 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Agentic Tool-Calling Decisions via Uncertainty-Aligned Reinforcement Learning
Jun 05, 2026Large language model (LLM)-based agents often make suboptimal tool-use decisions, including unsupported tool invocation and hallucinated direct responses, which may accumulate errors throughout multi-step interactions. Existing approaches mainly improve these behaviors through inference-time correction or coarse-grained reward signals based on decision outcomes and structured checklists, leaving the uncertainty characteristics of agent decisions underexplored. We observe that decision-oriented reinforcement learning tends to weaken the uncertainty separation between correct and incorrect actions, resulting in overconfident mistakes and weaker exploration signals. Therefore, we propose TRUST, which incorporates uncertainty quantification into reward design as a repulsive force for maintaining uncertainty separation, and labels lightweight key-turn annotations for unified post-training of multi-turn trajectories. Experimental results across diverse tool-use benchmarks show that TRUST consistently enhances both decision quality and agent performance while maintaining more reliable uncertainty estimates during optimization.
HomeGuard: VLM-based Embodied Safeguard for Identifying Contextual Risk in Household Task
Mar 15, 2026Vision-Language Models (VLMs) empower embodied agents to execute complex instructions, yet they remain vulnerable to contextual safety risks where benign commands become hazardous due to subtle environmental states. Existing safeguards often prove inadequate. Rule-based methods lack scalability in object-dense scenes, whereas model-based approaches relying on prompt engineering suffer from unfocused perception, resulting in missed risks or hallucinations. To address this, we propose an architecture-agnostic safeguard featuring Context-Guided Chain-of-Thought (CG-CoT). This mechanism decomposes risk assessment into active perception that sequentially anchors attention to interaction targets and relevant spatial neighborhoods, followed by semantic judgment based on this visual evidence. We support this approach with a curated grounding dataset and a two-stage training strategy utilizing Reinforcement Fine-Tuning (RFT) with process rewards to enforce precise intermediate grounding. Experiments demonstrate that our model HomeGuard significantly enhances safety, improving risk match rates by over 30% compared to base models while reducing oversafety. Beyond hazard detection, the generated visual anchors serve as actionable spatial constraints for downstream planners, facilitating explicit collision avoidance and safety trajectory generation. Code and data are released under https://github.com/AI45Lab/HomeGuard
DeepSight: An All-in-One LM Safety Toolkit
Feb 12, 2026As the development of Large Models (LMs) progresses rapidly, their safety is also a priority. In current Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) safety workflow, evaluation, diagnosis, and alignment are often handled by separate tools. Specifically, safety evaluation can only locate external behavioral risks but cannot figure out internal root causes. Meanwhile, safety diagnosis often drifts from concrete risk scenarios and remains at the explainable level. In this way, safety alignment lack dedicated explanations of changes in internal mechanisms, potentially degrading general capabilities. To systematically address these issues, we propose an open-source project, namely DeepSight, to practice a new safety evaluation-diagnosis integrated paradigm. DeepSight is low-cost, reproducible, efficient, and highly scalable large-scale model safety evaluation project consisting of a evaluation toolkit DeepSafe and a diagnosis toolkit DeepScan. By unifying task and data protocols, we build a connection between the two stages and transform safety evaluation from black-box to white-box insight. Besides, DeepSight is the first open source toolkit that support the frontier AI risk evaluation and joint safety evaluation and diagnosis.
INFA-Guard: Mitigating Malicious Propagation via Infection-Aware Safeguarding in LLM-Based Multi-Agent Systems
Jan 21, 2026The rapid advancement of Large Language Model (LLM)-based Multi-Agent Systems (MAS) has introduced significant security vulnerabilities, where malicious influence can propagate virally through inter-agent communication. Conventional safeguards often rely on a binary paradigm that strictly distinguishes between benign and attack agents, failing to account for infected agents i.e., benign entities converted by attack agents. In this paper, we propose Infection-Aware Guard, INFA-Guard, a novel defense framework that explicitly identifies and addresses infected agents as a distinct threat category. By leveraging infection-aware detection and topological constraints, INFA-Guard accurately localizes attack sources and infected ranges. During remediation, INFA-Guard replaces attackers and rehabilitates infected ones, avoiding malicious propagation while preserving topological integrity. Extensive experiments demonstrate that INFA-Guard achieves state-of-the-art performance, reducing the Attack Success Rate (ASR) by an average of 33%, while exhibiting cross-model robustness, superior topological generalization, and high cost-effectiveness.
