 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialect vs Demographics: Quantifying LLM Bias from Implicit Linguistic Signals vs. Explicit User Profiles
Apr 22, 2026As state-of-the-art Large Language Models (LLMs) have become ubiquitous, ensuring equitable performance across diverse demographics is critical. However, it remains unclear whether these disparities arise from the explicitly stated identity itself or from the way identity is signaled. In real-world interactions, users' identity is often conveyed implicitly through a complex combination of various socio-linguistic factors. This study disentangles these signals by employing a factorial design with over 24,000 responses from two open-weight LLMs (Gemma-3-12B and Qwen-3-VL-8B), comparing prompts with explicitly announced user profiles against implicit dialect signals (e.g., AAVE, Singlish) across various sensitive domains. Our results uncover a unique paradox in LLM safety where users achieve ``better'' performance by sounding like a demographic than by stating they belong to it. Explicit identity prompts activate aggressive safety filters, increasing refusal rates and reducing semantic similarity compared to our reference text for Black users. In contrast, implicit dialect cues trigger a powerful ``dialect jailbreak,'' reducing refusal probability to near zero while simultaneously achieving a greater level of semantic similarity to the reference texts compared to Standard American English prompts. However, this ``dialect jailbreak'' introduces a critical safety trade-off regarding content sanitization. We find that current safety alignment techniques are brittle and over-indexed on explicit keywords, creating a bifurcated user experience where ``standard'' users receive cautious, sanitized information while dialect speakers navigate a less sanitized, more raw, and potentially a more hostile information landscape and highlights a fundamental tension in alignment--between equitable and linguistic diversity--and underscores the need for safety mechanisms that generalize beyond explicit cues.
Toward More Effective Human Evaluation for Machine Translation
Apr 11, 2022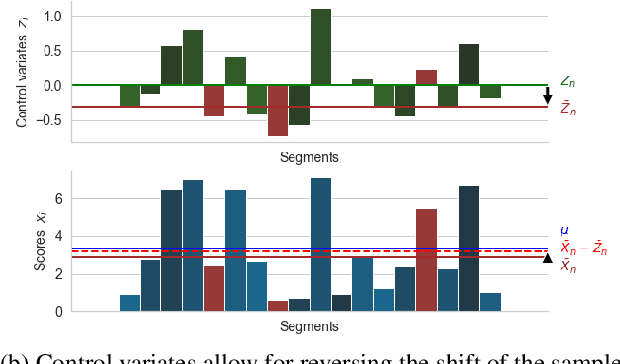
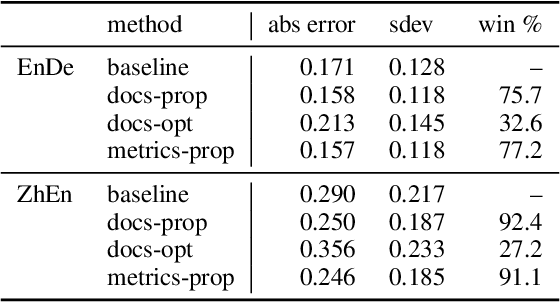
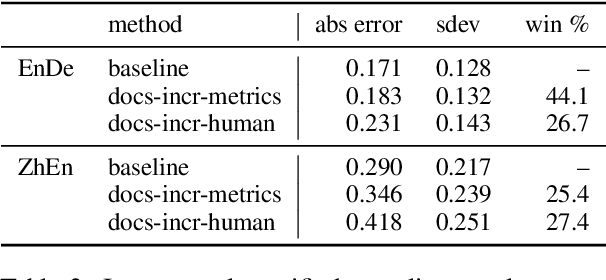
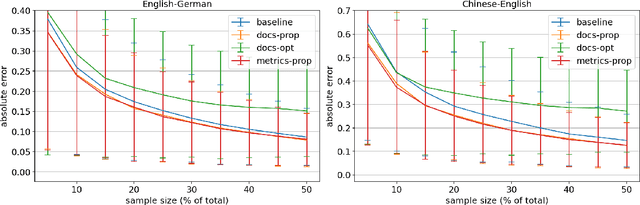
Improvements in text generation technologies such as machine translation have necessitated more costly and time-consuming human evaluation procedures to ensure an accurate signal. We investigate a simple way to reduce cost by reducing the number of text segments that must be annotated in order to accurately predict a score for a complete test set. Using a sampling approach, we demonstrate that information from document membership and automatic metrics can help improve estimates compared to a pure random sampling baseline. We achieve gains of up to 20% in average absolute error by leveraging stratified sampling and control variates. Our techniques can improve estimates made from a fixed annotation budget, are easy to implement, and can be applied to any problem with structure similar to the one we study.