 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scale up to infinity: the UWB Indoor Global Positioning System
Dec 03, 2021
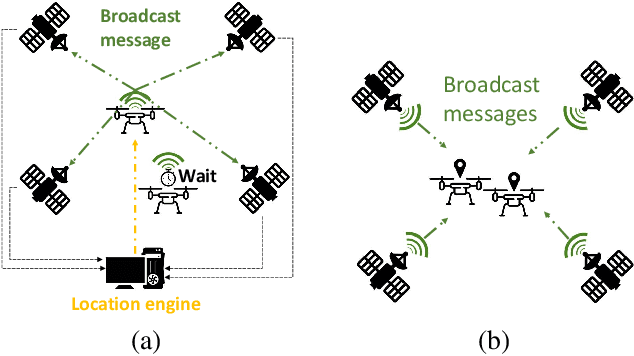
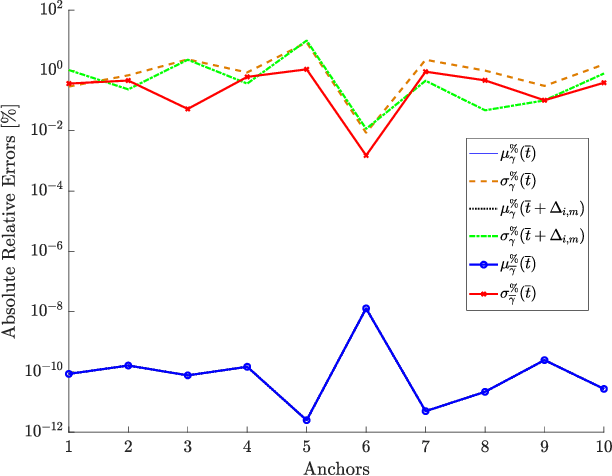
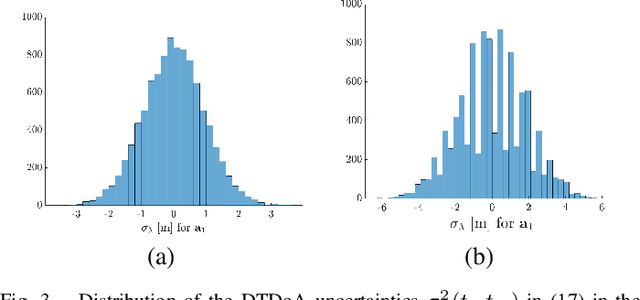
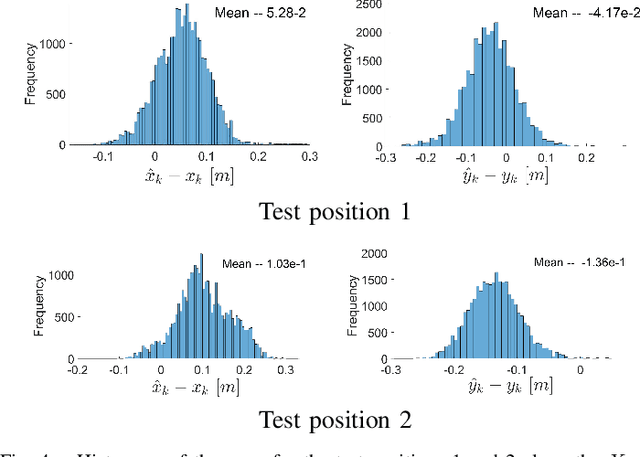
Determining assets position with high accuracy and scalability is one of the most investigated technology on the market. The accuracy provided by satellites-based positioning systems (i.e., GLONASS or Galileo) is not always sufficient when a decimeter-level accuracy is required or when there is the need of localising entities that operate inside indoor environments. Scalability is also a recurrent problem when dealing with indoor positioning systems. This paper presents an innovative UWB Indoor GPS-Like local positioning system able to tracks any number of assets without decreasing measurements update rate. To increase the system's accuracy the mathematical model and the sources of uncertainties are investigated. Results highlight how the proposed implementation provides positioning information with an absolute maximum error below 20 cm. Scalability is also resolved thanks to DTDoA transmission mechanisms not requiring an active role from the asset to be tracked.
