 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLung Infection Severity Prediction Using Transformers with Conditional TransMix Augmentation and Cross-Attention
Oct 08, 2025



Lung infections, particularly pneumonia, pose serious health risks that can escalate rapidly, especially during pandemics. Accurate AI-based severity prediction from medical imaging is essential to support timely clinical decisions and optimize patient outcomes. In this work, we present a novel method applicable to both CT scans and chest X-rays for assessing lung infection severity. Our contributions are twofold: (i) QCross-Att-PVT, a Transformer-based architecture that integrates parallel encoders, a cross-gated attention mechanism, and a feature aggregator to capture rich multi-scale features; and (ii) Conditional Online TransMix, a custom data augmentation strategy designed to address dataset imbalance by generating mixed-label image patches during training. Evaluated on two benchmark datasets, RALO CXR and Per-COVID-19 CT, our method consistently outperforms several state-of-the-art deep learning models. The results emphasize the critical role of data augmentation and gated attention in improving both robustness and predictive accuracy. This approach offers a reliable, adaptable tool to support clinical diagnosis, disease monitoring, and personalized treatment planning. The source code of this work is available at https://github.com/bouthainas/QCross-Att-PVT.
Vision Transformer-based Model for Severity Quantification of Lung Pneumonia Using Chest X-ray Images
Mar 18, 2023



To develop generic and reliable approaches for diagnosing and assessing the severity of COVID-19 from chest X-rays (CXR), a large number of well-maintained COVID-19 datasets are needed. Existing severity quantification architectures require expensive training calculations to achieve the best results. For healthcare professionals to quickly and automatically identify COVID-19 patients and predict associated severity indicators, computer utilities are needed. In this work, we propose a Vision Transformer (ViT)-based neural network model that relies on a small number of trainable parameters to quantify the severity of COVID-19 and other lung diseases. We present a feasible approach to quantify the severity of CXR, called Vision Transformer Regressor Infection Prediction (ViTReg-IP), derived from a ViT and a regression head. We investigate the generalization potential of our model using a variety of additional test chest radiograph datasets from different open sources. In this context, we performed a comparative study with several competing deep learning analysis methods. The experimental results show that our model can provide peak performance in quantifying severity with high generalizability at a relatively low computational cost. The source codes used in our work are publicly available at https://github.com/bouthainas/ViTReg-IP.
SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix Data Augmentation
Apr 11, 2022
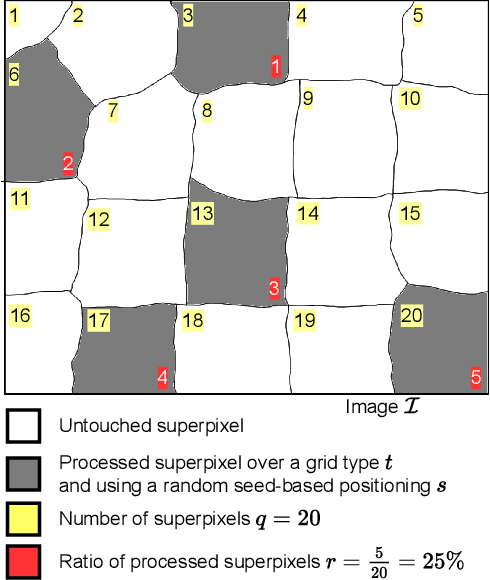

A novel approach of data augmentation based on irregular superpixel decomposition is proposed. This approach called SuperpixelGridMasks permits to extend original image datasets that are required by training stages of machine learning-related analysis architectures towards increasing their performances. Three variants named SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix are presented. These grid-based methods produce a new style of image transformations using the dropping and fusing of information. Extensive experiments using various image classification models and datasets show that baseline performances can be significantly outperformed using our methods. The comparative study also shows that our methods can overpass the performances of other data augmentations. Experimental results obtained over image recognition datasets of varied natures show the efficiency of these new methods. SuperpixelGridCut, SuperpixelGridMean and SuperpixelGridMix codes are publicly available at https://github.com/hammoudiproject/SuperpixelGridMasks