functional regions, demonstrating that dynamic relationships between different brain regions are an essential factor affecting emotion recognition determined through electroencephalography (EEG). Moreover, in EEG emotion recognition, we can observe that clearer boundaries exist between coarse-grained emotions than those between fine-grained emotions, based on the same EEG data; this indicates the concurrence of large coarse- and small fine-grained emotion variations. Thus, the progressive classification process from coarse- to fine-grained categories may be helpful for EEG emotion recognition. Consequently, in this study, we propose a progressive graph convolution network (PGCN) for capturing this inherent characteristic in EEG emotional signals and progressively learning the discriminative EEG features. To fit different EEG patterns, we constructed a dual-graph module to characterize the intrinsic relationship between different EEG channels, containing the dynamic functional connections and static spatial proximity information of brain regions from neuroscience research. Moreover, motivated by the observation of the relationship between coarse- and fine-grained emotions, we adopt a dual-head module that enables the PGCN to progressively learn more discriminative EEG features, from coarse-grained (easy) to fine-grained categories (difficult), referring to the hierarchical characteristic of emotion. To verify the performance of our model, extensive experiments were conducted on two public datasets: SEED-IV and multi-modal physiological emotion database (MPED).
Multimodal Fake News Detection
Dec 09, 2021
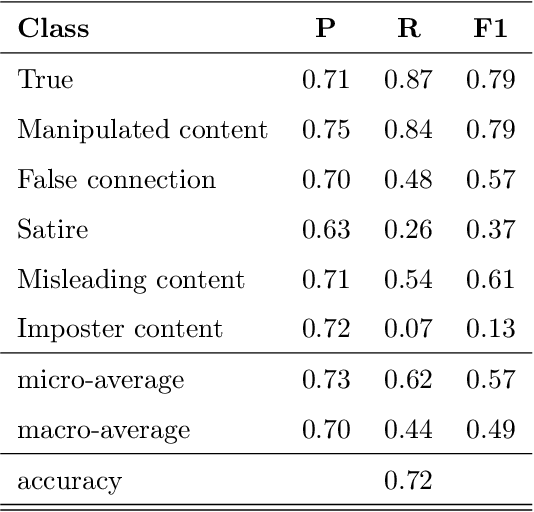
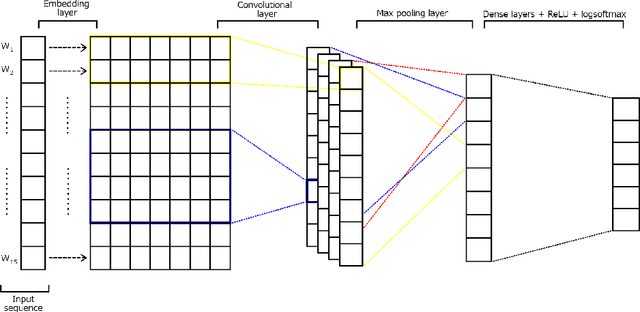
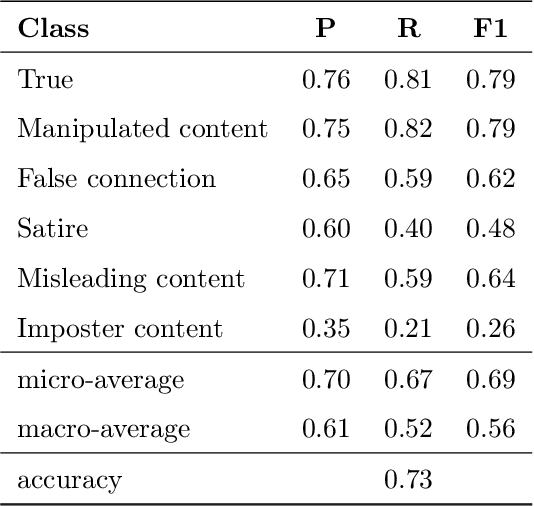
Over the last years, there has been an unprecedented proliferation of fake news. As a consequence, we are more susceptible to the pernicious impact that misinformation and disinformation spreading can have in different segments of our society. Thus, the development of tools for automatic detection of fake news plays and important role in the prevention of its negative effects. Most attempts to detect and classify false content focus only on using textual information. Multimodal approaches are less frequent and they typically classify news either as true or fake. In this work, we perform a fine-grained classification of fake news on the Fakeddit dataset, using both unimodal and multimodal approaches. Our experiments show that the multimodal approach based on a Convolutional Neural Network (CNN) architecture combining text and image data achieves the best results, with an accuracy of 87%. Some fake news categories such as Manipulated content, Satire or False connection strongly benefit from the use of images. Using images also improves the results of the other categories, but with less impact. Regarding the unimodal approaches using only text, Bidirectional Encoder Representations from Transformers (BERT) is the best model with an accuracy of 78%. Therefore, exploiting both text and image data significantly improves the performance of fake news detection.
