 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-generated Text Detection with a GLTR-based Approach
Feb 17, 2025The rise of LLMs (Large Language Models) has contributed to the improved performance and development of cutting-edge NLP applications. However, these can also pose risks when used maliciously, such as spreading fake news, harmful content, impersonating individuals, or facilitating school plagiarism, among others. This is because LLMs can generate high-quality texts, which are challenging to differentiate from those written by humans. GLTR, which stands for Giant Language Model Test Room and was developed jointly by the MIT-IBM Watson AI Lab and HarvardNLP, is a visual tool designed to help detect machine-generated texts based on GPT-2, that highlights the words in text depending on the probability that they were machine-generated. One limitation of GLTR is that the results it returns can sometimes be ambiguous and lead to confusion. This study aims to explore various ways to improve GLTR's effectiveness for detecting AI-generated texts within the context of the IberLef-AuTexTification 2023 shared task, in both English and Spanish languages. Experiment results show that our GLTR-based GPT-2 model overcomes the state-of-the-art models on the English dataset with a macro F1-score of 80.19%, except for the first ranking model (80.91%). However, for the Spanish dataset, we obtained a macro F1-score of 66.20%, which differs by 4.57% compared to the top-performing model.
A Framework for Identifying Depression on Social Media: MentalRiskES@IberLEF 2023
Jun 29, 2023This paper describes our participation in the MentalRiskES task at IberLEF 2023. The task involved predicting the likelihood of an individual experiencing depression based on their social media activity. The dataset consisted of conversations from 175 Telegram users, each labeled according to their evidence of suffering from the disorder. We used a combination of traditional machine learning and deep learning techniques to solve four predictive subtasks: binary classification, simple regression, multiclass classification, and multi-output regression. We approached this by training a model to solve the multi-output regression case and then transforming the predictions to work for the other three subtasks. We compare the performance of two modeling approaches: fine-tuning a BERT-based model directly for the task or using its embeddings as inputs to a linear regressor, with the latter yielding better results. The code to reproduce our results can be found at: https://github.com/simonsanvil/EarlyDepression-MentalRiskES
HULAT at SemEval-2023 Task 10: Data augmentation for pre-trained transformers applied to the detection of sexism in social media
Mar 01, 2023This paper describes our participation in SemEval-2023 Task 10, whose goal is the detection of sexism in social media. We explore some of the most popular transformer models such as BERT, DistilBERT, RoBERTa, and XLNet. We also study different data augmentation techniques to increase the training dataset. During the development phase, our best results were obtained by using RoBERTa and data augmentation for tasks B and C. However, the use of synthetic data does not improve the results for task C. We participated in the three subtasks. Our approach still has much room for improvement, especially in the two fine-grained classifications. All our code is available in the repository https://github.com/isegura/hulat_edos.
HULAT at SemEval-2023 Task 9: Data augmentation for pre-trained transformers applied to Multilingual Tweet Intimacy Analysis
Feb 24, 2023This paper describes our participation in SemEval-2023 Task 9, Intimacy Analysis of Multilingual Tweets. We fine-tune some of the most popular transformer models with the training dataset and synthetic data generated by different data augmentation techniques. During the development phase, our best results were obtained by using XLM-T. Data augmentation techniques provide a very slight improvement in the results. Our system ranked in the 27th position out of the 45 participating systems. Despite its modest results, our system shows promising results in languages such as Portuguese, English, and Dutch. All our code is available in the repository \url{https://github.com/isegura/hulat_intimacy}.