TransVOD: End-to-end Video Object Detection with Spatial-Temporal Transformers
Jan 14, 2022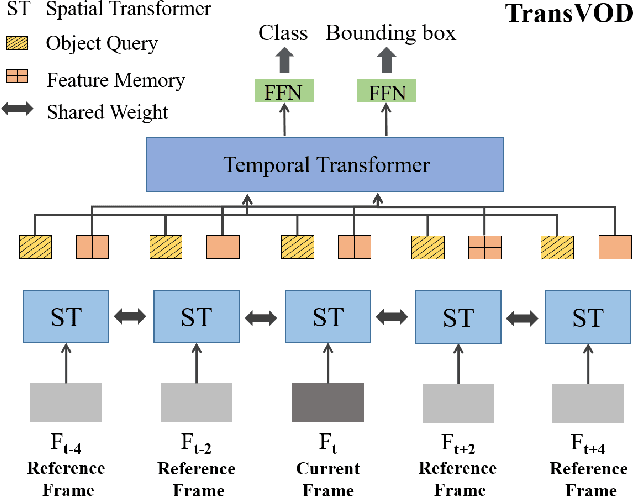
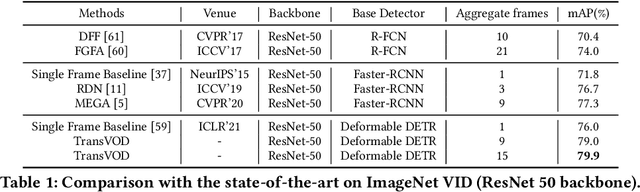
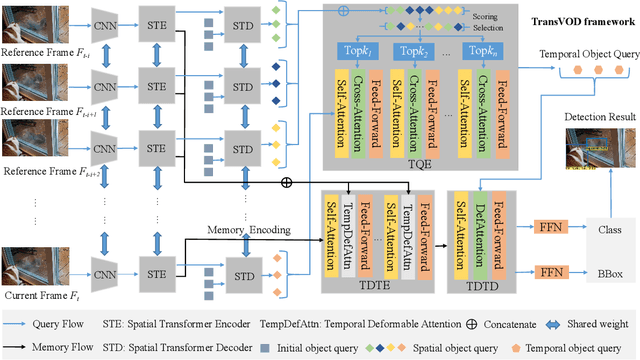
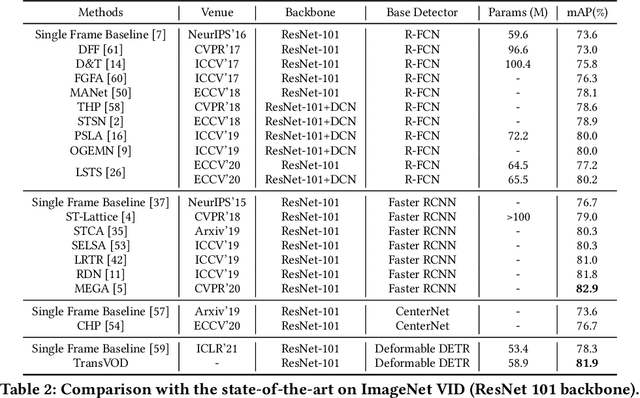
Detection Transformer (DETR) and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, the first end-to-end video object detection system based on spatial-temporal Transformer architectures. The first goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow model, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS. In particular, we present a temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal transformer consists of two components: Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder (TDTD) to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. Then, we present two improved versions of TransVOD including TransVOD++ and TransVOD Lite. The former fuses object-level information into object query via dynamic convolution while the latter models the entire video clips as the output to speed up the inference time. We give detailed analysis of all three models in the experiment part. In particular, our proposed TransVOD++ sets a new state-of-the-art record in terms of accuracy on ImageNet VID with 90.0% mAP. Our proposed TransVOD Lite also achieves the best speed and accuracy trade-off with 83.7% mAP while running at around 30 FPS on a single V100 GPU device. Code and models will be available for further research.