Efficient Context-Aware Network for Abdominal Multi-organ Segmentation
Sep 22, 2021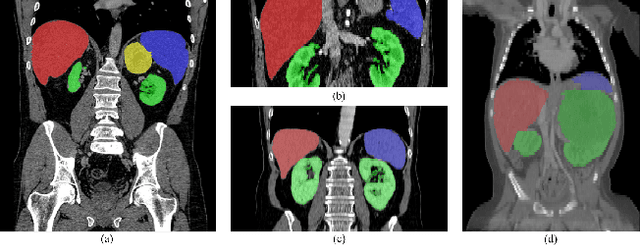
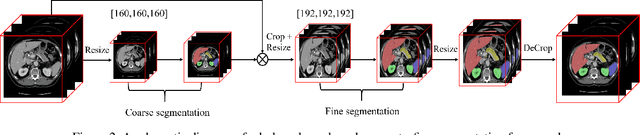
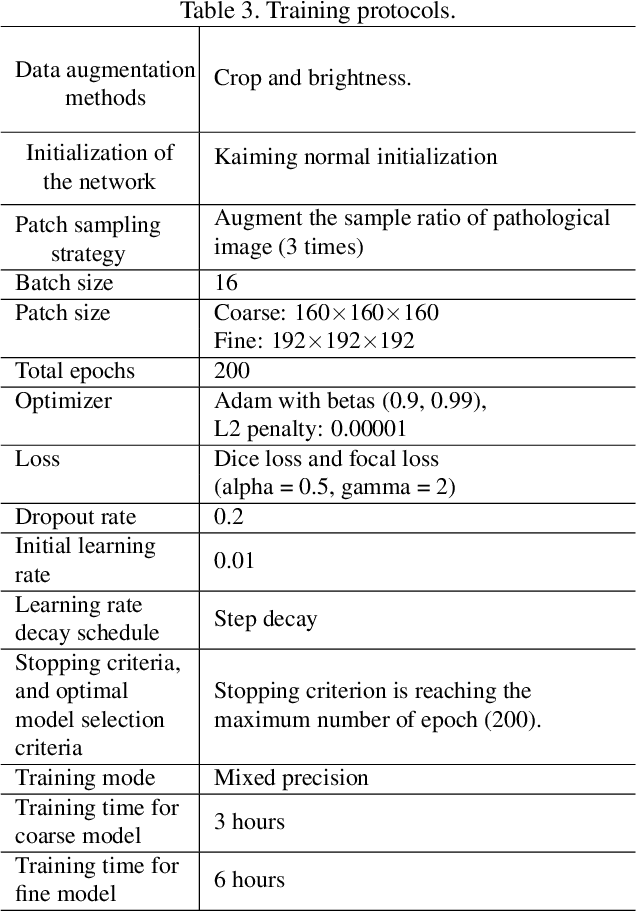
The contextual information, presented in abdominal CT scan, is relative consistent. In order to make full use of the overall 3D context, we develop a whole-volumebased coarse-to-fine framework for efficient and effective abdominal multi-organ segmentation. We propose a new efficientSegNet network, which is composed of encoder, decoder and context block. For the decoder module, anisotropic convolution with a k*k*1 intra-slice convolution and a 1*1*k inter-slice convolution, is designed to reduce the computation burden. For the context block, we propose strip pooling module to capture anisotropic and long-range contextual information, which exists in abdominal scene. Quantitative evaluation on the FLARE2021 validation cases, this method achieves the average dice similarity coefficient (DSC) of 0.895 and average normalized surface distance (NSD) of 0.775. The average running time is 9.8 s per case in inference phase, and maximum used GPU memory is 1017 MB.
NeurSF: Neural Shading Field for Image Harmonization
Dec 04, 2021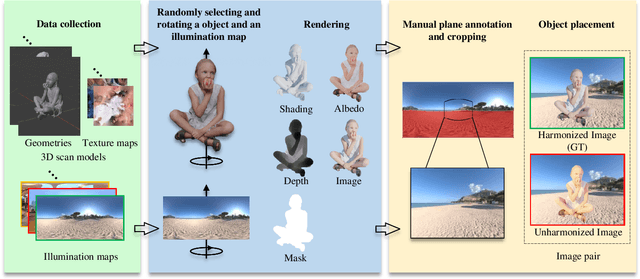

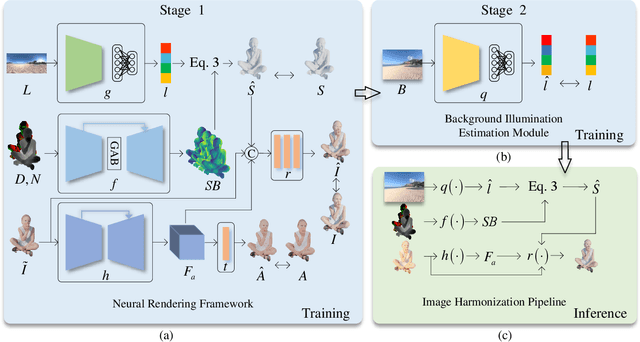
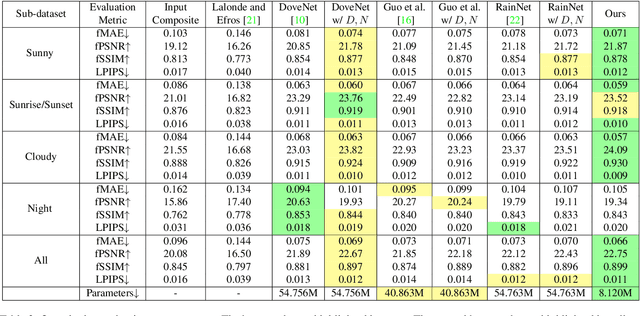
Image harmonization aims at adjusting the appearance of the foreground to make it more compatible with the background. Due to a lack of understanding of the background illumination direction, existing works are incapable of generating a realistic foreground shading. In this paper, we decompose the image harmonization into two sub-problems: 1) illumination estimation of background images and 2) rendering of foreground objects. Before solving these two sub-problems, we first learn a direction-aware illumination descriptor via a neural rendering framework, of which the key is a Shading Module that decomposes the shading field into multiple shading components given depth information. Then we design a Background Illumination Estimation Module to extract the direction-aware illumination descriptor from the background. Finally, the illumination descriptor is used in conjunction with the neural rendering framework to generate the harmonized foreground image containing a novel harmonized shading. Moreover, we construct a photo-realistic synthetic image harmonization dataset that contains numerous shading variations by image-based lighting. Extensive experiments on this dataset demonstrate the effectiveness of the proposed method. Our dataset and code will be made publicly available.
