 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DecBERT: Enhancing the Language Understanding of BERT with Causal Attention Masks
Apr 19, 2022
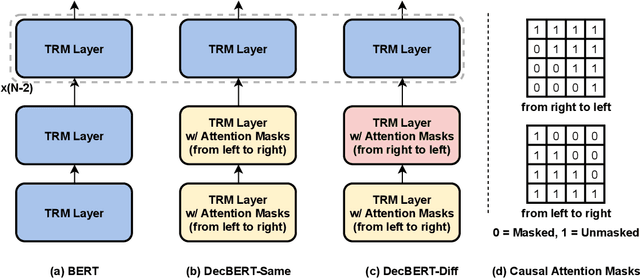


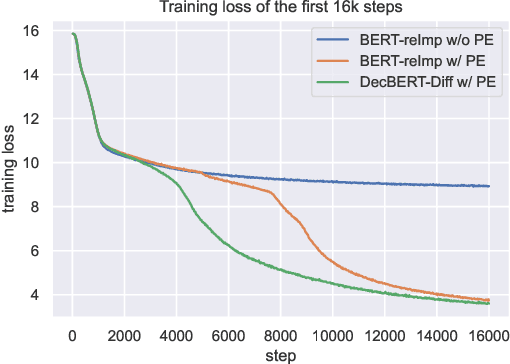
Since 2017, the Transformer-based models play critical roles in various downstream Natural Language Processing tasks. However, a common limitation of the attention mechanism utilized in Transformer Encoder is that it cannot automatically capture the information of word order, so explicit position embeddings are generally required to be fed into the target model. In contrast, Transformer Decoder with the causal attention masks is naturally sensitive to the word order. In this work, we focus on improving the position encoding ability of BERT with the causal attention masks. Furthermore, we propose a new pre-trained language model DecBERT and evaluate it on the GLUE benchmark. Experimental results show that (1) the causal attention mask is effective for BERT on the language understanding tasks; (2) our DecBERT model without position embeddings achieve comparable performance on the GLUE benchmark; and (3) our modification accelerates the pre-training process and DecBERT w/ PE achieves better overall performance than the baseline systems when pre-training with the same amount of computational resources.
LAMNER: Code Comment Generation Using Character Language Model and Named Entity Recognition
Apr 05, 2022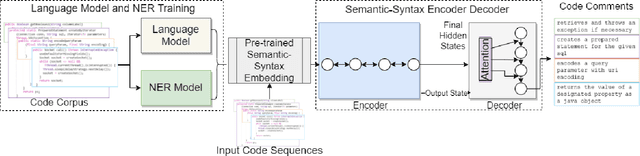
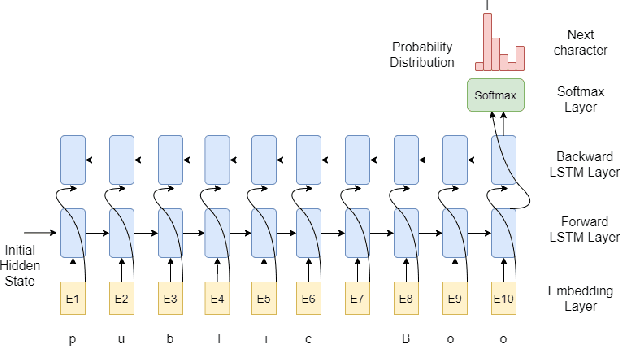
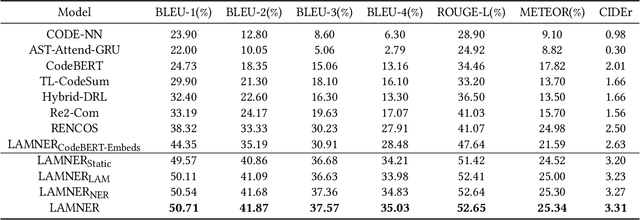
Code comment generation is the task of generating a high-level natural language description for a given code method or function. Although researchers have been studying multiple ways to generate code comments automatically, previous work mainly considers representing a code token in its entirety semantics form only (e.g., a language model is used to learn the semantics of a code token), and additional code properties such as the tree structure of a code are included as an auxiliary input to the model. There are two limitations: 1) Learning the code token in its entirety form may not be able to capture information succinctly in source code, and 2) The code token does not contain