 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology-Based Knowledge Graph Framework for Industrial Standard Documents via Hierarchical and Propositional Structuring
Dec 22, 2025Ontology-based knowledge graph (KG) construction is a core technology that enables multidimensional understanding and advanced reasoning over domain knowledge. Industrial standards, in particular, contain extensive technical information and complex rules presented in highly structured formats that combine tables, scopes of application, constraints, exceptions, and numerical calculations, making KG construction especially challenging. In this study, we propose a method that organizes such documents into a hierarchical semantic structure, decomposes sentences and tables into atomic propositions derived from conditional and numerical rules, and integrates them into an ontology-knowledge graph through LLM-based triple extraction. Our approach captures both the hierarchical and logical structures of documents, effectively representing domain-specific semantics that conventional methods fail to reflect. To verify its effectiveness, we constructed rule, table, and multi-hop QA datasets, as well as a toxic clause detection dataset, from industrial standards, and implemented an ontology-aware KG-RAG framework for comparative evaluation. Experimental results show that our method achieves significant performance improvements across all QA types compared to existing KG-RAG approaches. This study demonstrates that reliable and scalable knowledge representation is feasible even for industrial documents with intertwined conditions, constraints, and scopes, contributing to future domain-specific RAG development and intelligent document management.
A Scalable Unsupervised Framework for multi-aspect labeling of Multilingual and Multi-Domain Review Data
May 14, 2025



Effectively analyzing online review data is essential across industries. However, many existing studies are limited to specific domains and languages or depend on supervised learning approaches that require large-scale labeled datasets. To address these limitations, we propose a multilingual, scalable, and unsupervised framework for cross-domain aspect detection. This framework is designed for multi-aspect labeling of multilingual and multi-domain review data. In this study, we apply automatic labeling to Korean and English review datasets spanning various domains and assess the quality of the generated labels through extensive experiments. Aspect category candidates are first extracted through clustering, and each review is then represented as an aspect-aware embedding vector using negative sampling. To evaluate the framework, we conduct multi-aspect labeling and fine-tune several pretrained language models to measure the effectiveness of the automatically generated labels. Results show that these models achieve high performance, demonstrating that the labels are suitable for training. Furthermore, comparisons with publicly available large language models highlight the framework's superior consistency and scalability when