GROD: Enhancing Generalization of Transformer with Out-of-Distribution Detection
Jun 13, 2024



Transformer networks excel in natural language processing (NLP) and computer vision (CV) tasks. However, they face challenges in generalizing to Out-of-Distribution (OOD) datasets, that is, data whose distribution differs from that seen during training. The OOD detection aims to distinguish data that deviates from the expected distribution, while maintaining optimal performance on in-distribution (ID) data. This paper introduces a novel approach based on OOD detection, termed the Generate Rounded OOD Data (GROD) algorithm, which significantly bolsters the generalization performance of transformer networks across various tasks. GROD is motivated by our new OOD detection Probably Approximately Correct (PAC) Theory for transformer. The transformer has learnability in terms of OOD detection that is, when the data is sufficient the outlier can be well represented. By penalizing the misclassification of OOD data within the loss function and generating synthetic outliers, GROD guarantees learnability and refines the decision boundaries between inlier and outlier. This strategy demonstrates robust adaptability and general applicability across different data types. Evaluated across diverse OOD detection tasks in NLP and CV, GROD achieves SOTA regardless of data format. On average, it reduces the SOTA FPR@95 from 21.97% to 0.12%, and improves AUROC from 93.62% to 99.98% on image classification tasks, and the SOTA FPR@95 by 12.89% and AUROC by 2.27% in detecting semantic text outliers. The code is available at https://anonymous.4open.science/r/GROD-OOD-Detection-with-transformers-B70F.
EEG-based Emotion Style Transfer Network for Cross-dataset Emotion Recognition
Aug 09, 2023



As the key to realizing aBCIs, EEG emotion recognition has been widely studied by many researchers. Previous methods have performed well for intra-subject EEG emotion recognition. However, the style mismatch between source domain (training data) and target domain (test data) EEG samples caused by huge inter-domain differences is still a critical problem for EEG emotion recognition. To solve the problem of cross-dataset EEG emotion recognition, in this paper, we propose an EEG-based Emotion Style Transfer Network (E2STN) to obtain EEG representations that contain the content information of source domain and the style information of target domain, which is called stylized emotional EEG representations. The representations are helpful for cross-dataset discriminative prediction. Concretely, E2STN consists of three modules, i.e., transfer module, transfer evaluation module, and