Fast Algorithms for Poker Require Modelling it as a Sequential Bayesian Game
Dec 20, 2021

Many recent results in imperfect information games were only formulated for, or evaluated on, poker and poker-like games such as liar's dice. We argue that sequential Bayesian games constitute a natural class of games for generalizing these results. In particular, this model allows for an elegant formulation of the counterfactual regret minimization algorithm, called public-state CFR (PS-CFR), which naturally lends itself to an efficient implementation. Empirically, solving a poker subgame with 10^7 states by public-state CFR takes 3 minutes and 700 MB while a comparable version of vanilla CFR takes 5.5 hours and 20 GB. Additionally, the public-state formulation of CFR opens up the possibility for exploiting domain-specific assumptions, leading to a quadratic reduction in asymptotic complexity (and a further empirical speedup) over vanilla CFR in poker and other domains. Overall, this suggests that the ability to represent poker as a sequential Bayesian game played a key role in the success of CFR-based methods. Finally, we extend public-state CFR to general extensive-form games, arguing that this extension enjoys some - but not all - of the benefits of the version for sequential Bayesian games.
Symmetry-Enhanced Attention Network for Acute Ischemic Infarct Segmentation with Non-Contrast CT Images
Oct 11, 2021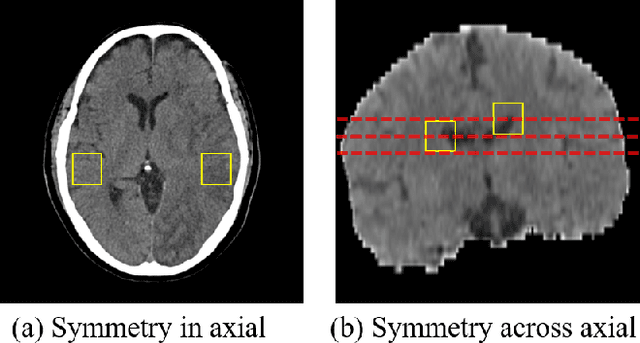
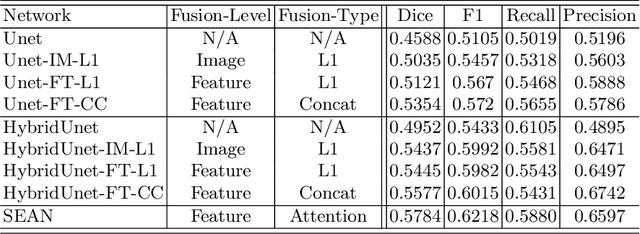
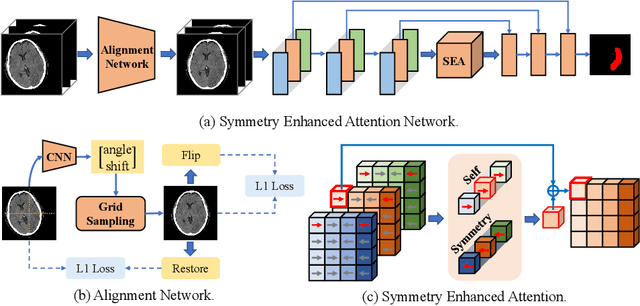
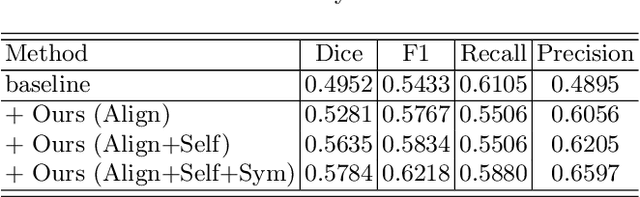
Quantitative estimation of the acute ischemic infarct is crucial to improve neurological outcomes of the patients with stroke symptoms. Since the density of lesions is subtle and can be confounded by normal physiologic changes, anatomical asymmetry provides useful information to differentiate the ischemic and healthy brain tissue. In this paper, we propose a symmetry enhanced attention network (SEAN) for acute ischemic infarct segmentation. Our proposed network automatically transforms an input CT image into the standard space where the brain tissue is bilaterally symmetric. The transformed image is further processed by a Ushape network integrated with the proposed symmetry enhanced attention for pixel-wise labelling. The symmetry enhanced attention can efficiently capture context information from the opposite side of the image by estimating long-range dependencies. Experimental results show that the proposed SEAN outperforms some symmetry-based state-of-the-art methods in terms of both dice coefficient and infarct localization.