Multimodal Fake News Detection
Dec 09, 2021
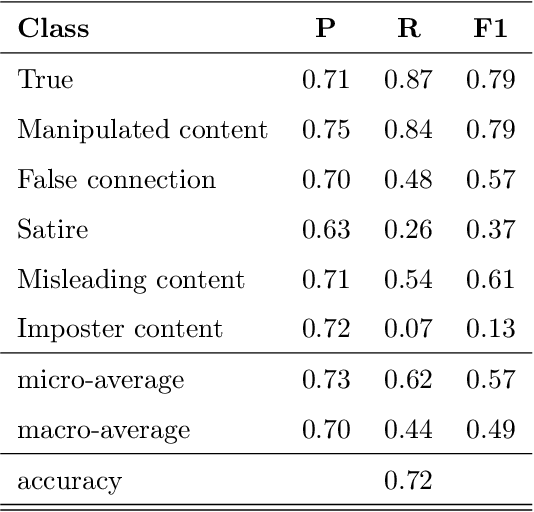
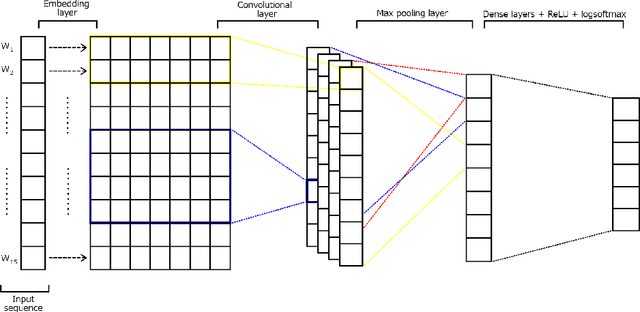
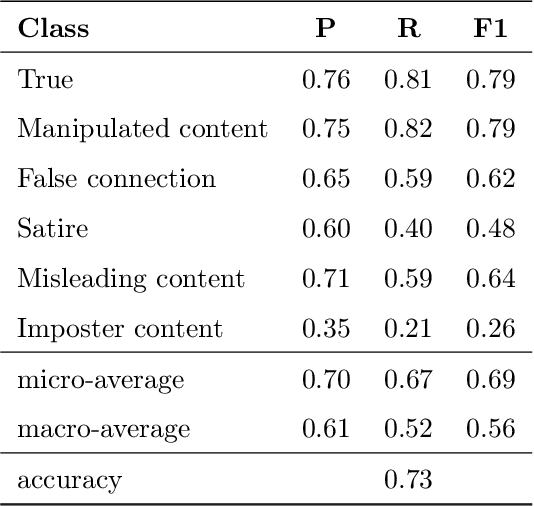
Over the last years, there has been an unprecedented proliferation of fake news. As a consequence, we are more susceptible to the pernicious impact that misinformation and disinformation spreading can have in different segments of our society. Thus, the development of tools for automatic detection of fake news plays and important role in the prevention of its negative effects. Most attempts to detect and classify false content focus only on using textual information. Multimodal approaches are less frequent and they typically classify news either as true or fake. In this work, we perform a fine-grained classification of fake news on the Fakeddit dataset, using both unimodal and multimodal approaches. Our experiments show that the multimodal approach based on a Convolutional Neural Network (CNN) architecture combining text and image data achieves the best results, with an accuracy of 87%. Some fake news categories such as Manipulated content, Satire or False connection strongly benefit from the use of images. Using images also improves the results of the other categories, but with less impact. Regarding the unimodal approaches using only text, Bidirectional Encoder Representations from Transformers (BERT) is the best model with an accuracy of 78%. Therefore, exploiting both text and image data significantly improves the performance of fake news detection.