processing large-scale data. A human evaluation also confirms that the quality of the automatic labels is comparable to those created manually. This study demonstrates the potential of a robust multi-aspect labeling approach that overcomes limitations of supervised methods and is adaptable to multilingual, multi-domain environments. Future research will explore automatic review summarization and the integration of artificial intelligence agents to further improve the efficiency and depth of review analysis.
DSTEA: Dialogue State Tracking with Entity Adaptive Pre-training
Jul 08, 2022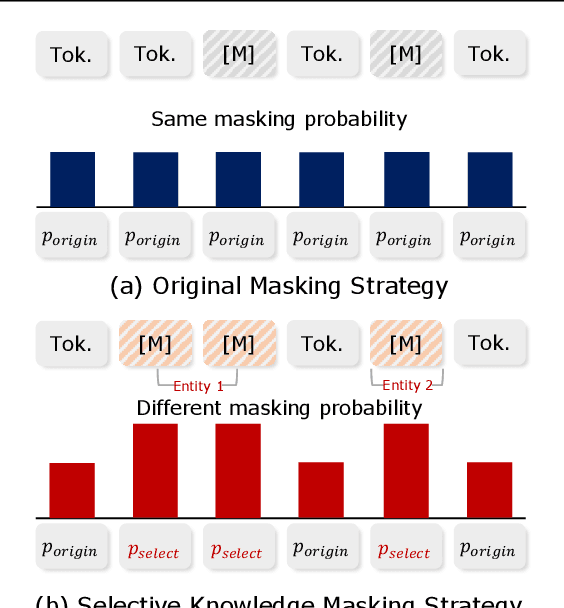
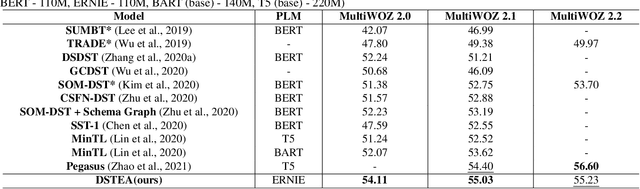
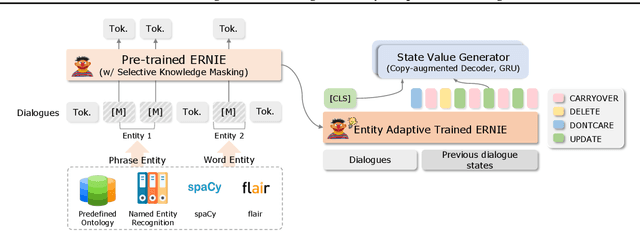
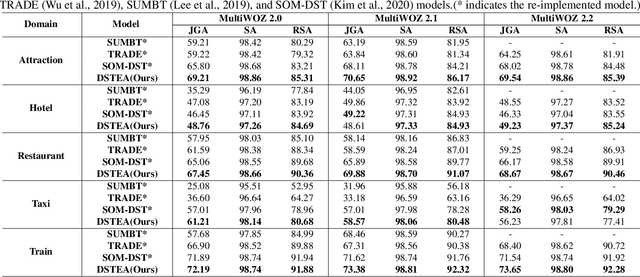
Dialogue state tracking (DST) is a core sub-module of a dialogue system, which aims to extract the appropriate belief state (domain-slot-value) from a system and user utterances. Most previous studies have attempted to improve performance by increasing the size of the pre-trained model or using additional features such as graph relations. In this study, we propose dialogue state tracking with entity adaptive pre-training (DSTEA), a system in which key entities in a sentence are more intensively trained by the encoder of the DST model. DSTEA extracts important entities from input dialogues in four ways, and then applies selective knowledge masking to train the model effectively. Although DSTEA conducts only pre-training without directly infusing additional knowledge to the DST model, it achieved better performance than the best-known benchmark models on MultiWOZ 2.0, 2.1, and 2.2. The effectiveness of DSTEA was verified through various comparative experiments with regard to the entity type and different adaptive settings.
Mismatch between Multi-turn Dialogue and its Evaluation Metric in Dialogue State Tracking
Mar 31, 2022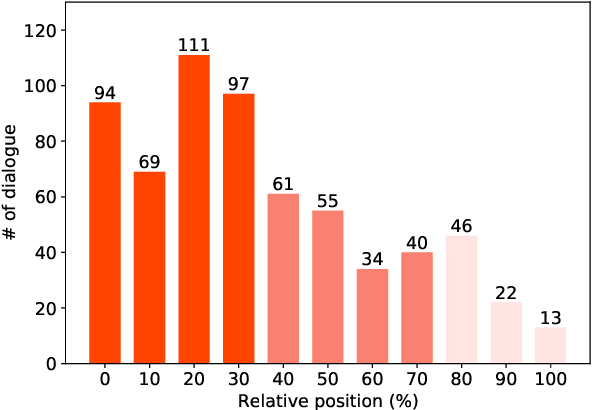
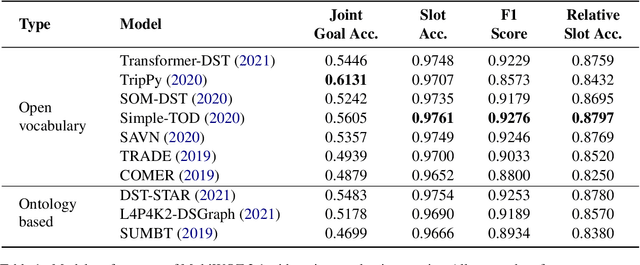
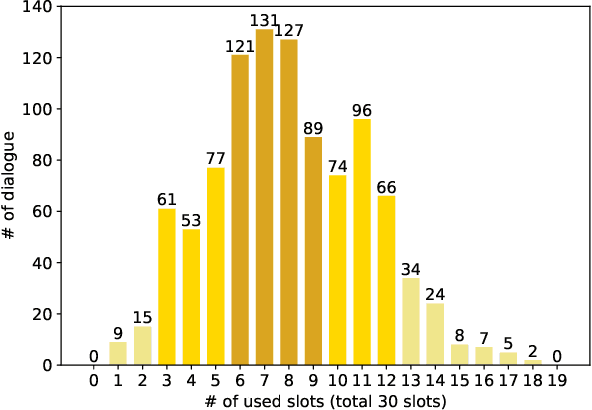
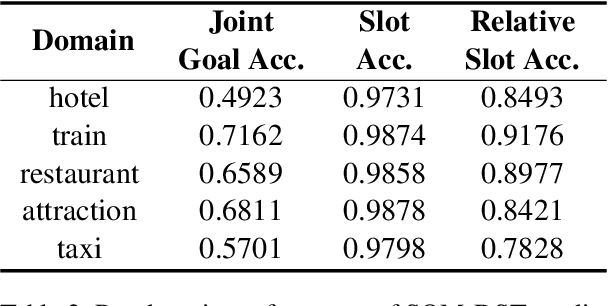
Dialogue state tracking (DST) aims to extract essential information from multi-turn dialogue situations and take appropriate actions. A belief state, one of the core pieces of information, refers to the subject and its specific content, and appears in the form of domain-slot-value. The trained model predicts "accumulated" belief states in every turn, and joint goal accuracy and slot accuracy are mainly used to evaluate the prediction; however, we specify that the current evaluation metrics have a critical limitation when evaluating belief states accumulated as the dialogue proceeds, especially in the most used MultiWOZ dataset. Additionally, we propose relative slot accuracy to complement existing metrics. Relative slot accuracy does not depend on the number of predefined slots, and allows intuitive evaluation by assigning relative scores according to the turn of each dialogue. This study also encourages not solely the reporting of joint goal accuracy, but also various complementary metrics in DST tasks for the sake of a realistic evaluation.