additional syntactic information, inherently important in programming languages. In this paper, we present LAnguage Model and Named Entity Recognition (LAMNER), a code comment generator capable of encoding code constructs effectively and capturing the structural property of a code token. A character-level language model is used to learn the semantic representation to encode a code token. For the structural property of a token, a Named Entity Recognition model is trained to learn the different types of code tokens. These representations are then fed into an encoder-decoder architecture to generate code comments. We evaluate the generated comments from LAMNER and other baselines on a popular Java dataset with four commonly used metrics. Our results show that LAMNER is effective and improves over the best baseline model in BLEU-1, BLEU-2, BLEU-3, BLEU-4, ROUGE-L, METEOR, and CIDEr by 14.34%, 18.98%, 21.55%, 23.00%, 10.52%, 1.44%, and 25.86%, respectively. Additionally, we fused LAMNER's code representation with the baseline models, and the fused models consistently showed improvement over the non-fused models. The human evaluation further shows that LAMNER produces high-quality code comments.
Toward More Effective Human Evaluation for Machine Translation
Apr 11, 2022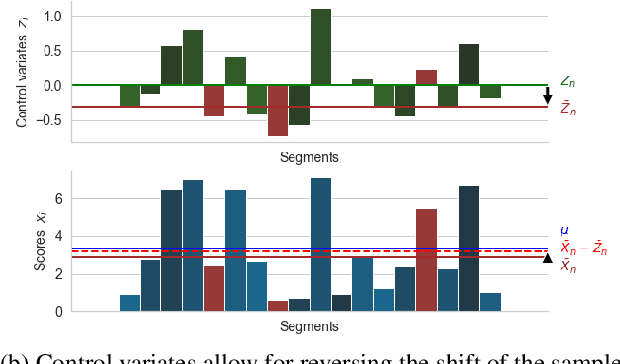
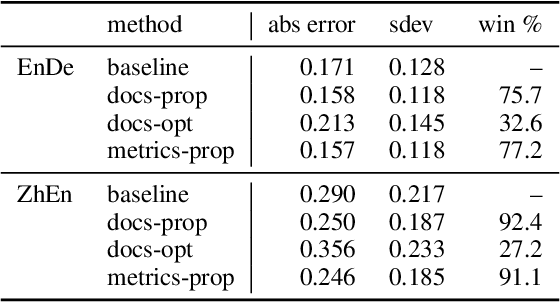
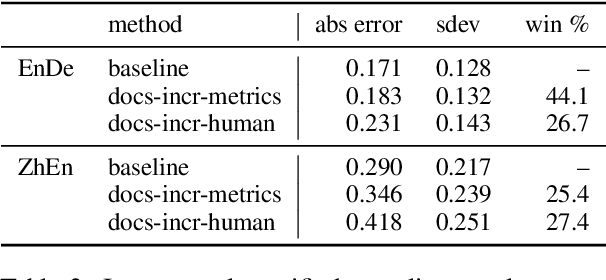
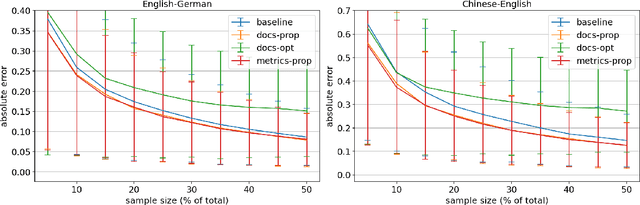
Improvements in text generation technologies such as machine translation have necessitated more costly and time-consuming human evaluation procedures to ensure an accurate signal. We investigate a simple way to reduce cost by reducing the number of text segments that must be annotated in order to accurately predict a score for a complete test set. Using a sampling approach, we demonstrate that information from document membership and automatic metrics can help improve estimates compared to a pure random sampling baseline. We achieve gains of up to 20% in average absolute error by leveraging stratified sampling and control variates. Our techniques can improve estimates made from a fixed annotation budget, are easy to implement, and can be applied to any problem with structure similar to the one we study.
SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix Data Augmentation
Apr 11, 2022
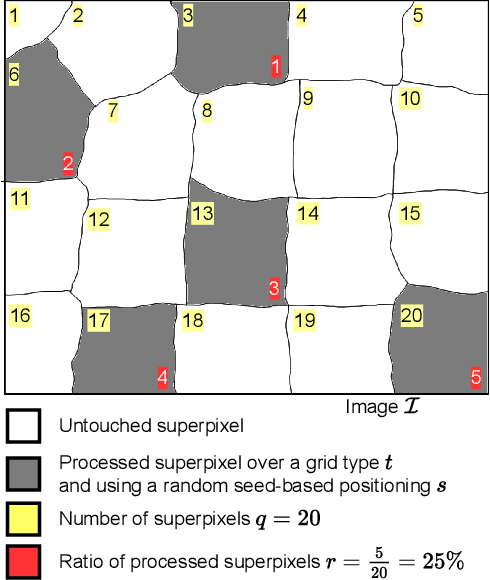

A novel approach of data augmentation based on irregular superpixel decomposition is proposed. This approach called SuperpixelGridMasks permits to extend original image datasets that are required by training stages of machine learning-related analysis architectures towards increasing their performances. Three variants named SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix are presented. These grid-based methods produce a new style of image transformations using the dropping and fusing of information. Extensive experiments using various image classification models and datasets show that baseline performances can be significantly outperformed using our methods. The comparative study also shows that our methods can overpass the performances of other data augmentations. Experimental results obtained over image recognition datasets of varied natures show the efficiency of these new methods. SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix codes are publicly available at https://github.com/hammoudiproject/SuperpixelGridMasks
Qtrade AI at SemEval-2022 Task 11: An Unified Framework for Multilingual NER Task
Apr 14, 2022
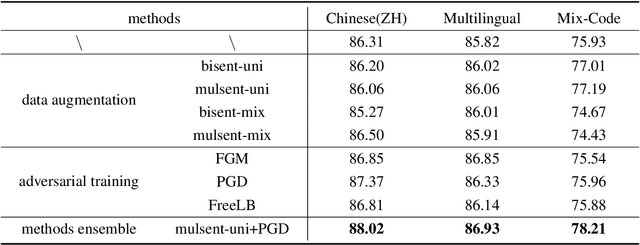
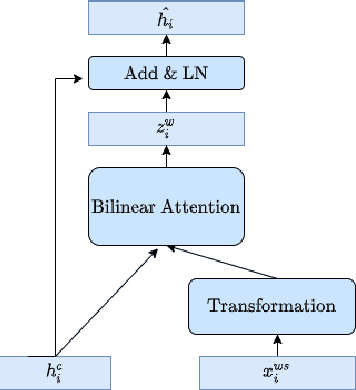
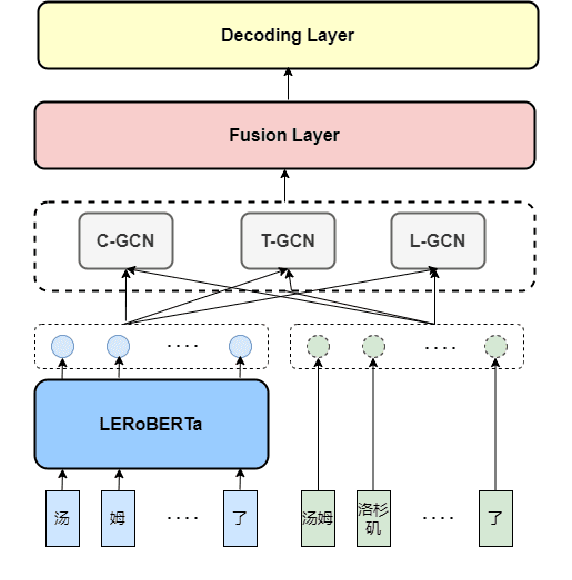
This paper describes our system, which placed third in the Multilingual Track (subtask 11), fourth in the Code-Mixed Track (subtask 12), and seventh in the Chinese Track (subtask 9) in the SemEval 2022 Task 11: MultiCoNER Multilingual Complex Named Entity Recognition. Our system's