Expected hypervolume improvement for simultaneous multi-objective and multi-fidelity optimization
Dec 30, 2021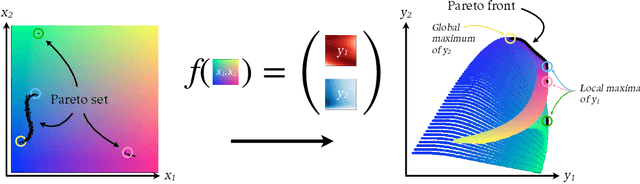
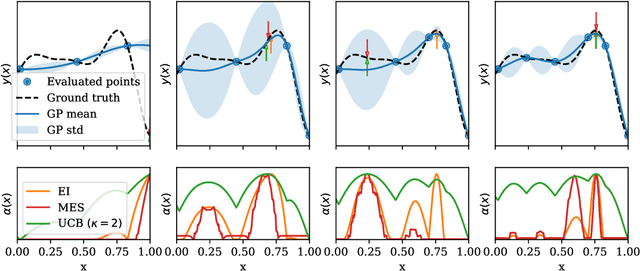
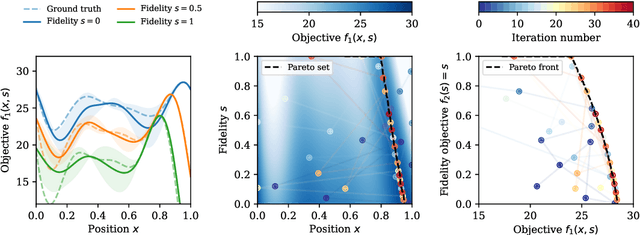
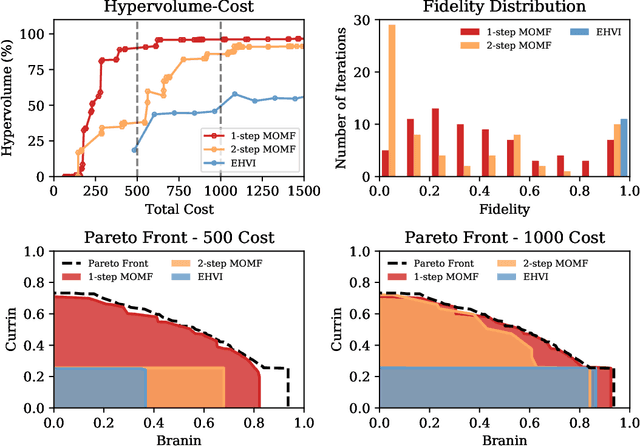
Bayesian optimization has proven to be an efficient method to optimize expensive-to-evaluate systems. However, depending on the cost of single observations, multi-dimensional optimizations of one or more objectives may still be prohibitively expensive. Multi-fidelity optimization remedies this issue by including multiple, cheaper information sources such as low-resolution approximations in numerical simulations. Acquisition functions for multi-fidelity optimization are typically based on exploration-heavy algorithms that are difficult to combine with optimization towards multiple objectives. Here we show that the expected hypervolume improvement policy can act in many situations as a suitable substitute. We incorporate the evaluation cost either via a two-step evaluation or within a single acquisition function with an additional fidelity-related objective. This permits simultaneous multi-objective and multi-fidelity optimization, which allows to accurately establish the Pareto set and front at fractional cost. Benchmarks show a cost reduction of an order of magnitude or more. Our method thus allows for Pareto optimization of extremely expansive black-box functions. The presented methods are simple and straightforward to implement in existing, optimized Bayesian optimization frameworks and can immediately be extended to batch optimization. The techniques can also be used to combine different continuous and/or discrete fidelity dimensions, which makes them particularly relevant for simulation problems in plasma physics, fluid dynamics and many other branches of scientific computing.