discriminative prediction module. The transfer module encodes the domain-specific information of source and target domains and then re-constructs the source domain's emotional pattern and the target domain's statistical characteristics into the new stylized EEG representations. In this process, the transfer evaluation module is adopted to constrain the generated representations that can more precisely fuse two kinds of complementary information from source and target domains and avoid distorting. Finally, the generated stylized EEG representations are fed into the discriminative prediction module for final classification. Extensive experiments show that the E2STN can achieve the state-of-the-art performance on cross-dataset EEG emotion recognition tasks.
Progressive Graph Convolution Network for EEG Emotion Recognition
Dec 14, 2021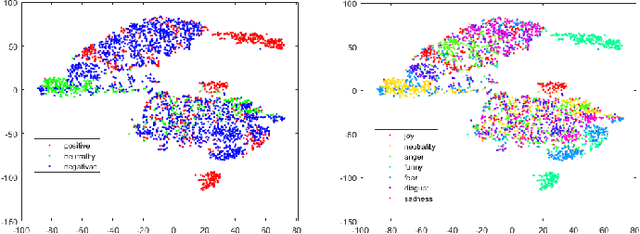
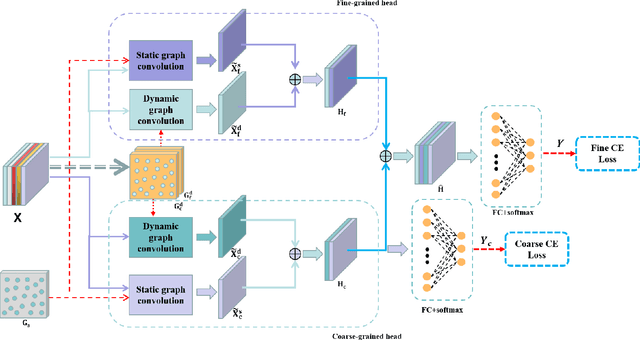
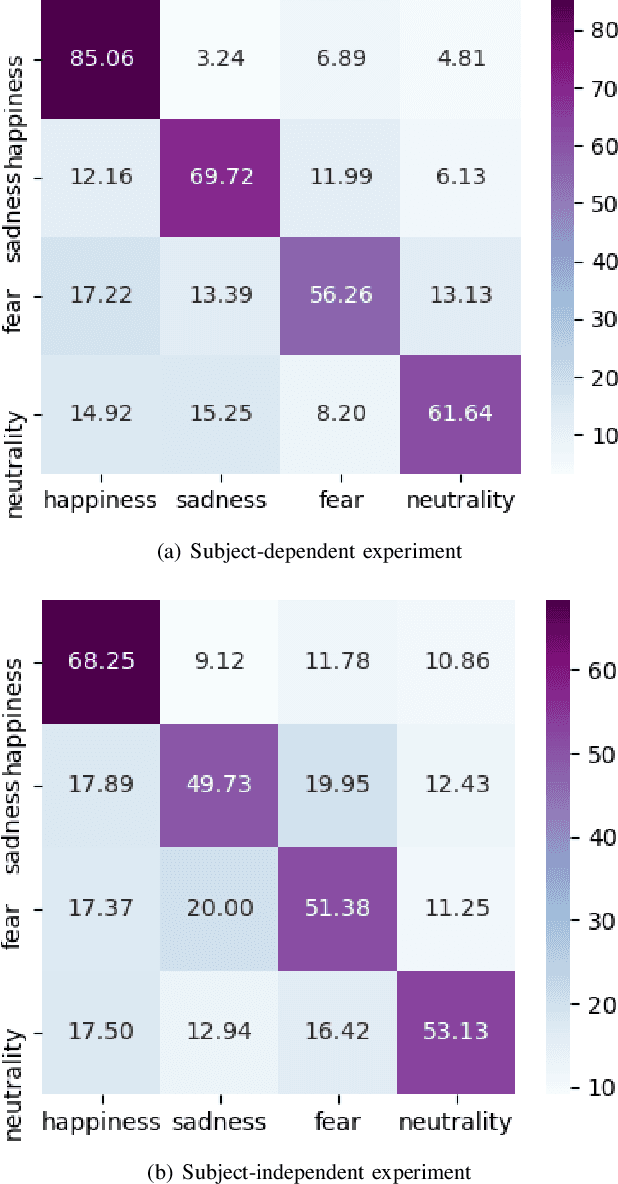
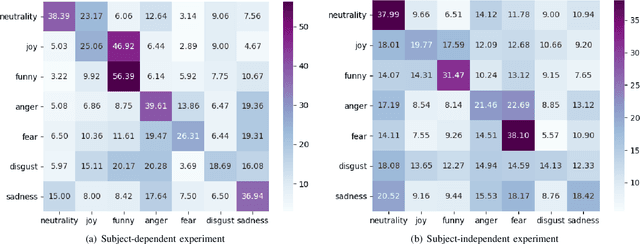
Studies in the area of neuroscience have revealed the relationship between emotional patterns and brain functional regions, demonstrating that dynamic relationships between different brain regions are an essential factor affecting emotion recognition determined through electroencephalography (EEG). Moreover, in EEG emotion recognition, we can observe that clearer boundaries exist between coarse-grained emotions than those between fine-grained emotions, based on the same EEG data; this indicates the concurrence of large coarse- and small fine-grained emotion variations. Thus, the progressive classification process from coarse- to fine-grained categories may be helpful for EEG emotion recognition. Consequently, in this study, we propose a progressive graph convolution network (PGCN) for capturing this inherent characteristic in EEG emotional signals and progressively learning the discriminative EEG features. To fit different EEG patterns, we constructed a dual-graph module to characterize the intrinsic relationship between different EEG channels, containing the dynamic functional connections and static spatial proximity information of brain regions from neuroscience research. Moreover, motivated by the observation of the relationship between coarse- and fine-grained emotions, we adopt a dual-head module that enables the PGCN to progressively learn more discriminative EEG features, from coarse-grained (easy) to fine-grained categories (difficult), referring to the hierarchical characteristic of emotion. To verify the performance of our model, extensive experiments were conducted on two public datasets: SEED-IV and multi-modal physiological emotion database (MPED).