key contributions are as follows: 1) For multilingual NER tasks, we offer an unified framework with which one can easily execute single-language or multilingual NER tasks, 2) for low-resource code-mixed NER task, one can easily enhance his or her dataset through implementing several simple data augmentation methods and 3) for Chinese tasks, we propose a model that can capture Chinese lexical semantic, lexical border, and lexical graph structural information. Finally, our system achieves macro-f1 scores of 77.66, 84.35, and 74.00 on subtasks 11, 12, and 9, respectively, during the testing phase.
Mismatch between Multi-turn Dialogue and its Evaluation Metric in Dialogue State Tracking
Mar 07, 2022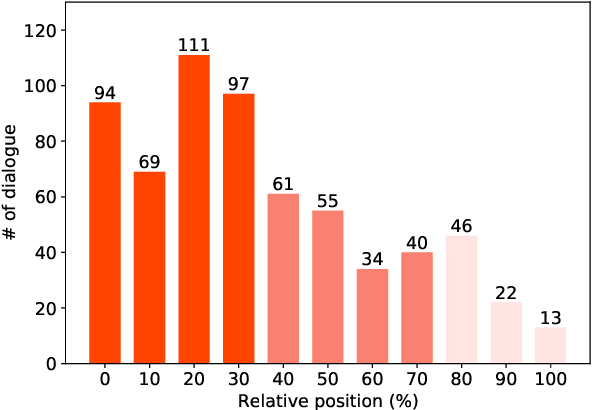
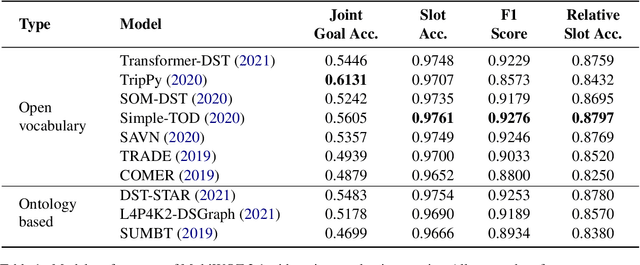
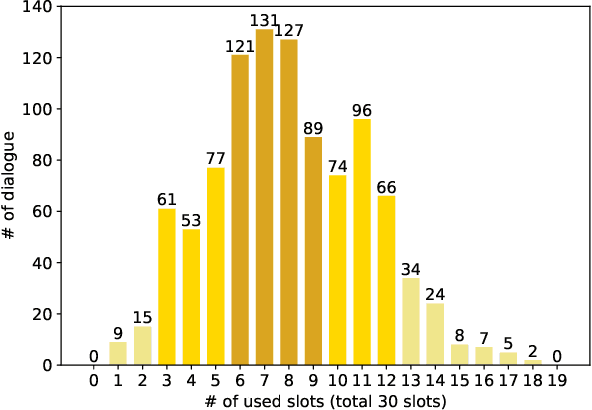
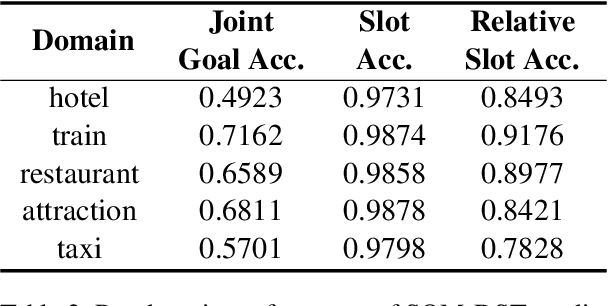
Dialogue state tracking (DST) aims to extract essential information from multi-turn dialogue situations and take appropriate actions. A belief state, one of the core pieces of information, refers to the subject and its specific content, and appears in the form of \texttt{domain-slot-value}. The trained model predicts "accumulated" belief states in every turn, and joint goal accuracy and slot accuracy are mainly used to evaluate the prediction; however, we specify that the current evaluation metrics have a critical limitation when evaluating belief states accumulated as the dialogue proceeds, especially in the most used MultiWOZ dataset. Additionally, we propose \textbf{relative slot accuracy} to complement existing metrics. Relative slot accuracy does not depend on the number of predefined slots, and allows