 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of optimal prediction error Thévenin models of Li-ion cells using the MOLI approach
Dec 19, 2022



This report presents System Identification algorithms to estimate the dynamical model of Li-Oin cells. First the dependence of open circuit voltage (OCV) on the state of charge (SOC) is studied. thN battery equivalent model when a resistor is added to the circuit is stated. The discharge data is divided into segments where the internal resistance is assumed constant, and therefore SOC is constant, thence is described an LTI identification algorithm to be used to estimate the cell model in each segment. A Randles circuit is introduced to the model to describe the diffusion process. This model includes the so called Warburg impedance which is as fractional system. This impedance is discussed and it is approximatted by a finite order linear time invariant state-space model. Also, after presenting the simplified Randles circuit, is stated an identification algorithm that estimates the parameters of this model. The Th\'evenin model is presented as an alternative to the Randles circuit. An algorithm to identify a Th\'evenin model of 1st and 2nd order is enunciated. The performances of the simplified randles model and of the two Th\'evenin models models described and its respective identification algorithms, are discussed and compared using an experimental set of data.
Subtractive mountain clustering algorithm applied to a chatbot to assist elderly people in medication intake
Oct 03, 2021
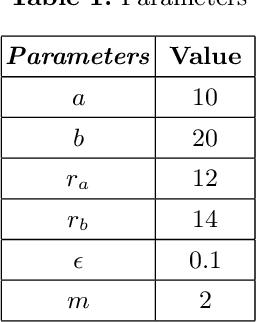
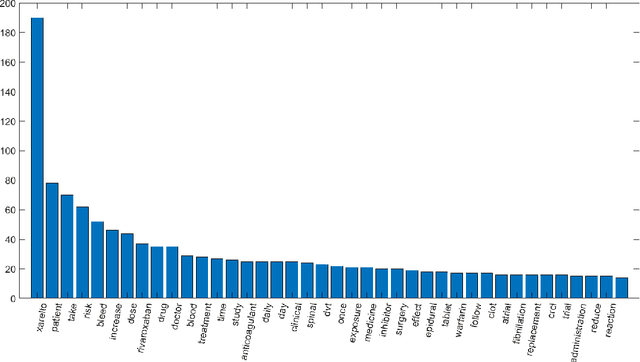
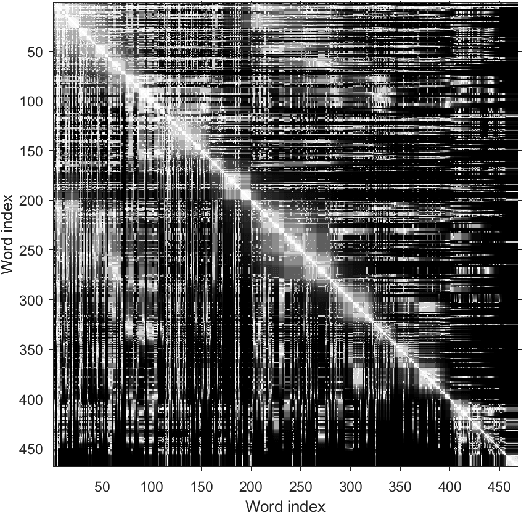
Errors in medication intake among elderly people are very common. One of the main causes for this is their loss of ability to retain information. The high amount of medicine intake required by the advanced age is another limiting factor. Thence, the design of an interactive aid system, preferably using natural language, to help the older population with medication is in demand. A chatbot based on a subtractive cluster algorithm, included in unsupervised learned models, is the chosen solution since the processing of natural languages is a necessary step in view to construct a chatbot able to answer questions that older people may pose upon themselves concerning a particular drug. In this work, the subtractive mountain clustering algorithm has been adapted to the problem of natural languages processing. This algorithm version allows for the association of a set of words into clusters. After finding the centre of every cluster -- the most relevant word, all the others are aggregated according to a defined metric adapted to the language processing realm. All the relevant stored information is processed, as well as the questions, by the algorithm. The correct processing of the text enables the chatbot to produce answers that relate to the posed queries. To validate the method, we use the package insert of a drug as the available information and formulate associated questions.