Interactive Segmentation for COVID-19 Infection Quantification on Longitudinal CT scans
Oct 03, 2021
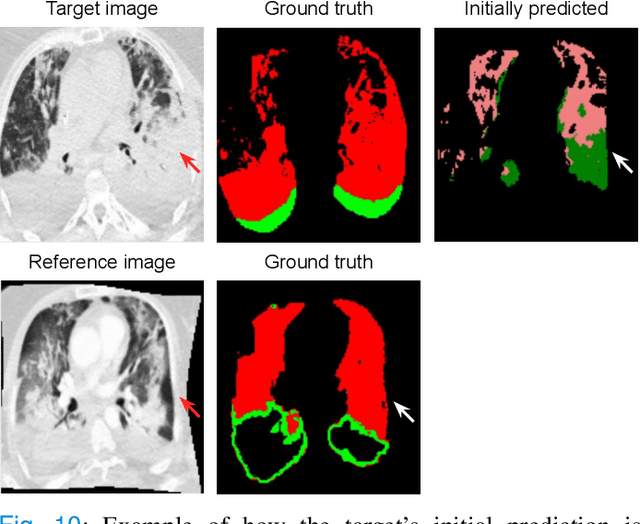
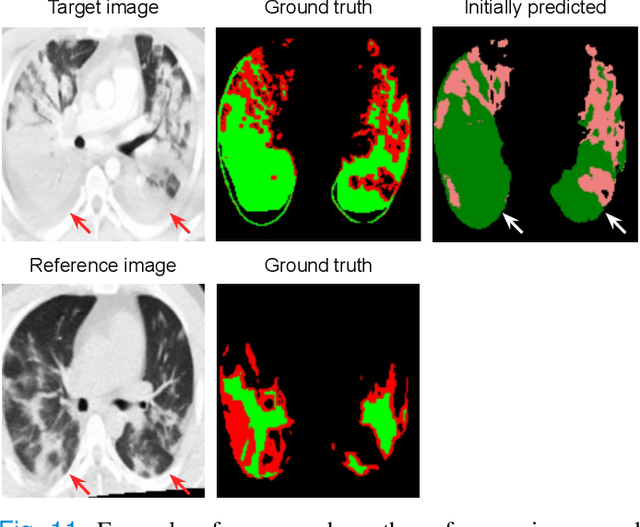
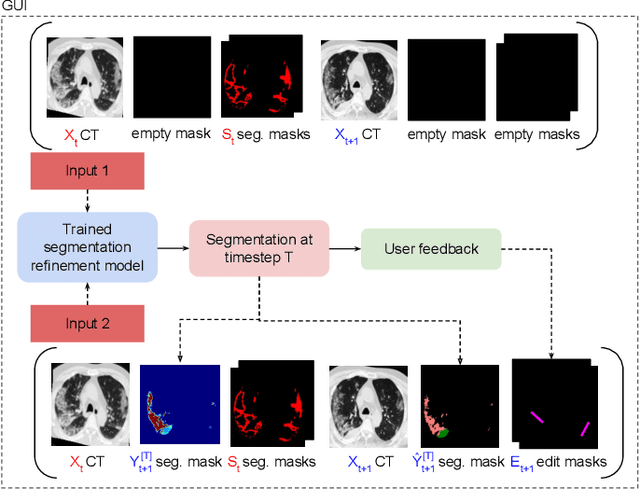
Consistent segmentation of COVID-19 patient's CT scans across multiple time points is essential to assess disease progression and response to therapy accurately. Existing automatic and interactive segmentation models for medical images only use data from a single time point (static). However, valuable segmentation information from previous time points is often not used to aid the segmentation of a patient's follow-up scans. Also, fully automatic segmentation techniques frequently produce results that would need further editing for clinical use. In this work, we propose a new single network model for interactive segmentation that fully utilizes all available past information to refine the segmentation of follow-up scans. In the first segmentation round, our model takes 3D volumes of medical images from two-time points (target and reference) as concatenated slices with the additional reference time point segmentation as a guide to segment the target scan. In subsequent segmentation refinement rounds, user feedback in the form of scribbles that correct the segmentation and the target's previous segmentation results are additionally fed into the model. This ensures that the segmentation information from previous refinement rounds is retained. Experimental results on our in-house multiclass longitudinal COVID-19 dataset show that the proposed model outperforms its static version and can assist in localizing COVID-19 infections in patient's follow-up scans.
Graph Theory in the Classification of Information Systems
Dec 27, 2020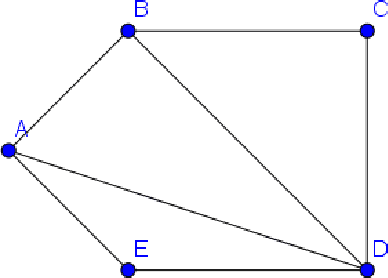
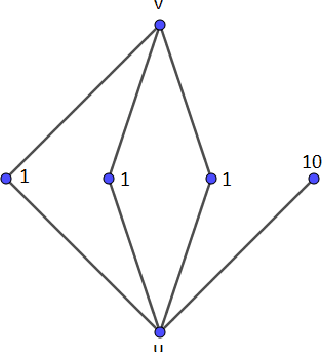
Risk classification plays an important role in many regulations and standards. However, a general method that provides an optimal classification has not been proposed yet. Also, the criteria of optimality are not defined in these regulations. In this work, we will propose a mathematical model that is sufficient to describe this problem, and we also propose an algorithm that classifies graph vertices based on their risk value in polynomial time.