intuitive evaluation by assigning relative scores according to the turn of each dialogue. This study also encourages not solely the reporting of joint goal accuracy, but also various complementary metrics in DST tasks for the sake of a realistic evaluation.
Detection Interval for Diffusion Molecular Communication: How Long is Enough?
Apr 19, 2022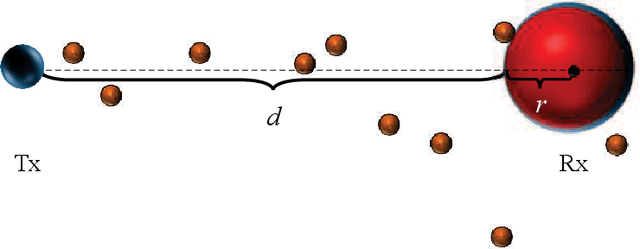
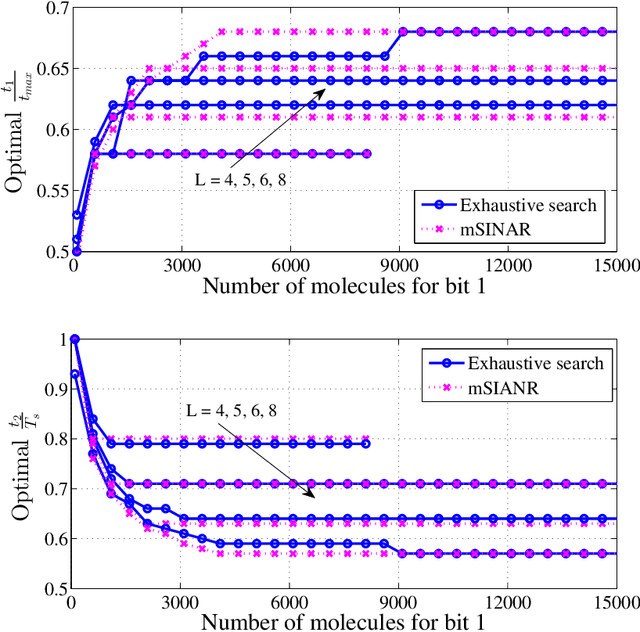
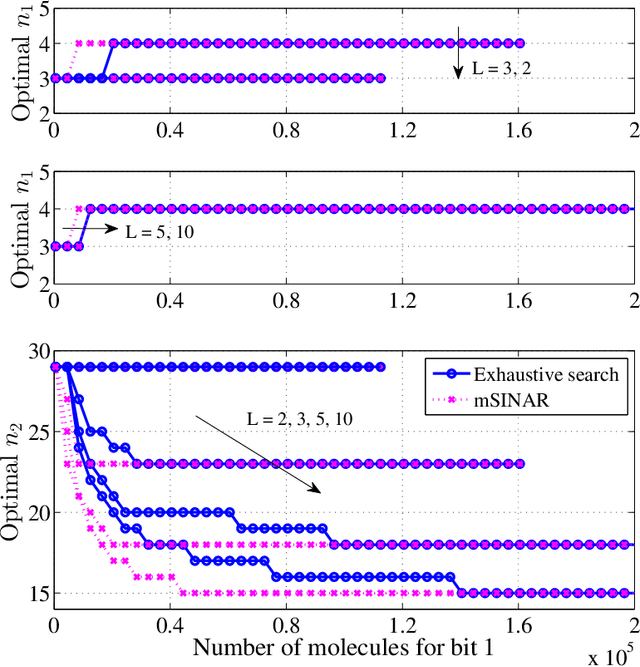
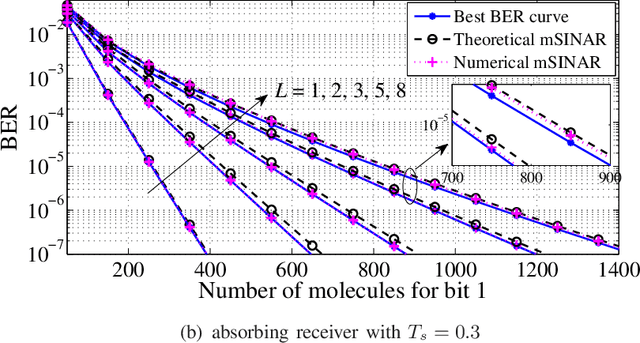
Molecular communication has a key role to play in future medical applications, including detecting, analyzing, and addressing infectious disease outbreaks. Overcoming inter-symbol interference (ISI) is one of the key challenges in the design of molecular communication systems. In this paper, we propose to optimize the detection interval to minimize the impact of ISI while ensuring the accurate detection of the transmitted information symbol, which is suitable for the absorbing and passive receivers. For tractability, based on the signal-to-interference difference (SID) and signal-to-interference-and-noise amplitude ratio (SINAR), we propose a modified-SINAR (mSINAR) to measure the bit error rate (BER) performance for the molecular communication system with a variable detection interval. Besides, we derive the optimal detection interval in closed form. Using simulation results, we show that the BER performance of our proposed mSINAR scheme is superior to the competing schemes, and achieves similar performance to optimal intervals found by the exhaustive search.
Deep Multi-Branch Aggregation Network for Real-Time Semantic Segmentation in Street Scenes