Exploring deep learning methods for recognizing rare diseases and their clinical manifestations from texts
Sep 01, 2021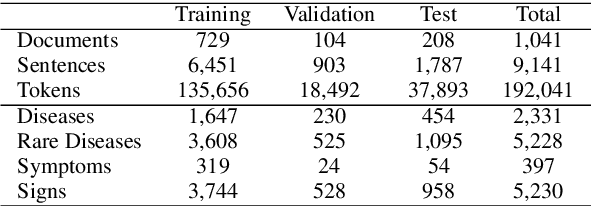
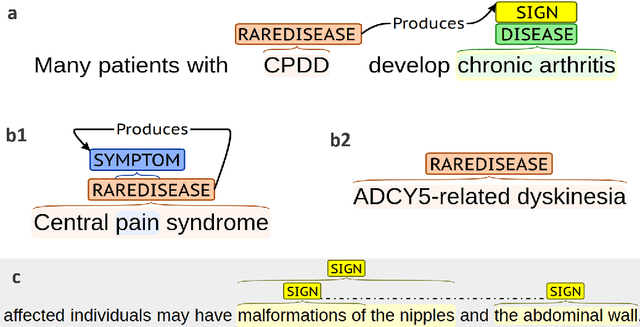
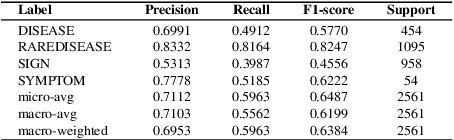
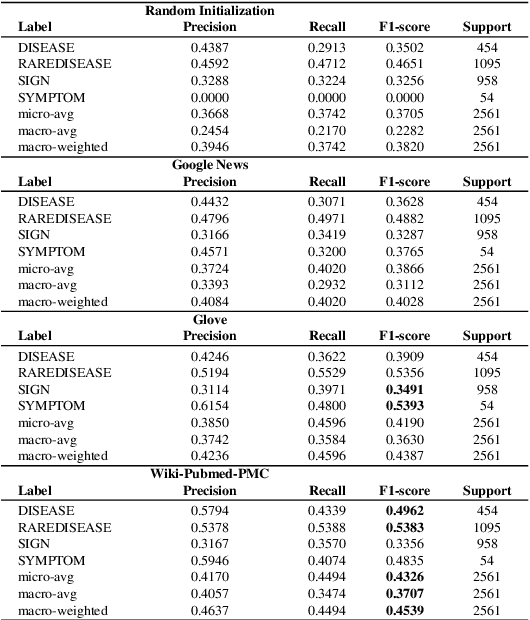
Although rare diseases are characterized by low prevalence, approximately 300 million people are affected by a rare disease. The early and accurate diagnosis of these conditions is a major challenge for general practitioners, who do not have enough knowledge to identify them. In addition to this, rare diseases usually show a wide variety of manifestations, which might make the diagnosis even more difficult. A delayed diagnosis can negatively affect the patient's life. Therefore, there is an urgent need to increase the scientific and medical knowledge about rare diseases. Natural Language Processing (NLP) and Deep Learning can help to extract relevant information about rare diseases to facilitate their diagnosis and treatments. The paper explores the use of several deep learning techniques such as Bidirectional Long Short Term Memory (BiLSTM) networks or deep contextualized word representations based on Bidirectional Encoder Representations from Transformers (BERT) to recognize rare diseases and their clinical manifestations (signs and symptoms) in the RareDis corpus. This corpus contains more than 5,000 rare diseases and almost 6,000 clinical manifestations. BioBERT, a domain-specific language representation based on BERT and trained on biomedical corpora, obtains the best results. In particular, this model obtains an F1-score of 85.2% for rare diseases, outperforming all the other models.
The RareDis corpus: a corpus annotated with rare diseases, their signs and symptoms
Aug 02, 2021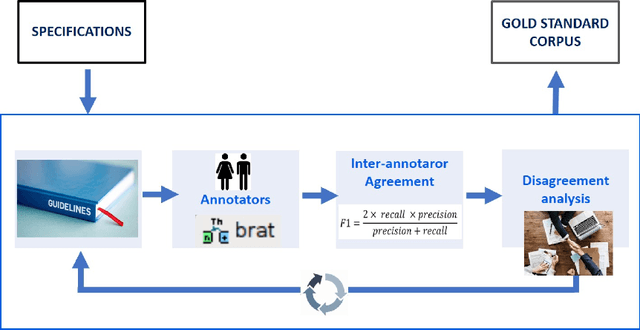



The RareDis corpus contains more than 5,000 rare diseases and almost 6,000 clinical manifestations are annotated. Moreover, the Inter Annotator Agreement evaluation shows a relatively high agreement (F1-measure equal to 83.5% under exact match criteria for the entities and equal to 81.3% for the relations). Based on these results, this corpus is of high quality, supposing a significant step for the field since there is a scarcity of available corpus annotated with rare diseases. This could open the door to further NLP applications, which would facilitate the diagnosis and treatment of these rare diseases and, therefore, would improve dramatically the quality of life of these patients.