A Dual-Attention Neural Network for Pun Location and Using Pun-Gloss Pairs for Interpretation
Oct 14, 2021

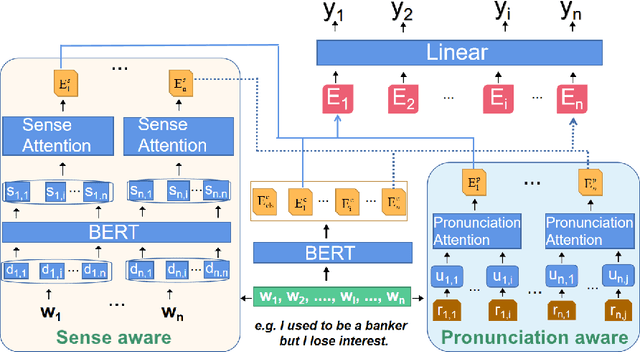
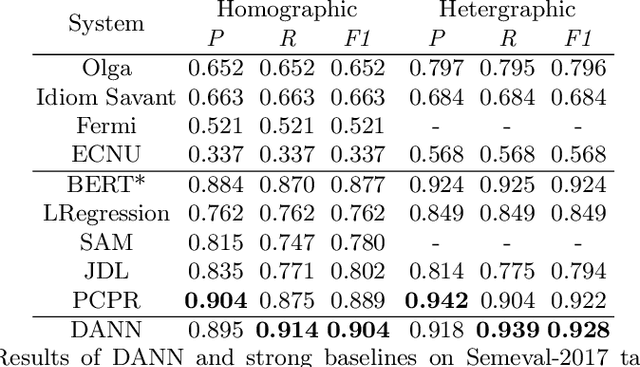
Pun location is to identify the punning word (usually a word or a phrase that makes the text ambiguous) in a given short text, and pun interpretation is to find out two different meanings of the punning word. Most previous studies adopt limited word senses obtained by WSD(Word Sense Disambiguation) technique or pronunciation information in isolation to address pun location. For the task of pun interpretation, related work pays attention to various WSD algorithms. In this paper, a model called DANN (Dual-Attentive Neural Network) is proposed for pun location, effectively integrates word senses and pronunciation with context information to address two kinds of pun at the same time. Furthermore, we treat pun interpretation as a classification task and construct pungloss pairs as processing data to solve this task. Experiments on the two benchmark datasets show that our proposed methods achieve new state-of-the-art results. Our source code is available in the public code repository.
Subtractive mountain clustering algorithm applied to a chatbot to assist elderly people in medication intake
Oct 03, 2021
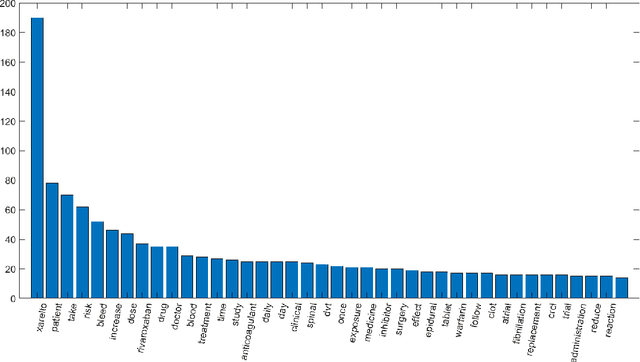
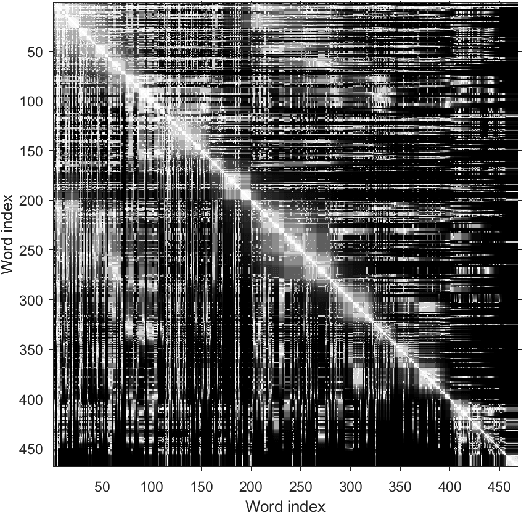
Errors in medication intake among elderly people are very common. One of the main causes for this is their loss of ability to retain information. The high amount of medicine intake required by the advanced age is another limiting factor. Thence, the design of an interactive aid system, preferably using natural language, to help the older population with medication is in demand. A chatbot based on a subtractive cluster algorithm, included in unsupervised learned models, is the chosen solution since the processing of natural languages is a necessary step in view to construct a chatbot able to answer questions that older people may pose upon themselves concerning a particular drug. In this work, the subtractive mountain clustering algorithm has been adapted to the problem of natural languages processing. This algorithm version allows for the association of a set of words into clusters. After finding the centre of every cluster -- the most relevant word, all the others are aggregated according to a defined metric adapted to the language processing realm. All the relevant stored information is processed, as well as the questions, by the algorithm. The correct processing of the text enables the chatbot to produce answers that relate to the posed queries. To validate the method, we use the package insert of a drug as the available information and formulate associated questions.