Mar 08, 2022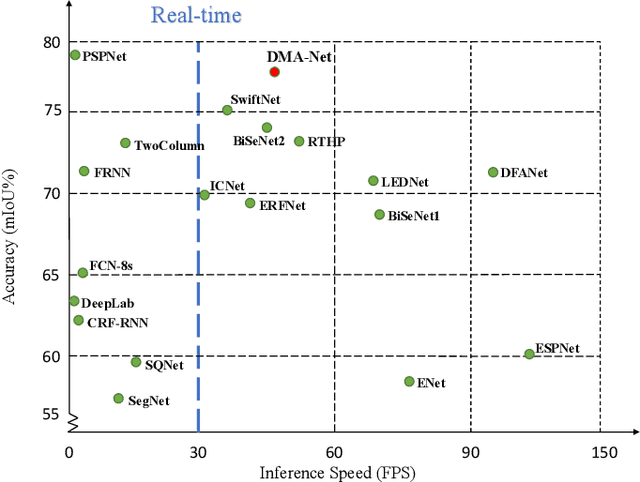


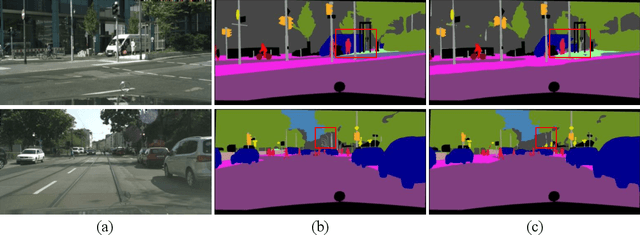
Real-time semantic segmentation, which aims to achieve high segmentation accuracy at real-time inference speed, has received substantial attention over the past few years. However, many state-of-the-art real-time semantic segmentation methods tend to sacrifice some spatial details or contextual information for fast inference, thus leading to degradation in segmentation quality. In this paper, we propose a novel Deep Multi-branch Aggregation Network (called DMA-Net) based on the encoder-decoder structure to perform real-time semantic segmentation in street scenes. Specifically, we first adopt ResNet-18 as the encoder to efficiently generate various levels of feature maps from different stages of convolutions. Then, we develop a Multi-branch Aggregation Network (MAN) as the decoder to effectively aggregate different levels of feature maps and capture the multi-scale information. In MAN, a lattice enhanced residual block is designed to enhance feature representations of the network by taking advantage of the lattice structure. Meanwhile, a feature transformation block is introduced to explicitly transform the feature map from the neighboring branch before feature aggregation. Moreover, a global context block is used to exploit the global contextual information. These key components are tightly combined and jointly optimized in a unified network. Extensive experimental results on the challenging Cityscapes and CamVid datasets demonstrate that our proposed DMA-Net respectively obtains 77.0% and 73.6% mean Intersection over Union (mIoU) at the inference speed of 46.7 FPS and 119.8 FPS by only using a single NVIDIA GTX 1080Ti GPU. This shows that DMA-Net provides a good tradeoff between segmentation quality and speed for semantic segmentation in street scenes.