Oh My Mistake!: Toward Realistic Dialogue State Tracking including Turnback Utterances
Aug 28, 2021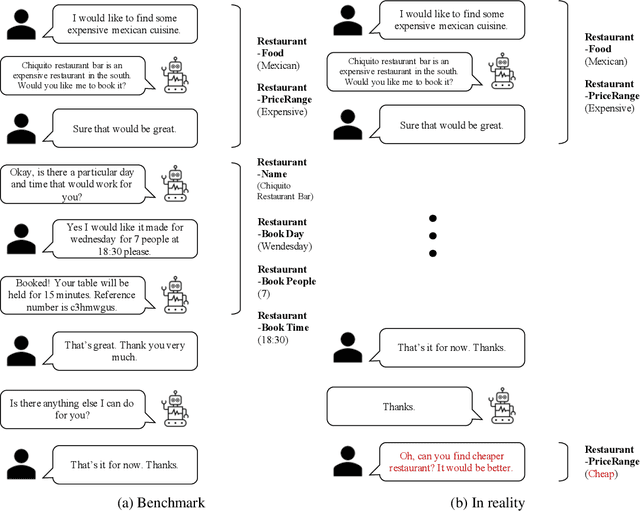
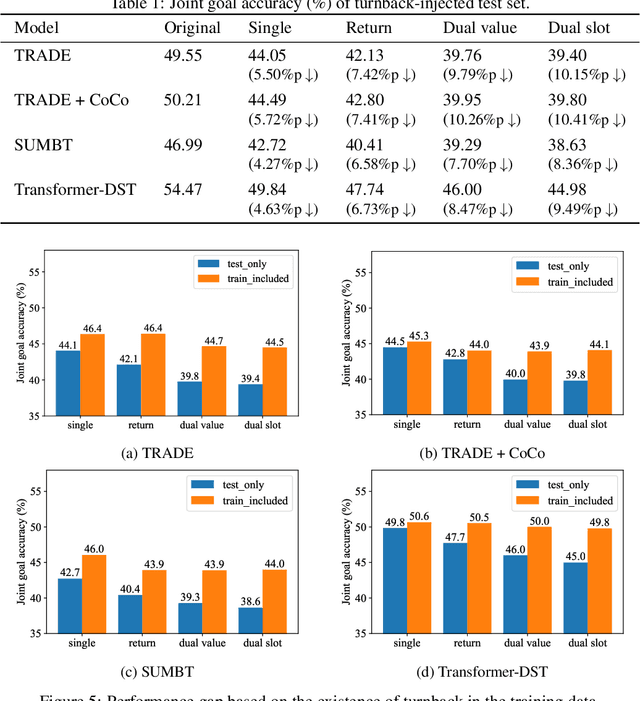

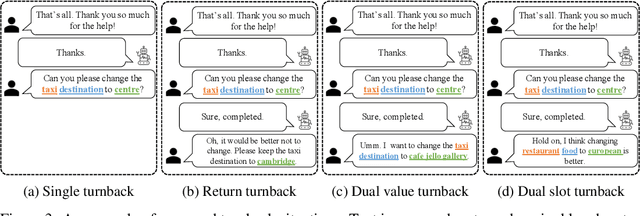
The primary purpose of dialogue state tracking (DST), a critical component of an end-to-end conversational system, is to build a model that responds well to real-world situations. Although we often change our minds during ordinary conversations, current benchmark datasets do not adequately reflect such occurrences and instead consist of over-simplified conversations, in which no one changes their mind during a conversation. As the main question inspiring the present study,``Are current benchmark datasets sufficiently diverse to handle casual conversations in which one changes their mind?'' We found that the answer is ``No'' because simply injecting template-based turnback utterances significantly degrades the DST model performance. The test joint goal accuracy on the MultiWOZ decreased by over 5\%p when the simplest form of turnback utterance was injected. Moreover, the performance degeneration worsens when facing more complicated turnback situations. However, we also observed that the performance rebounds when a turnback is appropriately included in the training dataset, implying that the problem is not with the DST models but rather with the construction of the benchmark dataset.