Hierarchical Topometric Representation of 3D Robotic Maps
Nov 16, 2021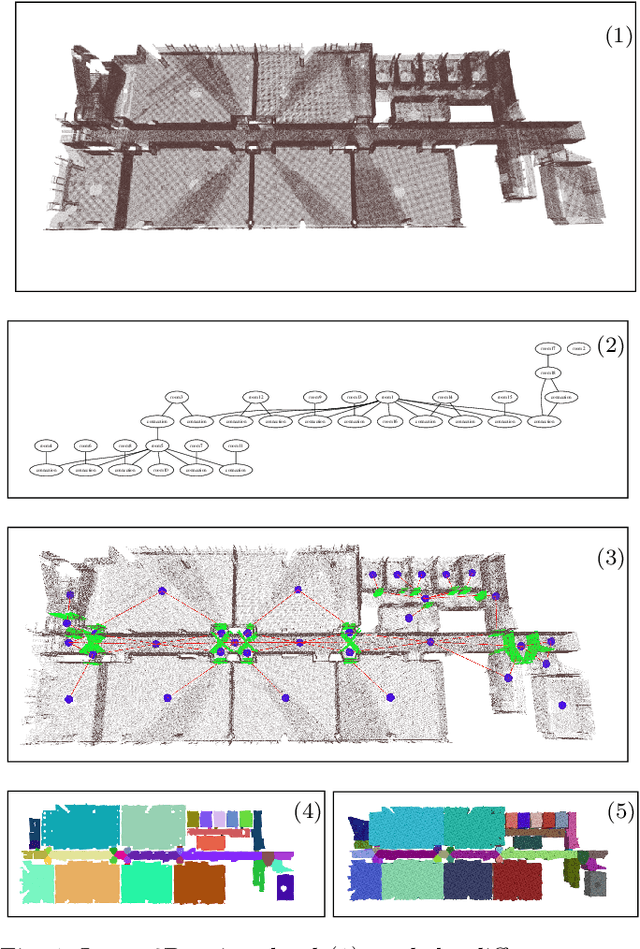

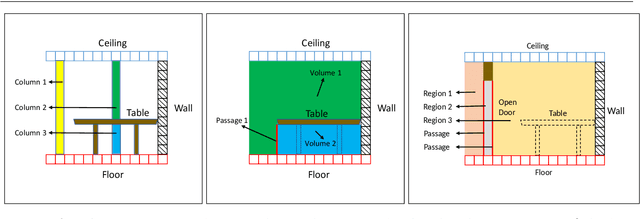
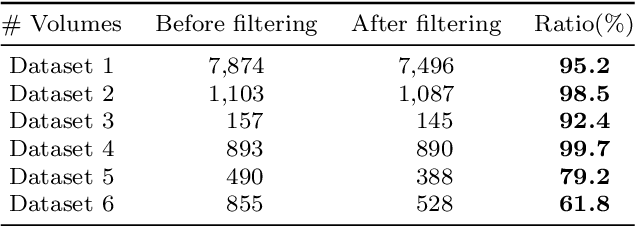
In this paper, we propose a method for generating a hierarchical, volumetric topological map from 3D point clouds. There are three basic hierarchical levels in our map: $storey - region - volume$. The advantages of our method are reflected in both input and output. In terms of input, we accept multi-storey point clouds and building structures with sloping roofs or ceilings. In terms of output, we can generate results with metric information of different dimensionality, that are suitable for different robotics applications. The algorithm generates the volumetric representation by generating $volumes$ from a 3D voxel occupancy map. We then add $passage$s (connections between $volumes$), combine small $volumes$ into a big $region$ and use a 2D segmentation method for better topological representation. We evaluate our method on several freely available datasets. The experiments highlight the advantages of our approach.
* Temporarily