CapOnImage: Context-driven Dense-Captioning on Image
Apr 27, 2022
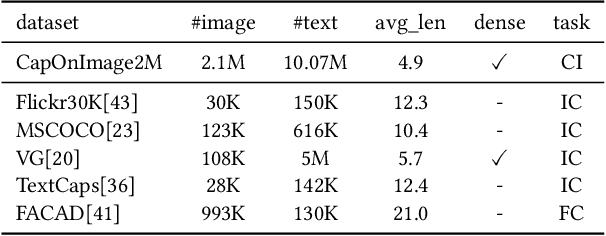
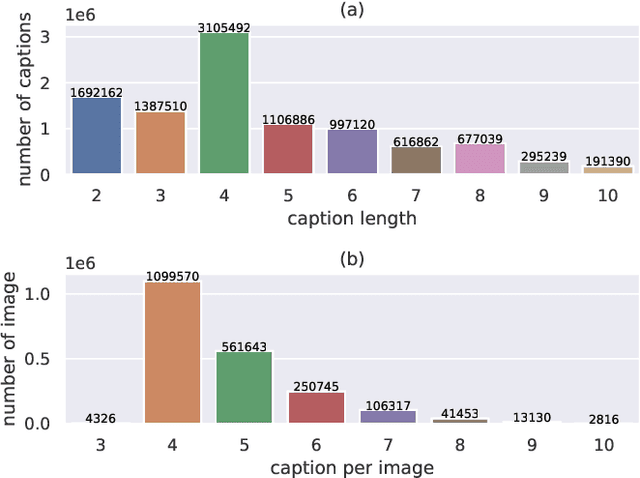
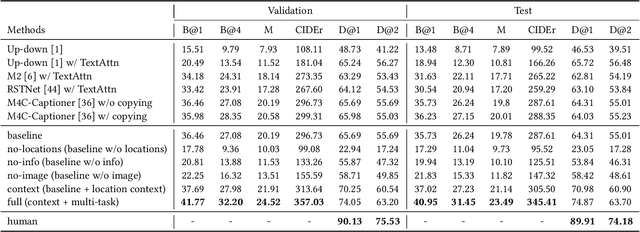
Existing image captioning systems are dedicated to generating narrative captions for images, which are spatially detached from the image in presentation. However, texts can also be used as decorations on the image to highlight the key points and increase the attractiveness of images. In this work, we introduce a new task called captioning on image (CapOnImage), which aims to generate dense captions at different locations of the image based on contextual information. To fully exploit the surrounding visual context to generate the most suitable caption for each location, we propose a multi-modal pre-training model with multi-level pre-training tasks that progressively learn the correspondence between texts and image locations from easy to difficult. Since the model may generate redundant captions for nearby locations, we further enhance the location embedding with neighbor locations as context. For this new task, we also introduce a large-scale benchmark called CapOnImage2M, which contains 2.1 million product images, each with an average of 4.8 spatially localized captions. Compared with other image captioning model variants, our model achieves the best results in both captioning accuracy and diversity aspects. We will make code and datasets public to facilitate future research.