Meta-CPR: Generalize to Unseen Large Number of Agents with Communication Pattern Recognition Module
Dec 15, 2021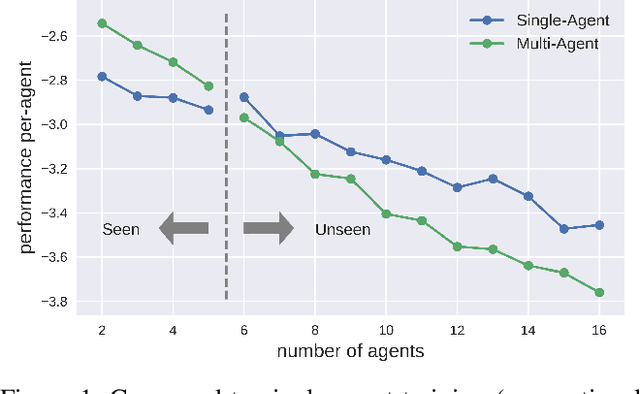
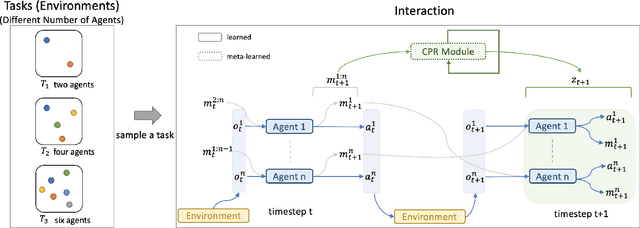
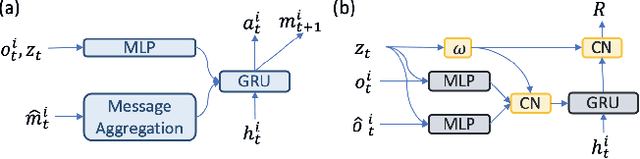
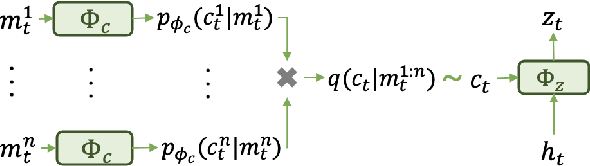
Designing an effective communication mechanism among agents in reinforcement learning has been a challenging task, especially for real-world applications. The number of agents can grow or an environment sometimes needs to interact with a changing number of agents in real-world scenarios. To this end, a multi-agent framework needs to handle various scenarios of agents, in terms of both scales and dynamics, for being practical to real-world applications. We formulate the multi-agent environment with a different number of agents as a multi-tasking problem and propose a meta reinforcement learning (meta-RL) framework to tackle this problem. The proposed framework employs a meta-learned Communication Pattern Recognition (CPR) module to identify communication behavior and extract information that facilitates the training process. Experimental results are poised to demonstrate that the proposed framework (a) generalizes to an unseen larger number of agents and (b) allows the number of agents to change between episodes. The ablation study is also provided to reason the proposed CPR design and show such design is effective.