 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection, Classification, and Mitigation of Gender Bias in Large Language Models
Jun 14, 2025With the rapid development of large language models (LLMs), they have significantly improved efficiency across a wide range of domains. However, recent studies have revealed that LLMs often exhibit gender bias, leading to serious social implications. Detecting, classifying, and mitigating gender bias in LLMs has therefore become a critical research focus. In the NLPCC 2025 Shared Task 7: Chinese Corpus for Gender Bias Detection, Classification and Mitigation Challenge, we investigate how to enhance the capabilities of LLMs in gender bias detection, classification, and mitigation. We adopt reinforcement learning, chain-of-thoughts (CoT) reasoning, and supervised fine-tuning to handle different Subtasks. Specifically, for Subtasks 1 and 2, we leverage the internal reasoning capabilities of LLMs to guide multi-step thinking in a staged manner, which simplifies complex biased queries and improves response accuracy. For Subtask 3, we employ a reinforcement learning-based approach, annotating a preference dataset using GPT-4. We then apply Direct Preference Optimization (DPO) to mitigate gender bias by introducing a loss function that explicitly favors less biased completions over biased ones. Our approach ranked first across all three subtasks of the NLPCC 2025 Shared Task 7.
BiasFilter: An Inference-Time Debiasing Framework for Large Language Models
May 28, 2025Mitigating social bias in large language models (LLMs) has become an increasingly important research objective. However, existing debiasing methods often incur high human and computational costs, exhibit limited effectiveness, and struggle to scale to larger models and open-ended generation tasks. To address these limitations, this paper proposes BiasFilter, a model-agnostic, inference-time debiasing framework that integrates seamlessly with both open-source and API-based LLMs. Instead of relying on retraining with balanced data or modifying model parameters, BiasFilter enforces fairness by filtering generation outputs in real time. Specifically, it periodically evaluates intermediate outputs every few tokens, maintains an active set of candidate continuations, and incrementally completes generation by discarding low-reward segments based on a fairness reward signal. To support this process, we construct a fairness preference dataset and train an implicit reward model to assess token-level fairness in generated responses. Extensive experiments demonstrate that BiasFilter effectively mitigates social bias across a range of LLMs while preserving overall generation quality.
CMoralEval: A Moral Evaluation Benchmark for Chinese Large Language Models
Aug 19, 2024



What a large language model (LLM) would respond in ethically relevant context? In this paper, we curate a large benchmark CMoralEval for morality evaluation of Chinese LLMs. The data sources of CMoralEval are two-fold: 1) a Chinese TV program discussing Chinese moral norms with stories from the society and 2) a collection of Chinese moral anomies from various newspapers and academic papers on morality. With these sources, we aim to create a moral evaluation dataset characterized by diversity and authenticity. We develop a morality taxonomy and a set of fundamental moral principles that are not only rooted in traditional Chinese culture but also consistent with contemporary societal norms. To facilitate efficient construction and annotation of instances in CMoralEval, we establish a platform with AI-assisted instance generation to streamline the annotation process. These help us curate CMoralEval that encompasses both explicit moral scenarios (14,964 instances) and moral dilemma scenarios (15,424 instances), each with instances from different data sources. We conduct extensive experiments with CMoralEval to examine a variety of Chinese LLMs. Experiment results demonstrate that CMoralEval is a challenging benchmark for Chinese LLMs. The dataset is publicly available at \url{https://github.com/tjunlp-lab/CMoralEval}.
Symmetry-Enhanced Attention Network for Acute Ischemic Infarct Segmentation with Non-Contrast CT Images
Oct 11, 2021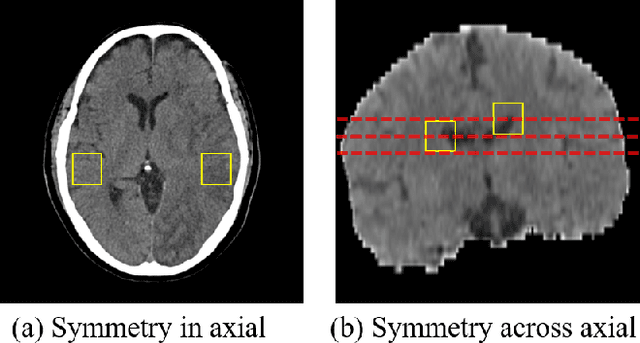
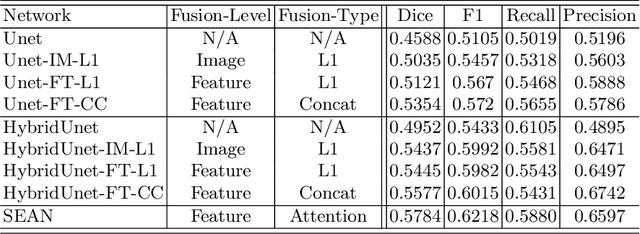
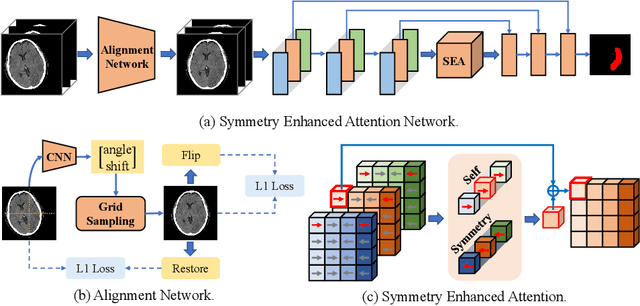
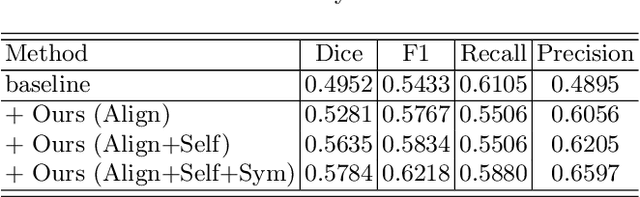
Quantitative estimation of the acute ischemic infarct is crucial to improve neurological outcomes of the patients with stroke symptoms. Since the density of lesions is subtle and can be confounded by normal physiologic changes, anatomical asymmetry provides useful information to differentiate the ischemic and healthy brain tissue. In this paper, we propose a symmetry enhanced attention network (SEAN) for acute ischemic infarct segmentation. Our proposed network automatically transforms an input CT image into the standard space where the brain tissue is bilaterally symmetric. The transformed image is further processed by a Ushape network integrated with the proposed symmetry enhanced attention for pixel-wise labelling. The symmetry enhanced attention can efficiently capture context information from the opposite side of the image by estimating long-range dependencies. Experimental results show that the proposed SEAN outperforms some symmetry-based state-of-the-art methods in terms of both dice coefficient and infarct localization.