RDP-Net: Region Detail Preserving Network for Change Detection
Feb 23, 2022
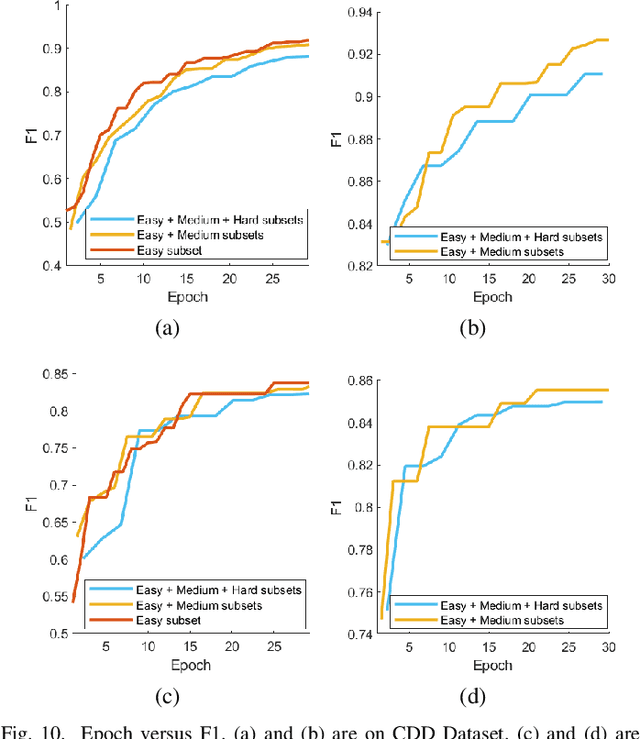

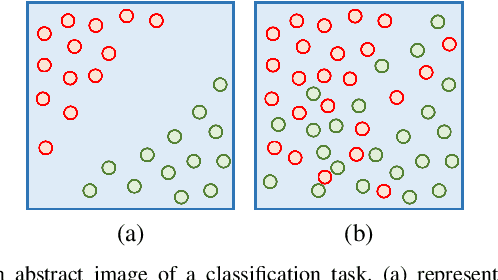
Change detection (CD) is an essential earth observation technique. It captures the dynamic information of land objects. With the rise of deep learning, neural networks (NN) have shown great potential in CD. However, current NN models introduce backbone architectures that lose the detail information during learning. Moreover, current NN models are heavy in parameters, which prevents their deployment on edge devices such as drones. In this work, we tackle this issue by proposing RDP-Net: a region detail preserving network for CD. We propose an efficient training strategy that quantifies the importance of individual samples during the warmup period of NN training. Then, we perform non-uniform sampling based on the importance score so that the NN could learn detail information from easy to hard. Next, we propose an effective edge loss that improves the network's attention on details such as boundaries and small regions. As a result, we provide a NN model that achieves the state-of-the-art empirical performance in CD with only 1.70M parameters. We hope our RDP-Net would benefit the practical CD applications on compact devices and could inspire more people to bring change detection to a new level with the efficient training strategy.